基于混合式内存结构的共享缓存替换算法及装置的制作方法
本发明涉及计算机领域,具体涉及一种基于混合式内存结构的共享缓存替换算法及装置。
背景技术:
随着互联网不断发展的需求,数据中心服务器(idc)迅速发展起来,成为了新世纪中国乃至世界互联网中不可或缺的重要一环,随着数据中心服务器中cpu核心数量的增加,并发运行线程数也在增加,数据中心服务器需要大容量的内存来同时提供给多个线程的工作集。然而,现行的ddr4及lpddr4存储器都是以既有的dram设计为基础,其中许多技术已沿用长达十余年,而今无论是系统总带宽或是处理器等工作环境都不可同日而语,并且众所周知的dram缺点,高刷新能耗和有限的可扩展性,使得仅仅采用dram的解决方案对于构建大容量存储器系统起不了太大作用。
而缓存的工作原理是当cpu读取数据时,首先要从高速缓存中寻找,找到后就立即读取后送给cpu处理,如果寻找失败,就从内存中读取后送往cpu进行处理,只是内存的速度相对于高速缓存会慢许多,与此同时将这个数据所在的数据块调入高速缓存中,这样以便于对数据的读取都从缓存中进行,不用再调用内存,正因为这样的读取机制使得cpu读取缓存的命中率很高,同时cpu下一次要读取的数据90%都在高速缓存中,只有小部分需要再次去内存中读取,然后重复以上的工作,这在很大程度上节约了cpu直接去访问内存进行读取的时间,因此cpu的读取速率也相当快,总体上看,cpu读取数据的顺序是先读取高速缓存,然后再读取内存。
有鉴于此,发展新的解决方案成为眼下业界的共识,混合存储器遂成业界关注重点,但混合内存对共享缓存也带来了新的问题,因为nvm的延迟时间过长,所以nvm数据的高速缓存未命中的成本就高于dram数据高速缓存未命中成本。因此,如果有大量的nvm数据未命中,则会大大降低共享缓存的性能,并且缓存的高命中率也是提升混合存储器性能的关键。
技术实现要素:
有鉴于此,为了解决上述问题,本发明提供一种基于混合式内存结构的共享缓存替换算法及装置,该算法针对利用dram和nvm的优点所构建的混合存储系统,采取混合内存感知缓存划分技术来调整共享缓存空间
为实现上述目的及其他目的,本发明提供一种基于混合式内存结构的共享缓存替换算法,所述缓存包括nvm区,包括以下步骤:
判断l1cache发送请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
若请求的数据不在llc中,则判断请求的数据是否在nvm中,若请求的数据在nvm中,则将其插入共享缓存的lru位置,若请求的数据不在nvm中,则将其插入共享缓存的mru位置。
为实现上述目的及其他目的,本发明还提供一种基于混合式内存结构的共享缓存替换装置,所述缓存包括nvm区,包括:
接收模块,接收l1cache发送的请求;
第一判断模块,用于判断请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
第二判断模块,用于在请求的数据不在llc中时,判断请求的数据是否在nvm中;
数据插入模块,用于在第二判断模块判定请求数据在nvm中时,将其插入共享缓存的lru位置;在第二判断模块判定请求数据不在nvm中时,将其插入共享缓存的mru位置。
为实现上述目的及其他目的,本发明还提供一种基于混合式内存结构的共享缓存替换算法,所述缓存包括nvm区和dram区,包括以下步骤:
判断l1cache发送请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
若请求的数据不在llc中,则判断llc中的nvm行计数器是否大于thigh,若nvm行计数器大于thigh则判断请求的数据是否属于nvm,若请求的数据属于nvm,则从nvm区中采取lru策略来挑选替换的块,若请求的数据不属于,则从llc上采取lru策略来挑选替换的块,并返回数据至l1请求者;
若llc中的nvm行计数器小于thigh,则判断llc中的nvm行计数器是否小于tlow,若nvm行计数器小于tlow,则判断请求的数据是否属于dram,若请求的数据属于dram,则从dram区中采取lru策略来挑选替换的块,并返回数据至l1请求者,若请求的数据不属于dram,则从llc上采取lru策略来挑选替换的块,并返回数据至l1请求者;若nvm行计数器大于tlow,则在llc上采用lru策略来挑选替换块,并返回数据至l1请求者。
