一种文本信息处理的方法、装置及存储介质与流程
本发明涉及自然语言处理技术,尤其涉及一种文本信息处理的方法、装置及存储介质。
背景技术:
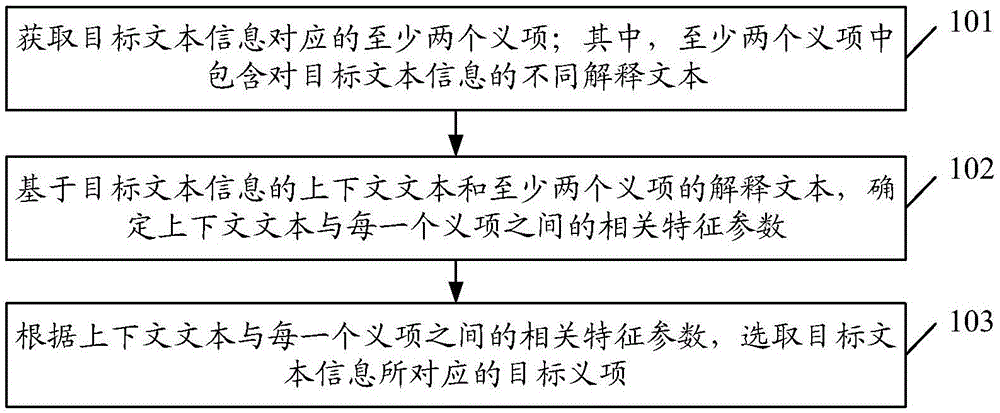
:词义消歧(wordsensedisambiguation,wsd)是自然语言处理领域的一个关键问题,对于机器翻译、信息检索、文本分类等众多研究领域都有重要的推动作用。词义消歧通过对文本中的每个多义词进行词义的明确,让计算机理解多义词在特定的上下文环境中具体代表的语义。文本信息处理需要解决以下三个关键问题:(1)如何判断一个词是不是多义词;(2)对每个多义词,如何确定其义项数量并进行有效的区分;(3)对出现在具体语境中的每个多义词如何确定其真正表达的词义。现有的词义消歧方法主要分为三类,有监督的词义消歧,无监督的词义消歧,基于语义词典的词义消歧方法。然而,有监督的词义消歧方法需要人工词义标注的语料库来训练分类器模型,需要耗费大量人力做词语的标注工作。无监督的词义消歧方法,需要对每个词语做大量的聚类处理,计算量非常大,而且词义类别数量的确定存在着一定的误差,词义消歧的精度较低。基于语义词典的词义消歧方法受限于词典中的词语数量,只能对文本中包含在语义词典中的词语进行词义的标注。语义词典一经建立,不会频繁的更新,语义词典在扩展性和动态更新方面的能力远不能满足当前词义消歧的需求,例如在机器翻译、语音识别等领域,要求词语的词义分类信息始终处于比较新的状态,才能产生更智能的应用。技术实现要素:为解决上述技术问题,本发明实施例期望提供一种文本信息处理的方法、装置及存储介质,能够快速确定目标文本信息的所表达的真实含义。本发明的技术方案是这样实现的,本发明实施例提供了一种文本信息处理的方法,包括:获取目标文本信息对应的至少两个义项;其中,所述至少两个义项中包含对所述目标文本信息的不同解释文本;基于所述目标文本信息的上下文文本和所述至少两个义项的解释文本,确定所述上下文文本与每一个义项之间的相关特征参数;根据所述上下文文本与每一个义项之间的相关特征参数,选取所述目标文本信息所对应的目标义项。上述方案中,所述基于所述目标文本信息的上下文文本和所述至少两个义项的解释文本,确定所述上下文文本与每一个义项之间的相关特征参数;包括:对所述目标文本信息的上下文文本进行分词处理,得到第一词语集合;基于所述第一词语集合和所述至少两个义项的解释文本,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数;将所述第一词语集合与每一个义项的解释文本之间的相关特征参数,作为所述上下文文本与每一个义项之间的相关特征参数。上述方案中,所述基于所述第一词语集合和所述至少两个义项的解释文本,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数,包括:计算所述第一词语集合中每一个词语的权重值;计算所述第一词语集合中每一个词语在第一解释文本中的逆文本频率指数tf-idf;其中,所述第一解释文本为所述至少两个义项的解释文本中任一个解释文本;基于所述第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数。上述方案中,所述基于所述第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数,包括:基于所述第一词语集合中每一个词语的权重值和每一个词语在所述第一解释文本中的tf-idf,计算每一个词语与所述第一解释文本之间的相关特征参数;基于每一个词语与所述第一解释文本之间的相关特征参数,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数。上述方案中,所述获取目标文本信息对应的至少两个义项,包括:从网络侧在线获取目标文本信息对应的至少两个义项。