一种基于门控循环单元网络的负荷聚合体分组预测方法与流程
本发明属于电力系统负荷预测技术领域,尤其涉及一种基于门控循环单元网络的负荷聚合体分组预测方法。
背景技术
准确快速的负荷预测对电力系统的安全经济运行作用重大。传统的负荷预测多依据电力系统量测的物理结构进行层级划分,比如系统级、母线级、变电站级、微电网级等,通常针对某一特定层级开发的负荷预测方法不能适用于其他层级。近年来,随着智能电表的普及,电力公司能够获取海量细粒度的用户负荷数据。以智能电表数据为基础,能够摆脱电力系统量测结构的限制,可按需求灵活划分不同规模的负荷聚合体并开展负荷预测,也即除了可实现传统层级的电力系统负荷预测外,还可依据地区(如楼宇、小区、街区、地块),行业(如居民、工商业),电价类型(分时、峰谷等)等形成负荷聚合体并开展负荷预测,以满足更为精细化的负荷预测需求。
负荷聚合体的预测是以智能电表为基础的自底向上的负荷预测方法。负荷聚合体可按需划分,更为灵活,但不同划分方法会导致预测对象规模差异巨大,传统的负荷预测方法仅适用于特定的负荷规模,不具备泛化能力。特别是当负荷规模减小时,由于小规模负荷的群体效应减弱,负荷预测的平均绝对误差百分比(meanabsolutepercentageerror,mape)指标随预测规模的减小而显著提高,故传统的预测方法不适用于负荷聚合体的预测。针对负荷聚合体划分灵活、规模可变、与用户负荷特性联系紧密等特点,提出具有适用性的、高精度的预测方法,是负荷聚合体预测的难点。
由于智能电表数据与用户负荷特性关系密切,通过聚类分析,发现不同用户间负荷变化共性规律,据此将负荷聚合体划分为多个用电群体,针对负荷群体进行建模分析,能提高负荷聚合体的预测精度。在预测方法上,bp神经网络、支持向量机(supportvectormachine,svm)等在负荷预测中得到了广泛应用。这些算法通过训练建立输出与输入之间的非线性关系,将动态时间建模问题转化为静态建模问题。但是,作为典型的时序数据,负荷变化具有动态特性,即负荷变化规律除受当前时刻状态影响外,还受过去一段时间变化过程的影响。传统方法大多以相似日、典型日的历史数据作为输入,无法考虑负荷变化在时序上的特征,导致负荷预测误差较大。从用户历史用电数据中发现潜在的用电行为规律,并通过数据演变推测负荷的发展变化,是准确进行负荷预测的关键。随着深度学习的发展,以长短期记忆(longshort-termmemory,lstm)为代表的递归神经网络(recurrentneuralnetwork,rnn)能够考虑时间序列之间的相关性,可以更加全面地描述时间序列的变化过程,在语音识别、自然语言处理等多个领域得到了广泛应用。将lstm用于风电及居民负荷预测,证明其能考虑时间序列发展演变的内在规律,抓住时间序列的本质特征,从而提高预测精度。但lstm存在训练时间长的缺点,并且,由于负荷聚合体包含多种负荷特性,不同的负荷特性所适用的神经网络结构不同。因此,基于这些问题,提出基于深度神经网络的模型融合方法,充分整合利用不同网络结构的优势,有助于提高负荷聚合体预测精度。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出一种适用于负荷聚合体的预测方法,通过引入分组预测、深度神经网络、模型融合方法,使得所提方法能把握用户负荷特性及变化规律,预测精度高,适用性强。
本发明解决其技术问题是采取以下技术方案实现的:
一种基于门控循环单元网络的负荷聚合体分组预测方法,所述分组预测方法包括如下步骤:
(1)使用自适应分布式谱聚类算法,对用户负荷数据进行聚类,从而得到多个负荷特性相似的用电群体,并求得各群体负荷特征矩阵;
(2)搭建三种结构不同的gru网络,并通过提取群体的时序特征对三种结构不同的gru网络进行训练,得到三种gru网络的预测模型,通过随机森林算法对三种gru网络进行模型融合,得到每个群体的负荷预测模型;