可选地,通过来自不同类型存储器的数据来调整nvm分区大小;当数据不命中发生并触发替换时,选择适当类型的缓存块位置的数据作为被替换的数据。
为实现上述目的及其他目的,本发明还提供一种基于混合式内存结构的共享缓存替换装置,所述缓存包括nvm区和dram区,包括:
接收模块,接收l1cache发送的请求;
第三判断模块,用于判断请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
第四判断模块,用于在第三判断模块判定请求的数据不在llc中,判断llc中的nvm行计数器是否大于thigh;
第五判断模块,用于在第四判断模块判定llc中的nvm行计数器大于thigh时判定请求的数据是否属于nvm;
第一执行模块,用于在第五判断模块判定请求的数据属于nvm时,从nvm区中采取lru策略来挑选替换的块;
第二执行模块,用于在第五判断模块判定请求的数据不属于nvm时,从llc上采取lru策略来挑选替换的块,并返回数据至l1请求者;
第六判断模块,用于在第四判断模块判定llc中的nvm行计数器小于thigh时判定llc中的nvm行计数器是否小于tlow;
第七判断模块,用于在第六判断模块判定nvm行计数器小于tlow时判断请求的数据是否属于dram;
第三执行模块,用于在第七判断模块判定请求的数据属于dram时,从dram区中采取lru策略来挑选替换的块,并返回数据至l1请求者;
第四执行模块,用于在第七判断模块判定请求的数据不属于dram时,从llc区中采取lru策略来挑选替换的块,并返回数据至l1请求者;
第五执行模块,用于在第六判断模块判定nvm行计数器大于tlow时,在llc上采用lru策略来挑选替换块,并返回数据至l1请求者。
可选地,通过来自不同类型存储器的数据来调整nvm分区大小;当数据不命中发生并触发替换时,选择适当类型的缓存块位置的数据作为被替换的数据。
由于采用了上述技术方案,本发明具有如下的优点:
随着目前数据发展的速度,以及人们对存储器的要求日渐提高的现状,服务器需要大容量的主内存来容纳大量的工作集。dram和nvm相结合的混合存储器是相对比较完善的候选者,这种混合式存储器利用了dram的低延迟与nvm良好的扩展性的优点,从而克服了单个使用dram和nvm的局限性。但是混合内存也带来了新的问题,因为nvm的延迟时间过长,所以nvm数据的高速缓存未命中的成本就高于dram数据的高速缓存未命中成本,因此本发明实现的两种算法改进了缓存的划分,更有效力地利用存储器,为共享缓存技术提供了参考。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述:
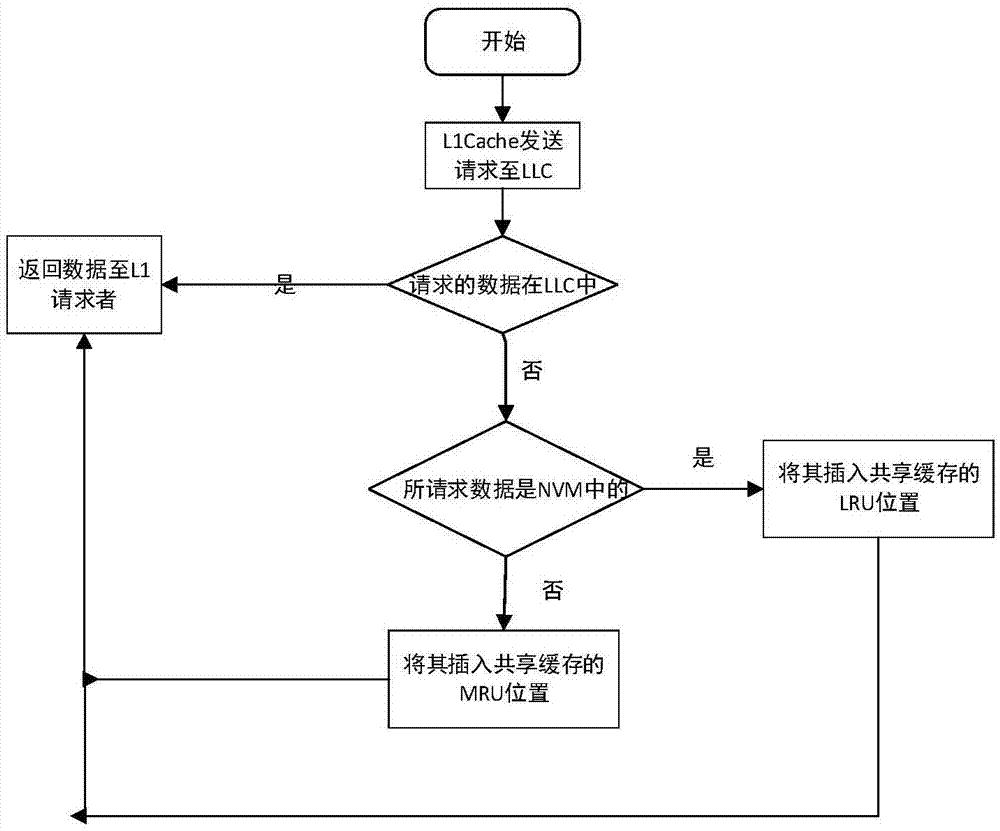
图1是hapbypass算法流程图;
图2是hapstatic算法流程图;
图3是hapbypass不同缓存机制下各benchmark加速比;
图4是hapbypass不同缓存机制下各benchmark的ipc值;
图5是hapbypass不同缓存机制下各benchmark的共享缓存缺失率;
图6是hapbypass不同缓存机制下各benchmark加速比;
图7是hapbypass不同缓存机制下各benchmark的ipc值;
图8是hapbypass不同缓存机制下各benchmark的共享缓存缺失率。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
本发明在了解各种存储器的利弊后,针对利用dram和nvm的优点所构建的混合存储系统,采取混合内存感知缓存划分技术hap来调整共享缓存空间。
hap技术是将高速缓存块与nvm和dram区分开来,它将缓存空间逻辑划分为dram和nvm两个分区,分区中的行数表示分区大小。例如,如果nvm进入llc,则hap认为nvm分区大小增加。hap将nvm分区大小限制在适当的范围内(tlow~thigh)。当nvm的行数小于tlow时,由于nvm数据未命中次数显著提高,相应地,性能就显著降低。同样地,当nvm的行数大于thigh时,则由于dram数据未命中次数的显著提高,相应地,性能也显著降低。因此,hap技术根据工作负载行为调整阈值。
