带属性人脸图像生成方法、装置、系统及可读存储介质与流程
本发明涉及计算机视觉研究领域,特别涉及一种带属性人脸图像生成方法、装置、系统及一种计算机可读存储介质。
背景技术:
图像生成问题一直是国内外学者研究的主要问题之一,在深度学习研究领域中,多样性丰富的人脸图像数据集有较大的需求。如何利用生成图像技术扩充数据集,根据特定的属性条件生成符合条件的高清人脸图像是急需解决的问题之一。
目前,根据特定的属性条件进行人脸图像生成是基于属性标签进行图像生成的,比如预先设定一些属性标签,“男性”、“女性”、“金色头发”、“是否微笑”、“是否张嘴”等,根据挑选的属性标签生成对应的人脸图像。
而利用属性标签(例如5维属性二值标签向量:00100)作为图像生成的条件限制具有局限性。即图像的属性只能局限在所提供的标签范围内,属性多样性较差,而且通过属性标签进行属性的限定细节体现差、描述方式非日常化。
因此,如何根据文本细节描述,生成符合文本所描述属性的人脸图像,是本领域技术人员需要解决的技术问题。
技术实现要素:
本发明的目的是提供一种带属性人脸图像生成方法,该方法通过将描述文本转化为向量形式后,与输入图像进行通道级联,将属性描述与图像融合,消除文本描述与图像间的差异,利用深度学习中的生成对抗网络技术进行完整图像的还原,可以生成符合文本所描述属性的人脸图像;本发明的另一目的是提供一种带属性人脸图像生成装置、系统及一种计算机可读存储介质,具有上述有益效果。
本发明提供一种带属性人脸图像生成方法,包括:
接收人脸特征描述文本以及部分遮挡图像;
将所述描述文本输入至文本编码器网络,得到文本编码向量;
将所述文本编码向量以及所述部分遮挡图像进行通道级联,生成语义特征数据;
将所述语义特征数据输入至人脸图像生成模型中进行人脸特征还原,得到带属性的人脸图像;其中,所述人脸图像生成模型为根据文本数据集以及训练集图像训练优化得到的深度学习网络。
优选地,将所述语义特征数据输入至人脸图像生成模型中进行人脸特征还原包括:
将所述语义特征数据输入至基于生成式对抗网络的生成器进行人脸特征还原;
则所述人脸图像生成模型通过语义特征训练数据以及对应的原图训练得到具体为:
利用所述生成器根据输入的语义特征训练数据进行图像还原;
根据对应的原图,通过判别器进行还原图像的真实性评判,得到真实性概率;
根据所述真实性概率对所述生成器以及所述判别器进行参数优化。
优选地,根据所述真实性概率对所述生成器以及所述判别器进行参数优化包括:
根据所述真实性概率计算最小化损失函数;
根据所述最小化损失函数利用梯度下降法对所述生成器以及所述判别器进行优化。
优选地,将所述语义特征数据输入至基于生成式对抗网络的生成器进行人脸特征还原包括:
通过预训练的全局网络对所述语义特征数据进行全局特征还原,得到具有全局还原信息的特征矩阵;
通过预训练的局部网络将所述语义特征数据进行矩阵维度处理,将维度处理后的特征数据与所述全局特征矩阵进行信息叠加,并对叠加后的数据进行局部增强,得到细节优化的全局特征矩阵;
对所述细节优化的全局特征矩阵进行输出设置,得到还原图像,将所述还原图像作为所述带属性的人脸图像。
优选地,所述通过预训练的全局网络对所述语义特征数据进行全局特征还原,得到具有全局还原信息的特征矩阵后还包括:
预训练的全局网络通过全局残差网络对所述具有全局还原信息的特征矩阵进行全局深度优化,得到优化全局特征矩阵;
则预训练的局部网络将维度处理后的特征数据与所述全局特征矩阵进行信息叠加具体为:预训练的局部网络将维度处理后的特征数据与所述优化全局特征矩阵进行信息叠加。
优选地,对所述细节优化的全局特征矩阵进行输出设置前还包括:
预训练的局部网络将所述细节优化的全局特征矩阵输入至局部残差网络进行局部深度优化,得到优化矩阵;
则对所述细节优化的全局特征矩阵进行输出设置具体为:对所述优化矩阵进行输出设置。
本发明公开一种带属性人脸图像生成装置,包括:
信息接收单元,用于接收人脸特征描述文本以及部分遮挡图像;
文本编码单元,用于将所述描述文本输入至文本编码器网络,得到文本编码向量;
通道级联单元,用于将所述文本编码向量以及所述部分遮挡图像进行通道级联,生成语义特征数据;
特征还原单元,用于将所述语义特征数据输入至人脸图像生成模型中进行人脸特征还原,得到带属性的人脸图像;其中,所述人脸图像生成模型为根据文本数据集以及训练集图像训练优化得到的深度学习网络。
优选地,所述特征还原单元具体用于:将所述语义特征数据输入至基于生成式对抗网络的生成器进行人脸特征还原;
则网络优化单元包括:
训练还原子单元,用于利用所述生成器根据输入的语义特征训练数据进行图像还原;
训练评判子单元,用于根据对应的原图,通过判别器进行还原图像的真实性评判,得到真实性概率;
训练优化子单元,用于根据所述真实性概率对所述生成器以及所述判别器进行参数优化。
本发明公开一种带属性人脸图像生成系统,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现所述的带属性人脸图像生成方法的步骤。
本发明公开一种计算机可读存储介质,所述计算机可读存储介质上存储有程序,所述程序被处理器执行时实现所述带属性人脸图像生成方法的步骤。
为解决上述技术问题,本发明提供一种带属性人脸图像生成方法,该方法接收人脸特征描述文本以及部分遮挡图像,文本描述人脸属性的方式提供的属性多样性更丰富,且这种属性提供方式更符合人类的认知。将描述文本输入至文本编码器网络,得到文本编码向量;将文本编码向量以及部分遮挡图像进行通道级联,实现将文本属性描述与图像融合,生成语义特征数据,该数据中既包括人脸属性信息,又包括需要还原的图像信息;将语义特征数据输入至人脸图像生成模型中进行人脸特征还原,人脸图像生成模型为根据文本数据集以及训练集图像训练优化得到的人脸图像生成模型,训练后的人脸图像生成模型可以识别语义特征数据,根据文本细节描述,进行整体图像还原,可以生成符合文本描述属性的人脸图像。