本发明实施例中还提供了一种文本信息处理装置,所述装置包括:处理器和存储器;其中,所述处理器用于执行存储器中存储的文本信息处理程序,以实现以下步骤:获取目标文本信息对应的至少两个义项;其中,所述至少两个义项中包含对所述目标文本信息的不同解释文本;基于所述目标文本信息的上下文文本和所述至少两个义项的解释文本,确定所述上下文文本与每一个义项之间的相关特征参数;根据所述上下文文本与每一个义项之间的相关特征参数,选取所述目标文本信息所对应的目标义项。上述方案中,所述处理器具体用于执行存储器中存储的文本信息处理程序,以实现以下步骤:对所述目标文本信息的上下文文本进行分词处理,得到第一词语集合;基于所述第一词语集合和所述至少两个义项的解释文本,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数;将所述第一词语集合与每一个义项的解释文本之间的相关特征参数,作为所述上下文文本与每一个义项之间的相关特征参数。上述方案中,所述处理器具体用于执行存储器中存储的文本信息处理程序,以实现以下步骤:计算所述第一词语集合中每一个词语的权重值;计算所述第一词语集合中每一个词语在第一解释文本中的逆文本频率指数tf-idf;其中,所述第一解释文本为所述至少两个义项的解释文本中任一个解释文本;基于所述第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数。上述方案中,所述处理器具体用于执行存储器中存储的文本信息处理程序,以实现以下步骤:基于所述第一词语集合中每一个词语的权重值和每一个词语在所述第一解释文本中的tf-idf,计算每一个词语与所述第一解释文本之间的相关特征参数;基于每一个词语与所述第一解释文本之间的相关特征参数,计算所述第一词语集合与每一个义项的解释文本之间的相关特征参数。上述方案中,所述处理器具体用于执行存储器中存储的文本信息处理程序,以实现以下步骤:从网络侧在线获取目标文本信息对应的至少两个义项。本发明实施例中还提供了一种文本信息处理装置,所述装置包括:获取单元,用于获取目标文本信息对应的至少两个义项;其中,所述至少两个义项中包含对所述目标文本信息的不同解释文本;处理单元,用于基于所述目标文本信息的上下文文本和所述至少两个义项的解释文本,确定所述上下文文本与每一个义项之间的相关特征参数;选取单元,根据所述上下文文本与每一个义项之间的相关特征参数,选取所述目标文本信息所对应的目标义项。本发明实施例中还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现前述方法的步骤。本发明实施例中提供的上述技术方案,利用目标文本信息的上下文文本与不同义项之间的相关特征参数,来衡量上下文文本与不同义项的解释文本之间的相似度,确定具有最大相似度的义项所表达的含义即为目标文本信息在文本中的真实含义,无需事先训练语料,无需人为参与,提高了目标文本信息辨识速度和效率。附图说明图1为本发明实施例中文本信息处理的方法的第一流程示意图;图2为本发明实施例中文本信息处理的方法的第二流程示意图;图3为本发明实施例中相关特征参数的计算流程示意图;图4为本发明实施例中文本信息处理装置的第一组成结构示意图;图5为本发明实施例中文本信息处理装置的第二组成结构示意图。具体实施方式为了能够更加详尽地了解本发明实施例的特点与技术内容,下面结合附图对本发明实施例的实现进行详细阐述,所附附图仅供参考说明之用,并非用来限定本发明实施例。实施例一如图1所示,文本信息处理的方法包括:步骤101:获取目标文本信息对应的至少两个义项;其中,至少两个义项中包含对目标文本信息的不同解释文本;步骤102:基于目标文本信息的上下文文本和至少两个义项的解释文本,确定上下文文本与每一个义项之间的相关特征参数;步骤103:根据上下文文本与每一个义项之间的相关特征参数,选取目标文本信息所对应的目标义项。这里,步骤101至步骤103的执行主体可以为文本信息处理装置的处理器。实际应用中,获取义项的方法为:从网络侧在线获取目标文本信息对应的至少两个义项。