具体地,在一实施例中,一种基于混合式内存结构的共享缓存替换算法(hapbypass算法),所述缓存包括nvm区,包括以下步骤:
判断l1cache发送请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
若请求的数据不在llc中,则判断请求的数据是否在nvm中,若请求的数据在nvm中,则将其插入共享缓存的lru位置,若请求的数据不在nvm中,则将其插入共享缓存的mru位置。
更加具体地,在本实施例中,通过在gem5多核模拟器中运行speccpu2006,作为多线程应用程序,根据性能评估参数给出实验的统计数据。hapbypass算法包括:
1、gem5的前序工作:使用ubuntu版本是15.04或者是更高的版本,安装必要的软件包,检测和构建gem5,下载磁盘映象和linux内核文件作为在gem5中alpha全系统仿真的所需的文件,最后运行gem5。
2、gem5中实现细节:首先在gem5/src/mem/cache/tags中添加了脚本hap_bypass.cc。主要是在lru算法中的插入缓存块部分进行设计,以下介绍了该脚本的核心算法。
1)将nvm数据移到mru位置
2)将dram数据移到lru位置
3、分别在gem5/src/mem/cache/tags目录下的sconscipt和tags.py中添加hap_bypass的相关信息,在gem5/configs/common/cacheconfig.py中也添加hap_bypass的相关信息。
在一实施例中,本发明还提供一种基于混合式内存结构的共享缓存替换装置,所述缓存包括nvm区,包括:
接收模块,接收l1cache发送的请求;
第一判断模块,用于判断请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
第二判断模块,用于在请求的数据不在llc中时,判断请求的数据是否在nvm中;
数据插入模块,用于在第二判断模块判定请求数据在nvm中时,将其插入共享缓存的lru位置;在第二判断模块判定请求数据不在nvm中时,将其插入共享缓存的mru位置。
在另一实施例中,本发明提供一种基于混合式内存结构的共享缓存替换算法(hapstatic算法),所述缓存包括nvm区和dram区。
hapstatic算法通过来自不同类型存储器的数据来调整nvm分区大小。当数据不命中发生并触发替换时,hapstatic必须选择适当类型的缓存块位置的数据作为被替换的数据。本发明提出的hapstatic算法是在lru替换算法基础上进行改进,这是一种静态划分缓存空间的算法,是在算法中运行共享缓存划分dram与nvm为不同比例。
hapstatic算法分为以下三种情况:
1)nvm缓存行计数器numnvmlines的当前值大于thigh。这意味着llc中具有的nvm数据比它应有的数量更多。在这种情况下,不应该拥有更多的nvm数据。因此,如果未命中的数据是属于nvm,则hapstatic从nvm中采用传统的lru算法来挑选替换的行。
2)nvm缓存行计数器numnvmlines的当前值小于tlow。这意味着llc种具有的nvm数据比它应有的数量更少。在这种情况下,不应该再容纳更多的dram数据。因此,如果未命中的数据属于dram,则hapstatic从dram中采用传统的lru算法来挑选替换的行。
3)除了这两种情况,hapstatic总是直接在llc种采用lru算法来选择所要替换的行,而不用区分其类型。在这样的做法中,hap可以调整分区大小,同时尽量排除最近最少使用的行。例如,假设nvm线路计数器超过thigh,并且dram数据发生未命中。在这种情况下,即使线路是dram,hap也会排除lru位置上的缓存行,而不是驱逐不在lru位置的nvm。hapstatic算法流程图如下图2所示。
包括以下步骤:
判断l1cache发送请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