另外,本发明另一实施例中公开了通过训练优化后的生成式对抗网络生成器进行图像还原这一技术特征,以深度学习的生成对抗网络为基础,采用渐进式网络架构,更有利于提高生成的人脸图像的真实性,且生成的人脸图像具有较高的图像分辨率。
本发明还公开了一种带属性人脸图像生成装置、系统及一种计算机可读存储介质,具有上述有益效果,在此不再赘述。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的局部图像特征提取方法的流程图;
图2为本发明实施例提供的一种全局残差网络结构示意图;
图3为本发明实施例提供的局部残差网络示意图;
图4为本发明实施例提供的生成器网络的结构示意图;
图5为本发明实施例提供的一种判别器结构示意图;
图6为本发明实施例提供的一种带属性人脸图像生成装置的结构框图;
图7为本发明实施例提供的网络优化单元与带属性人脸图像生成装置的连接示意图;
图8为本发明实施例提供的带属性人脸图像生成系统的结构示意图。
具体实施方式
本发明的核心是提供一种带属性人脸图像生成方法,该方法通过将描述文本转化为向量形式后,与输入图像进行通道级联,将属性描述与图像融合,消除文本描述与图像间的差异,利用深度学习中的生成对抗网络技术进行完整图像的还原,可以生成符合文本所描述属性的人脸图像;本发明的另一核心是提供一种带属性人脸图像生成装置、系统及一种可读存储介质,具有上述有益效果。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
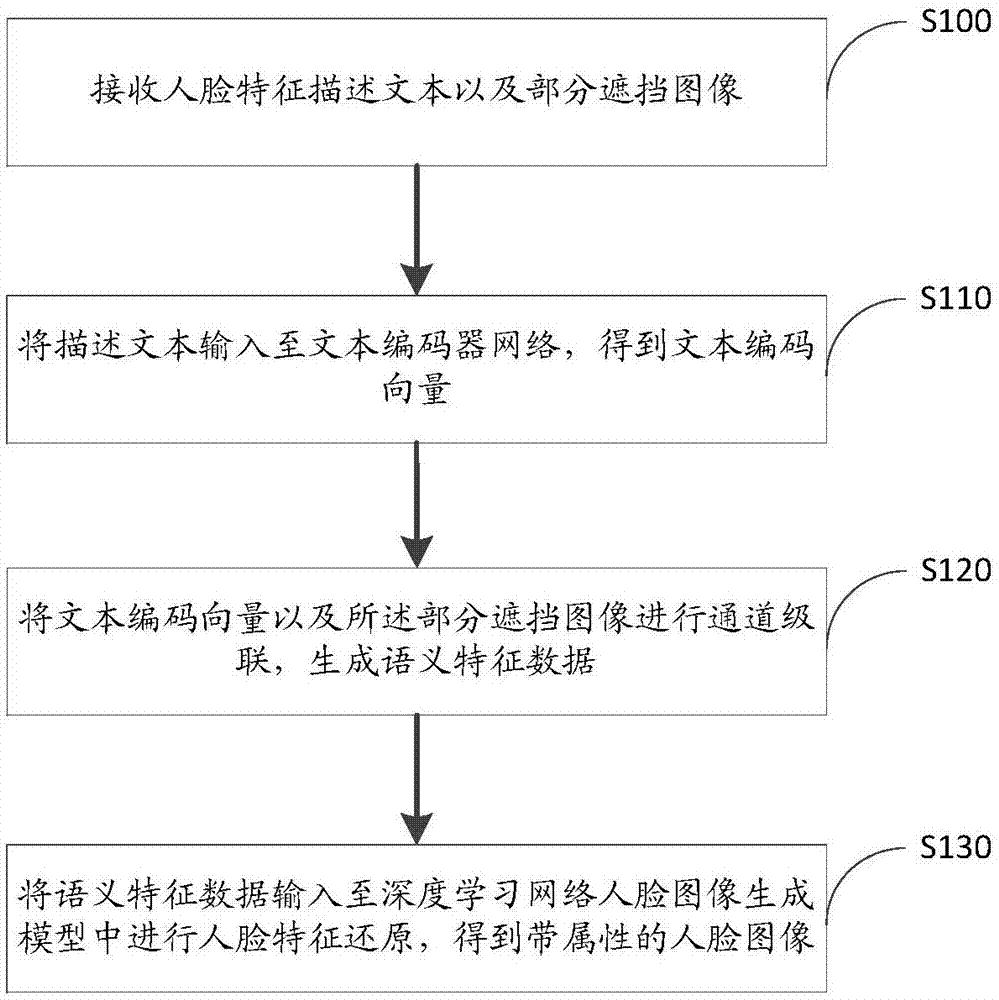
图1为本实施例提供的局部图像特征提取方法的流程图;该方法可以包括:
步骤s100:接收人脸特征描述文本以及部分遮挡图像。
人脸特征描述文本指描述人脸特征(比如五官、皮肤、外貌等)的文本,例如,一个有黑色齐肩短发鹰钩鼻丹凤眼的女人。相对于利用属性标签(例如5维属性二值标签向量:00100)作为人脸图像生成的条件的方式,通过文本描述人脸属性的方式所能提供的属性多样性更丰富,特征描述的细节性更强,且这种属性提供方式更符合人类的认知,符合人类对图片描述的表达方式与习惯。
部分遮挡图像指需要进行人脸图像还原的部分特征遮挡的基础人脸图像。部分遮挡图像可以由用户输入,对图像进行部分遮挡的实现方式不做限定,比如可以通过高斯噪声的掩码图替换原图中需要遮挡的部分,或者也可以利用可以实现图像遮挡处理的软件自动实现。本发明可以实现基于部分遮挡图像,依据文本描述人脸特征属性对遮挡部分进行图像还原,也可以实现依据文本描述人脸特征属性的人脸图像生成。
步骤s110:将描述文本输入至文本编码器网络,得到文本编码向量。
将描述文本输入到文本编码器网络中,得到固定维度的文本编码向量。本实施例对于文本编码器网络的结构类型不做限定,可参照现有文本编码器,例如可以采用用于解决序列转序列(seq2seq)问题中提出的编码-解码模型的编码结构部分。通过编码器网络将描述文本编码输出成一个固定大小的语义向量,该语义向量即为固定维度的文本编码向量。
步骤s120:将文本编码向量以及部分遮挡图像进行通道级联,生成语义特征数据。
将文本编码向量以及部分遮挡图像进行通道级联,实现将文本属性描述与图像融合,生成的语义特征数据中既包含了文本信息,又包含了被遮挡图像的信息,利用语义特征数据作为人脸图像生成模型的输入,可使得同时根据文本描述以及输入图像进行人脸图像的还原,最终生成的人脸图像既能符合文本描述,又能保留未遮挡部分的输入信息。
步骤s130:将语义特征数据输入至人脸图像生成模型中进行人脸特征还原,得到带属性的人脸图像。
人脸图像生成模型的具体结构不做限定,可以根据功能以及数据处理精确度需要对网络结构进行设置,固定网络结构后即可根据训练集图像以及文本数据集对人脸图像生成模型进行参数优化。
人脸图像生成模型为根据文本数据集以及训练集图像训练优化得到的人深度学习网络。深度学习是对人工神经网络的延伸,可以模拟人脑的机制来解释图像,通过自主学习以及深度特征提取形成更加高级的高层特征来表示属性和类别。训练过程中将语义特征训练数据(即文本数据集)、部分遮挡图像集以及对应的原图集输入至搭建好的人脸图像生成模型,根据语义特征训练数据以及部分遮挡图像集生成还原后的人脸图像,再根据原图对还原后的人脸图像进行分析比对,通过分析比对结果对人脸图像生成模型中各层参数进行修正及优化,直至还原结果达到预期,得到训练好的人脸图像生成模型。经过训练后的人脸图像生成模型可以自动实现对语义特征数据的识别与特征提取。
基于上述介绍,本实施例提供的带属性人脸图像生成方法,接收人脸特征描述文本以及部分遮挡图像,文本描述人脸属性的方式提供的属性多样性更丰富,且这种属性提供方式更符合人类的认知。将描述文本输入至文本编码器网络,得到文本编码向量;将文本编码向量以及部分遮挡图像进行通道级联,实现将文本属性描述与图像融合,生成语义特征数据,该数据中既包括人脸属性信息,又包括需要还原的图像信息;将语义特征数据输入至人脸图像生成模型中进行人脸特征还原,人脸图像生成模型为根据文本数据集以及训练集图像训练优化得到的人脸图像生成模型,训练后的人脸图像生成模型可以识别语义特征数据,根据文本细节描述,进行整体图像还原,可以生成符合文本描述属性的人脸图像。
上述实施例中对人脸图像生成模型的结构不做限定,优选地,可以选用基于生成式对抗网络的生成器进行人脸特征的还原。生成式对抗网络通过生成器与判别器对抗训练机制,无需在学习过程中进行推断,回避了近似计算棘手的概率的难题,能够使生成器不断逼近图像生成的最优性能,还原的照片噪声分布也能更逼近真实照片的分布,基于该机制得到的生成器进行图像的还原可以得到真实度更高的还原图像。
