基于密度峰值与社区归属度的重叠社区发现方法与流程
本发明涉及复杂网络上的重叠社区发现技术领域,具体涉及一种基于密度聚类的重叠社区发现方法。
背景技术
在现实世界中存在大量复杂网络,如社交网络、生物网络、文献引用网络。研究表明,这些复杂网络普遍存在着一定的社区结构,各社区内部节点连接较为紧密,社区间连接较为稀疏。社区发现研究的就是如何准确的识别出复杂网络中的社区结构。
传统的社区发现算法是将网络划分成若干个互不相连的社区,网络中每个节点和边只能隶属一个固定社区。包括模块度优化方法,层次聚类算法,标签传播算法和信息论算法。.然而,真实网络中,社区之间通常是互相交叉,彼此联系的,这种情形下,网络中的节点不再仅隶属于单个社区,而是同时被包含到多个相关联的社区中。因而,研究重叠社区结构具有更重要意义。
目前,重叠社区发现算法主要包括基于派系过滤的算法、基于局部社区的算法、基于多标签传播的算法和基于链接聚类的算法等。这些算法在社区结构明显且大小均匀时可以较好的发现网络社区结构,但对于社区大小不均以及形状各异的网络,上述算法的效果较差。所以就有研究员提出了基于密度峰值聚类的重叠社区发现算法。
目前已有一些学者对基于密度峰值聚类的重叠社区发现算法进行了研究,也取得了一定的成果,但仍然存在以下两个问题:首先算法的时间复杂度相对较高,无法处理较大规模网络;其次,在选取社区中心点时,需要人为指定社区中心点的局部密度阈值和跟随距离阈值,这种方法无法很好的应用于较为复杂网络结构。这两个问题导致了社区发现的精度不高。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于密度聚类的重叠社区发现方法,能够准确的识别重叠社区结构,且具近似线性的时间复杂度,适用于大规模复杂网络。
为实现上述目的,本发明采用如下技术方案:
基于密度峰值与社区归属度的重叠社区发现方法,其特征在于:包括以下步骤:
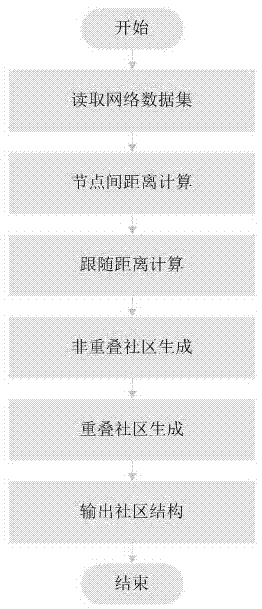
步骤s1:读取网络数据集,生成网络图g;
步骤s2:根据网络图g节点间的路径长度来计算网络中节点间距离、距离最大值dmax、距离最小值dmin,得到节点间距离字典pd;
步骤s3:根据节点间距离字典pd计算节点间的距离阈值dc、节点的局部密度rho;
步骤s4:根据节点间距离字典pd、节点的局部密度rho求取节点的跟随节点nnb和跟随距离del;
步骤s5:根据密度峰值聚类算法的原理生成非重叠社区集c;
步骤s6:对非重叠社区集c的边界点进行社区归属判断,得到重叠社区集c';
步骤s7:输出最终的社区划分结果。
进一步的,所述步骤s1具体为:读取网络数据集,生成用于划分社区结构的网络图g=(v,e),其中v表示节点集,e表示边集。
进一步的,所述步骤s2具体为:
步骤s21:初始化节点间距离字典pd为空;
步骤s22:遍历v中每个节点v,再遍历节点v的每个邻居u,按公式(1)求出节点u,v间的距离d(u,v),并把d(u,v)添加到距离字典pd中;
其中,dnb(v)表示节点v的直接邻居,当u∈dnb(v)时,节点u,v间距离由长度为1的路径所表示的距离和长度为2的路径所表示的
距离相加计算得到;而
当
步骤s23:遍历节点u的每个邻居r,按公式(2)求出节点r,v间的距离d(r,v),并把d(r,v)添加到节点间距离字典pd中;
步骤s24:求出节点间距离的最大值dmax、最小值dmin;
步骤s25:输出节点间距离字典pd、最大值dmax、最小值dmin。
进一步的,所述步骤s3具体为:
步骤s31:初始化节点的局部密度字典rho为空,网络所有节点的dc-邻域内节点数nb及nb与网络节点总数的比例np为0;
步骤s32:根据密度峰值聚类算法中距离阈值的选取规则计算阈值dc;
步骤s33:根据dc和公式(3)计算网络中每个节点的局部密度;
其中,rho(u)表示节点u的局部密度,inb(u)表示节点u邻居的邻居;
步骤s34:输出局部密度字典rho,距离阈值dc。
进一步的,所述步骤s4具体为:
步骤s41:初始化局部密度列表rl、节点跟随邻居字典nnb,跟随距离字典del和邻居节点集合nb为空;
步骤s42:将rho中的元素逐个添加到rl中,并对rl按局部密度值大小降序排序,得到排序后的局部密度列表rl;
步骤s43:根据密度峰值聚类算法的原理求取每个节点的跟随邻居和跟随距离,得到跟随邻居字典nnb,跟随距离字典del;
步骤s44:输出节点跟随邻居字典nnb,跟随距离字典del和排序后的局部密度列表rl。
进一步的,所述步骤s5具体为:
步骤s51:初始化非重叠社区集c、节点及其所在社区标号字典cn和社区边界点集合bc为空。
步骤s52:根据(4)求取社区中心点集合cc,并给cc中的每一个社区中心点分配社区标号;
社区集合c的中心点cc定义为:
其中,del(v)表示社区中心点的跟随距离阈值,ui∈v,avg(del(ui))表示节点的平均跟随距离,rho(v)表示社区中心点的局部密度阈值,avg(rho(ui))表示节点的平均局部密度,λ、γ为调节参数;
步骤s53:根据密度峰值聚类算法中节点分派规则给社区非中心点分配社区,并根据(5)计算社区边界点bc;
社区ci的边界点bci定义为:
步骤s54:把节点及其所在社区标号字典cn转换成社区集c;
步骤s55:输出非重叠社区集c,社区边界点bc。
进一步的,所述步骤s6具体为:
步骤s61:初始化社区归属度字典aff、社区边界点及其归属社区标号字典oc和重叠社区标号集合s为空;
步骤s62:根据公式(6)、(7)计算算社区边界点的社区归属度,添加到社区归属度字典aff中;
其中,σ(u,v)表示节点v和节点u之间的余弦相似度,|dnb+(u)|表示节点u的直接邻居节点个数;affi(v)表示节点v对社区ci的社区归属度,d(u)表示节点u的度。
步骤s63:根据公式(8)计算社区边界点社区归属度阈值
其中,affth(v)表示节点v的社区归属度阈值,ci={i|v∈ci},表示与节点v有边连接的社区,|ci|表示集合ci中元数数目,β为调节参数,用来度量边界点的社区归属度均匀分布情况,由定义可知β≥1;
步骤s64:计算社区边界点的归属社区标号,并添加到归属社区标号字典oc中;
步骤s65:把社区边界点集合bc中的节点划分到相应的社区中;
步骤s66:输出重叠社区集c'。
进一步的,所述步骤7具体为:
步骤s71:将重叠社区集c'中每个社区ci中的节点vi,j写成行向量形式ri=(vi,j);
步骤s72:输出向量集{ri},0<i<p,p为社区个数,每行代表一个社区;社区重叠由行向量中包含的重复节点表示。
本发明与现有技术相比具有以下有益效果:
1、本发明提出出一种基于节点直接邻居和间接邻居的距离度量方法,具有近似线性的时间复杂度,可以应用于大规模复杂网络。
2、本发明计一种聚类中心点的局部密度阈值和跟随距离阈值自动选取方法,可以解决密度峰值聚类算法中这两个阈值需要人为选定的问题
3、本发明出社区归属度计算方法,并对采用密度峰值聚类算法生成的社区边界节点进行社区归属计算,根据社区归属度把社区边界点划分到对应社区中,可以较好的识别出网络的重叠社区。
附图说明
图1是本发明本发明实施例的实现流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于密度峰值与社区归属度的重叠社区发现方法,其特征在于:包括以下步骤:
步骤s1:读取网络数据集,生成网络图g;
步骤s2:根据网络图g节点间的路径长度来计算网络中节点间距离、距离最大值dmax、距离最小值dmin,得到节点间距离字典pd;
步骤s3:根据节点间距离字典pd计算节点间的距离阈值dc、节点的局部密度rho;
步骤s4:根据节点间距离字典pd、节点的局部密度rho求取节点的跟随节点nnb和跟随距离del;
步骤s5:根据密度峰值聚类算法的原理生成非重叠社区集c;
步骤s6:对非重叠社区集c的边界点进行社区归属判断,得到重叠社区集c';
步骤s7:输出最终的社区划分结果。
在本发明一实施例中,所述步骤s1具体为:读取网络数据集,生成用于划分社区结构的网络图g=(v,e),其中v表示节点集,e表示边集。
