一种用于视频融合中的人脸检测方法和装置与流程
本发明涉及人工智能领域,特别涉及一种用于视频融合中的人脸检测方法和装置。
背景技术:
视频融合技术是虚拟现实技术的一个分支,也可以说是虚拟现实的一个发展阶段。视频融合技术指将一个或多个由视频采集设备采集的关于某场景或模型的图像序列视频与一个与之相关的虚拟场景加以融合,以生成一个新的关于此场景的虚拟场景或模型。
这个模型中因为视频的加入得到一个无论是虚拟场景还是视频本身都无法单独完成的信息结合体。视频融合的目的是增加虚拟场景与现实的互动性,减小计算机模型中信息不确定因素,增加虚拟模型的信息承载量,为现实与虚拟之间架起一座桥梁,拓展虚拟现实技术的应用领域。
但是,现有技术中已经存在的视频融合技术,尚未在人像视频的使用场景下广泛应用。
技术实现要素:
本发明要解决的技术问题是提供一种用于视频融合中的人脸检测方法和装置。
为了解决上述技术问题,本发明的技术方案为:
一种用于视频融合中的人脸检测方法,其特征在于,包括:
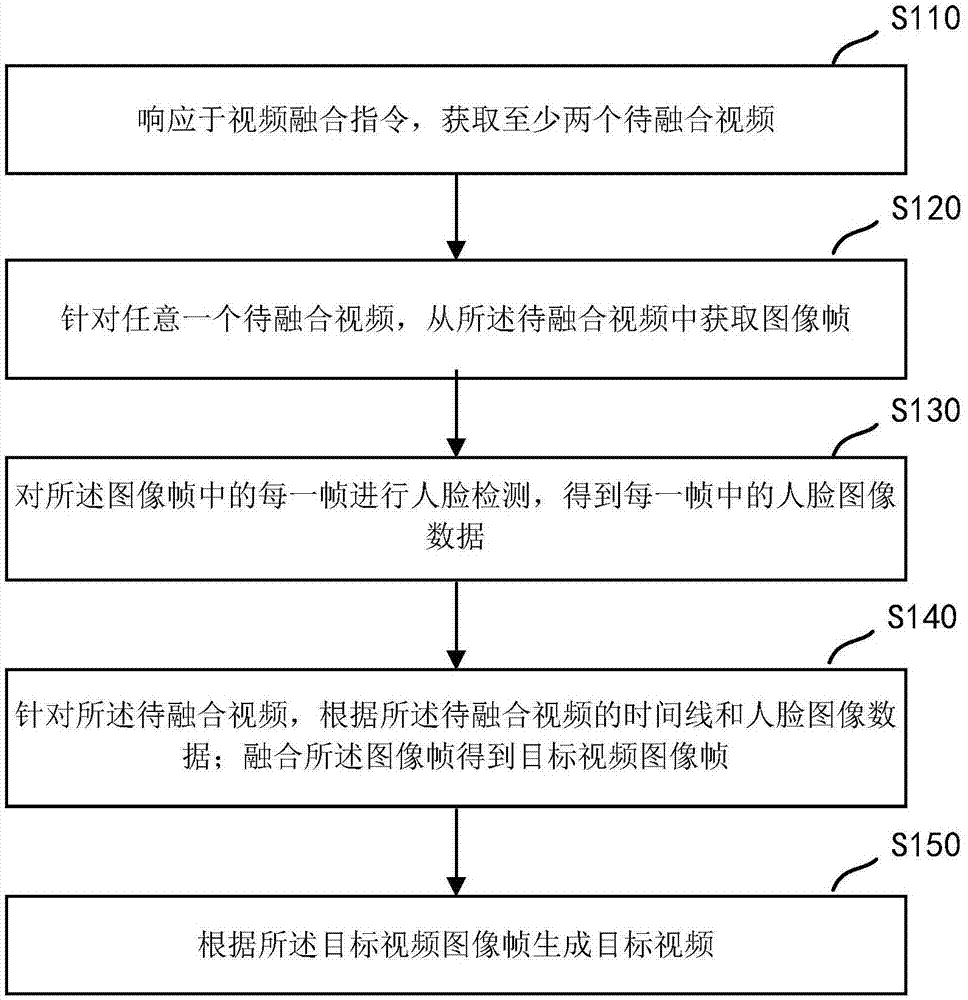
响应于视频融合指令,获取至少两个待融合视频;
针对任意一个待融合视频,从所述待融合视频中获取图像帧;
对所述图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据;
针对所述待融合视频,根据所述待融合视频的时间线和人脸图像数据;融合所述图像帧得到目标视频图像帧;
根据所述目标视频图像帧生成目标视频。
在上述实施例的基础上,所述对所述图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据之前,还包括:
对所述图像帧中的每一帧进行格式转换和/或降阶处理。
在上述实施例的基础上,所述对图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据,包括:
捕捉所述图像帧的每一帧中的人脸区域;
采用三眼五庭分割法对所述人脸区域进行区域分割;
从分割后的区域中筛选出基准区域。
基于相同的思路,本发明还提供了一种用于视频融合中的人脸检测装置,具体为:
视频获取模块,响应于视频融合指令,获取至少两个待融合视频;
图像帧获取模块,用于针对任意一个待融合视频,从所述待融合视频中获取图像帧;
检测模块,用于对所述图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据;
融合模块,用于针对所述待融合视频,根据所述待融合视频的时间线和人脸图像数据,融合所述图像帧得到目标视频图像帧;
视频生成模块,用于根据所述目标视频图像帧生成目标视频。
进一步的,所述装置还包括预处理模块,用于对所述图像帧中的每一帧进行格式转换和/或降阶处理。根据所述目标视频图像帧生成目标视频。
进一步的,所述检测模块包括:
图像捕捉单元,用于捕捉所述图像帧的每一帧中的人脸区域;
区域分割单元,用于采用三眼五庭分割法对所述人脸区域进行区域分割;
筛选单元,用于从分割后的区域中筛选出基准区域。
采用上述技术方案,通过对待融合视频的每一帧进行人脸检测,并得到相应的人脸图像数据,进而根据所述待融合视频的时间线和人脸图像数据;融合所述图像帧得到目标视频图像帧;最后生成目标视频,实现了视频融合技术在人像视频的使用场景下应用。
附图说明
图1为本发明实施例一提供的一种用于视频融合中的人脸检测方法的流程图;
图2为本发明实施例二提供的一种视频融合装置的结构示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。
实施例一
图1为本发明实施例一提供的一种用于视频融合中的人脸检测方法的流程图,该方法可以由一种人脸检测装置来执行,该装置可以通过软件和/或硬件的方式实现,并集成在是智能设备中。具体的,所述的用于视频融合中的人脸检测方法包括:
s110、响应于视频融合指令,获取至少两个待融合视频。
本实施例所述的人脸检测方法通常在服务器中执行,其中,所述视频融合指令由用户通过终端(包括pc端和移动端)发出,同时,所述至少两个待融合视频也可以同视频融合指令一同从终端发送至服务端,以提高视频融合方法的执行效率。所述待融合视频可以包括用户终端中预先存储的自拍视频,可以包括用户所感兴趣的视频,也可以包括用户所喜欢明星的视频。
示例性的,如果所述待融合视频包括用户的自拍视频和用户所喜欢明星的视频,融合待融合视频所得到的目标视频中会呈现用户与明星互动的画面。
s120、针对任意一个待融合视频,从所述待融合视频中获取图像帧。
其中,所述待融合视频包括图像帧,所述图像帧包括视频关键帧和普通帧。
可选的,图像帧的类型包括interframe(i帧)、p-frame(p帧)和b-frame(b帧)。
s130、对所述图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据。
其中,所述人脸图像数据用于表示所述图像帧中的人脸特征的数据,所述人脸特征包括直方图特征、颜色特征、模板特征、结构特征及haar(haar-like特征)特征,具体的,所述haar特征包括边缘特征、线性特征、中心特征和对角线特征等。例如,haar特征值反映了图像的灰度变化情况。例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述特定走向(水平、垂直、对角)的结构。
s140、针对所述待融合视频,根据所述待融合视频的时间线和人脸图像数据;融合所述图像帧得到目标视频图像帧。
其中,所述时间线用于排列待视频图像中的所有图像帧。在本实施例具体执行的过程中,可以根据所述时间线对处于相同时刻的图像帧进行融合
s150、根据所述目标视频图像帧生成目标视频。
实施例二
在实施例一的基础上,本实施例还可以为增加了对图像帧的预处理过程,具体的,所述人脸检测方法,包括:
s210、响应于视频融合指令,获取至少两个待融合视频。
s220、针对任意一个待融合视频,从所述待融合视频中获取图像帧。
s230、对所述图像帧中的每一帧进行格式转换和/或降阶处理。
s240、对所述图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据;
s250、针对所述待融合视频,根据所述待融合视频的时间线和人脸图像数据;融合所述图像帧得到目标视频图像帧;
s260、根据所述目标视频图像帧生成目标视频。
实施例三
图2为本发明实施例三提供的一种用于视频融合中的人脸检测装置的结构示意图,具体包括:视频获取模块310、图像帧获取模块320、检测模块330、融合模块340和视频生成模块350。
视频获取模块310,响应于视频融合指令,获取至少两个待融合视频;
图像帧获取模块320,用于针对任意一个待融合视频,从所述待融合视频中获取图像帧;
检测模块330,用于对所述图像帧中的每一帧进行人脸检测,得到每一帧中的人脸图像数据;
融合模块340,用于针对所述待融合视频,根据所述待融合视频的时间线和人脸图像数据,融合所述图像帧得到目标视频图像帧;
视频生成模块350,用于根据所述目标视频图像帧生成目标视频。
在上述实施例的基础上,所述人脸检测装置还包括:
预处理模块,用于对所述图像帧中的每一帧进行格式转换和/或降阶处理。根据所述目标视频图像帧生成目标视频。
在上述实施例的基础上,所述检测模块包括:
图像捕捉单元,用于捕捉所述图像帧的每一帧中的人脸区域;
区域分割单元,用于采用三眼五庭分割法对所述人脸区域进行区域分割;
筛选单元,用于从分割后的区域中筛选出基准区域。
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!