基于最大似然回归树的地铁事故延误时间预测方法与流程
本发明涉及交通领域,具体涉及地铁事故延误分析及预测方法。
技术背景
由突发事件、供电故障等多种因素造成的地铁事故可能导致地铁运输能力暂时下降,给乘客带来巨大损失,尤其是对通勤者带来延误损失。地铁是城市公共交通的重要交通方式,减轻地铁事故带来的影响很重要。
地铁管理部门需要实施有效的管理措施,尽快处理地铁事故。快速清除地铁事故通常需要有效地分配相关资源,以便及时分派工作人员。为了达到这一目标,需要建立一个模型来全面探索地铁事故的影响因素,并预测地铁事故造成的延误。通勤者的出行可能受到外部影响因素的影响,向公众提供地铁事故延误信息可以提醒乘客重新安排行程。因此,准确预测地铁事件延误,并确定地铁事故延误是否可接受至关重要。
目前,诸如加速失效时间(aft)模型等许多参数模型都被用来预测高速公路事故延误。然而,参数模型具有事先定好的函数形式和假设条件,地铁事故一般不满足该条件,尤其是考虑到大量影响因素的情形。为了消除参数模型的缺点,许多研究人员提出了估计地铁或高速公路事件延迟的非参数模型。但需要指出的是,这些非参数模型难以计算影响因素对事故延误的边际效应,而这些边际效应对于工作人员确定减少地铁事故延误的各影响因素的先后顺序很有帮助。在地铁事故延误中,这些变量可能和其他变量之间存在相互作用。因此,准确识别地铁事故延误中相互作用的变量很重要。
技术实现要素:
本发明的目的在于准确预测地铁事故延误以及地铁事故延误超出最大承受范围的概率,为乘客重新规划行程提供基础信息。
本发明提供的基于最大似然回归树的地铁事故延误时间预测方法是这样实现的,主要包括以下步骤:
s1.历史数据收集并处理。收集某一特定统计期内目标地铁交通系统的事故数据,并将其按照地铁事故发生的日期、地铁线路、事故起因以及地铁事故延误时间等类别进行分类梳理。
s2.描述性统计分析。对收集的地铁运营事故延误数据及地铁事故发生日期、发生时间、供电故障、车门故障等自变量进行描述性统计分析,研究数据的分布特点,确定数据分布形式,为研究模型的选取提供依据。
s3.模型建立。包括两个阶段:建树和剪枝。将样本分为两部分,随机选取80%的数据作为训练样本,用于初始树形结构的构建,剩余20%的数据作为检验样本,用于初始树形结构的剪枝,得到最优树形结构。
s3-1.建树:
(1)对于具有nk个样本观测数量的节点k,计算预测模型(aft模型)的参数
(2)对于具有m个解释变量的集合x=(x1,x2,...,xm),给定xi,i=1,2,...,m,让其与变量xj,j=1,2,...,m进行组合,根据变量xi和xj组合的所有取值情况来搜寻所有可能的分裂方案。单变量分裂是双变量分裂的一种特殊情形,即xi=xj。设xi和xj的取值个数分别为h和p。双变量分裂产生的所有可能的分裂方案可以表示为:
节点k处由分裂方案
对分裂方案集sij的穷举搜索,最终可以找到对数似然值增量最大的最优方案
(3)对于给定变量xi,通过步骤(2)可以找到其最佳配对变量
(4)在对所有变量组合进行搜索后,通过搜寻总体对数似然值最大增量可以得到总体最优分裂方案
(5)若
(6)当满足以下两个分裂停止规则的其中一个时,停止建树:
(a)底部任意一个节点有
(b)当前树形结构的深度达到了阈值。
否则,返回步骤(1)。
s3-2.剪枝:
采用复杂成本剪枝算法对树形结构进行修剪,移除对预测准确度无贡献的分支;使用赤池信息量准则(aic)来代表最大似然回归树t的成本,最小化aic值,生成最优树。其中,树t的aic值表示为:
(1)对于初始树tj,设k是其内部节点,且k具有叶节点,tk表示以k为根节点的子树,tj-tk表示从初始树tj剪掉子树tk(节点k保留)。计算树tj和tj-tk的aic值,得到aic(tj)和aic(tj-tk);