这里,目标信息文本可以为任何一种文字语言中的字、词、成语、短语等,由于文字在使用过程中存在很多“一词多义”的歧义词,因此,需要识别这些歧义词在文本中所表达的真实含义。至少两个义项可以包括在网络侧检索到的与目标文本信息对应的所有义项,每一个义项中包含了解释文本,用于解释目标文本信息所表达的不同含义。采用在线获取义项的方法词源丰富,能够覆盖绝大部分文本信息处理的需求,而且能够不断地动态更新;无需事先训练语料,无需人为参与,提高了目标文本信息辨识速度和效率。示例性的,联网后从百度百科、维基百科等网站中检索目标文本信息对应的所有义项。如:从百度百科中检索中文词语“苹果”,共有得到12个义项,每一个义项中包含了具体的解释文本。例如,“苹果”的义项中所表达的含义有:科技公司、水果和电影名称等。“仪表”的义项中所表达的含义有:人的外表;测定温度、气压等的仪器,在汉英机器翻译中,“仪表”可译成appearance或meter。另外,在每一个义项中还包含了对这些歧义词的具体解释文本。在一些实施例中,获取义项的方法为:从离线数据库中获取目标文本信息的至少两个。这里,离线数据库中预先存储了词典数据,词典中收录了不同文本信息所对应的至少一个义项。本发明实施例中,虽然离线获取义项的方法也具有较高的处理速度,但离线数据库中保存的词典数据有限,仍需要定时对离线数据库进行更新,才能更好的保证文本信息处理的准确性和快速性。实际应用中,步骤102具体可以包括:目标文本信息所在文本中以目标文本信息为中心,截取紧邻目标文本信息的前n个字符,截取紧邻目标文本信息的后m个字符;其中,n和m均取大于1的整数;前n个字符、目标文本信息和后m个字符组成目标文本信息的上下文文本。实际应用中,基于目标文本信息的上下文文本和至少两个义项的解释文本,确定上下文文本与每一个义项之间的相关特征参数,包括:对目标文本信息的上下文文本进行分词处理,得到第一词语集合;基于第一词语集合和至少两个义项的解释文本,计算第一词语集合与每一个义项的解释文本之间的相关特征参数;将第一词语集合与每一个义项的解释文本之间的相关特征参数,作为上下文文本与每一个义项之间的相关特征参数。这里,第一词语集合中包含上下文文本中所有的有效词语,分词处理除了用于将文本分割成词语之外还用于剔除文本中的停用词以及标点符号,停用词是对上下文文本意思没有多大贡献,或起到连接作用的一些字词,如:的、了、呢等。示例性的,目标文本信息c的上下文文本对应的第一词语集合c={c1,c2,...,cn},目标文本信息c为第一词语集合中任意一个词语。在百度百科中目标文本信息c对应的义项数量为m,所有义项的解释文本集合为d={d1,d2,...,dm},对于d中任意一个解释文本dk,k=1,2,...,m。进一步地,计算第一词语集合中每一个词语的权重值;计算第一词语集合中每一个词语在第一解释文本中的tf-idf;其中,第一解释文本为至少两个义项的解释文本中任一个解释文本;基于第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算第一词语集合与每一个义项的解释文本之间的相关特征参数。示例性的,先对上下文文本进行分词处理,去掉停用词,得到上下文文本对应的第一词语集合c={c1,c2,...,cn},其中,每一个词语的权重值计算公式为:其中,w(ci)为第一词语集合中第i个词语ci的权重值,count(ci)为第i个词语在上下文文本中出现的次数,为上下文文本中第一词语集合中的所有词语出现的总次数。计算包含第一词语集合中第i个词语ci(i=1,2,...,n)的义项数量vi,以及ci在dk中的频率ni,计算第i个词语ci在每一个义项的解释文本中的tf-idf,计算公式如下:其中,tfidf(ci)为第i个词语ci在解释文本中的tf-idf,ndk为解释文本dk所包含的词语总数。也就是说,在计算tf-idf之前需要对解释文本dk进行分词处理,得到第二词语集合,第二词语集合中包含解释文本dk中所有的词语,根据第二词语集合确定解释文本dk中的词语总数ndk。