具体地,基于生成式对抗网络根据判别器对生成器进行训练的过程具体可以为:生成器根据输入的语义特征训练数据进行图像还原;根据对应的原图,通过判别器进行还原图像的真实性评判,得到真实性概率;根据真实性概率对生成器以及判别器进行参数优化。从而使得生成器网络随着训练生成能力越来越好,同时判别器的鉴别能力也越来越好。
优选地,为提高参数优化的效率,可以根据真实性概率计算最小化损失函数;根据最小化损失函数利用梯度下降法对生成器进行优化。
最小化损失函数值(loss)越小,生成器性能越好。要使得loss下降,通过梯度下降法反传梯度,其中,梯度反向传播是网络参数更新的方法,通过迭代实现。根据公式计算loss函数的值,从网络最后一层反向传播梯度更新网络每一层参数直到第一层,更新完全部参数一次后,根据网络输入再次计算loss函数的值,然后再反向传播梯度更新参数,再计算loss,再反向更新,不停迭代,更新网络(包括生成器网络和判别器网络)每一层的参数,也就是更新生成器和判别器网络每一层的参数,在迭代过程中loss值逐渐变小,最终收敛,此时生成器人脸图像生成能力强,判别器鉴别能力也更强。其它进行参数优化的方法在此不再赘述。生成器网络对整体图像进行图像还原,其中,为尽量降低网络结构的复杂度、减少计算数据量的情况下提高图像精度与还原程度。优选地,可以先通过生成器中的全局网络生成低分辨率全局特征数据,再通过局部网络在低分辨率基础上进行局部增强,生成高分辨率特征数据。通过这种先生成低分辨率特征数据再生成高分辨率特征数据的方式,不论在网络结构或是其他方面比直接生成一张高分辨率图像可能更容易实现。
则,将语义特征数据输入至基于生成式对抗网络的生成器进行人脸特征还原的过程具体可以包括以下步骤:
预训练的全局网络对语义特征数据进行全局特征还原,得到具有全局还原信息的特征矩阵;
预训练的局部网络将语义特征数据进行矩阵维度处理,将维度处理后的特征数据与全局特征矩阵进行信息叠加,并对叠加后的数据进行局部增强,得到细节优化的全局特征矩阵;
对细节优化的全局特征矩阵进行输出设置,得到还原图像,将还原图像作为带属性的人脸图像。
局部网络首先对语义特征数据进行矩阵维度处理,保持原本的信息,对生成的语义特征数据不做复杂处理,调整到与全局网络输出同样的维度,从而可以与全局网络的输出相加,进行下一步的局部增强,使得图像更精细,分辨率更高。最后通过输出设置调整将特征矩阵转换为现实意义上的一张生成图像。局部网络和全局网络分别用于对不同尺度(scale)的输入进行图像生成。例如,输入的尺度是原图的1024×1024×131尺寸经过下采样之后得到的,全局网络的输入尺寸可以只有一半,即512×512×131,此时全局网络的输出尺寸也是512×512×64。而局部网络在输入的尺度即原图的1024×1024×131时,输出尺寸可以为1024×1024×3。整个生成器网络结构中先采用普通卷积得到512×512×64,与全局网络生成512×512×64的全局特征矩阵相加,得到叠加的特征矩阵,将其作为还原得到的人脸特征矩阵。
为提高数据特征提取的精度,可能会多层叠加,当网络层数达到一定的数目以后,网络的性能就会饱和以及退化,为提高网络性能,可以通过残差网络增加网络深度,优化网络性能。具体地,当采用局部网络以及全局网络进行图像的还原时,优选地,为提高全局网络的深度,可以在全局网络中设置残差网络,将进行局部深度优化后得到优化矩阵输入至预训练的全局残差网络中,进行全局特征深度优化,得到优化全局特征矩阵。则预训练的局部网络将维度处理后的特征数据与全局特征矩阵进行信息叠加具体为:预训练的局部网络将维度处理后的特征数据与优化全局特征矩阵进行信息叠加。
具体地残差网络的网络结构与网络参数的设置不做限定,为加深对全局网络后接残差网络实现提升网络深度的理解,在此以图2所示的全局残差网络结构为例进行介绍,其它网络结构形式均可参照本实施例的介绍。
假设全局残差网络输入为a×b×c大小的图像,记为resinput,则:
(1)将a×b×c大小的输入图像i输入到残差网络第一个卷积层,采用1024个3×3的滤波器,使用1个像素的步长,使用1个像素的零补充,对残差网络的输入图像进行卷积操作,得到a×b×1024大小的卷积层输出图像。
(2)将(1)中最后卷积层的a×b×1024大小的输出图像输入到实例归一化层进行实例归一化,输出a×b×1024大小的实例归一化特征图像,并用relu激活函数激活,输出a×b×1024大小的激活图像。
(3)将(2)中最后输出激活图像的a×b×1024大小输入到残差网络第二个卷积层,采用1024个3×3的滤波器,使用1个像素的步长,使用1个像素的零补充,对(2)中最后输出的激活图像进行卷积操作,得到a×b×1024大小的卷积层输出图像。
(4)将(3)中最后卷积层的a×b×1024大小的输出图像输入到实例归一化层进行实例归一化,输出a×b×1024大小的实例归一化特征图像。
(5)将(4)中最后输出的a×b×1024大小的实例归一化特征图像与输入为a×b×c大小的图像resinput相加,得到大小为a×b×1024的残差网络输出图像,记为resoutput。经过残差网络输出的图像相比没有经过残差网络的输出图像真实度大大升高,图像的精确度也有较大的改善。
优选地,为提高局部网络对局部特征提取的性能,还可以在局部网络中设置残差网络,优选地,预训练的局部网络将细节优化的全局特征矩阵输入至局部残差网络进行局部深度优化,得到优化矩阵。则对细节优化的全局特征矩阵进行输出设置具体为:对优化矩阵进行输出设置。在此以图3所示的局部残差网络示意图为例进行介绍。