(3)将待预测时刻特征输入到步骤(2)中得到的负荷预测模型中,分别得到每个群体的负荷预测值,将不同群体预测值求和得到最终负荷聚合体的预测值。
需要说明的是,所述步骤(1)中用电群体的获得过程为:对每个用户负荷数据按周取均值,通过最大-最小值归一化缩放到区间[0,1],对每个用户得到一条负荷特性曲线,将所有用户特性曲线整合为矩阵,针对矩阵进行聚类即可获得用电群体。
需要指出,所述步骤(2)中gru网络由输入层、输出层和隐藏层组成,其中隐藏层包含多个级联的gru单元;所述gru单元包括一个重置门,一个更新门,通过门控机制控制输出、记忆信息。
此外,所述步骤(2)中对负荷群体分别搭建三种结构的gru网络,通过控制网络深度及gru单元数量学习负荷聚合体的低频、中频、高频特征,并学习不同频域负荷变化特点,最终通过随机森林算法融合三个深度神经网络的输出。
本发明的优点和积极效果是:
1、本发明提出依据负荷特性对负荷聚合体进行分组预测,并将分布式谱聚类算法应用于负荷聚合体的分组聚类上,相较传统k-means算法提高了聚类精度及稳定性,克服了单机谱聚类算法计算速度慢、占用内存多的缺点;将模型融合思想应用于负荷聚合体的预测,采用不同结构的gru深度神经网络作为元模型,实现了时间序列的动态建模,通过随机森林算法对多个元模型进行融合,能充分利用不同网络结构特点,进一步提高负荷预测精度;
2、相较于bp、svm等常规方法,本发明的分组预测+模型融合的预测方法对负荷聚合体预测问题具有适用性,且在不同负荷规模条件下都具有更高的预测精度;通过滚动预测的形式可灵活调整预测的时间尺度,在30min-24h的预测尺度上,本发明的负荷预测方法均具有更高的预测精度。
附图说明
以下将结合附图和实施例来对本发明的技术方案作进一步的详细描述,但是应当知道,这些附图仅是为解释目的而设计的,因此不作为本发明范围的限定。此外,除非特别指出,这些附图仅意在概念性地说明此处描述的结构构造,而不必要依比例进行绘制。
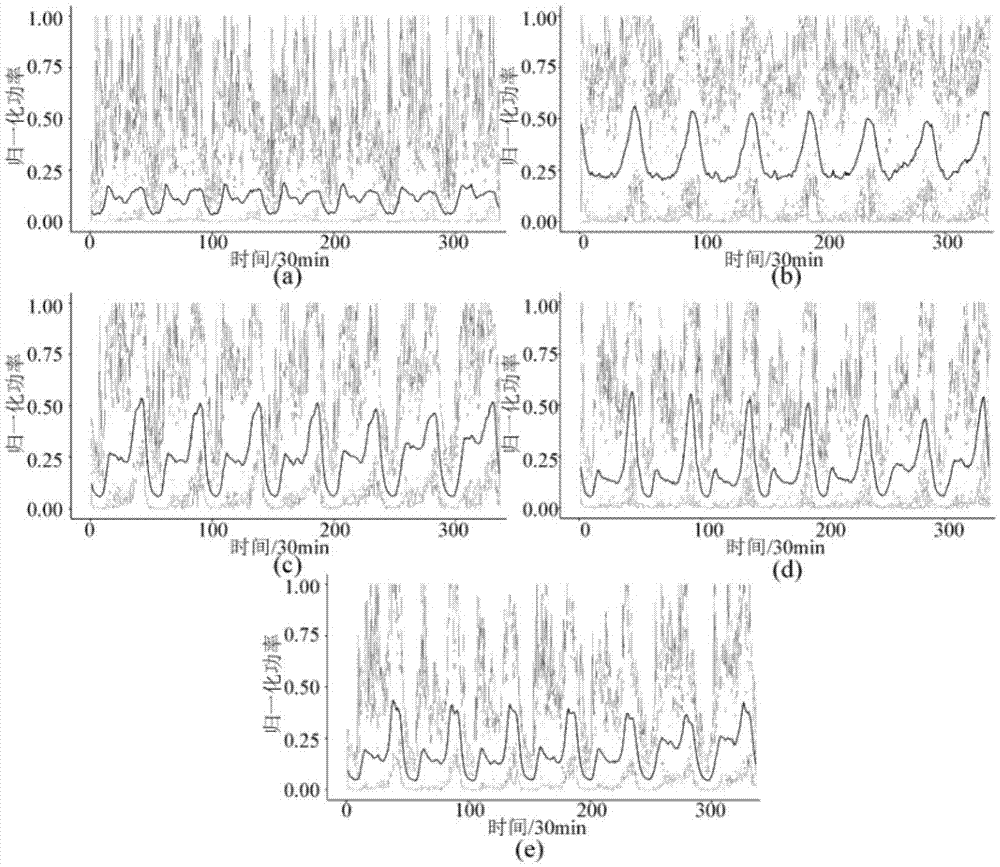
图1为负荷聚类图;
图2为分布式谱聚类算法与k-means算法的db指数随聚类数量变化情况图;
图3为三种gru网络结构图;
图4为基于gru网络与模型融合的预测架构图;
图5为不同用户数量下不同方法预测误差对比情况图;
图6为四种方法预测精度mape随预测时间尺度变化图;
具体实施方式
首先,需要说明的是,以下将以示例方式来具体说明本发明的具体结构、特点和优点等,然而所有的描述仅是用来进行说明的,而不应将其理解为对本发明形成任何限制。此外,在本文所提及各实施例中予以描述或隐含的任意单个技术特征,仍然可在这些技术特征(或其等同物)之间继续进行任意组合或删减,从而获得可能未在本文中直接提及的本发明的更多其他实施例。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
下面就结合图1至图6来具体说明本发明。
实施例1
图1为负荷聚类图;图2为分布式谱聚类算法与k-means算法的db指数随聚类数量变化情况图;图3为三种gru网络结构图;图4为基于gru网络与模型融合的预测架构图;图5为不同用户数量下不同方法预测误差对比情况图;图6为四种方法预测精度mape随预测时间尺度变化图;如图1~6所示,本实施例提供的基于门控循环单元网络的负荷聚合体分组预测方法,以伦敦智能电表数据集为例进行负荷聚合体的预测,具体过程如下:
一、采用分布式谱聚类的负荷聚类方法进行聚类