进一步地,基于第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算每一个词语与第一解释文本之间的相关特征参数;基于每一个词语与第一解释文本之间的相关特征参数,计算第一词语集合与每一个义项的解释文本之间的相关特征参数。示例性的,计算第i个词语ci与解释文本dk之间的相关特征参数s(ci),计算公式如下:s(ci)=w(ci)×tfidf(ci)(3)计算目标文本信息c的上下文文本与解释文本dk之间的相关特征参数score(c,dk),计算公式如下:这里,相关特征参数score(c,dk)用于衡量目标文本信息c的上下文文本与解释文本dk的文本相似度。根据计算得到的目标文本信息c的上下文文本与每一个义项中解释文本之间的相关特征参数,确定相关特征参数最大值的义项,该义项中的解释文本与目标文本信息c的上下文文本具有最大文本相似度,该义项所对应的含义即为目标文本信息所在文本中的含义。采用上述技术方案,利用目标文本信息的上下文文本与不同义项之间的相关特征参数,来衡量上下文文本与不同义项的解释文本之间的相似度,确定具有最大相似度的义项所表达的含义即为目标文本信息在文本中的真实含义,无需事先训练语料,无需人为参与,提高了目标文本信息辨识速度和效率。实施例二为了能更加体现本发明的目的,在本发明实施例一的基础上,进行进一步的举例说明,如图2所示,文本信息处理方法具体包括:步骤201:从网络侧在线获取目标文本信息对应的至少两个义项。这里,目标文本信息以歧义词为例进行举例说明,歧义词是指具有至少两个不同含义的词语。在线获取义项的方法包括:首先确定文本中一个歧义词,先获取歧义词对应的所有义项。例如,可通过百度百科api或者通过网络链接抓取网页数据,网络链接为:https://baike.baidu.com/item/待识别词?force=1,获取当前词语所有义项信息。以“苹果”为例,通过解析https://baike.baidu.com/item/苹果?force=1,得到苹果义项信息如表1所示,共有12个义项。其中data-lemmaid是“苹果”不同含义的标识编号。表1词语“苹果”在百度百科中的所有义项编号data-lemmaid解释文本15670蔷薇科苹果属果实26011208韩国2008年康理贯执导电影36011224苹果产品公司49976487动漫《男子高中生的日常》中角色519927344谢和弦、e-so演唱歌曲614822460蔷薇科苹果属果树712641327安与骑兵演唱歌曲86011191伊朗1998年莎米拉·玛克玛尔巴夫执导电影920587748minecraft中的食物类物品1017609283邓丽欣演唱歌曲1160111762007年李玉执导电影1210079481网游《天堂梦》中人物根据词语和每个义项的data-lemmaid,可以获取词语各义项的解释文本,链接地址格式为:https://baike.baidu.com/item/待识别词/data-lemmaid。以“苹果”的第一个义项为例,通过解析https://baike.baidu.com/item/苹果/5670,可以得到苹果(蔷薇科苹果属果实)更具体解释文本为:苹果(学名:maluspumila)是水果的一种,是蔷薇科苹果亚科苹果属植物,其树为落叶乔木。苹果的果实富含矿物质和维生素,是人们经常食用的水果之一。苹果是一种低热量食物,每100克只产生60千卡热量。苹果中营养成分可溶性大,易被人体吸收,故有“活水”之称。其有利于溶解硫元素,使皮肤润滑柔嫩。据说“每天一苹果,医生远离我”。根据联合国粮农组织统计,2013年全世界的苹果产量为8082万吨,超过葡萄的7718万吨,排世界第二位(第一位是香蕉:1.067亿吨)。毫无疑问,苹果是温带水果之王。苹果营养丰富,味道甜美。苹果营养丰富,味道甜美。