假设残差网络输入为a×b×c大小的图像,记为resinput2,则:
(1)将a×b×c大小的输入图像i输入到残差网络第一个卷积层,采用64个3×3的滤波器,使用1个像素的步长,使用1个像素的零补充,对残差网络的输入图像进行卷积操作,得到a×b×6大小的卷积层输出图像。
(2)将(1)中最后卷积层的a×b×64大小的输出图像输入到实例归一化层进行实例归一化,输出a×b×64大小的实例归一化特征图像,并用relu激活函数激活,输出a×b×64大小的激活图像。
(3)将(2)中最后输出激活图像的a×b×64大小输入到残差网络第二个卷积层,采用64个3×3的滤波器,使用1个像素的步长,使用1个像素的零补充,对(2)中最后输出的激活图像进行卷积操作,得到a×b×64大小的卷积层输出图像。
(4)将(3)中最后卷积层的a×b×64大小的输出图像输入到实例归一化层进行实例归一化,输出a×b×64大小的实例归一化特征图像。
(5)将(4)中最后输出的a×b×64大小的实例归一化特征图像与输入为a×b×c大小的图像resinput相加,得到大小为a×b×64的局部特征提取卷积神经网络部分中残差网络的最终残差网络输出图像,记为resoutput2。
通过在得到整体还原后将图像输入至局部残差网络,既不会改变局部网络所生成图像的大小的同时,大大改善了局部网络生成图像的精度。
为便于理解,本实施例对生成器网络的训练的具体过程进行介绍,具体地,以生成式对抗网络训练生成器为例,其它情况均可参照本实施例的介绍。训练过程具体可以包括:
步骤一:对人脸图像数据集中1024×1024×3大小的rgb人脸图像进行预处理,同时对人脸图像对应的文本数据集中的文本进行预处理,划分为训练集和测试集。
人脸数据集图像的图像像素大小为1024×1024×3,每幅图像对应一句话文本描述,文本描述内容例如“一个有着金色短发三角形眼睛高鼻梁大嘴巴的中年男人”。将数据集图像和文本对按4:1的比例分为训练集和测试集。
将训练集中真实人脸图像x均匀分为4×4的方格区域,将位于中心的第二三行的各自三四列的方格区域共512×512大小的图像区域设置为掩模区域,即512×512大小掩模区域范围内的原图像像素值替换为符合标准高斯分布的噪声值,被掩模处理后1024×1024×3维的图像记为x’。
步骤二:将步骤一中的训练集图像对应文本t输入到文本编码器网络中,得到固定维度128的文本编码向量
该文本编码网络采用双向循环卷积网络中用于解决序列转序列(seq2seq)问题中提出的编码-解码模型的编码结构部分,编码时使用双向循环卷积网络,即输入文本,通过编码器网络将其编码输出成一个固定大小的语义向量,该语义向量即为维度为128的文本编码向量
步骤三:将步骤二得到的文本编码向量以及步骤一得到的图像x’进行通道级联,生成含文本语义特征的图像j。
将得到的128维的文本编码向量
步骤四:将步骤三生成的图像j输入至局部特征提取卷积神经网络,得到局部特征图像。
本实施例中提供一种生成器网络的结构,示意图如图4所示,在此仅以图4所示的网络结构为例进行人脸图像的生成。具体地,生成器网络中每一层的工作过程如下:
步骤五:将步骤三生成的图像j输入至全局网络中特征提取卷积神经网络,得到全局特征图像。
将得到的1024×1024×131维的含文本语义特征图像j输入到下采样层s1,下采样层采用取最大值法进行降采样,滤波器尺寸为2个像素,步长为2个像素,深度不变,输出512×512×131的s1下采样图像。
将得到的s1下采样图像输入到生成器网络的全局特征提取卷积神经网络部分中的c1’卷积层,通过64个7×7的滤波器,使用1个像素的步长,使用3个像素的零补充,对s1下采样图像进行卷积操作,输出512×512×64的c1’卷积层特征图像。
将得到的每幅512×512×64的c1'卷积层特征特征图像输入到全局特征提取卷积神经网络中的n1’实例归一化层进行实例归一化,输出512×512×64的n1’实例归一化特征图像,并用relu激活函数激活,输出512×512×64的r1’激活图像。
将得到的r1’激活图像输入到生成器网络的全局特征提取卷积神经网络部分中的c2’卷积层,通过128个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r1’激活图像进行卷积操作,输出256×256×128的c2’卷积层特征图像;
将得到的每幅256×256×128的c2'卷积层特征特征图像输入到全局特征提取卷积神经网络中的n2’实例归一化层进行实例归一化,输出256×256×128的n2’实例归一化特征图像,并用relu激活函数激活,输出256×256×128的r2’激活图像。
将得到的r2’激活图像输入到生成器网络的全局特征提取卷积神经网络部分中的c3’卷积层,通过256个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r2’激活图像进行卷积操作,输出128×128×256的c3’卷积层特征图像。
将得到的每幅128×128×256的c3'卷积层特征特征图像输入到全局特征提取卷积神经网络中的n3’实例归一化层进行实例归一化,输出128×128×256的n3’实例归一化特征图像,并用relu激活函数激活,输出128×128×256的r3’激活图像。
将得到的r3’激活图像输入到生成器网络的全局特征提取卷积神经网络部分中的c4’卷积层,通过512个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r3’激活图像进行卷积操作,输出64×64×512的c4’卷积层特征图像。
