基于深度学习网络和卡尔曼滤波的船只目标视频检测方法与流程
本发明属于船舶数字影像处理技术领域,特别涉及一种基于深度学习网络和和卡尔曼滤波的船只目标视频检测方法。
背景技术:
现今社会中,视频监控摄像头无处不在,如果只是依靠人眼观察检测,很容易错过视频中的异常事件。随着计算机网络、通信和半导体技术的迅速发展,人们越来越青睐于利用计算机视觉代替人眼对传感器得到的视频图像进行分析,获取图像中的有用信息。视频目标检测就是计算机视觉研究的一个重点,它主要是对图像传感器得到的感兴趣的目标进行检测。视频目标检测是许多视频应用的基础,更是比如交通监控、智能机器人和人机交互等,其对于智能城市管理、打击违法犯罪以及建设平安城市与智慧城市具有重要作用,是当前视频处理研究的重点和难点。而对于船只目标来说,更是对于沿海城市的船只管理、监督和调度起着至关重要的作用。
针对船只的视频目标检测主要有基于运动的检测、基于匹配的检测和基于特征的检测三大类。
基于运动的检测方法通过对视频中的动态图像进行分析处理来获取运动船只信息,从而实现对运动船只的检测,进一步通过初始船只位置,获得视频中后续帧的船只位置。该方法将检测问题视作一个状态估计问题,根据给定数据,用新号处理的方法对船只在下一帧的状态(如位置、颜色、形状等)进行最优化估计。该方法主要包括基于滤波的检测算法和基于子空间学习的算法。基于滤波的算法如卡尔曼滤波、均值漂移滤波和粒子滤波,主要根据前期数据学习出船只的特征空间,再根据当前帧的图像块在特征空间的分布进行船只定位。预测的方法在船只目标检测方面具有速度快的优势,但是当前帧状态完全取决于前一帧检测结果,无法自动进行检测和检测错误的修正,检测的精度较低。
基于匹配的算法将视频中的船只检测问题视为一个模板匹配问题,用一个模板表示待检测的目标,寻找下一帧中的最优匹配结果。匹配中的目标可以是一个或一组图形块,也可以是目标图像的全局或局部特征表示。这类方法通过边检测边学习的过程,提高了后续帧中目标检测的性能,但是依然难以实现自动快速的目标检测结果,同时对于遮盖、复杂环境下难以准确检测。
基于特征的检测方法主要通过图像目标检测算法,对视频中每一帧图像进行单独的船只检测过程。其中,基于深度学习的方法尤为突出,该方法能够对多种目标进行特征的自动学习,获得船只的高维特征,检测结果精度相比传统方法有了大幅度提升。然而,对于视频目标来说,单帧图像的船只检测放弃了视频目标中的上下文关系,属于离线学习的方法,对于动态变化的目标检测效果较差,而在线学习方法容易因每一次的更新引入新的误差导致误差累计,最终发生漂移甚至丢失目标。如何自动快速对视频中的船只目标检测,即考虑当前帧结果,又参考目标不同的特征,还需要进一步研究。
技术实现要素:
本发明的目的就在于克服现有技术存在的缺点和不足,提供一种基于深度学习网络和卡尔曼滤波的船只目标视频检测方法。
本发明技术方案提供一种基于深度学习网络和卡尔曼滤波的船只目标视频检测方法,包括以下步骤:
步骤1,监控视频数据采集;
步骤2,对于获取到的监控视频数据进行预处理,为卷积神经网络训练准备船只目标的正负样本;
步骤3,采用基于区域的卷积神经网络方法,基于船只目标的正负样本进行训练,得到训练后的深度学习网络;
步骤4,基于卡尔曼滤波方法,根据前一时刻船只检测最终结果,对当前时刻的船只位置进行预测,获得当前时刻的卡尔曼滤波预测结果;
步骤5,通过当前时刻的卡尔曼滤波预测结果和当前时刻的深度学习网络检测结果,共同确定当前时刻的船只检测最终结果。
而且,步骤2的实现方式为,利用获取到的监控视频数据中视频图像,通过几何变换方式,对影像进行扩充;得到每个船只目标在影像中竖直的最小包围矩形的四个顶点坐标,作为正样本坐标,将对应影像和其上的所有目标坐标共同输出,作为正样本;在正样本周围随机截取其他区域,得到其竖直的最小包围矩形的四个顶点坐标,作为负样本坐标,将对应影像和其上的负样本坐标一同输出。
而且,步骤5的实现方式包括以下步骤,
a,设以t-1时刻的检测到的ξ个船只位置作为初始位置,经过步骤4获得t时刻的卡尔曼滤波预测结果
b,通过基于区域的卷积神经网络方法和步骤3训练后的深度学习网络,对t时刻的图像进行船只检测,获得t时刻的深度学习检测结果;
c,根据t时刻的深度学习检测结果zt,更新卡尔曼增益值kt,得到t时刻的修正状态值
根据修正状态值
d,设经步骤b得到第num个船只检测坐标
记录每个船只预测位置
如果omax小于阈值θ1,则认为该船只位置为虚警,删除船只预测位置
e,对于步骤b所得每个船只检测坐标
对比现有技术,本发明具有下列优点和积极效果:
深度学习方法部分具体采用基于区域的卷积神经网络对监控视频图像进行多个船只目标的同时检测过程,该方法快速高效、准确度高。对于复杂场景如云雾、阴天、下雨等情况依然具有较好的检测结果,方法鲁棒性高。
采用快速高效的卡尔曼滤波方法,结合视频中的每个船只在前后帧关系,对视频中的船只目标检测结果进行优化,根据深度学习检测结果剔除虚警,又基于卡尔曼滤波的视频前后帧关系,修正了检测中的漏检问题,大幅度提高针对视频船只目标的检测精度。
深度学习网络方法和卡尔曼滤波方法的结合,一方面更好完成多船只目标的自动检测过程,让检测过程全自动化,不需要人机交互过程;另一方面卡尔曼滤波方法对于视频信息的学习和船只位置前后帧的连续性,也为深度学习检测结果的错误进行排除,对新出现目标的检测打下基础。
附图说明
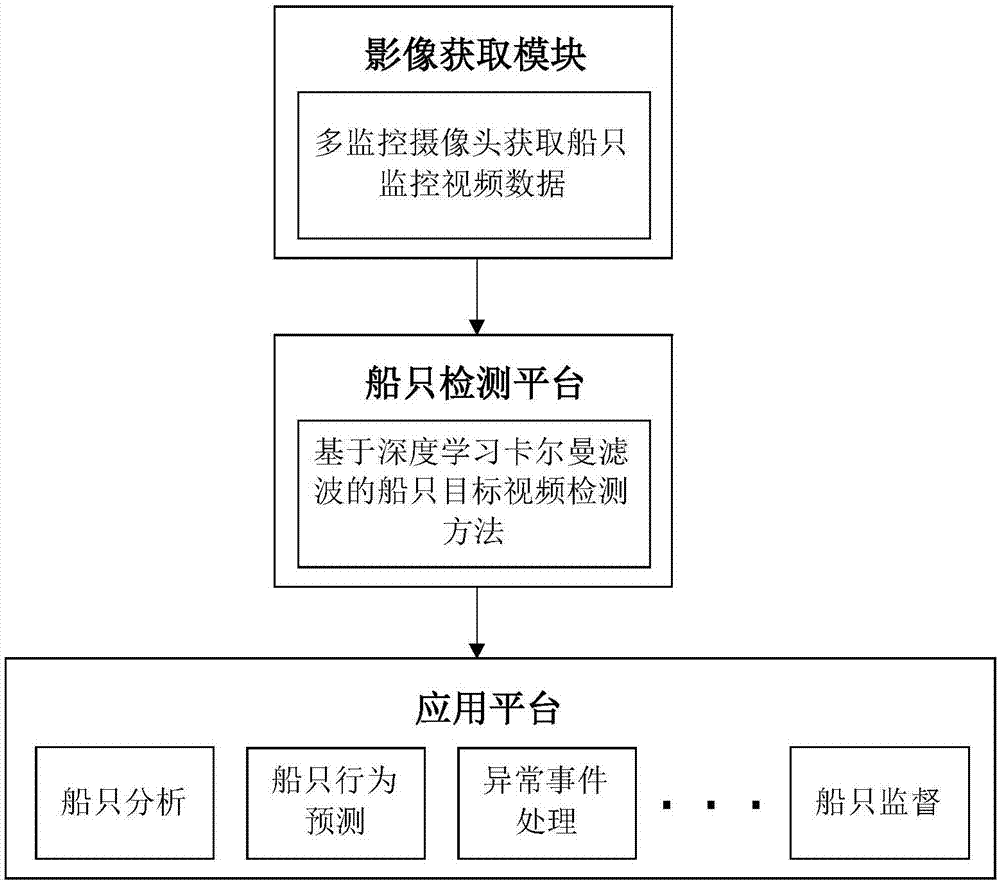
图1为本发明实施例的应用系统整体系统结构图。
图2为本发明实施例方法的整体流程图。
图3为本发明实施例中步骤③以后基于深度学习网络和卡尔曼滤波方法获取船只目标视频检测结果具体策略流程图。
具体实施方式
具体实施时,本发明技术方案所提供流程可由本领域技术人员采用计算机软件技术实现自动运行。为了更好地理解本发明的技术方案,下面结合附图和实施例对本发明做进一步的详细说明。