在本发明一实施例中,所述步骤s2具体为:
步骤s21:初始化节点间距离字典pd为空;
步骤s22:遍历v中每个节点v,再遍历节点v的每个邻居u,按公式(1)求出节点u,v间的距离d(u,v),并把d(u,v)添加到距离字典pd中;
其中,dnb(v)表示节点v的直接邻居,当u∈dnb(v)时,节点u,v间距离由长度为1的路径所表示的距离和长度为2的路径所表示的
距离相加计算得到;而
当
步骤s23:遍历节点u的每个邻居r,按公式(2)求出节点r,v间的距离d(r,v),并把d(r,v)添加到节点间距离字典pd中;
步骤s24:求出节点间距离的最大值dmax、最小值dmin;
步骤s25:输出节点间距离字典pd、最大值dmax、最小值dmin。
在本发明一实施例中,所述步骤s3具体为:
步骤s31:初始化节点的局部密度字典rho为空,网络所有节点的dc-邻域内节点数nb及nb与网络节点总数的比例np为0;
步骤s32:根据密度峰值聚类算法中距离阈值的选取规则计算阈值dc;
步骤s33:根据dc和公式(3)计算网络中每个节点的局部密度;
其中,rho(u)表示节点u的局部密度,inb(u)表示节点u邻居的邻居;
步骤s34:输出局部密度字典rho,距离阈值dc。
在本发明一实施例中,所述步骤s4具体为:
步骤s41:初始化局部密度列表rl、节点跟随邻居字典nnb,跟随距离字典del和邻居节点集合nb为空;
步骤s42:将rho中的元素逐个添加到rl中,并对rl按局部密度值大小降序排序,得到排序后的局部密度列表rl;
步骤s43:根据密度峰值聚类算法的原理求取每个节点的跟随邻居和跟随距离,得到跟随邻居字典nnb,跟随距离字典del;
步骤s44:输出节点跟随邻居字典nnb,跟随距离字典del和排序后的局部密度列表rl。
在本发明一实施例中,所述步骤s5具体为:
步骤s51:初始化非重叠社区集c、节点及其所在社区标号字典cn和社区边界点集合bc为空。
步骤s52:根据(4)求取社区中心点集合cc,并给cc中的每一个社区中心点分配社区标号;
社区集合c的中心点cc定义为:
其中,del(v)表示社区中心点的跟随距离阈值,ui∈v,avg(del(ui))表示节点的平均跟随距离,rho(v)表示社区中心点的局部密度阈值,avg(rho(ui))表示节点的平均局部密度,λ、γ为调节参数;
步骤s53:根据密度峰值聚类算法中节点分派规则给社区非中心点分配社区,并根据(5)计算社区边界点bc;
社区ci的边界点bci定义为:
步骤s54:把节点及其所在社区标号字典cn转换成社区集c;
步骤s55:输出非重叠社区集c,社区边界点bc。
在本发明一实施例中,所述步骤s6具体为:
步骤s61:初始化社区归属度字典aff、社区边界点及其归属社区标号字典oc和重叠社区标号集合s为空;
步骤s62:根据公式(6)、(7)计算算社区边界点的社区归属度,添加到社区归属度字典aff中;
其中,σ(u,v)表示节点v和节点u之间的余弦相似度,|dnb+(u)|表示节点u的直接邻居节点个数;affi(v)表示节点v对社区ci的社区归属度,d(u)表示节点u的度。
步骤s63:根据公式(8)计算社区边界点社区归属度阈值
其中,affth(v)表示节点v的社区归属度阈值,ci={i|v∈ci},表示与节点v有边连接的社区,|ci|表示集合ci中元数数目,β为调节参数,用来度量边界点的社区归属度均匀分布情况,由定义可知β≥1;
步骤s64:计算社区边界点的归属社区标号,并添加到归属社区标号字典oc中;
步骤s65:把社区边界点集合bc中的节点划分到相应的社区中;
步骤s66:输出重叠社区集c'。
在本发明一实施例中,所述步骤7具体为:
步骤s71:将重叠社区集c'中每个社区ci中的节点vi,j写成行向量形式ri=(vi,j);
步骤s72:输出向量集{ri},0<i<p,p为社区个数,每行代表一个社区;社区重叠由行向量中包含的重复节点表示。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!