将得到的每幅64×64×512的c4'卷积层特征特征图像输入到全局特征提取卷积神经网络中的n4’实例归一化层进行实例归一化,输出64×64×512的n4’实例归一化特征图像,并用relu激活函数激活,输出64×64×512的r4’激活图像。
将得到的r4’激活图像输入到生成器网络的全局特征提取卷积神经网络部分中的c5’卷积层,通过1024个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r4’激活图像进行卷积操作,输出32×32×1024的c5’卷积层特征图像。
将得到的每幅32×32×1024的c5'卷积层特征特征图像输入到全局特征提取卷积神经网络中的n5’实例归一化层进行实例归一化,输出32×32×1024的n5’实例归一化特征图像,并用relu激活函数激活,输出32×32×1024的r5’激活图像。
r5’激活图像即为全局特征图像,为具有全局还原信息的特征矩阵。
步骤六:将步骤五中全局网络中特征提取卷积神经网络生成的激活图像输入至全局残差网络,得到进行全局深度优化后的全局特征图像。
在此以图2所示的残差网络结构为例进行介绍,其它残差网络结构均可参照本实施例的介绍。
将得到的32×32×1024的r5’激活图像作为全局残差网络输入图像,输入res6’全局残差网络中,得到32×32×1024的res6’残差网络卷积图像。(本实施例中所用残差网络对应全局特征提取卷积神经网络部分中的残差网络结构的参数。其中resinput大小:32×32×1024,resoutput大小:32×32×1024)。
将得到的32×32×1024的残差网络图像依次输入到生成器网络的全局特征提取卷积神经网络部分中的res7’,res8’,res9’,res10’,res11’,res12’的残差网络中,得到32×32×1024的res7’,res8’,res9’,res10’,res11’,res12’残差网络卷积图像,最终输出32×32×1024的res12’残差网络卷积图像。(本步骤s3.18中所用的所有残差网络全部对应全局特征提取卷积神经网络部分中的残差网络结构的参数。其中resinput大小:32×32×1024,resoutput大小:32×32×1024)。
将得到的res12’残差网络卷积图像输入到全局特征提取神经网络部分中的u13’转置卷积层,通过512个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对res12’残差网络卷积图像进行转置卷积操作,输出64×64×512的u13’转置卷积层特征图像。
将得到的每幅64×64×512的u13’转置卷积层特征图像输入到全局特征提取卷积神经网络中的n13’实例归一化层进行实例归一化,输出64×64×512的n13’实例归一化特征图像,并用relu激活函数激活,输出64×64×512的r13’激活图像。
将得到的r13’激活图像输入到全局特征提取神经网络部分中的u14’转置卷积层,通过256个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r13’激活图像进行转置卷积操作,输出128×128×256的u14’转置卷积层特征图像。
将得到的每幅128×128×256的u14’转置卷积层特征图像输入到全局特征提取卷积神经网络中的n14’实例归一化层进行实例归一化,输出128×128×256的n14’实例归一化特征图像,并用relu激活函数激活,输出128×128×256的r14’激活图像。
将得到的r14’激活图像输入到全局特征提取神经网络部分中的u15’转置卷积层,通过128个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r14’激活图像进行转置卷积操作,输出256×256×128的u15’转置卷积层特征图像。
将得到的每幅256×256×128的u15’转置卷积层特征图像输入到全局特征提取卷积神经网络中的n15’实例归一化层进行实例归一化,输出256×256×128的n15’实例归一化特征图像,并用relu激活函数激活,输出256×256×128的r15’激活图像。
将得到的r15’激活图像输入到全局特征提取神经网络部分中的u16’转置卷积层,通过64个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r15’激活图像进行转置卷积操作,输出512×512×64的u16’转置卷积层特征图像。
将得到的每幅512×512×64的u16’转置卷积层特征图像输入到全局特征提取卷积神经网络中的n16’实例归一化层进行实例归一化,输出512×512×64的n16’实例归一化特征图像,并用relu激活函数激活,输出512×512×64的r16’激活图像。
步骤七:将得到的1024×1024×131维的含文本语义特征图像j输入到局部网络中维度转换卷积神经网络部分中,进行维度调整。
将得到的1024×1024×131维的含文本语义特征图像j输入到生成器网络的局部特征提取卷积神经网络部分中的c1卷积层,通过32个7×7的滤波器,使用1个像素的步长,使用3个像素的零补充,对含文本语义特征图像j进行卷积操作,输出1024×1024×32的c1卷积层特征图像。
将得到的每幅1024×1024×32的c1卷积层特征图像输入到局部特征提取卷积神经网络中的n1实例归一化层进行实例归一化,输出1024×1024×32的n1实例归一化特征图像,并用relu激活函数激活,输出1024×1024×32的r1激活图像。
将激活后的每幅1024×1024×32的r1激活图像输入到生成器网络的局部特征提取卷积神经网络部分中的c2卷积层,通过64个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对r1激活图像进行卷积操作,输出512×512×64的c2卷积层特征图像。