实施例提供的方法可应用于监控视频船只目标自动检测系统(简称系统):
参见图1,该系统主要包括监控视频获取模块、船只检测平台、应用平台。监控视频获取模块主要使用多个可见光监控摄像头获取海边区域的视频,并下传数据到船只检测模块。船只检测平台采用本发明提出的方法,进行船只目标的提取和自动检测,将船只目标异常等情况传入应用平台。根据应用平台中具体的船只分析平台、行为预测平台、异常事件处理平台和舰船监督平台等,对船只目标的分布、行动分析,做出合理预测和规划,完成相关任务。
参见图2,本发明实施例所提供方法包括以下步骤:
①监控视频数据采集。
监控视频数据的采集。本发明所需采集的数据主要为可见光下的沿海区域监控视频数据。对于采集到的视频数据,可通过解码器或代码获得每帧图像。
②视频数据的预处理和正负样本准备。
对于获取到的监控视频数据,需要进行预处理,方便后续数字图像处理的展开。预处理部分主要用图像平滑操作,本发明实施例采用中值滤波方法对视频每帧图像进行平滑。正负样本是为后续步骤的卷积神经网络训练准备,其具体过程如下:
第一步:利用步骤①得到的视频图像,具体实施时可通过旋转、平移等几何变换方式,对影像进行一定的扩充(实施例主要采用旋转方式,通过对原有图片按照180度旋转,获得加倍的影像数据量)。第二步:得到每个船只目标在影像中竖直的最小包围矩形的四个顶点坐标,作为正样本坐标,将对应影像和其上的所有目标坐标共同输出,作为正样本。第三步:在正样本周围随机截取其他区域,得到其竖直的最小包围矩形的四个顶点坐标,作为负样本坐标,将对应影像和其上的负样本坐标一同输出。
其中,竖直的最小包围矩形的四边分别与坐标轴横轴、纵轴平行。
③通过基于区域的卷积神经网络方法,输入视频里的船只目标样本到神经网络中,进行模型训练。
实施例中,将步骤①完成的船只目标的正负样本数据进行标准格式化,转换成结构化数据库格式,并输入到卷积神经网络中进行训练,得到监控视频下船只目标的训练结果模型。基于区域的卷积神经网络由多个交替的卷积层、池化层和全连接层组成,主要采用反向传播算法(bp算法),有一个输入层,多个隐藏层和一个输出层。用公式表示bp算法中两层之间的计算关系如下:
其中,i是输入层单元的索引值,j是隐藏层单元的索引值,
对于卷积神经网络中的卷积层,网络采用bp神经网络模式进行更新。在一个卷积层,上一层的特征图被一个可学习的卷积核进行卷积运算,然后通过一个激活函数,就可以得到输出特征图。具体加入卷积操作后的下层更新算法如下:
其中,mj表示输入层的所有选择集合。
卷积神经网络中除了卷积层,还有一个重要的运算过程,即池化过程与池化层的计算。池化过程即一个对大图像中不同位置的特征进行聚合统计的过程,该过程大大降低了特征冗余,减少统计特征维数。池化层的计算公式如下:
其中,d()表示池化过程的降采样函数,
