中文错字检测方法及系统与流程
本发明涉及语言处理技术领域,具体涉及一种中文错字检测方法及系统。
背景技术:
信息化社会下,中文书写大量通过电脑处理,中文文字可以录入到电脑的方法主要有三种:拼音输入法、五笔输入法、ocr扫描。每天通过电脑处理的中文文字数以千亿计算,各种输入法和ocr扫描会产生大量的错别字问题,包括同音字问题、多音字问题、音近字问题、形近字问题、多字、少字、词语搭配不对、历史文化常识性错误、语法搭配错误、标点符号错误等,错别字问题长期广泛存在,对人们的工作和生活带来极大影响,例如,经济合同里的错别字可能会导致巨大的商业损失,知名公众人物的错别字问题可能会影响其发展前途,高考作文里的错别字也一定会影响到学生的升学成绩,政府网站、新闻媒体里的错别字甚至会造成政府公信力的丧失。
然而,目前的错别字处理方法不但复杂,而且效率低下,不能满足互联网大规模海量文本的实时处理需求。
技术实现要素:
本发明的目的在于提供一种中文错字检测方法及系统,可以提高错字处理效率。
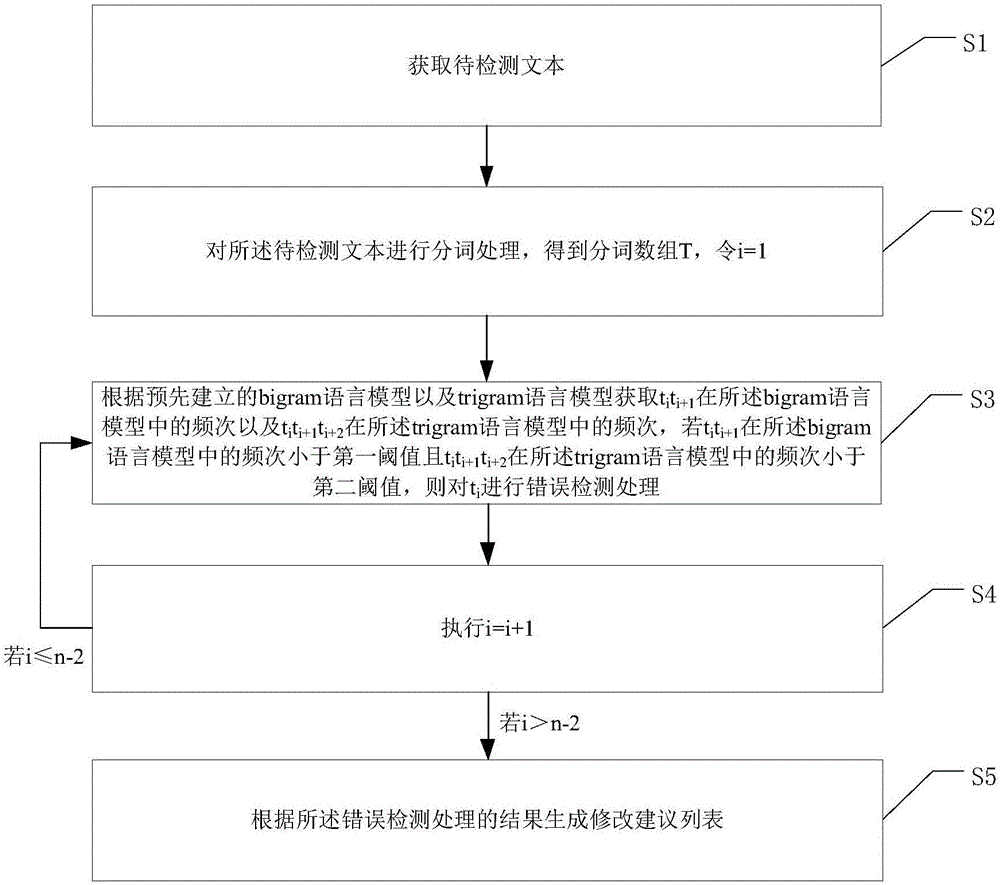
为实现上述目的,本发明的技术方案提供了一种中文错字检测方法,包括:
步骤s1:获取待检测文本;
步骤s2:对所述待检测文本进行分词处理,得到分词数组t=[t1,t2,t3,......,tn],令i=1;
步骤s3:根据预先建立的bigram语言模型以及trigram语言模型获取titi+1在所述bigram语言模型中的频次以及titi+1ti+2在所述trigram语言模型中的频次,若titi+1在所述bigram语言模型中的频次小于第一阈值且titi+1ti+2在所述trigram语言模型中的频次小于第二阈值,则对ti进行错误检测处理;
步骤s4:执行i=i+1,若i≤n-2,重复执行步骤s3,若i>n-2,执行步骤s5;
步骤s5:根据所述错误检测处理的结果生成修改建议列表。
进一步地,所述错误检测处理包括:
步骤a:判断ti+1与ti是否相同,若相同,则根据titi+1在所述bigram语言模型中的频次以及ti+1的词性对ti+1执行标记删除操作。
进一步地,所述错误检测处理还包括:
步骤b:对ti进行局部重搭配操作,并根据所述bigram语言模型以及所述trigram语言模型比较重搭配前与重搭配后的合理度。
进一步地,所述错误检测处理还包括:
步骤c:若ti、ti+1的结合或者ti、ti+1、ti+2的结合为4个字,则对所结合的4个字进行字或词的替换,并判断替换后的四个字是否为四字成语;
步骤d:根据预设的稀有姓氏表判断ti中是否存在稀有姓氏,若存在,则采用不识别姓名模式的分词算法对所述待检测文本再次进行分词处理,并对得到的分词数组进行错误检测流程。
进一步地,所述步骤s5包括:
按照预设的误报处理规则判断所述错误检测处理得到的错词的候选词是否为误报;
去除误报的候选词,在所述修改建议列表中将剩余的候选词标记为错词的推荐词。
为实现上述目的,本发明的技术方案还提供了一种中文错字检测系统,包括:
获取模块,用于获取待检测文本;
分词处理模块,用于对所述待检测文本进行分词处理,得到分词数组t=[t1,t2,t3,......,tn],令i=1;
错误检测处理模块,用于根据预先建立的bigram语言模型以及trigram语言模型获取titi+1在所述bigram语言模型中的频次以及titi+1ti+2在所述trigram语言模型中的频次,若titi+1在所述bigram语言模型中的频次小于第一阈值且titi+1ti+2在所述trigram语言模型中的频次小于第二阈值,则对ti进行错误检测处理;