将得到的每幅512×512×64的c2卷积层特征特征图像输入到局部特征提取卷积神经网络中的n2实例归一化层进行实例归一化,输出512×512×64的n2实例归一化特征图像,并用relu激活函数激活,输出512×512×64的r2激活图像。
步骤八:将步骤七得到的叠加了维度处理后的特征数据与优化全局特征矩阵的特征矩阵输入至叠加了resnet的局部网络中特征提取卷积神经网络,进行局部增强,得到整体还原特征矩阵,并对整体还原特征矩阵进行输出设置,得到还原图像。
将生成器网络中局部网络中的维度转换卷积神经网络输出的512×512×64的r16’全局网络中特征提取网络激活图像与局部特征提取卷积神经网络生成的输出的512×512×64的r2局部特征提取网络激活图像相加,得到大小512×512×64的生成器网络叠加激活函数图像r17。
将生成的512×512×64的生成器网络叠加激活函数图像r17作为残差网络输入图像,输入到生成器网络的局部特征提取卷积神经网络部分中的res18残差网络中,得到512×512×64的res18残差网络卷积图像。(本实施例中局部残差网络对应局部特征提取卷积神经网络部分中的残差网络结构的参数。其中resinput2大小:512×512×64,resoutput2大小:512×512×64)。
将得到的512×512×64的残差网络图像按顺序输入到生成器网络的局部特征提取卷积神经网络部分中的res19,res20,res21的残差网络中,得到512×512×64的res19,res20,res21残差网络卷积图像,最终输出512×512×64的res21残差网络卷积图像。(本步骤中所用的所有残差网络全部对应局部特征提取卷积神经网络部分中的残差网络结构的参数。其中resinput2大小:512×512×64,resoutput2大小:512×512×64)
将得到的512×512×64的res21残差网络卷积图像输入到局部特征提取神经网络部分中的u22转置卷积层,通过32个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对res21残差网络卷积图像进行转置卷积操作,输出1024×1024×32的u22转置卷积层特征图像。
将得到的每幅1024×1024×32的u22转置卷积层特征图像输入到局部特征提取卷积神经网络中的n22实例归一化层进行实例归一化,输出1024×1024×32的n22实例归一化特征图像,并用relu激活函数激活,输出1024×1024×32的r22激活图像。
将得到的1024×1024×32维的r22激活图像输入到生成器网络的局部特征提取卷积神经网络部分中的c23卷积层,通过3个7×7的滤波器,使用1个像素的步长,使用3个像素的零补充,对r22激活图像进行卷积操作,输出1024×1024×3的c23卷积层特征图像。
将得到的每幅1024×1024×3的c23卷积层特征特征图像输入到局部特征提取卷积神经网络中的n23实例归一化层进行实例归一化,输出1024×1024×3的n23实例归一化特征图像,并用relu激活函数激活,输出1024×1024×3的r23激活图像,该激活函数图像即为最终生成器网络部分输出的高清带属性人脸图像,记为x。
局部网络的resnet(残差网络)加在局部网络的第二部分,把既带有原本j的信息又带有全局网络特征提取后输出的信息的叠加图r17作为第二部分输入。局部网络的作用是在全局网络的基础上进行局部增强,使得图像更精细,分辨率更高,可以看出经过局部网络第二部分,图像从输入特征矩阵r17(大小512×512×64)经残差网络变为了特征矩阵r22(大小1024×1024×32),分辨率由512提升到1024,得到了明显提升。
步骤九:根据输出的高清带属性人脸图像以及存储的真实图像通过判别器进行分析比对。
图5所示为本实施例提供的一种判别器结构示意图,其它类型的可以实现本实施例所提供的功能的装置均可参照本实施例的介绍。将生成的高清带属性1024×1024×3人脸图像x和1024×1024×3的训练集真实图像x,作为判别器网络的图像输入之一。将图像对应的文本t输入到文本编码器网络中,得到固定维度128的文本编码向量
将得到的128维的文本编码向量
将得到的1024×1024×131维的含文本语义特征图像j输入到判别器卷积神经网络部分中的cn1卷积层,通过64个7×7的滤波器,使用2个像素的步长,使用3个像素的零补充,对含文本语义特征图像j进行卷积操作,输出512×512×64的cn1卷积层特征图像。
将得到的每幅512×512×64的cn1卷积层特征图像输入到判别器卷积神经网络中的in1实例归一化层进行实例归一化,输出512×512×64的in1实例归一化特征图像,并用斜率0.2的leakyrelu激活函数激活,输出512×512×64的lr1激活图像。
将激活后的每幅512×512×64的lr1激活图像。输入到判别器卷积神经网络中的cn2卷积层,通过128个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对lr1激活图像进行卷积操作,输出256×256×128的cn2卷积层特征图像。
将得到的每幅256×256×128的cn2卷积层特征图像输入到判别器卷积神经网络中的in2实例归一化层进行实例归一化,输出256×256×128的in2实例归一化特征图像,并用斜率0.2的leakyrelu激活函数激活,输出256×256×128的lr2激活图像。