④基于卡尔曼滤波的方法,根据t-1时刻船只检测最终结果,对t时刻的船只位置进行预测。
实施例中,利用卡尔曼滤波的理论过程如下:
对船只位置的预测过程定义卡尔曼滤波的状态方程和测量方程如下:
st=ast-1+wt-1
zt=hst+vt
其中,st和st-1分别代表时刻t、时刻t-1的状态值(即基于卡尔曼滤波的预测值),具体到每个船只状态有:st={xt,yt,dtx,dty},即包括该船只中心点横坐标xt、纵坐标yt和分别对时间的微分值dtx、dty。zt代表时刻t测量到的状态结果(深度学习检测到的结果)。a是状态转移矩阵,h是测量矩阵,wt-1表示时刻t-1的过程噪声,wt和vt分别表示时刻t的过程噪声和测量噪声,两者均定义为高斯噪声,其服从以下分布:
wt~n(0,qt)
vt~n(0,rt)
其中,n表示均值为0的正态分布,qt和rt分别代表wt和vt正态分布的协方差大小。本专利中qt取10-5,rt取10-1,为对st={xt,yt,dtx,dty}进行矩阵运算,取a和h如下:
根据t-1时刻的最终检测结果,基于卡尔曼滤波算法预测船只的t时刻状态
其中,
进一步地,可根据t时刻的深度学习检测结果(zt,即测量结果),更新卡尔曼增益值kt,并得到t时刻的修正状态值
kt=pt-ht(hpt-ht+rt)-13
修正状态值
⑤通过t时刻的卡尔曼滤波预测结果和t时刻的深度学习网络检测结果,共同确定t时刻的船只检测最终结果。
实施例中,基于深度学习网络和卡尔曼滤波方法获取检测结果具体策略流程图如图3,其详细过程如下:
a,设以t-1时刻的检测到的ξ个船只位置作为初始位置,根据④中提出的方法,获得t时刻的卡尔曼滤波预测结果
b,通过基于区域的卷积神经网络方法和步骤③训练好的船只模型,对t时刻的图像(在基于卷积的神经网络中输入图像)进行船只检测,该方法独立获得t时刻的深度学习检测结果,设检测得到μ个候选船只位置,即船只检测坐标boxdt。
c,根据t时刻的深度学习检测结果zt,和公式3,更新卡尔曼增益值kt和公式4、5,并得到t时刻的修正状态值
根据该状态值
d,设num为t时刻检测结果编号,经步骤b得到第num={1,...,μ}个船只检测坐标
其中,s代表面积大小。同时记录每个船只预测位置
e,通过步骤b的神经网络检测结果,对t时刻出现的新船只目标进行更新。对于步骤b所得每个船只检测坐标
具体实施时,获取当前时刻的船只检测最终结果后,可以提取后续待处理帧数据,返回步骤④,针对t+1时刻重新进行步骤④、⑤的步骤,以此循环,实现递归方法确定当前帧船只检测结果。
最终可以记录和存储船只位置并进行评价。
具体实施时,可采用计算机软件技术实现流程的自动运行。
至此,本专利所使用的基于深度学习网络和卡尔曼滤波的船只目标视频检测方法具体实施过程介绍完毕。
本文中所描述的具体实例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!