一种基于多源异构数据融合的社交网络链路预测方法与流程
本发明属于机器学习中的神经网络领域,是一种基于深度学习的方法,尤其是利用深度学习对基于地理位置信息的社交网络(localbasedsocialnetworks,lbsn)中的用户关系拓扑图和用户签到记录这两种异构数据进行融合,实现社交网络链路预测,并使用局部敏感哈希(localitysensitivehashing,lsh)提高深度学习进行训练的计算速度及降低存储开销。
背景技术:
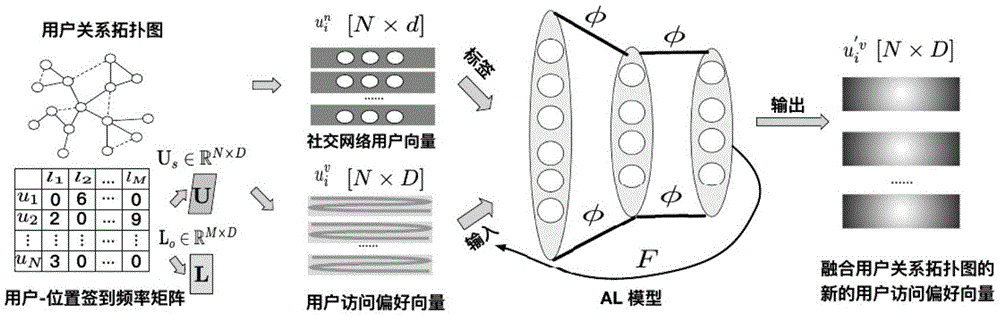
:社交网络链路预测(linkprediction,lp),简称链路预测,旨在从一个由好友关系构成的用户关系拓扑图中找出该图中丢失的边或者将来会出现的边。随着社交网络服务(socialnetworkservice,sns)和其他网络应用的迅速增长,网络数据无处不在。获取facebook、qq等app上的好友关系这类网络数据,可以构建用户关系拓扑图,该用户关系拓扑图可用于社交网络链路预测。同时,随着定位技术的发展,利用移动设备的gps定位功能可以采集用户的位置信息,这类位置信息结合定位的时间可形成用户签到记录。许多研究表明,用户签到记录也有助于社交网络链路预测。链路预测在信息推荐系统中扮演着重要的角色,主要用于社交网络分析中,通过链路预测可以获得置信度较高的好友,推荐给用户可能认识的人,能够显著提高用户的社交体验和忠诚度,并为企业带来巨大的经济效益。除了预测出用户关系拓扑图中的用户关联外,链路预测的方法和思想还可用于在已知部分节点类型的网络中预测出无标签节点的类型,这对于网络重组和结构功能的优化有重大价值。在传统的链路预测方法中,通常采用jaccard、欧式距离或余弦值来衡量两个用户节点的相似度,以此判定是否存在该链路。而这些方法都不够灵活。如果换了新的数据集,或者对原始数据集进行增加或删除数据则需要对所有数据进行重新计算,消耗大量的计算存储资源。深度学习可以灵活处理海量数据。基于深度学习的方法搭建的链路预测模型,可以通过输入海量的训练数据,对模型的参数进行优化,以得到训练好的模型进行预测工作。技术实现要素:本发明使用的lbsn数据集包含用户关系拓扑图和用户签到记录这两种不同结构的数据源。用户关系拓扑图由用户间的关系构成,用户间的关系称为链路(即点对),每条链路由两个用户节点的关系组成。用户签到记录由签到的用户节点、签到点经度、签到点纬度、签到时间和兴趣点(point-of-interest,poi)组成。本发明的目的旨在克服使用lbsn中单数据源进行链路预测时,预测结果不准确的问题。本发明的基本思路为,提出一种混合的框架,将lbsn中用户关系拓扑图和用户签到记录这两种异构数据进行融合实现链路预测,增强现有链路预测方法的预测效果。同时采用lsh对计算和存储的性能进行提升。基于上述发明思路,本发明提供一种基于多源异构数据融合的社交网络链路预测的方法,其包括以下步骤:s1,data_process(g)→tra,tes:从用户关系拓扑图g=(v,e)中提取出训练集tra和测试集tes。其中v表示拓扑图中用户节点的集合,e表示拓扑图中边的集合。若g中的两个用户ui和uj存在社交关系,则他们之间存在一条边,记为eij=(ui,uj);s2,采用网络表示学习方法,从tra的正样本g'中学习并获取v的社交网络用户向量,记为其中d为的维度;s3,根据用户签到记录s=(u,l),构建用户-位置签到频率矩阵其中u和l分别表示s中的用户集合和签到点集合,n是u中的用户数量,m是l中的签到点数量。再利用泊松矩阵分解获得在低维向量空间中的用户访问偏好向量,记为其中d为的维度;s4,为了捕获lbsn中这两类数据源的关联,类似锚链接(anchorlink)的方式,设计出一个改进的深度学习模型,称为al。作为样本,作为样本对应的标签,两种向量一起输入到al中进行多轮训练。利用最终训练好的al生成融合了g中拓扑信息的新的用户访问偏好向量s5,将和ui'v进行再次融合,输入到一个卷积神经网络(convolutionalneuralnetwork,cnn)中进行训练。最终将tes输入到训练好的cnn中进行链路预测,获取预测结果result。上述基于多源异构数据融合的社交网络链路预测的方法,所述步骤s1,目的在于获取tra和tes。链路预测可以看作是一个二分类问题,g中存在的链路视为正样本,而不存在的链路视为负样本。tra中的正样本是缺失了部分链路的用户关系拓扑图g'∈g,而这些缺失的链路将作为tes的正样本。具体包括以下分步骤:s11,进行数据清洗,使得lbsn中g和s中的用户保持一致;s12,从g中选择出一些链路作为tes正样本。同时保证从g中去除掉tes正样本后的g'∈g是连通的;将g'作为tra的正样本;s13,从g中随机选择一些不存在的链路作为负样本,按预定义的比例分配到tra和tes中。