若请求的数据不在llc中,则判断llc中的nvm行计数器是否大于thigh,若nvm行计数器大于thigh则判断请求的数据是否属于nvm,若请求的数据属于nvm,则从nvm区中采取lru策略来挑选替换的块,若请求的数据不属于,则从llc上采取lru策略来挑选替换的块,并返回数据至l1请求者;
若llc中的nvm行计数器小于thigh,则判断llc中的nvm行计数器是否小于tlow,若nvm行计数器小于tlow,则判断请求的数据是否属于dram,若请求的数据属于dram,则从dram区中采取lru策略来挑选替换的块,并返回数据至l1请求者,若请求的数据不属于dram,则从llc上采取lru策略来挑选替换的块,并返回数据至l1请求者;若nvm行计数器大于tlow,则在llc上采用lru策略来挑选替换块,并返回数据至l1请求者。
在本实施例中,通过在gem5多核模拟器中运行speccpu2006,作为多线程应用程序,根据性能评估参数给出实验的统计数据。hapbypass算法包括:
1、gem5实现细节:在gem5/src/mem/cache/tags/目录下添加新的脚本文件,hap_static.py。主要是在lru算法中的寻找替换缓存块部分进行设计。
2、分别在gem5/src/mem/cache/tags目录下的sconscipt和tags.py中添加hap_static的相关信息,在gem5/configs/common/cacheconfig.py中也添加hap_static的相关信息。
python脚本需要一层一层的调用,对于上述的src文件和configs文件都是gem5中的配置文件,所以需一层一层的对它们进行修改,再将参数一层一层传入运行测试程序,这些操作都是为了确保运行测试程序时正确调用,以保证最后测试结果不会出错。
hapstatic算法是将共享缓存划分为nvm和dram两个分区,通过设定两个分区的不同比例来提高程序性能。通过来自不同类型存储器的数据来调整nvm分区大小;当数据不命中发生并触发替换时,选择适当类型的缓存块位置的数据作为被替换的数据。
在另一实施例中,本发明还提供一种基于混合式内存结构的共享缓存替换装置,所述缓存包括nvm区和dram区,包括:
接收模块,接收l1cache发送的请求;
第三判断模块,用于判断请求的数据是否在llc中,若请求的数据在llc中,则返回数据至l1请求者;
第四判断模块,用于在第三判断模块判定请求的数据不在llc中,判断llc中的nvm行计数器是否大于thigh;
第五判断模块,用于在第四判断模块判定llc中的nvm行计数器大于thigh时判定请求的数据是否属于nvm;
第一执行模块,用于在第五判断模块判定请求的数据属于nvm时,从nvm区中采取lru策略来挑选替换的块;
第二执行模块,用于在第五判断模块判定请求的数据不属于nvm时,从llc上采取lru策略来挑选替换的块,并返回数据至l1请求者;
第六判断模块,用于在第四判断模块判定llc中的nvm行计数器小于thigh时判定llc中的nvm行计数器是否小于tlow;
第七判断模块,用于在第六判断模块判定nvm行计数器小于tlow时判断请求的数据是否属于dram;
第三执行模块,用于在第七判断模块判定请求的数据属于dram时,从dram区中采取lru策略来挑选替换的块,并返回数据至l1请求者;
第四执行模块,用于在第七判断模块判定请求的数据不属于dram时,从llc区中采取lru策略来挑选替换的块,并返回数据至l1请求者;
第五执行模块,用于在第六判断模块判定nvm行计数器大于tlow时,在llc上采用lru策略来挑选替换块,并返回数据至l1请求者。
于本实施例中,基于传统的lru替换建立llc缓存,并将其集成到gem5中。修改主内存模块来建立模型模拟2gb混合内存:第一个512mb的容量是作为dram,剩下的1536mb是nvm。将hap与传统lru替换策略的实现进行比较。
在本发明中在speccpu2006整点和浮点基准测试程序中挑选了16个作为本次的工作负载。speccpu2006年的基准是spec的下一代,是一种产业标准化、cpu密集型基准测试套件,强调系统的处理器、内存子系统和编译器。