将激活后的每幅256×256×128的lr2激活图像。输入到判别器卷积神经网络中的cn3卷积层,通过256个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对lr2激活图像进行卷积操作,输出128×128×256的cn3卷积层特征图像。
将得到的每幅128×128×256的cn3卷积层特征图像输入到判别器卷积神经网络中的in3实例归一化层进行实例归一化,输出128×128×256的in3实例归一化特征图像,并用斜率0.2的leakyrelu激活函数激活,输出128×128×256的lr3激活图像。
将激活后的每幅128×128×256的lr3激活图像。输入到判别器卷积神经网络中的cn4卷积层,通过512个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对lr3激活图像进行卷积操作,输出64×64×512的cn4卷积层特征图像。
将得到的每幅64×64×512的cn4卷积层特征图像输入到判别器卷积神经网络中的in4实例归一化层进行实例归一化,输出64×64×512的in4实例归一化特征图像,并用斜率0.2的leakyrelu激活函数激活,输出64×64×512的lr4激活图像。
将激活后的每幅64×64×512的lr4激活图像。输入到判别器卷积神经网络中的cn5卷积层,通过1个3×3的滤波器,使用2个像素的步长,使用1个像素的零补充,对lr4激活图像进行卷积操作,输出32×32×1的cn5卷积层特征图像。
将得到的每幅32×32×1的cn5卷积层特征图像输入到判别器卷积神经网络中的in5实例归一化层进行实例归一化,输出32×32×1的in5实例归一化特征图像,并用斜率0.2的leakyrelu激活函数激活,输出32×32×1的lr5激活图像。
将得到的每幅32×32×1的lr5激活图像依次对应输入904个神经元的全连接层fc1,fc1再连接输入到具有一个神经元的全连接fc2层,并使用sigmoid函数激活,输出一个值p。进一步的,p的值的范围大小为0到1,代表判别器网络对输入人脸图像真假的判断概率,其中判别器认为输入判别器网络的人脸图像越真实,p值越大,反之认为越虚假,p值越小。
步骤十:根据判别器的分析结果对网络参数进行修正。
对生成器网络和判别器网络损失函数最小最大化的博弈对抗优化:
其中,d()表示一个0-1的概率值,g表示生成器网络,di代表判别器网络,d1对应输入图像大小为1024×1024×3,d2对应输入图像为经过d1输入图像对应降采样得到的512×512×3的图像。d1和d2网络结构相似,粗糙尺度的判别器d2可以更好判断全局是否真实,而精细尺度的判别器d1可以更好判断局部细节是否真实,通过采用两个不同尺度的判别器可以提高判别的精确度。x来自真实人脸图像分布pdata,
lg的作用:g应该希望自己生成的图片“越接近真实越好”。也就是说,g希望
将训练集真实人脸图像和生成图像送入到预训练好的深度卷积网络vgg19中,计算感知损失:
其中,vgg19网络是一个参数已经训练好的深度网络,它的每一层都可以对输入的图像提取特征。如果将生成图像和真实图像分别送入vgg19中,他们对应每一层提取的特征尽可能相似(差异距离小)的话,那么可以指导输入的生成图像与真实图像尽可能相似,也就是指导生成图像更真实,更以假乱真。f(i)表示vgg19的第i层的mi个元素,感知损失评价的是真实人脸图像和生成人脸图像送入到vgg特征提取网络后每一层提取的特征之间的差异距离。
判别器损失函数为ld=ld1+ld2+λlperceptual,其中λ是一个超参数,可取5。
将成对的训练集图像和文本数据集输入到设计好的生成对抗网络结构中进行网络训练,根据损失函数,利用梯度下降的方法,对生成器和判别器卷积神经网络参数进行优化。
根据优化后的卷积神经网络参数更新神经网络,重复优化步骤,直至损失函数ld和lg逐渐稳定,最后训练得到生成对抗网络卷积神经网络结构中目标生成器网络和目标判别器网络。并提取训练好的目标生成对抗网络中的生成器部分的网络结构与参数。
在网络训练过程中,可以先训练全局网络部分的参数,先生成一张分辨率只有原图一半的粗糙的人脸图像,然后训练一段时间后,再引入局部网络部分,使得全局网络和局部网络联合一起完整的网络进行参数训练,这样基于粗糙人脸图像的基础上可以进一步生成1024×1024的高分辨率人脸图像。
本实施例中仅以上述情况为例对生成器的训练过程进行介绍,其它训练过程均可参照本实施例的介绍。
基于上述网络训练过程实施例的介绍,在此基于上述训练后的网络结构对网络测试(或使用)过程进行介绍。
将测试集对应文本ttest输入到文本编码器网络中,得到固定维度128的文本编码向量
将测试集中真实人脸图像xtest均匀分为4×4的方格区域,将位于中心的第二三行的各自三四列的方格区域共512×512大小的图像区域设置为掩模区域,即512×512大小掩模区域范围内的原图像像素值替换为符合标准高斯分布的噪声值,被掩模处理后1024×1024×3维的图像记为xtest’。
将得到的128维的文本编码向量
将得到的1024×1024×131维的含文本语义特征测试图像jtest输入到生成器网络中,最终得到测试集文本对应1024×1024×131维的高清带属性人脸生成图像。
若网络在使用或测试过程中生成图像效果低于使用预期时,可以重新投入训练,对于这种情况不做限定。
基于上述实施例对人脸图像生成方法的介绍,通过“部分遮挡图像+文本”的输入来生成人脸图像,通过训练优化的人脸图像生成模型进行人脸细节特征还原,生成的图像既符合文本描述的属性,同时生成人脸图像中生成的遮挡部分与原本未遮挡的人脸图像部分连接的边界处也自然真实,有利于提高生成的人脸图像的真实性,且具有较高的图像分辨率,而且图像特征提取过程更符合人类认知的属性方式,如文本描述人脸特征的方式,也可以生成相对应的符合文本描述条件的高清人脸图像,用户可以方便地获取大量高真实度、高分辨率的人脸图像。
