一种基于PAUC算法的农田智能喷药方法与流程
本发明涉及统计学习分类技术领域,尤其涉及一种基于pauc算法的农田智能喷药方法。
背景技术:
当今社会日新月异,科学技术的不断进步使人们的生活更加便利,农业作为国民经济的基础,其智能化的推进势在必行。农业智能化不仅能够有效改善农业生态环境,而且可以显著提高农业生产经营效率。相应地,智能喷药在农业智能化的推进过程中具有重要意义。
当前,人们通常采用大容量、雨淋式、全覆盖的方法给农作物喷药。但人工喷药通常难以避免以下弊端:1、整个作业环境都弥漫农药,极易造成施药人员中毒;2、人工喷药易造成喷药不均,对杂草喷药并无针对性,药物利用率低,易造成农药浪费;3、喷药效率较低,人工喷药需耗费较大的人力及时间。而当前已经存在的自动喷药设备仍无法避免喷药不合理、操作复杂以及药物浪费的缺点。究其原因,即为无法实时的识别出杂草进行针对性的喷洒,而pauc(partialareaundercurve)评估标准,能很好的度量不平衡二分类算法的整体性能,同时其原理在分类领域具有重要意义,因此在机器学习中受到广泛关注。因此,本发明提出了一种基于在线pauc分类算法的农田智能喷药方法。
技术实现要素:
基于背景技术存在的技术问题,本发明提出了一种基于pauc算法的农田智能喷药方法;
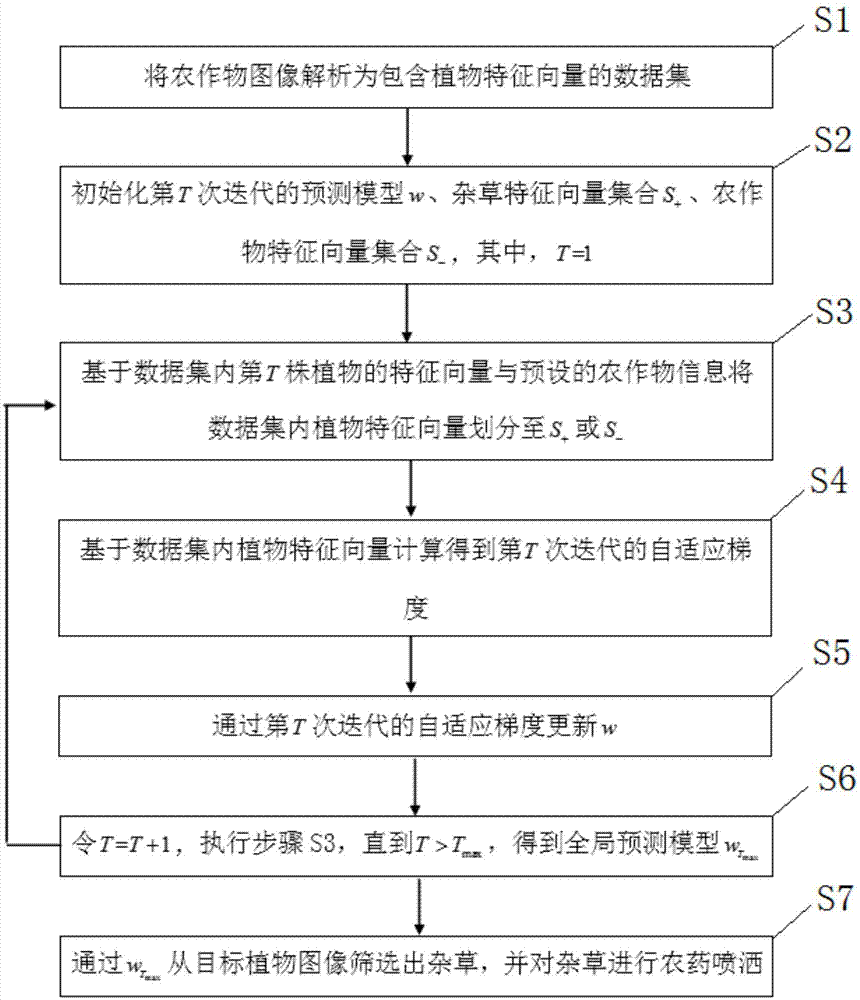
本发明提出的一种基于pauc算法的农田智能喷药方法,包括:
s1、将农作物图像解析为包含植物特征向量的数据集;
s2、初始化第t次迭代的预测模型w、杂草特征向量集合s+、农作物特征向量集合s-,其中,t=1;
s3、基于数据集内第t株植物的特征向量与预设的农作物信息将数据集内植物特征向量划分至s+或s-;
s4、基于数据集内植物特征向量计算得到第t次迭代的自适应梯度;
s5、通过第t次迭代的自适应梯度更新w;
s6、令t=t+1,执行步骤s3,直到t>tmax,得到全局预测模型
s7、通过
优选地,步骤s1,具体包括:
将农作物图像解析为包含植物特征向量的数据集,记为
优选地,步骤s2,具体包括:
定义迭代次数t=1,最大迭代次数为tmax,迭代过程中的排序间隔数为k,杂草特征向量集合s+、农作物特征向量集合s-,s+与s-大小为n的空集合,第t次迭代的预测模型w为一个d维的零向量wt。
优选地,步骤s3,具体包括:
s31、将第t株植物的特征向量xt与预设的农作物信息进行对比,当判定xt为杂草特征向量时,执行步骤s32;否则,执行步骤s34;
s32、当前s+集合中杂草特征向量的数目n+小于n时,将xt放入s+中,记录s+中n+=n++1,若n+=n,则随机将杂草特征向量集合中一株杂草特征向量删除,将xt存入集合s+中;
s33、计算杂草整体特征向量
s34、当前s-集合中农作物特征向量的数目n-小于n时,将xt放入s-中,记录s-中n-=n-+1,计算农作物整体信息特征向量
s35、计算t=tmodk,判断t=0是否成立,若成立,则执行步骤s36;否则,执行步骤s38;
s36、计算第t次迭代时第j个农作物信息
s37、对
s38、将
s39、将本次迭代识别出的农作物特征向量xt与杂草整体特征信息向量xpos进行求差计算,得到第t次迭代的植物特征向量x*=xpos-xt,执行步骤s4。
优选地,步骤s4,具体包括:
s41、定义损失函数l(wt,x*)=max{0,1-wt·x*};
s42、对l(wt,x*)求偏导,利用随机梯度下降法得到第t次迭代的梯度gt;
s43、对前t次迭代的梯度求二范数的平方vt,得到第t次迭代的自适应步长
s44、通过结合第t次迭代的自适应步长
优选地,步骤s5,具体包括:通过
