一种基于混合智能算法的变压器故障识别方法与流程
本发明涉及一种故障识别方法,具体涉及一种基于混合智能算法的变压器故障识别方法。
背景技术:
变压器作为输配电环节中昂贵的重要设备,其现行运维主要依赖定期批量检修结合状态评估的方式,这种费时费力的方式成了提升电网运行安全性、可靠性和经济性的瓶颈。提高设备状态评估的准确性和有效性可大大提高运行维护工作效率,将原被动的方式转变为依据变压器状态变化而响应的主动检修工作,降低设备运行维护环节的费用。
传统的状态检修主要依据《油浸式变压器(电抗器)状态评价导则》、《变压器油中溶解气体分析和判断导则》等相关导致与检修规程制定评估方法,另外还有iec比值法、扩展德拜等效电路、杜瓦尔三角法等,这些方法只能针对特定的故障类型进行判断,可能导致变压器故障状态不准确的判断,扩展性弱。
由于变压器运行数据与试验、检修数据积累渐成规模,现有技术中提出了通过专家经验来对数据进行挖掘分析判断变压器的运行状态,然而这种方法太过于依赖专家的主观认知与经验知识,可靠性不高,不利于推广。因此,科学研究者将智能算法运用到数据分析挖掘中,利用人工智能算法对变压器设备状态指标数据进行学习,建立状态评估模型,以代替专家评估方法,现如今已有许多行之有效的方法。例如,使用多层次支持向量机(svm)分类器对变压器溶解气体进行故障分类;基于遗传算法的支持向量机算法,在支持向量机算法的故障状态判断模型之下;利用遗传算法对支持向量机参数的优化;多目标粒子群算法优化分类器,在多数分类算法中得到准确度较高的算法;通过将人工神经网络和证据理论的结合,结合两者优点提出了一种变压器故障综合诊断方法。
由于数据规模越来越庞大,数据维度随检查仪器设备的投入不断扩展,信息不断增多且产生冗余,智能算法面向的变压器数据越来越复杂,单一算法已经无法满足分析要求。例如支持向量机在处理高维复杂非线性的数据时,计算慢,耗时长,精度低,泛化能力弱;模糊c均值聚类对样本敏感,分类准确率低;层次分析法在指标权值的确定、状态等级的划分以及具有复杂关联关系的数据指标的组合分类或分层等方面容易出现错误。基于数理统计的状态关联规则分析方法对前期统计数据要求高,容错性差。遗传算法计算量大,复杂,后期收敛速度慢,容易陷入早熟。人工神经网络结构复杂,对参数敏感,收敛速度慢,容易产生过度拟合。
技术实现要素:
针对上述现有技术中存在的问题,本发明为提高电力变压器故障识别的准确率和可靠性,提出一种基于混合智能算法的变压器故障识别方法,在大数据的基础上,采用混合智能算法建立电力变压器故障识别模型,通过模型来识别变压器的故障。
为了实现上述任务,本发明采用以下技术方案:
一种基于混合智能算法的变压器故障识别方法,包括以下步骤:
建立样本集,确定识别模型的结构规模、预设参数;
根据所述识别模型的预设参数生成粒子群,其中每一个粒子表征一组待寻优的识别模型参数;
计算粒子群中每个粒子的适应度,选择粒子的进化方式,更新粒子的位置与速度,当达到设定的迭代次数时输出寻优结果,将寻优结果作为识别模型参数,建立识别模型,利用识别模型进行变压器故障的识别。
进一步地,所述的建立样本集,包括:
收集n组样本(x,y)构成样本集,其中x作为输入,属性长度为m;y作为输出,表征了c类故障状态;随机选取n组作为训练样本集xn*m,余下作为测试样本集;
对所述的训练样本集、测试样本集均进行标准化或归一化处理。
进一步地,所述的确定识别模型的结构规模、预设参数,包括:
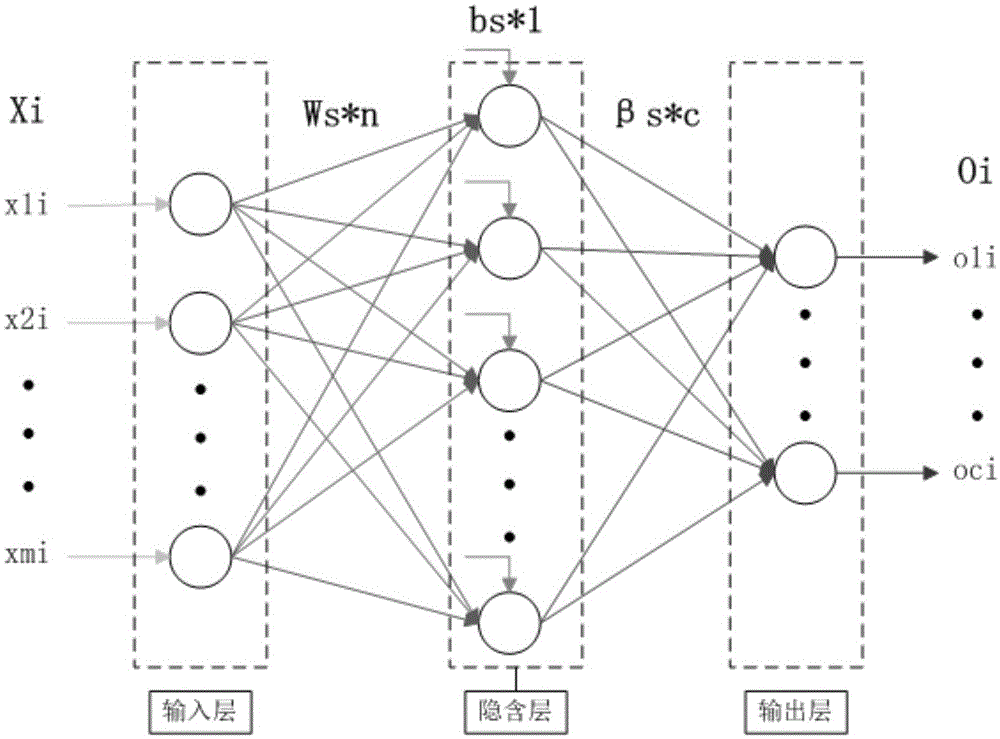