这里,基于百度百科的在线文本信息处理方案,利用了百度百科的义项分类信息和各义项中的解释文本信息,包含了丰富最新的词汇量及其义项的解释文本,能够随时不断地扩展更新,具有更好的文本信息处理精度,能够有效支持机器翻译、智能客服、智能语音等需要准确识别不同语境下词语含义的智能应用。且本方案不需要人工手动标识、也不需要离线下载语料库。此外本方案对于词语含义的标识非常直观,不同于以往词语和序号组合、以及词语和词典编码组合等新式,本方案直接用词语在百度百科中不同义项的含义标识来标识,能够进一步获取更多的解释文本。本方法基本思想是:上下文文本在义项的解释文本中的相关特性参数值越大,说明上下文文本与解释文本中蕴含的语义越接近,因此相似程度越大。上下文文本在各义项的相关特征参数就可作为目标文本信息的上下文文本与目标文本信息每个义项的解释文本之间文本相似度的度量标准。步骤202:获取目标文本信息所在文本的上下文文本。本发明实施例提供的技术方案中,文本信息处理过程需要计算目标文本信息的上下文信息与不同词语义项的解释文本之间的文本相似度。词语的上下文文本以目标文本信息为中心的左右固定范围窗口的词语集合。上下文窗口的选取通常不能太大,否则会引入大量的噪声数据;同样也不能太小,造成上下文信息的不足,本方案设置的上下文窗口大小可以取20,即待识别词左右各10个词组成上下文信息。但是上下文文本信息和百度百科中的词语义项的解释文本信息相比,词语数量要少很多;而且各义项的解释文本大小也各不相同。具体的,目标文本信息所在文本中以目标文本信息为中心,截取紧邻目标文本信息的前n个字符,截取紧邻目标文本信息的后m个字符;其中,n和m均取大于1的整数;前n个字符、目标文本信息和后m个字符组成目标文本信息的上下文文本。步骤203:基于目标文本信息的上下文文本和至少两个义项的解释文本,确定上下文文本与每一个义项之间的相关特征参数。这里,计算上下文文本与每一个义项之间的相关特征参数的方法流程图如图3所示。示例性的,目标文本信息c的上下文文本对应的第一词语集合c={c1,c2,...,cn},目标文本信息c为第一词语集合中任意一个词语。在百度百科中目标文本信息c对应的义项数量为m,所有义项的解释文本集合为d={d1,d2,...,dm},对于d中任意一个解释文本dk,k=1,2,...,m,dk与目标文本信息c的上下文之间的文本相似度计算过程如下:步骤301:对上下文文本进行分词处理,计算上下文文本中每一个词语的权重值。具体的,对上下文文本进行分词处理,去掉停用词,得到上下文文本对应的第一词语集合c={c1,c2,...,cn},其中,每一个词语的权重值计算公式为:其中,w(ci)第i个词语ci的权重值,count(ci)为第一词语集合中第i个词语在上下文文本中出现的次数,为上下文文本中第一词语集合中所有词语出现的总次数。步骤302:计算包含每一个词语的义项数,每一个词语在解释文本中出现的频率。具体的,计算包含第一词语集合中词语ci(i=1,2,...,n)的义项数量vi,以及ci在dk中的频率ni。步骤303:计算每一个词语在解释文本中的tf-idf值。具体的,计算词语ci在每一个义项的解释文本中的tf-idf值,计算公式如下:其中,tfidf(ci)为词语ci在解释文本中的tf-idf值,ndk为解释文本dk所包含的词语总数。步骤304:计算每一个词语与解释文本之间的相关特征参数。具体的,计算词语ci与解释文本dk之间的相关特征参数s(ci),计算公式如下:s(ci)=w(ci)×tfidf(ci)(3)步骤305:计算目标文本信息的上下文文本与解释文本之间的相关特征参数。具体的,将每一个词语与解释文本dk之间的相关特征参数s(ci)进行累加之后,得到目标文本信息c的上下文文本与解释文本dk之间的相关特征参数score(c,dk),计算公式如下:这里,直接将相关特征参数score(c,dk)作为目标文本信息c的上下文文本与解释文本dk之间的文本相似度。基于计算得到的目标文本信息c的上下文文本与每一个义项中解释文本之间的相关特征参数,确定相关特征参数最大值的义项,该义项中的解释文本与目标文本信息c的上下文文本具有最大文本相似度,该义项中所表达的含义即为目标文本信息所在文本中的含义。