首先,对每个用户负荷数据lm按周取均值,通过最大-最小值归一化缩放到区间[0,1],这样对每个用户得到一条负荷特性曲线,将所有用户特性曲线整合为矩阵cm×t,针对矩阵cm×t进行聚类即可获得用电群体,按智能电表典型的30分钟采样间隔计算,则每个用户特征曲线含有48×7=336个点,数据维度很高,且待分析用户数量多,导致传统聚类方法精度、速度、稳定性无法满足分析要求。谱聚类则克服了k-means等传统聚类算法只能识别凸球形分布的数据,并且可能陷入局部最优的缺点,能够在任意形状样本上聚类,并收敛于全局最优,其本质是将聚类问题转换为图的最优划分问题。谱聚类算法流程如下:
由矩阵cm×t求得n个用户两两之间的欧式距离矩阵hm,n,计算公式如下:
式中,hm,n表示第m个用户与第n个用户之间的欧式距离,hm,n为对称矩阵,且对角线元素为0。
采用高斯函数构建hm,n的相似性矩阵a:
式中,σm和σn为自适应尺度参数,在实际操作时,自适应是指预先指定几个尺度参数σ的值,分别执行谱聚类,最后选取使聚类结果最好的σ作为参数。
进而可构建拉普拉斯矩阵l:
l=d-1/2ad-1/2(4)
依据摄动理论,通过计算相似度矩阵的特征值来确定最优分类数,设确定的最优分类数为k,则其对应的k个特征向量为x1,x2,…,xk,则所得特征向量矩阵x=(x1,x2,…,xk)。对所得特征矩阵采用k-means方法聚类,得到最终用电群体划分结果。
谱聚类算法在计算相似矩阵及寻找k个特征向量时计算量最大,并且占用较多的存储空间。为克服传统谱聚类算法效率上的不足,分布式谱聚类算法使用最近邻稀疏相似矩阵代替原相似矩阵,同时采用基于mapreduce的分布式计算框架计算特征向量。首先,在p个节点上均存储n/p行的矩阵,在每个map阶段设置所有n/p个数据点具有相同的键,在reduce阶段每个节点均计算本地数据与输入xi的距离:
其中xj表示节点的本地数据,为保证所得距离矩阵具有对称性,在map阶段设置两个键,分别返回行列编号及相应距离,以确定各元素位置。节点间的并行化计算使得问题复杂度由(6)降低为(7):
o(n2d+n2logt)(6)
o(n2d/p+(n2logt)/p)(7)
如式(2)所示,对相似矩阵的计算也采用同样的并行化步骤,得到一个稀疏化的相似矩阵。相似矩阵的特征值求取计算量大,占用内存多,由于谱聚类中相似矩阵的稀疏化特点,采用并行化求解特征值的parpack算法,分别部署到所有计算节点上。并行计算特征值的复杂度由式(8)降低为式(9):
o(m3)+(o(nm)+o(nt))×o(m-k)(8)
o(m3)+(o(mn/p)+o(nt/p))×o(m-k)(9)
谱聚类通过对特征向量进行聚类实现分组,本实施例采用并行化的k-means算法实现聚类步骤。spark中内置了分布式版本的k-means算法,可通过mllib包进行调用。设p为计算节点数,分布式k-means算法理论计算复杂度仅为单机版本的1/p。
对伦敦智能电表数据集中的2676个用户进行聚类,由图1可见:不同用户群体之间存在明显的差异性,但同类中具有共性;(a)类群体属于用电相对较为平稳的类型,负荷整体处于较低水平;而(b)类群体则相反,最低负荷状态仍保持在较高水平,表明该类用户长期工作的设备较多;(c)、(e)类群体在早晚存在明显的两个用电尖峰,但高峰持续时间及大小有所不同;(d)类群体的波动性较强。
下面分析所提算法的计算性能,对照方法为传统单机版本k-means算法,实验环境为8节点分布式计算集群(intelxeone7-8850v2*8,16gregisteredddr3内存*16)。以davies-bouldin指数(db)作为聚类结果评价指标,db指数定义为:
式中,
为保证聚类结果之间具有可比性,手动指定聚类数量,由于初始点的选择会影响聚类结果,对每个指定的聚类数量两种方法均重复10次聚类,记录对应db指数。两种方法db指数随聚类数量变化情况如图2所示,从图2中可以看出,对应不同的聚类数量,谱聚类算法的db值均小于k-means算法的db值,说明谱聚类算法聚类效果要优于k-means算法的聚类效果。