所述的识别模型为神经网络模型,识别模型的结构规模为m*s*c,其中识别模型中输入神经元个数为m个,输出神经元个数为c个,根据试错法对隐含层神经元个数s取值,并选择隐含层激活函数g(x);
所述的预设参数包括:最大进化次数maxiter,最大进化速度v_max和最小进化速度v_min,迭代计数t取1,粒子最大发光亮度l0,亮度调整系数σ,粒子荧光传播损耗系数γ;动量因子α。
进一步地,所述的根据所述识别模型的预设参数生成粒子群,包括:
根据所述的识别模型的预设参数随机生成粒子群ap*l,种群ap*l由p个粒子构成,每个粒子长度为l,l=s*(m+1)。
进一步地,所述的计算粒子群中每个粒子的适应度,包括:
通过新粒子与旧粒子适应度的竞争来对种群进行更新,若旧粒子的适应度小于新粒子的适应度,则用新粒子取代旧粒子;采用同样的竞争方式对全局最优位置进行更新;所述的适应度f的计算公式为:
f=αerr(o,y)+(1-α)acc(o,y)式1
其中,α为动量因子,oi为训练样本集中第i个训练样本通过识别模型计算的输出值,yi为第i个训练样本的期望输出值,acc(o,y)为识别模型计算输出的正确率。
进一步地,所述的第i个训练样本通过识别模型计算的输出值oi的计算方法包括:
(1)规范化训练样本集xn*m,其中训练样本共有n组,yn*c为对应的n组训练样本的输出,c为故障状态类数;
(2)确定隐含层神经元个数s以及激活函数为sigmoid,随机生成输入层与隐含层连接权重和隐含层神经元偏置值;
(3)计算隐含层神经元的输出矩阵h:
上式中,g(·)为激活函数sigmoid,w1…ws分别为s个输入层与隐含层连接权重,b1…bs为s个隐含层神经元偏置值,x1…xn指训练样本集xn*m中的n个训练样本;
(4)计算隐含层神经元与输出层神经元权重
上式中,h为输出矩阵,λ0为正则系数,i表示单位矩阵,yn*c为n组训练样本的输出;
根据上面的计算可获得一组参数:输入层与隐含层连接权重w、隐含层神经元偏置值b、隐含层神经元与输出层神经元权重
则所述的第i个训练样本通过识别模型计算的输出值oi即为输出值矩阵o中的第i个值。
进一步地,所述的选择粒子的进化方式,更新粒子的位置与速度,当达到设定的迭代次数时输出寻优结果,包括:
当迭代次数t等于1时,采用更新方式1,否则采用更新方式2:
更新方式1:采用粒子群算法对种群进行位置与速度的更新;
更新方式2:采用萤火虫算法对种群进行位置更新,在计算时,一个萤火虫对应一个粒子,每个粒子携带了亮度l与吸引度b(i)两种信息:
l=-l0(rij-σ)2式6
其中,l0为粒子的最大发光亮度;rij为粒子i与光源j距离,距离采用euclidean计算方式进行计算;σ为亮度调整系数,γ为粒子荧光传播损耗系数,当第i个粒子适应度小于第j个粒子适应度时,按式8和式9对粒子位置和速度进行更新,否则粒子位置不做更新:
xi(t+1)=xi(t)+b(i)(xj(t)-xi(t))+αeerr(t)(j=1,2,...,p)式8
vi(t+1)=xi(t+1)-xi(t)式9
其中,α为动量因子,e为自然常数,p为粒子总数,xi(t)和xj(t)分别为粒子i和j在第t次进化的位置,xi(t+1)为粒子i在第t+1次进化的位置,err(t)为进化过程的训练误差,vi(t+1)为粒子i更新后的速度;
当迭代次数大于最大进化次数maxiter时,停止迭代,输出寻优结果;否则继续迭代过程。
进一步地,所述的利用识别模型进行变压器故障的识别,包括:
取训练样本集作为特征字典,d={d1,d2,......,dc},其中c为故障状态类别数;识别模型的测试输出yi为第i个未知类别测试样本,稀疏系数α与特征字典d、未确知分类样本之间的关系:
dkαk=yi(k=1,2,3......c)式10
式中,dk为第k个数据特征字典,由第k类训练样本构成;αk为第k类稀疏表示系数;yi为第i个未知类别测试样本;
计算满足阈值要求的稀疏系数
上式中,ε为最小容许残差;
计算残差r(yi),返回残差最小值所对应的特征字典项dk即yi所属类别:
与现有技术相比,本发明具有以下技术特点:
1.比较传统专家评估、三比值法或者基于数理统计的方法,本方法利用算法对大量数据进行挖掘分析学习,然后做出判断和预测,不受专家经验与主观认知局限,扩展性强,通过基于数据的自学习与推理能力实现智能化;
2.方法所建立的模型较神经网络、支持向量机计算速度快、泛化能力强,能够处理大规模高维度的数据,适用于多分类或回归计算等问题;
3.方法通过混合算法对elm模型的输入层与隐含层之间的权重值w与隐含层偏置值b进行寻优,较单一算法或单一优化算法优化的模型故障识别准确率高,稳定性强;
4.通常算法采用多输出值标签的方式输出计算结果,然后依据最大输出值隶属原则进行分类判断,这种方式过于绝对。本发明引入稀疏表示分类,对模型输出结果与模型训练样本(特征字典)进行特征确认,利用特征关联度对分类结果再分类,进一步提高分类正确率。
附图说明
图1为本发明中所述的识别模型的结构示意图;
图2为本发明方法流程图;
具体实施方式
下面结合附图及具体实施方式对本发明进行详细说明。
本发明一种基于混合智能算法的变压器故障识别方法,如图2所示,具体按照以下步骤实施:
步骤1,建立样本集,确定识别模型的结构规模、预设参数;
收集n组样本(x,y)构成样本集,其中x作为输入,属性长度为m;y作为输出,表征了c类故障状态;随机选取n组作为训练样本集xn*m,余下作为测试样本集;对所述的训练样本集、测试样本集均进行标准化或归一化处理。
所述的识别模型为神经网络模型,识别模型的结构规模为m*s*c,其中识别模型中输入神经元个数为m个,输出神经元个数为c个,根据试错法对隐含层神经元个数s取值,并选择隐含层激活函数g(x);
所述的预设参数包括:最大进化次数maxiter,最大进化速度v_max和最小进化速度v_min,迭代计数t取1,粒子最大发光亮度l0,亮度调整系数σ,粒子荧光传播损耗系数γ;动量因子α。
步骤2,根据所述识别模型的预设参数生成粒子群
根据所述的识别模型的预设参数随机生成粒子群ap*l,种群ap*l由p个粒子构成,每个粒子长度为l,l=s*(m+1);其中每一个粒子表征一组待寻优的识别模型参数。
步骤3,计算粒子群ap*l中每个粒子的适应度
通过新粒子与旧粒子适应度的竞争来对种群进行更新,若旧粒子的适应度小于新粒子的适应度,则用新粒子取代旧粒子;采用同样的竞争方式对全局最优位置进行更新;更新种群的同时保留全局最优位置粒子适应度用于进化方式的选择判断条件;所述的适应度f的计算公式为:
f=αerr(o,y)+(1-α)acc(o,y)式1
其中,α为动量因子,oi为训练样本集中第i个训练样本通过识别模型计算的输出值,yi为第i个训练样本的期望输出值,n为训练样本集中样本的组数,acc(o,y)为识别模型计算输出的正确率。
在所述的适应度计算过程中,第i个训练样本通过识别模型计算的输出值oi的计算方法包括:
(1)规范化训练样本集xn*m,其中训练样本共有n组,yn*c为对应的n组训练样本的输出,c为故障状态类数,采用一对多输出值的标记方式;
(2)确定隐含层神经元个数s以及激活函数为sigmoid,随机生成输入层与隐含层连接权重和隐含层神经元偏置值;
(3)计算隐含层神经元的输出矩阵h:
上式中,g(·)为激活函数sigmoid,w1…ws分别为s个输入层与隐含层连接权重,b1…bs为s个隐含层神经元偏置值,x1…xn指训练样本集xn*m中的n个训练样本;
(4)计算隐含层神经元与输出层神经元权重
上式中,h为输出矩阵,λ0为正则系数,i表示单位矩阵,上标t表示矩阵的转置,yn*c为n组训练样本的输出;
根据上面的计算可获得一组参数:输入层与隐含层连接权重w、隐含层神经元偏置值b、隐含层神经元与输出层神经元权重
则所述的第i个训练样本通过识别模型计算的输出值oi即为输出值矩阵o中的第i个值。
步骤4,选择粒子的进化方式,更新粒子的位置与速度,当达到设定的迭代次数时输出寻优结果
根据条件选择粒子的更新方式:当迭代次数t等于1时,采用更新方式1,否则采用更新方式2:
更新方式1:采用粒子群算法对种群进行位置与速度的更新;
更新方式2:采用萤火虫算法对种群进行位置更新,在计算时,一个萤火虫对应一个粒子,每个粒子携带了亮度l与吸引度b(i)两种信息:
l=-l0(rij-σ)2式6
其中,l0为粒子的最大发光亮度;rij为粒子i与光源j距离,距离采用euclidean计算方式进行计算;σ为亮度调整系数,γ为粒子荧光传播损耗系数,亮度较弱的粒子(萤火虫)向具有较强吸引度的粒子(萤火虫)移动,即当第i个粒子适应度小于第j个粒子适应度时,按式8和式9对粒子位置和速度进行更新,否则粒子位置不做更新:
xi(t+1)=xi(t)+b(i)(xj(t)-xi(t))+αeerr(t)(j=1,2,...,p)式8
vi(t+1)=xi(t+1)-xi(t)式9
其中,α为动量因子,结合进化过程训练误err(t)实现动态的步长调整;e为自然常数,p为粒子总数,xi(t)和xj(t)分别为粒子i和j在第t次进化的位置,xi(t+1)为粒子i在第t+1次进化的位置,err(t)为进化过程的训练误差,vi(t+1)为粒子i更新后的速度。可见,在群体中,粒子(萤火虫)会被亮度较亮的邻居所吸引,位置产生相应的移动,并且每一次的位移方向都会随着挑选的不同邻居而改变。当粒子所处邻域内密度低时,扩大搜索半径;当邻域内密度高时,搜索半径会缩小。通过这种方式实现粒子搜索域的自行调整,避免了搜索域盲目扩张或者缩小。
当迭代次数大于最大进化次数maxiter时,停止迭代,输出寻优结果;否则继续迭代过程,将迭代次数t加1,然后回到步骤3。
步骤5,将寻优结果作为识别模型参数,建立识别模型
经过步骤4的寻优最终输出的结果作为识别模型参数(w,b)进行变压器故障识别模型建模,并输入测试样本进行测试计算。
步骤6,利用识别模型进行变压器故障的识别
该步骤中,对识别模型测试输出结果与模型训练样本(特征字典)进行特征确认,再将确认的分类结果作为最终输出,具体包括:
取训练样本集xn*m作为特征字典,d={d1,d2,......,dc},其中c为样本类别数,即故障状态类别数;识别模型的测试输出yi为第i个未知类别测试样本,稀疏系数α与特征字典d、未确知分类样本之间的关系:
dkαk=yi(k=1,2,3......c)式10
式中,dk为第k个数据特征字典,由第k类训练样本构成;αk为第k类稀疏表示系数;yi为第i个未知类别测试样本;