(2)对树tj自下向上寻找所有可能的节点k,将其记作集合k,重复步骤一的操作,求出相应的aic(tj-tk),k∈k,从中找出最小的aic(tj-tk),并将此节点记为k*,则有:
(3)比较
s4.模型校验。将训练样本和检验样本分别应用于传统单变量分裂的最大似然回归树模型,计算对数似然值和aic值,并与双因素分裂的最大似然回归树模型进行比较,验证模型的拟合优度。
s5.预测比对。基于步骤一收集到的数据,建立双因素分裂的最大似然回归树;在最优树形结构的每个叶节点处建立预测模型(aft模型),对香港地铁事故延误作出预测。
在一些实施方式中,步骤s2.所描述的自变量具体包括地铁事故发生日期、发生时间、供电故障、车门故障、车辆故障、紧急事件、信号故障、与坠落物或乘客发生碰撞、轨道故障、操作故障10个变量与地铁事故延误因变量。
在一些实施方式中,一种基于最大似然回归树的地铁事故延误时间预测方法,在模型建立前对于会对地铁事故产生交互作用的变量组合进行了相关识别。具体有工作日且非高峰期、周末或高峰期、无信号故障且无碰撞、信号故障或碰撞、有车门故障且无车辆故障、无车门故障或有车辆故障。
在一些实施方式中,在步骤s3.模型建立过程中使用最大似然回归树方法,并在每个叶节点上分配aft模型,使其具有更好的拟合优度并解释异质性效应。
该种基于最大似然回归树的地铁事故延误时间预测方法,在模型建立过程前假设一对变量(即使用两个变量)可以充分描述它们对地铁事故延误的影响,并且母节点的最佳分裂方案在由变量组合形成的所有可行方案中选取(即双变量分裂方案)。
模型建立之后采用复杂成本剪枝算法来进行树形结构的修剪,以移除对预测准确度无贡献的分支。
一种基于最大似然回归树的地铁事故延误时间预测方法,可应用于地铁事故相关因素影响分析,其中,主要利用了基于双因素分裂的最大似然回归树模型可降低地铁事故延误影响因素之间的交互作用的影响,并能够用来预测地铁事故延误超出承受能力的概率。
与现有技术相比,本发明提供的基于最大似然回归树的地铁事故延误时间预测方法在检验数据上具有更高的拟合优度,对于地铁延误事故的预测更为准确。
附图说明
为了更清楚地说明本发明实例或
背景技术:
中的技术方案,下面对本发明实例或背景技术中所需要使用的附图进行说明。
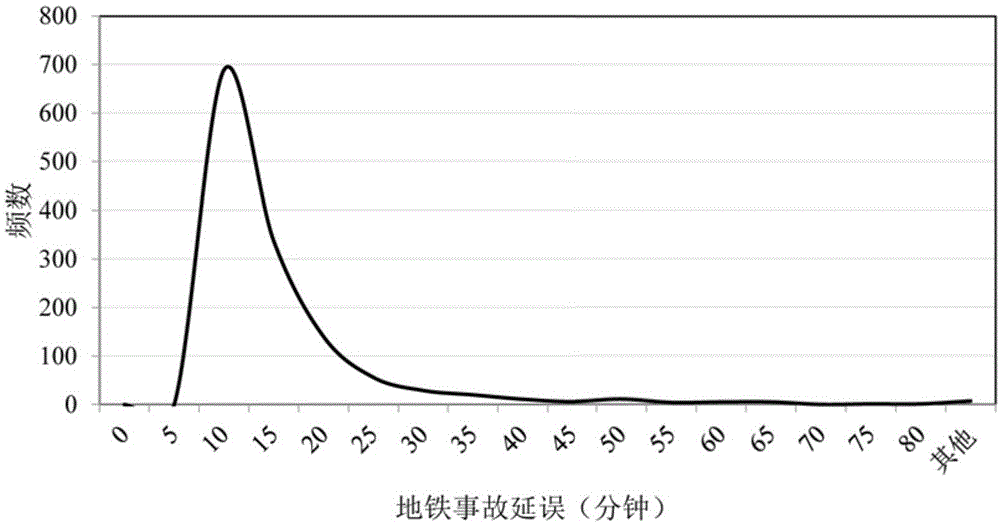
图1是本发明实施例统计分析2005-2012年香港地铁事故延误数据后提供的地铁运营事故延误分布折线图。
图2为本发明实施例提供的变量组合对地铁事故延误的影响。
图3为本发明实施例提供的广义似然回归树构造流程图。
图4为本发明实施例提供的广义似然回归树建树过程。
图5为本发明实施例提供的广义似然回归树和aft模型。
图6为本发明实施例提供的地铁事故延误超过最大承受值的概率。
具体实施方式
以下以香港地铁2005年至2012年的事故数据,进一步说明本发明方法。
本发明提供的基于最大似然回归树的地铁事故延误时间预测方法,应用于香港地铁事故延误预测与分析的具体方法如下:
s1.根据香港立法会公布的数据,收集香港地铁2005年至2012年的事故数据,并将其按照地铁事故发生的日期、地铁线路、事故起因以及地铁事故延误时间等类别进行分类梳理,并确定地铁运营事故延误分布。如图1所示。
s2.对所分类梳理完成的1332条地铁运营事故数据中的地铁事故发生日期、发生时间、供电故障、车门故障等自变量进行描述性统计分析。
表1变量描述
s3.对上述地铁事故发生日期、发生时间、供电故障、车门故障、车辆故障、紧急事件、信号故障、与坠落物或乘客发生碰撞、轨道故障、操作故障进行单因素方差分析。