步骤204:根据得到的上下文文本与每一个义项之间的相关特征参数,选取相关特性参数最大值对应的义项为目标义项。本发明实施例中,将上下文文本与每一个义项之间的相关特征参数作为上下文文本与每一个义项之间的文本相似度,用于评价上下文文本与每一个义项中解释文本所表达的含义的接近程度,相关特征参数最大值对应的义项中解释文本所表达的含义即为目标文本真实的含义。步骤205:确定目标义项中解释文本所表达的含义为目标文本信息的真实含义。例如,“苹果”在“烟台苹果的营养很丰富,含有多种维生素和酸类物质”中被标识为苹果(蔷薇科苹果属果实);“苹果”在“苹果公司创立之初,主要开发和销售的个人电脑”中被标识为苹果(苹果产品公司)。经过上述的文本信息处理过程,可以准确识别出每一种词语在不同上下文文本中所表达的具体词义。本发明实施例中提供的技术方案与现有技术相比,具有以下优点:(1)利用了百度百科的义项分类信息和各义项解释文本来识别不同上下问的词语词义;(2)提出了一种基于上下文文本重要性评分的文本相似度计算方法,能够在线地计算衡量词语上下文文本和义项的解释文本之间的相似度;(3)利用词语在百度百科中不同义项的含义标识来标识多义词,更为直观,并且能够进一步获取更多的解释文本;(3)本方案不需要人工手动标识训练集、也不需要离线下载语料库,直接通过在线的网页解析获取词语义项信息,对不同语境的多义词进行识别;(4)本方案包含的词汇量极其丰富,能够覆盖绝大部分文本信息处理的需求,而且能够不断地动态更新。实施例三基于同一发明构思,本发明实施例还提供了一种文本信息处理装置。图4为本发明实施例中文本信息处理装置的第一组成结构示意图,如图4所示,该文本信息处理装置40包括:处理器401和存储器402,其中,处理器401用于执行存储器402中存储的文本信息处理程序,以实现以下步骤:获取目标文本信息对应的至少两个义项;其中,至少两个义项中包含对目标文本信息的不同解释文本;基于目标文本信息的上下文文本和至少两个义项的解释文本,确定上下文文本与每一个义项之间的相关特征参数;根据上下文文本与每一个义项之间的相关特征参数,选取目标文本信息所对应的目标义项。在一些实施例中,处理器401具体用于执行存储器402中存储的文本信息处理程序,以实现以下步骤:对目标文本信息的上下文文本进行分词处理,得到第一词语集合;基于第一词语集合和至少两个义项的解释文本,计算第一词语集合与每一个义项的解释文本之间的相关特征参数;将第一词语集合与每一个义项的解释文本之间的相关特征参数,作为上下文文本与每一个义项之间的相关特征参数。在一些实施例中,处理器401具体用于执行存储器402中存储的文本信息处理程序,以实现以下步骤:计算第一词语集合中每一个词语的权重值;计算第一词语集合中每一个词语在第一解释文本中的逆文本频率指数tf-idf;其中,第一解释文本为至少两个义项的解释文本中任一个解释文本;基于第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算第一词语集合与每一个义项的解释文本之间的相关特征参数。在一些实施例中,处理器401具体用于执行存储器402中存储的文本信息处理程序,以实现以下步骤:基于第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算每一个词语与第一解释文本之间的相关特征参数;基于每一个词语与第一解释文本之间的相关特征参数,计算第一词语集合与每一个义项的解释文本之间的相关特征参数。在一些实施例中,处理器401具体用于执行存储器402中存储的文本信息处理程序,以实现以下步骤:从网络侧在线获取目标文本信息对应的至少两个义项。