计算满足阈值要求的稀疏系数
上式中,ε为最小容许残差;
计算残差r(yi),返回残差最小值所对应的特征字典项dk即yi所属类别:
可见,稀疏表示分类本质通过线性计算量化了测试样本输出值(输出类)与训练样本集的之间数据特征关联关系。关联度越高,残差rk(yi)越小,说明yi特征与dk越近似,认为yi所属类别为第k类。
实施例:
步骤1,建立样本集,确定识别模型的结构规模、预设参数;
采集变压器样本数据(x,y)共503组。x作为输入,所包含指标分别为h2、ch4、c2h2、c2h4、c2h6共五项,因此输入样本的属性长度m为5;y作为输出,对应输出状态类别数c为6,编码形式如表1所示。将样本数据集打乱,随机选取400组作为训练样本集(x_train,y_train),余下103作为测试样本集(x_test,y_test);
表1
确定识别模型的结构规模(5*100*6):根据输入样本的属性长度可确定模型输入神经元个数为5个;输出神经元个数为6个;根据试错法取隐含层神经元个数s取100个,以及隐含层激活函数g(x)为sigmoid函数;
对步骤1的样本数据进行标准化或归一化处理;相关预设参数还有:最大进化次数maxiter为500次;最大进化速度v_max和最小进化速度v_min分别取1和-1;迭代计数t取1;粒子最大发光亮度l0取值1;亮度调整系数σ取0.85;粒子荧光传播损耗系数γ取值0.9;动量因子α取随机数。
步骤2,根据所述识别模型的预设参数生成粒子群
根据识别模型大小随机生成粒子群a30*600,种群a由30个粒子构成,每个粒子长度为600,每个粒子为一组待寻优的识别模型参数(w,b);
步骤3,计算粒子群a30*600中每个粒子的适应度
通过新粒子与旧粒子适应度的竞争来对种群进行更新,若旧粒子的适应度小于新粒子的适应度,则用新粒子取代旧粒子;采用同样的竞争方式对全局最优位置进行更新;更新种群的同时保留全局最优位置粒子适应度用于进化方式的选择判断条件;所述的适应度f的计算公式为:
f=αerr(o,y)+(1-α)acc(o,y)式1
其中,α为动量因子,oi为训练样本集中第i个训练样本通过识别模型计算的输出值,yi为第i个训练样本的期望输出值,acc(o,y)为识别模型计算输出的正确率。
在所述的适应度计算过程中,第i个训练样本通过识别模型计算的输出值oi的计算方法包括:
(1)规范化输入样本x400*5,共400组样本,每个样本有5个属性;y400*6为400组样本对应的输出,表征6种状态,采用一对多输出值的标记方式,如表1所示;
(2)随机生成输入层与隐含层连接权重w100*5和隐含层神经元偏置值b100*1;
(3)计算隐含层神经元的输出矩阵h100*400:
(4)计算隐含层神经元与输出层神经元权重
其中λ0为正则系数,取值0.9;根据计算可获得一组参数输入层与隐含层连接权重w100*5、隐含层神经元偏置值b100*1、隐含层神经元与输出层神经元权重
步骤4,选择粒子的进化方式,更新粒子的位置与速度,当达到设定的迭代次数时输出寻优结果
根据条件选择粒子的更新方式:当迭代次数t等于1时,采用更新方式1,否则采用更新方式2:
更新方式2:采用萤火虫算法对种群进行位置更新,在计算时,一个萤火虫对应一个粒子,每个粒子携带了亮度l与吸引度b(i)两种信息:
l=-l0(rij-σ)2式6