下面对本发明提供的带属性人脸图像生成装置进行介绍,请参考图5,图6本发明实施例提供的带属性人脸图像生成装置的结构框图;该装置可以包括:信息接收单元610、文本编码单元620、通道级联单元630以及特征还原单元640。
其中,信息接收单元610主要用于接收人脸特征描述文本以及部分遮挡图像;
文本编码单元620主要用于将描述文本输入至文本编码器网络,得到文本编码向量;
通道级联单元630主要用于将文本编码向量以及部分遮挡图像进行通道级联,生成语义特征数据;
特征还原单元640主要用于将语义特征数据输入至人脸图像生成模型中进行人脸特征还原,得到带属性的人脸图像;其中,人脸图像生成模型为根据文本数据集以及训练集图像训练优化得到的深度学习网络。
需要说明的是,本发明具体实施方式中的带属性人脸图像生成装置中的各个单元,其工作过程请参考图1对应的具体实施方式,在此不再赘述。
其中,可选地,特征还原单元具体可以用于:将语义特征数据输入至基于生成式对抗网络的生成器进行人脸特征还原;
则网络优化单元具体包括:
训练还原子单元,主要用于利用生成器根据输入的语义特征训练数据进行图像还原;
训练评判子单元,主要用于根据对应的原图,通过判别器进行还原图像的真实性评判,得到真实性概率;
训练优化子单元,主要用于根据真实性概率对生成器以及判别器进行参数优化。
图7所示为网络优化单元与带属性人脸图像生成装置的连接示意图,带属性人脸图像生成装置利用网络优化单元将训练好的生成器进行人脸图像的生成。
可选地,训练优化子单元具体可以包括:损失函数计算子单元,用于根据真实性概率计算最小化损失函数;损失函数优化子单元,用于根据最小化损失函数利用梯度下降法对生成器以及判别器进行优化。
其中,损失函数具体可以为:
其中lg用来更新优化生成网络,ld用来更新优化判别网络。λ是一个超参数,di代表判别器网络,lg越小,证明生成器生成真实性高的图片的能力越强。
ld1ld2:判别器网络d1和d2网络结构相似,d1对应输入图像大小为1024×1024×3,d2对应输入图像为经过d1输入图像对应降采样得到的512×512×3的图像。ld1ld2越小,证明判别器分辩能力越强。
lperceptual:vgg19网络是一个参数已经训练好的参数固定的深度网络,它的每一层都可以对输入的图像得到每层参数,也就是代表特征的特征矩阵。将生成图像送入vgg19,vgg19每层参数都有一个值,将对应原真实图像送入vgg19,vgg19每层参数都又有一个值。将两次的值一一对应相减作差取平均,平均值越小,证明生成图像和真实图像含有的特征越相似。
可选地,特征还原单元具体可以包括:
全局还原子单元,用于预训练的全局网络对语义特征数据进行全局特征还原,得到具有全局还原信息的特征矩阵;
局部还原子单元,用于预训练的局部网络将语义特征数据进行矩阵维度处理,将维度处理后的特征数据与全局特征矩阵进行信息叠加,并对叠加后的数据进行局部增强,得到细节优化的全局特征矩阵;
输出设置单元,用于对细节优化的全局特征矩阵进行输出设置,得到还原图像,将还原图像作为带属性的人脸图像。
可选地,特征还原单元中还包括:全局优化单元,用于通过全局残差网络对具有全局还原信息的特征矩阵进行全局深度优化,得到优化全局特征矩阵;
则局部还原子单元可以用于将维度处理后的特征数据与优化全局特征矩阵进行信息叠加。
可选地,局部特征还原单元中可以还包括:局部优化单元,用于将细节优化的全局特征矩阵输入至局部残差网络进行局部深度优化,得到优化矩阵;
则对细节优化的全局特征矩阵进行输出设置具体为:对优化矩阵进行输出设置。
本发明还公开一种带属性人脸图像生成系统,主要包括:存储器以及处理器。
其中,存储器用于存储计算机程序;
处理器用于执行计算机程序时实现上述的带属性人脸图像生成方法的步骤。
请参考图8,为本实施例提供的带属性人脸图像生成系统的结构示意图,该生成系统可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(centralprocessingunits,cpu)322(例如,一个或一个以上处理器)和存储器332,一个或一个以上存储应用程序342或数据344的存储介质330(例如一个或一个以上海量存储设备)。其中,存储器332和存储介质330可以是短暂存储或持久存储。存储在存储介质330的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对数据处理设备中的一系列指令操作。更进一步地,中央处理器322可以设置为与存储介质330通信,在生成系统301上执行存储介质330中的一系列指令操作。
生成系统301还可以包括一个或一个以上电源326,一个或一个以上有线或无线网络接口350,一个或一个以上输入输出接口358,和/或,一个或一个以上操作系统341,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等等。
上面图1所描述的带属性人脸图像生成方法中的步骤可以由带属性人脸图像生成系统的结构实现。
本实施例公开了一种可读存储介质,可读存储介质上存储有程序,程序被处理器执行时实现带属性人脸图像生成方法的步骤,其中,带属性人脸图像生成方法可参照图1对应的实施例,在此不再赘述。
说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
以上对本发明所提供的带属性人脸图像生成方法、装置、系统及可读存储介质进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!