上述基于多源异构数据融合的社交网络链路预测的方法,所述步骤s3,目的在于获取具体包括以下分步骤:s31,利用s构建h。其中,h的行表示用户,列表示poi,h的值由用户访问对应的poi的次数填充;s32,对h进行泊松矩阵分解,可以得到反映用户访问偏好的矩阵和poi特征矩阵poi特征矩阵能反映某一poi被用户访问的情况。us的行作为上述基于多源异构数据融合的社交网络链路预测的方法,所述步骤s4,目的在于捕获lbsn中g和s之间的关联,实现融合。为了捕获这种关联,模型al的训练具体包括以下分步骤:s41,利用表示出tra中的用户节点,计算tra中用户点对的余弦均值cosori;s42,利用v和u中用户的一一对应关系来捕获g和s之间的关联。将样本及对应标签划分为多个批次(batch)并循环输入到多层感知机(multilayerperception,mlp)中进行训练;s43,通过多轮训练实现对模型al中的参数的调优。al训练好后,将输入al,输出ui'v。上述模型al的实现方法步骤s42中涉及两个计算函数。第一个计算函数是捕获v和u中用户一一对应关系的映射函数,记为该映射函数对应的损失函数为其中x表示样本,y表示真实值,a表示模型的输出值,n表示样本的数量。调用随机梯度下降算法优化全局权重参数w和全局偏差参数b,该调优过程分别记为其中σ表示激活函数,z是神经元的输入,表示为第二个计算函数是为了保证生成的ui'v不会产生偏移,即使用ui'v表示tra中用户点对计算的余弦均值要不小于cosori。因此引入余弦均值约束限制,记为其中和分别表示用户um和用户un的用户访问偏好向量,且g中存在emn。n(u)表示u中的用户数。该余弦均值约束限制对应的损失函数为全局权重参数w和全局偏差参数b的调优过程分别记为上述基于多源异构数据融合的社交网络链路预测的方法,所述步骤s5,目的在于将g和s再度融合实现存储消耗低、计算速度快的链路预测。具体包括以下分步骤:s51,将和ui'v拼接成一个向量s52,应用lsh将投影到一个二进制向量mi∈{0,1}m上,用户ui使用mi表示;s53,对于g中的任一条边eij=(ui,uj),采用相同方法获取mj作为用户uj的表示;s54,将mi和mj拼接以获取边eij的二进制向量表示mij(∈{0,1}2m)=[mi;mj];s55,将长度为2m的向量mij中的元素按行优先的顺序依次填入一个大小为n×n的方阵中,这个过程称为重塑。然后将这个方阵输入到一个卷积神经网络(convolutionalneuralnetwork,cnn)中进行训练;s56,将tes输入到训练好的cnn中进行链路预测。与现有技术相比,本发明具有以下有益效果:1、本发明基于多源异构数据融合的社交网络链路预测的方法,利用类似于锚链接的模型al,生成融合用户关系拓扑图的新的用户访问偏好向量,可以充分捕获社交网络用户向量和用户访问偏好向量之间的关联。al不仅能将同一用户的社交网络用户向量和用户访问偏好向量这两个向量进行对齐,还通过引入余弦均值的约束机制,以确保两个数据源中的用户向量融合后产生的新的用户访问偏好向量不会发生偏移。2、本发明基于多源异构数据融合的社交网络链路预测的方法,将lbsn中的两个数据源分别获得的社交网络用户向量和用户访问偏好向量进行拼接,并应用lsh将拼接的向量投影到一个二进制向量上,再把该二进制向量作为lbsn中用户节点的最终表示向量,并根据用户关系拓扑图中链路包含的点对关系,使用用户节点的最终向量进行拼接表示点对关系。最后将这个拼接的向量重塑为一个方阵,输入到cnn中,实现链路预测。lsh的应用能提高深度学习进行训练的计算速度并降低存储开销。附图说明图1为基于多层感知机(mlp)捕获社交网络用户向量和用户访问偏好向量之间关联的类锚链接模型al。图2为基于多源异构数据融合的社交网络链路预测的方法的整体模型架构。利用图1中生成的融合了用户关系拓扑图的新的用户访问偏好向量与社交网络用户向量进行拼接,并应用lsh将拼接的向量投影到一个二进制向量上,再把该二进制向量作为lbsn中用户节点的最终表示向量,并根据用户关系拓扑图中链路包含的点对关系,使用用户节点的最终向量进行拼接表示点对关系。最后将这个拼接的向量重塑为一个方阵,输入到cnn中。图3为不使用lsh和使用lsh时,基于多源异构数据融合的社交网络链路预测的方法的性能对比。其中(a)为内存消耗的对比,(b)为cpu消耗的对比,(c)为gpu消耗的对比,(d)为时间消耗的对比。(d)中的向量维度为输入到cnn的向量维度。术语解释lbsn是location-basedsocialnetwork的缩写,表示“基于位置的社会网络”。lbsn除了包含传统社会网络中人与人的联系外,还记录有用户签到的时间及地理位置等信息。poi是point-of-interest的缩写,表示“兴趣点”。