表2地铁事故延误单因素方差分析结果
分析多种变量交互作用对于地铁事故延误的影响,准确识别会对地铁事故产生交互作用的变量组合。车辆故障可能和车门故障对于地铁事故延误的交叉作用如附图2所示。
s3.选取80%的数据进行初始树形结构的建立,20%的数据用于初始树形结构的剪枝,得到最优树形结构,从而建立基于双因素分裂的最大似然回归树模型。如附图3所示,具体采用如下步骤进行模型构建:
a.对于给定节点k,我们可以计算aft模型的参数
b.假设解释变量数量为m个,并且解释变量集表示为x=(x1,x2,...,xm)。对于给定的xi,i=1,2,...,m,它将会与其他变量xj,j=1,2,...,m进行组合,根据变量xi和xj组合的所有取值情况来搜寻所有可能的分裂方案。需要注意的是,单变量分裂是双变量分裂的一种特殊情形,即xi=xj。设xi和xj的取值个数分别为h和p。双变量分裂产生的所有可能的分裂方案可以表示为:
其中,
节点k处由分裂方案
其中,kr和kl分别表示母节点k的右子节点和左子节点。只有
c.对于给定变量xi,通过步骤b可以找到其最佳配对变量
d.在对所有变量组合进行搜索后,通过搜寻总体对数似然值最大增量可以得到总体最优分裂方案
e.如果
f.当满足以下两个分裂停止规则的其中一个时,停止建树:(a)底部任意一个节点有
g.采用复杂成本剪枝算法来进行树形结构的修剪,移除对预测准确度无贡献的分支。使用赤池信息量准则(aic)来代表最大似然回归树t成本,树t的aic值可表示如下:
从最大的初始树tj开始,并且确定一棵母节点h不包含任何后代节点的子树,记作tj-th。如果对于新数据(即检验数据),这棵子树用一个叶节点代替能够降低树形结构整体的aic值(即aic(tj-th)<aic(tj)),那么就相应的进行剪枝。当用叶节点代替子树不能使树形结构的aic值减小时,停止剪枝过程。
附图4描述了叶节点数量和训练数据的负对数似然值以及检验数据的aic值之间的关系,最终选取来预测地铁事故延误的最大似然回归树包含13个叶节点。
附图5显示剪枝后所选的最终树的树形结构,其可被直观解释如下:
根节点的初始分裂是基于车门故障和紧急事件两个变量。树形结构将不涉及车门故障和紧急事件的地铁事故分到左侧形成node1,将涉及车门故障或紧急事件的地铁事故分到右侧形成node2。后继续将node1分裂为nodes3和4。根据高峰期是否有紧急事件发生,node2被分裂为node5和leafnode1。当13个叶节点中的数据不能继续划分时,树形结构停止分裂。
采用后向消除法来选择叶节点的aft模型的变量。附图5给出了由最大似然估计法得到的每个叶节点aft模型的参数,leafnode5中的地铁事故延误只受轨道故障的影响,但是leafnode2中的地铁事故延误同时受轨道故障和信号故障的显著影响。
s4.根据训练数据和检验数据,构建9个不同分布的传统aft模型,例如对数正态分布、对数逻辑斯谛分布、伽玛分布、威布尔分布,以及具有伽玛异质性的威布尔分布。
构造一棵基于传统的单变量分裂的最大似然回归树,对所构造模型进行对比验证。
表3训练数据模型拟合优度对比
表4检验数据模型拟合优度对比
在双因素分裂最大似然回归树预测模型的基础上构造累积分布函数的互补函数,它表示地铁事故延误超过地铁站最大承受值d的概率,具体如下:
假设工作日高峰期有地铁事故发生。该事故由操作故障引起,并涉及道岔故障。根据该地铁事故特征,沿着树的路径进行追踪可以发现,叶节点5的aft模型可以用来描述该地铁事故延误的分布情况。
附图6显示了地铁事故延误超过最大承受值的概率。
- 还没有人留言评论。精彩留言会获得点赞!