执行模块,用于执行i=i+1;
结果生成模块,用于根据所述错误检测处理的结果生成修改建议列表。
进一步地,所述错误检测处理模块包括:
第一处理单元,用于判断ti+1与ti是否相同,若相同,则根据titi+1在所述bigram语言模型中的频次以及ti+1的词性对ti+1执行标记删除操作。
进一步地,所述错误检测处理模块还包括:
第二处理单元,用于对ti进行局部重搭配操作,并根据所述bigram语言模型以及所述trigram语言模型比较重搭配前与重搭配后的合理度。
进一步地,所述错误检测处理模块还包括:
第三处理单元,用于若ti、ti+1的结合或者ti、ti+1、ti+2的结合为4个字,则对所结合的4个字进行字或词的替换,并判断替换后的四个字是否为四字成语;
第四处理单元,用于根据预设的稀有姓氏表判断ti中是否存在稀有姓氏,若存在,则采用不识别姓名模式的分词算法对所述待检测文本再次进行分词处理,并对得到的分词数组进行错误检测流程。
进一步地,所述结果生成模块包括:
误报处理单元,用于按照预设的误报处理规则判断所述错误检测处理得到的错词的候选词是否为误报;
标记单元,用于去除误报的候选词,在所述修改建议列表中将剩余的候选词标记为错词的推荐词。
本发明提供的中文错字检测方法,可以解决现有错字检测方法计算复杂、效率低下的问题,有效提高错字处理效率,能够满足互联网大规模海量文本的实时处理需求,降低用户使用成本。
附图说明
图1是本发明实施方式提供的一种中文错字检测方法的流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
参见图1,图1是本发明实施方式提供的一种中文错字检测方法的流程图,该方法包括:
步骤s1:获取待检测文本;
步骤s2:对所述待检测文本进行分词处理,得到分词数组t=[t1,t2,t3,......,tn],令i=1,开始进行错误检测流程;
步骤s3:根据预先建立的bigram语言模型以及trigram语言模型获取titi+1在所述bigram语言模型中的频次以及titi+1ti+2在所述trigram语言模型中的频次,若titi+1在所述bigram语言模型中的频次小于第一阈值且titi+1ti+2在所述trigram语言模型中的频次小于第二阈值,则对ti进行错误检测处理;
步骤s4:执行i=i+1,若i≤n-2,重复执行步骤s3,若i>n-2,执行步骤s5;
步骤s5:根据所述错误检测处理的结果生成修改建议列表。
其中,在本发明实施方式中,所述步骤s5包括:
按照预设的误报处理规则判断所述错误检测处理得到的错词的候选词是否为误报;
去除误报的候选词,在所述修改建议列表中将剩余的候选词标记为错词的推荐词。
本发明实施方式提供的中文错字检测方法,可以解决现有错字检测方法计算复杂、效率低下的问题,有效提高错字处理效率,能够满足互联网大规模海量文本的实时处理需求,降低用户使用成本。
具体地,首先进行预处理过程,包括步骤1.1~步骤1.4;
步骤1.1:对gb18030中定义的汉字,机器统计其同音字;同时考虑键盘上字母布局,统计每个字的近音字,比如kai、lai、kao、lao这四个拼音在键盘布局上是非常接近的,通过上述方式构造一个汉字的“拼音混淆集”;