其中,l0为粒子的最大发光亮度;rij为粒子i与光源j距离,距离采用euclidean计算方式进行计算;σ为亮度调整系数,γ为粒子荧光传播损耗系数,亮度较弱的粒子(萤火虫)向具有较强吸引度的粒子(萤火虫)移动,即当第i个粒子适应度小于第j个粒子适应度时,按式8和式9对粒子位置和速度进行更新,否则粒子位置不做更新:
xi(t+1)=xi(t)+bi(xj(t)-xi(t))+αeerr(t)(j=1,2,...,p)式8
vi(t+1)=xi(t+1)-xi(t)式9
其中,α为动量因子,合进化过程训练误差err(t)实现动态的步长调整;p=30,xi(t)和xj(t)分别为粒子i和j在第t次进化的位置,xi(t+1)为粒子i在第t+1次进化的位置,err(t)为进化过程的训练误差。可见,在群体中,粒子(萤火虫)会被亮度较亮的邻居所吸引,位置产生相应的移动,并且每一次的位移方向都会随着挑选的不同邻居而改变。当粒子所处邻域内密度低时,扩大搜索半径;当邻域内密度高时,搜索半径会缩小。通过这种方式实现粒子搜索域的自行调整,避免了搜索域盲目扩张或者缩小。
当迭代次数大于最大进化次数500时,停止迭代,输出寻优结果;否则继续迭代过程,将迭代次数t加1,然后回到步骤3。
步骤5,将寻优结果作为识别模型参数,建立识别模型
步骤4算法输最终出结果作为识别模型参数(w,b)进行变压器故障识别模型建模,并输入测试样本进行测试计算。
步骤6,利用识别模型进行变压器故障的识别
对识别模型测试输出结果与模型训练样本(特征字典)进行特征确认,再将确认的分类结果作为最终输出,具体包括:
取识别模型的训练样本作为特征字典d={d1,d2,......,d6}(共6个特诊字典),识别模型的测试输出yi={yi1,yi2,...,yi6}为第i个未确知分类样本,稀疏系数α与特征字典d、未确知分类样本之间的关系:
dkαk=yi(k=1,2,3......6)式10
式中,dk为第k个数据特征字典,由第k类训练样本构成;αk为第k类稀疏表示系数;yi为第i个未知类别测试样本;
计算满足阈值要求的稀疏系数
上式中,ε为最小容许残差,||·||1为l1范数。
计算残差r(yi),返回残差最小值所对应的特征字典dk即yi所属类别:
上式中,||·||2为l2范数。
实施例分析:
利用本发明所提一种基于混合智能算法构建的变压故障识别模型,将已知故障类型的503组数据,随机取400组数据作为训练样本,余下103组作为测试样本,利用训练样本进行模型参数寻优,并根据寻优输出结果建立变压器故障识别模型。利用测试样本对模型进行测试。结果表明,模式训练正确率91.26%。正确率比elm模型以及pso-elm模型高,且稳定性较好。
本发明利用fa算法和pso算法对elm模型参数进行优化,在参数优化基础上建立变压器故障识别模型。本发明方法中,采用了混合fa和pso的智能算法,既保留了pso计算简单、前期收敛速度快、泛化能力强的优点,又结合fa中,粒子(萤火虫)的决策域范围随着所处领域密度实现种群的自我多样性调节,避免搜索区域盲目扩张或者缩小的优点,维持了进化过程中粒子的多样性,提高了混合算法的全局寻优与局部搜索能力。本发明方法中,利用fa-pso对变压器故障识别elm模型参数进行寻优,有效提高了elm故障识别模型的正确率与计算稳定性;本发明方法还结合稀疏表示分类的方法对fa-pso-elm模型的输出值进行再分类确认,进一步提高了模型识别正确率。
该模型能计算简单,泛化能力强,不受数据规模的限制,人为影响因素少,可通过对数据的自学习与推理能力实现智能化的判断。
- 还没有人留言评论。精彩留言会获得点赞!