分别从加速比、ipc和共享缓存的未命中率这三个角度进行分析研究。
1)加速比:加速比是用来衡量在不同缓存划分机制下的性能提升效果。计算公式为:
2)ipc:ipc是指cpu每个时钟周期内所执行的指令数。ipc的值越高,表明性能越好。从ipc角度来看,不同的benchmark在采用lru和hapbypass是不同的。
3)缺失率:从命中率和缺失率的角度来看,缺失率越高性能越差,用hapbypass和hapstatic和lru算法在不同benchmark情况下会有所不同。
下面通过在gem5多核模拟器中运行speccpu2006,作为多线程应用程序,根据性能评估参数评测hapbypass和hapstatic算法的有效性。
表1模拟器基本配置
表2speccpu2006整点基准测试程序
表3speccpu2006浮点基准测试程序
hapbypass算法性能分析:
从加速比的角度来看,如图3所示,横坐标为benchmark的类型,纵坐标为加速比,此图展现了不同benchmark在不同共享缓存机制的加速比。显而易见,对于gcc来说,采用hapbypass算法明显比传统lru算法更优,加速比为1.177,也就是在速度层面来看,hapbypass算法提高了大约17.7%。其次是omnetpp,加速比接近1.1,hapbypass算法提高了大约10%,对于namd、hmmer、sjeng、gemsfdtd、libquantum、astar、sphinx3来说,hapbypass算法提高了不到1%。
从ipc角度看,如图4所示,可看出,gcc、hmmer、sjeng、gemsfdtd、omnetpp、astar、sphinx3的ipc在使用hapbypass算法时,每个时钟周期执行的指令数得到了提升,意味着在hapbypass算法在lru算法基础上有了改进,最高的是omnetpp,采用hapbypass时ipc较lru时提升了17.72%。
从命中率和缺失率的角度来看,用hapbypass算法和lru算法在不同benchmark情况下会有所不同,如图5所示,横坐标表示benchmark类型,纵坐标是共享缓存缺失率,显而易见,gcc与omnetpp采用了hapbypass算法后缓存命中率有所提高,gcc提高了20%,omnetpp提高了40%左右。
hapstatic算法性能分析:
从加速比的角度看,如图6所示,采用hapstatic算法在不同的dram与nvm比例时,加速比是不同,明显看出,对于gcc来说,当dram与nvm比例为5:7时加速比得到最大值,同时对于hmmer来说,dram与nvm比例为3:5时加速比得到最大值,因此对不不同的测试程序,当采取不同dram与nvm比例所达到的效果是不同的,看其他benchmark也可知,hapstatic算法中总有一种比例划分会使得其加速比大于1,也就是性能较lru相比会有所提高。
从ipc角度来看,不同的benchmark的在采用lru和hapstatic是不同的。ipc的值越高,表示性能越好,如图7所示,可看出,除了gromacs外别的benchmark的ipc都有所提高,不同的dram,nvm不同划分比例下ipc会有所不同。
从命中率和缺失率的角度来看,用hapstatic算法和lru算法在不同benchmark情况下会有所不同,并且dram,nvm不同划分比例时缺失率也会有所差别,如图8所示,横坐标表示benchmark类型,纵坐标是共享缓存缺失率,显而易见,gcc与libquantum采用了hapstatic算法后与之前lru算法缺失率并没有太大变化,都居高不下,h264ref采用hapbypass算法后缓存命中率有所提高,不管dram,nvm划分比例为多少,缺失率都降低了。dram,nvm不同划分比例影响最大的有6个,分别是namd、soplex、hmmer、h264ref、omnetpp、sphinx3,在不同的划分比例时,除了h264ref缺失率都降低外,其他几个都忽高忽低。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的保护范围当中。
- 还没有人留言评论。精彩留言会获得点赞!