在lbsn中,一个poi就是用户签到的一个地点。lsh是localitysensitivehashing的缩写,表示“局部敏感哈希”。它是一种针对海量高维数据的快速最邻近查找算法。具体实施方式以下结合附图对本发明作进一步描述。实施例本实施提供的基于多源异构数据融合的社交网络链路预测的方法,可用于包含了用户关系拓扑图和用户签到记录这两种数据源的数据集。以表1所示的真实世界的lbsn数据集,如foursquare(可以从http://snap.stanford.edu获取)为例进行实验。表1:多源异构数据融合的社交链路预测训练集的相关信息dataset#check_ins#pois#edges#usersfoursquare@nyc22,5631,9925,810588foursquare@tky38,7422,2129,6241,055gowalla@dc13,5944,7955,826880gowalla@chi10,3143,2692,542627brightkite75,5224,03833,0081,502图1为基于多层感知机(mlp)捕获社交网络用户向量和用户访问偏好向量之间关联的类锚链接模型al。如图1所示,首先使用foursquare中的用户关系拓扑图g代入步骤s1:data_process(g)→tra,tes,获取训练集tra和测试集tes。再将tra中的正样本g'代入步骤s2:其中可使用常见的网络学习表示方法,如node2vec,获得社交网络用户向量接下来先使用foursquare中的用户签到记录s代入步骤s3:获得用户访问偏好向量再将步骤s2和s3的输出和输入到模型al中,使用步骤s4:获取ui'v。表2:在三种真实数据集上进行社交链路预测的效果图2为基于多源异构数据融合的社交网络链路预测的方法的整体模型架构。如图2所示,将步骤s2和s4的输出和ui'v,输入进预测模型cnn中,使用步骤s5:获取最终的预测结果result。混合模型的链路预测效果见表2。#check_ins表示用户签到记录数量;#pois表示用户签到记录中的不同poi数量;#edges表示用户关系拓扑图中的链路数量;#users表示用户关系拓扑图(或用户签到记录)中用户的数量;foursquare@nyc表示数据集foursquare中区域为纽约市的数据;foursquare@tky表示数据集foursquare中区域为东京的数据;gowalla@dc表示数据集gowalla中区域为华盛顿的数据;gowalla@chi表示数据集gowalla中区域为芝加哥的数据;vec2link-是没有使用lsh的基于多源异构数据融合的社交网络链路预测的方法;vec2link+是使用了lsh的基于多源异构数据融合的社交网络链路预测的方法,与vec2link-进行对比,体现使用了lsh后,存储占用变低,计算速度提升的优势;average、hadamard、weighted-l1、weighted-l2是vec2link+的对比方法,其只使用lbsn中用户关系拓扑图的信息,实现方案可以参考文献【grover,aditya,andjureleskovec."node2vec:scalablefeaturelearningfornetworks."proceedingsofthe22ndacmsigkddinternationalconferenceonknowledgediscoveryanddatamining.acm,2016.】;jaccard是vec2link+的对比方法,用于比较有限样本集之间的相似性与差异性;walk2friend是vec2link+的对比方法,其只使用lbsn中用户签到记录的数据,实现方案可以参考文献【backes,michael,etal."walk2friends:inferringsociallinksfrommobilityprofiles."proceedingsofthe2017acmsigsacconferenceoncomputerandcommunicationssecurity.acm,2017.】。从表2中的试验结果可以看出,使用了本发明中基于多源异构数据融合的社交网络链路预测的方法,其预测效果要全面优于仅使用单数据源进行链路预测的效果。由此可知,本发明可以有效地克服在使用lbsn中单数据源进行链路预测时,预测结果不准确的问题,实现链路预测效果的提升。本发明采用深度学习的方法,将lbsn中用户关系拓扑图和用户签到记录这两种异构的数据源进行融合实现链路预测。同时采用lsh,以离散的二值向量表示用户节点,加速模型的计算速度并节约存储开销。本发明达到了计算速度快、存储消耗少、链路预测效果优于单源数据预测效果的目的。本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1