二、基于gru网络与模型融合的预测模型设计
gru网络由输入层、输出层和隐藏层组成。其中隐藏层包含多个级联的gru单元。
gru单元包括一个重置门rt,一个更新门zt,通过门控机制控制输出、记忆等信息,在当前时间步做出预测。gru工作流程如下:每一个时刻,gru单元通过更新门接收当前状态xt与上一个时刻的隐藏状态ht-1,接收输入信息后,通过矩阵运算,由激活函数决定神经元是否激活。同理,重置门同样接收xt与ht-1,其运算结果决定有多少过去的信息需要被遗忘。当前时刻输入经过运算与重置门输出叠加,经过激活函数形成当前记忆内容h′t。当前记忆h′t与前一步输入ht-1通过更新门的动态控制,决定最终门控单元的输出内容ht,同时ht也将传递到下一个gru单元中。各变量之间的计算公式如下:
zt=σ(w(z)xt+u(z)ht-1)(11)
rt=σ(w(r)xt+u(r)ht-1)(12)
式中,w(z)与u(z)表示更新门的权重,w(r)与u(r)表示遗忘门的权重,w与u表示形成当前记忆时网络权重,σ(x)为激活函数sigmoid,tanh(x)为激活函数tanh。
得到gru网络后,通过按时间展开的反向误差传播算法(bptt)进行训练。本实施例选择负荷预测值的平均绝对误差(mae)作为损失函数:
不同负荷群体之间负荷波动性存在较大差异。对相对平稳的负荷群体,浅层多单元的gru网络效果较好,而对于波动性很强的负荷群体,则应该采用多层叠加的网络充分提取高频特征。为了适应不同群体的负荷特点,对每类负荷群体分别提出三种结构的gru网络,以充分学习不同频域负荷变化特点,最终通过随机森林算法融合三个深度神经网络的输出。多模型融合的方法保证了预测模型具有较强的适用性。
三种gru网络结构如图3所示。通过控制网络深度及gru单元数量,有针对性地学习负荷聚合体的低频、中频、高频特征,最终通过随机森林实现模型融合。本文选择的深度神经网络输入特征如下:
(1)过去k个时刻的负荷数据向量e,e={et-k,…,et-2,et-1},本实施例设置的k为6,即依据过去3小时的负荷变化进行预测;
(2)待预测点所属的时刻系数i,将24小时分为48个预测点,则i∈{1,2,...,48};
(3)待预测点所属的星期数d,d∈{1,2,...,7};
(4)工作日/节假日h,工作日置1,节假日置0;
(5)前一时刻温度t;
(6)当前气象类型w;伦敦气象局指定的晴、小雨等13种气象类型,w∈{1,2,...,13};
由于gru网络要求输入在0-1之间,通过最大最小归一化的方式处理向量e,t,将i,d,h,w转化为热编码的形式。对于类型变量j,设j所属类别数量为m,热编码后的变量j含有m个比特位,并且只有一个对应所属类别的比特位为1。
将处理后的特征组成特征矩阵x:
x={e,i,d,h,t,w}(16)
所有gru网络基于keras框架构建,在gpunvidiagtx10606g上进行训练和测试,使用tensorflow作为计算后端。在gru网络的训练过程中,通过优化器实现梯度下降算法,常用优化器有adagrad,adadelta,rmsprop,adam。本文采用adam作为优化器,其优势在于能实现自适应的学习率调整,训练高效。对于用于多模型融合的随机森林算法,设置cart回归树个数为50,最大决策树深度不做限制,设置随机森林使用的最大特征数为3。随机森林模型在获得三个gru网络后进行训练,训练数据为验证集lval。
训练得到预测模型后,对给定待预测负荷聚合体,按聚类结果将其划分为i个负荷群体,对每个负荷群体i,采用图4所示结构进行预测,最终将i个预测值ei-t加和,即可得到最终t时刻负荷聚合体的预测值et。