步骤1.2:对gb18030中定义的汉字,机器统计其形近字,比如“习”、“刁”是字形接近的汉字,通过该方式构造一个汉字的“字形混淆集”;
步骤1.3:对步骤1.1和步骤1.2中的字,按汉字字频排序,形成每个汉字的“单字混淆集”;
步骤1.4:通过大规模爬虫抓取(如抓取中央和省级报纸、官方网站、知名商业媒体文章)、网页文章自动抽取技术,建立文章素材库,使用中文分词技术对素材库中文章进行分词;
之后统计词与词之间的二元配对关系bigram、三元配对关系trigram,建立bigram语言模型以及trigram语言模型,例如:中国_人民_站_起来_了,bigram语言模型有:中国^人民,人民^站,站^起来,起来^了;trigram语言模型有:中国^人民^站,人民^站^起来,站^起来^了,bigram语言模型中可超过2000万对,trigram语言模型中可超过4亿对,其中,统计bigram语言模型中所有二元配对的词频总数,表示为total2;统计trigram语言模型中所有三元配对的词频总数,表示为total3;寻找第一阈值r2,使得bigram语言模型中词频>r2的所有二元配对的频次≥totoal2*k;寻找第二阈值r3,使得trigram语言模型中词频>r3的所有三元配对的总频次≥totoal3*k,其中k是(0,1)之间的一个常数,可以取k在范围[0.8,0.99],设置第一阈值r2和第二阈值r3的目的,是为了减少文章中要纠错的处所,提高算法的执行效率;
另外,对素材库中所有文章的所有分词结果,按同音词、音近词进行统计,以词的拼音为主键、词的序列为值,建立同音词倒排索引,得到同音库,例如,tongyi:[统一,同意,同一,同义,........];
再有,对素材库的文章进行依存语法分析,存放到依存树统计库中,例如,对于句子“我吃过饭了”,依存树分析结果为:我^吃,主谓关系;吃^饭,动宾关系;吃^过,动补关系;吃^了,动补关系;过^了,状态关系,将这些结果统计起来,主键是类似“我^吃:主谓关系”,值是出现频次;
之后可以利用上述预处理得到的结果对待检测文本进行错字检测,具体过程如下:
步骤2.1:对于要纠错的文章(即待检测文本),先进行分词处理,将分词结果表示为分词数组t=[t1,t2,t3,......,tn];
顺序遍历数组t,若titi+1在bigram语言模型中的频次<第一阈值r2,且titi+1ti+2在trigram语言模型中的频次<第二阈值r3,1≤i≤n-2,则对ti进行错误检测处理,其中,r2和r3越大,漏报率越低,检测速度越慢;r2和r3越小,漏报率越高,检测速度越快,其中,错误检测处理包括:
步骤a:判断ti+1与ti是否相同,若相同,则根据titi+1在所述bigram语言模型中的频次以及ti+1的词性对ti+1执行标记删除操作;
即进行叠词处理过程,对当前词ti,如果ti+1与ti相同,且ti是形容词、副词、拟声词中的一种,同时bigram(ti^ti+1)<r2*2,则ti+1非常可能是多余的叠词,执行标记删除操作,其中,bigram(ti^ti+1)为titi+1在bigram语言模型中的频次;
对当前词ti,如果ti+1与ti相同,且ti是名词、动词中的一种,同时bigram(ti^ti+1)<r2/2,则ti+1非常可能是多余的叠词,建议删除,执行标记删除操作;
如果ti+1与ti相同,且ti+1是其他虚词(如连词、介词、助词等),建议删除,执行标记删除操作。