本发明使用在线分类算法进行迭代处理,每次只需要接收并处理一个训练样本,以此更新分类模型,其仅需保留对构建分类模型有用的部分信息或者部分具有训练意义的样本,其他的信息全部抛弃,并在训练过程中能够实时更新分类模型,进而高效的识别出杂草进行针对性的农药喷洒,因此非常适用于农药喷洒的场景在迭代训练过程中,使用杂草与农作物信息特征向量的差值得到的新的迭代训练特征向量参与迭代,避免了单个植物信息对预测模型的干扰,从而保证了每一次的迭代过程对于预测模型的优化都有意义,利用pauc算法能够快速实时的识别出当前的杂草,同时随着喷药过程的不断进行其对杂草的识别率将越来越高,然后对杂草进行针对性的喷药操作,避免了农药的过度使用造成的农作物药物残留;减少了喷药过程中农药弥漫的程度,降低了工作人员中毒的风险。
附图说明
图1为本发明提出的一种基于pauc算法的农田智能喷药方法的流程示意图。
具体实施方式
参照图1,本发明提出的一种基于pauc算法的农田智能喷药方法,包括:
步骤s1,将农作物图像解析为包含植物特征向量的数据集,具体包括:将农作物图像解析为包含植物特征向量的数据集,记为
在具体方案中,可以通过摄像头实时拍摄农作物图像,对农作物图像进行图像处理,解析为包含植物特征向量的数据集,植物特征向量对应的植物特征信息包括颜色、叶片长度、叶片形状、有无花朵、花朵颜色等等。
步骤s2,初始化第t次迭代的预测模型w、杂草特征向量集合s+、农作物特征向量集合s-,其中,t=1,具体包括:
定义迭代次数t=1,最大迭代次数为tmax,迭代过程中的排序间隔数为k,杂草特征向量集合s+、农作物特征向量集合s-,s+与s-大小为n的空集合,第t次迭代的预测模型w为一个d维的零向量wt。
在具体方案中,定义迭代过程中的排序间隔数为k,引入参数k,对不相关信息特征向量采取间隔k次迭代过程排序一次的方式,进而大幅度的节省了迭代训练时间。
步骤s3,基于数据集内第t株植物的特征向量与预设的农作物信息将数据集内植物特征向量划分至s+或s-,具体包括:
s31、将第t株植物的特征向量xt与预设的农作物信息进行对比,当判定xt为杂草特征向量时,执行步骤s32;否则,执行步骤s34;
s32、当前s+集合中杂草特征向量的数目n+小于n时,将xt放入s+中,记录s+中n+=n++1,若n+=n,则随机将杂草特征向量集合中一株杂草特征向量删除,将xt存入集合s+中;
s33、计算杂草整体特征向量
s34、当前s_集合中农作物特征向量的数目n_小于n时,将xt放入s_中,记录s_中n_=n_+1,计算农作物整体信息特征向量
s35、计算t=tmodk,判断t=0是否成立,若成立,则执行步骤s36;否则,执行步骤s38;
s36、计算第t次迭代时第j个农作物信息
s37、对
s38、将
s39、将本次迭代识别出的农作物特征向量xt与杂草整体特征信息向量xpos进行求差计算,得到第t次迭代的植物特征向量x*=xpos-xt,执行步骤s4。
步骤s4,基于数据集内植物特征向量计算得到第t次迭代的自适应梯度,具体包括:
s41、定义损失函数l(wt,x*)=max{0,1-wt·x*};
s42、对l(wt,x*)求偏导,利用随机梯度下降法得到第t次迭代的梯度gt;
s43、对前t次迭代的梯度求二范数的平方vt,得到第t次迭代的自适应步长
s44、通过结合第t次迭代的自适应步长
步骤s5,通过第t次迭代的自适应梯度更新w,具体包括:通过
步骤s6,令t=t+1,执行步骤s3,直到t>tmax,得到全局预测模型
在具体方案中,在线分类算法进行迭代处理,每次只需要接收并处理一个训练样本,以此更新分类模型。在这个过程中,其仅需保留对构建分类模型有用的部分信息或者部分具有训练意义的样本,其他的信息全部抛弃,并在训练过程中能够实时更新分类模型。
步骤s7,通过
在具体方案中,利用pauc算法能够快速实时的识别出当前的杂草,同时随着喷药过程的不断进行其对杂草的识别率将越来越高,然后对杂草进行针对性的喷药操作,避免了农药的过度使用造成的农作物药物残留;减少了喷药过程中农药弥漫的程度,降低了工作人员中毒的风险。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!