三、负荷聚合体预测误差分析
设置待预测的负荷聚合体用户数量m为2676,负荷聚合体可细分为5类负荷群体,每类包含数据样本7392组,其中输出功率矩阵es维度为7392×1,输入特征矩阵x维度为7392×75,将数据按照8:1:1的比例划分为训练集,验证集与测试集。训练集用于训练gru网络,验证集用于训练随机森林模型,并输出重要度系数wk,测试集用于测试最终模型性能。除mape外,计算模型的平均绝对误差(meanabsoluteerror,mae)作为补充指标,预测模型在不同负荷群体上预测效果如表1所示。
表1
由表1可见,对于不同的负荷群体,三种网络重要度差别较大,同时模型融合后的预测精度优于任一单一模型,证明了本文所提模型融合方法能充分利用不同网络结构特点,实现各网络权重的自动分配,从而进一步提高预测精度。
为证明本文方法优越性,分别采用bp神经网络(三层,神经元数量为128,256,128),采用高斯核函数的支持向量机(supportvectormachine,svm),随机森林(randomforest,rf)算法直接对负荷聚合体进行预测。四种方法精度对比如表2所示。
表2
由表2可以看出,本发明实施例中的算法得到的平均绝对误差百分比(mape)、计算模型的平均绝对误差(mae)相较于bp神经网络、svm、随机森林算法均低,说明在这四种方法中,本发明实施例中的算法的精度最高。
四、不同规模负荷聚合体下预测性能对比
负荷聚合体划分灵活,本质上讲不同划分方法最终只是影响聚合用户的数量。为验证本发明所述算法对不同规模负荷聚合体的适用性,通过随机抽样的方式设置用户数量m=500,1000,1500,2000,2676,对比所述方法与传统方法的预测精度。四种方法预测精度随用户数量变化情况如图5所示。由图5可见,本文所提方法由于采用了分组预测、动态时间建模及模型融合技术,在不同负荷规模条件下均取得了最高的预测精度。从不同用户规模下各方法的mae指标来看,本文所述预测方法的绝对误差最小,并且随用户数量增加误差变化不大,性能稳定,从而证明了本文所提方法对不同规模的负荷聚合体都具有较好的适用性。而其他三种方法,特别是svm在用户数量较少时表现很好,随着用户数量增加绝对误差迅速增大,预测性能不稳定,适用性较差。
五、滚动预测效果
通过滚动预测的形式可灵活调整本文所述方法的预测时间尺度,仍设置负荷聚合体的用户数量为2676,分别将预测尺度由未来30min扩展到24h,四种方法的预测精度mape变化如图6所示。图中曲线为对散点进行多重线性拟合的结果。由图6可见,随预测时间尺度的增加,四种方法的预测精度均有所降低,其中随机森林算法与svm性能劣化显著。在预测尺度超过10小时后,两种人工神经网络方法的误差情况趋于稳定,本方法的精度优势得到了保持,且相较于超短期预测更为显著。
综上所述,本发明提出依据负荷特性对负荷聚合体进行分组预测,并将分布式谱聚类算法应用于负荷聚合体的分组聚类上,相较传统k-means算法提高了聚类精度及稳定性,克服了单机谱聚类算法计算速度慢、占用内存多的缺点;将模型融合思想应用于负荷聚合体的预测,采用不同结构的gru深度神经网络作为元模型,实现了时间序列的动态建模,通过随机森林算法对多个元模型进行融合,能充分利用不同网络结构特点,进一步提高负荷预测精度;相较于bp、svm等常规方法,本发明的分组预测+模型融合的预测方法对负荷聚合体预测问题具有适用性,且在不同负荷规模条件下都具有更高的预测精度;通过滚动预测的形式可灵活调整预测的时间尺度,在30min-24h的预测尺度上,本发明的负荷预测方法均具有更高的预测精度。
以上实施例对本发明进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
- 还没有人留言评论。精彩留言会获得点赞!