在实际应用中,上述存储器可以是易失性存储器(volatilememory),例如随机存取存储器(ram,random-accessmemory);或者非易失性存储器(non-volatilememory),例如只读存储器(rom,read-onlymemory),快闪存储器(flashmemory),硬盘(hdd,harddiskdrive)或固态硬盘(ssd,solid-statedrive);或者上述种类的存储器的组合,并向处理器提供指令和数据。上述处理器可以为中央处理器(centralprocessingunit,cpu)、微处理器(microprocessorunit,mpu)、数字信号处理器(digitalsignalprocessor,dsp)、或现场可编程门阵列(fieldprogrammablegatearray,fpga)中的至少一种。可以理解地,对于不同的设备,用于实现上述处理器功能的电子器件还可以为其它,本发明实施例不作具体限定。实施例四基于同一发明构思,本发明实施例还提供了另一种文本信息处理装置。图5为本发明实施例中文本信息处理装置的第二组成结构示意图,如图5所示,该文本信息处理装置50包括:获取单元501,用于获取目标文本信息对应的至少两个义项;其中,至少两个义项中包含对目标文本信息的不同解释文本;处理单元502,用于基于目标文本信息的上下文文本和至少两个义项的解释文本,确定上下文文本与每一个义项之间的相关特征参数;选取单元503,根据上下文文本与每一个义项之间的相关特征参数,选取目标文本信息所对应的目标义项。在一些实施例中,处理单元502,具体用于对目标文本信息的上下文文本进行分词处理,得到第一词语集合;基于第一词语集合和至少两个义项的解释文本,计算第一词语集合与每一个义项的解释文本之间的相关特征参数;将第一词语集合与每一个义项的解释文本之间的相关特征参数,作为上下文文本与每一个义项之间的相关特征参数。在一些实施例中,处理单元502,具体用于计算第一词语集合中每一个词语的权重值;计算第一词语集合中每一个词语在第一解释文本中的逆文本频率指数tf-idf;其中,第一解释文本为至少两个义项的解释文本中任一个解释文本;基于第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算第一词语集合与每一个义项的解释文本之间的相关特征参数。在一些实施例中,处理单元502,具体用于基于第一词语集合中每一个词语的权重值和每一个词语在第一解释文本中的tf-idf,计算每一个词语与第一解释文本之间的相关特征参数;基于每一个词语与第一解释文本之间的相关特征参数,计算第一词语集合与每一个义项的解释文本之间的相关特征参数。在一些实施例中,获取单元501,具体用于从网络侧在线获取目标文本信息对应的至少两个义项。上述各个单元之间通过总线系统504实现连接通信,总线系统504除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图5中将各种总线都标为总线系统504。在实际应用中,上述各个单元的功能均可由位于文本信息处理装置cpu、mpu、dsp、fpga等实现。实施例五基于同一发明构思,本发明实施例还提供了一种计算机可读存储介质,例如包括计算机程序的存储器,上述计算机程序可由终端的处理器执行,以完成前述一个或者更多个实施例中的方法步骤。本领域内的技术人员应明白,本发明的实施例可提供为方法、装置、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。本发明是参照根据本发明实施例的方法、装置、和计算机程序产品的流程示意图和/或方框图来描述的。应理解可由计算机程序指令实现流程示意图和/或方框图中的每一流程和/或方框、以及流程示意图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程示意图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。以上,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1