步骤b:对ti进行局部重搭配操作,并根据所述bigram语言模型以及所述trigram语言模型比较重搭配前与重搭配后的合理度;
具体地,可以对前后、前中后的词,进行合并、替换(按步骤1.3中的单字混淆集、步骤1.4中词的同音库进行查错替换,寻找概率最高的混淆字/词)、换位、删字中的至少一种操作,构造新的字/词,对新的字词,再检查前后的ngram搭配,通过局部二、三元ngram搭配关系计算新字/词的局部搭配得分(也即合理度),如果新搭配的合理度>>原来搭配的合理度,说明新的搭配更合理,纠错词可以接受,可以作为错词的候选词,其中,局部二、三员ngram搭配得分的计算公式为:
score(ti)=a1*pleft(ti|ti-1)+a2*pright(ti|ti+1)+a3*ptri(ti|ti-1ti+1)+
a4*pleft-tri(ti|ti-2ti-1)+a5*pright-tri(ti|ti+1ti+2);
其中,score(ti)为重搭配前的合理度,pleft(ti|ti-1)为ti-1ti的bigram概率(即在bigram语言模型中的概率),pright(ti|ti+1)为titi+1的bigram概率,ptri(ti|ti-1ti+1)为ti-1titi+1的trigram概率(即在trigram语言模型中的概率),pleft-tri(ti|ti-2ti-1)为ti-2ti-1ti的trigram概率,pright-tri(ti|ti+1ti+2)为titi+1ti+2的trigram概率,a1、a2、a3、a4、a5为预设系数,且a1+a2+a3+a4+a5=1;
例如,若重搭配将ti替换为tio,则将上述公式中的ti更换为tio以计算重搭配后的合理度;
步骤c:若ti、ti+1的结合或者ti、ti+1、ti+2的结合为4个字,则对所结合的4个字进行字或词的替换,并判断替换后的四个字是否为四字成语,尝试有无可能是成语;
步骤d:根据预设的稀有姓氏表判断ti中是否存在稀有姓氏,若存在,则采用不识别姓名模式的分词算法对所述待检测文本再次进行分词处理,并对得到的分词数组进行错误检测流程;
具体地,如果ti被分词标记为姓名(词性是nr),检查姓名词的姓氏部分,是否是稀有姓氏(如没有在中国人常见姓氏的前100名的姓氏可认为是稀有姓氏),如果是,设置分词算法不识别姓名再次分词,对当前句子再进行一轮上述的错误检测流程;
通过上述错误检测处理可以找到若干个错词的候选词,通过对得到的候选词进行误报过滤处理,可以进一步地降低误报,具体地,对候选词,要计算候选词和当前句子中主要成分词(主谓宾定)的关联关系是否合理,其实现办法是通过神经网络依存树算法和词向量结合的方式,判断候选纠错词是否可接受,具体地,若原词和前序词(可以紧邻,可以不紧邻)存在主谓关系,候选词破坏了主谓关系,标记候选词可能为误报;若原词和后序词(可以紧邻,可以不紧邻)存在动宾关系,候选词破坏了动宾关系,标记候选词可能为误报;若原词和前、后词(可以紧邻,可以不紧邻)存在并列关系,候选词破坏了并列关系,标记候选词可能为误报;若原词和前、后词(可以紧邻,可以不紧邻)的搭配关系在预先建立的依存树统计库中的频率非常高,候选词和前、后词(可以紧邻,可以不紧邻)的搭配关系频率没有显著上升,则标记的候选词可能为误报;
通过上述方式去掉误报后的候选词,之后在修改建议列表中将剩余的候选词标记为错词的推荐词;
本发明实施方式提供的中文错字检测方法具有以下优点:
1、通过机器学习技术,可以主动发现中文语义搭配规律、语法规律,能够自动学习、自动训练、智能进化,快速迭代以提升算法的准确率和召回率;
2、可以智能跟踪互联网上的新词语、新的语法表述,快速收录到算法知识库;
3、解决现有算法计算复杂、效率低下的问题,处理速度可以达到现在主流错别字检测技术的100倍以上,普通4核8g内存的电脑可以达到20万字/秒,进而满足互联网海量信息高速实时处理的需求,降低用户使用成本;
4、可以快速应用到不同的行业,比如政府行文、大众传媒、出版社、武装部队、商业企业等,此外,在学生作文/论文写作、各种知识工作者日常工作中,也可以方便地使用本发明中的技术方案实现快速检测错别字。
例如,本发明的实际应用可以采用以下两种模式:
1、基于saas服务的api接口模式,任何客户可以快速在自己产品里集成云查错错别字检测功能;
2、基于chrome浏览器的插件形式,用户安装一次插件,以后在浏览网页、在网页写作时,都可以进行错别字检测,使用简单方便。
本发明可以实现网络信息自动采集、自动学习、自动验证模型、自动更新部署模型的全自动流程,无需人工干预,对互联网新的词语和表述可以快速发现和学习应用,因为具备持续的自动学习能力,算法的准确性可以持续快速提升,在生产环境实际测试,其漏报率<5%,准确率>83%,远远高于市场上现有错别字检测技术的水准。
此外,本发明实施方式还提供了一种中文错字检测系统,包括:
获取模块,用于获取待检测文本;
分词处理模块,用于对所述待检测文本进行分词处理,得到分词数组t=[t1,t2,t3,......,tn],令i=1;
错误检测处理模块,用于根据预先建立的bigram语言模型以及trigram语言模型获取titi+1在所述bigram语言模型中的频次以及titi+1ti+2在所述trigram语言模型中的频次,若titi+1在所述bigram语言模型中的频次小于第一阈值且titi+1ti+2在所述trigram语言模型中的频次小于第二阈值,则对ti进行错误检测处理;
执行模块,用于执行i=i+1;
结果生成模块,用于根据所述错误检测处理的结果生成修改建议列表。
其中,在本发明实施方式中,所述错误检测处理模块包括:
第一处理单元,用于判断ti+1与ti是否相同,若相同,则根据titi+1在所述bigram语言模型中的频次以及ti+1的词性对ti+1执行标记删除操作。
其中,在本发明实施方式中,所述错误检测处理模块还包括:
第二处理单元,用于对ti进行局部重搭配操作,并根据所述bigram语言模型以及所述trigram语言模型比较重搭配前与重搭配后的合理度。
其中,在本发明实施方式中,所述错误检测处理模块还包括:
第三处理单元,用于若ti、ti+1的结合或者ti、ti+1、ti+2的结合为4个字,则对所结合的4个字进行字或词的替换,并判断替换后的四个字是否为四字成语;
第四处理单元,用于根据预设的稀有姓氏表判断ti中是否存在稀有姓氏,若存在,则采用不识别姓名模式的分词算法对所述待检测文本再次进行分词处理,并对得到的分词数组进行错误检测流程。
其中,在本发明实施方式中,所述结果生成模块包括:
误报处理单元,用于按照预设的误报处理规则判断所述错误检测处理得到的错词的候选词是否为误报;
标记单元,用于去除误报的候选词,在所述修改建议列表中将剩余的候选词标记为错词的推荐词。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!