一种防止数据信息丢失的DGRU神经网络及其预测模型建立方法与流程
本发明属于深度学习领域,具体涉及一种防止数据信息丢失的dgru神经网络及其预测模型建立方法。
背景技术:
循环神经网络(recurrentneuralnetworks,rnn)是人工神经网络的一个重要分支。它在隐含层引入了反馈机制,实现对序列数据的有效处理。循环神经网络具有存储和处理上下文信息的强大能力,成为语音识别、自然语言处理、计算机视觉等领域的研究热点之一。一方面,循环神经网络普遍采用s型函数作为激活函数,而s型函数的饱和区限制了rnn训练收敛速度,因此对激活函数的优化研究成为研究热点;另一方面,循环神经网络主要采用软件实现的方式,算法的硬件加速研究具有重要意义。长短时记忆单元(longshort-termmemory,lstm)特有的门结构解决了传统循环神经网络时间维度的梯度消失问题,成为rnn结构的重要组成部分。
门控循环单元(gru)神经网络针对lstm结构进行改进,是近几年取得重大突破的网络模型,使用了更新门与遗忘门,解决了传统循环神经网络梯度消失问题。更新门和遗忘门这两个门控向量决定了哪些信息最终能作为门控循环单元的输出,存储并过滤信息,能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。更新门帮助模型决定到底要将多少过去的信息传递到未来,或到底前一时间步和当前时间步的信息有多少需要继续传递,遗忘门主要决定了到底有多少过去的信息需要遗忘。但是gru在过滤过程中会出现重要信息丢失情况,会降低模型的预测能力。
技术实现要素:
本发明的目的在于提供一种能增强模型记忆力、防止信息丢失的dgru神经网络。
一种防止数据信息丢失的dgru神经网络,包括输入层、输出层和隐含层,隐含层由dgru神经元构成,dgru神经网络的输入数据为经过数据预处理后的t时刻的集群行为数据
一种防止数据信息丢失的dgru神经网络,dgru是在gru的基础上改进的,标准的gru单元包括遗忘门和更新门;设输入序列为
其中
一种防止数据信息丢失的dgru神经网络,考虑到各个时段之间的时序关联,t时刻的同一时刻邻近的两层gru单元之间添加一个控制门,控制同一时刻低层gru的记忆单元实现向邻近高层记忆单元的信息流传输,则dgru网络中t时刻第l+1层隐含单元与第l层隐含单元之间连接的控制门输入的计算公式如下:
其中,上标l+1表示第l+1层的操作,wd表示第l层控制门的权重。控制门也可以用于连接第一层隐含层状态
则dgru中t时刻第l+1层更新门
本发明的目的还在于提供一种能增强模型记忆力、预测精度高、防止信息丢失的dgru神经网络预测模型建立方法。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,具体包括如下步骤:
步骤1、对数据集进行数据清洗,包括处理数据不平衡问题、归一化问题;
步骤2、利用数据预处理后的数据集训练dgru神经网络,建立预测模型;
步骤3、根据模型预测结果。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤1具体包括如下步骤:
步骤1.1、数据不平衡问题的处理,首先分析正负样本比例,然后根据数据集的大小采用不同的采样方法处理,如果数据量较充足,采取欠采样的方法,通过减少样本数据较多的类的数量来平衡数据集;如果数据量较少,采取过采样的方法,通过增加数量较少的类的数量来平衡数据集;
步骤1.2、对数据进行归一化处理,从而加快后期模型的建立。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤2具体包括如下步骤:
步骤2.1、将归一化处理后的数据按照序列的时间顺序分为两组,时间顺序靠前的一组作为训练数据集、时间顺序靠后的一组作为验证数据集;
步骤2.2、设定dgru神经网络的输入层神经元个数为5,输出层神经元个数为1,设定dgru神经网络隐含层的神经元个数为d,隐含层共3层,d=1,2,3...,dmax,其中dmax为预设值;
步骤2.3、依次在d的每个取值所对应的dgru神经网络结构上,利用训练集数据迭代地训练神经网络中的参数,并利用验证集数据对每次训练后的网络进行评估,更新并保存d的每个取值下性能最优的dgru神经网络,选取性能最优的dgru神经网络结构作为预测模型。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤3具体包括如下步骤:
步骤3.1、获取软件的最近一次的数据ct,以及最近一次时间以前的失效时间数据ct-1,ct-2,...,ct-n;
步骤3.2、利用步骤1中方法,对ct,ct-1,ct-2,...,ct-n进行数据的归一化处理;
步骤3.3、将经过归一化处理过的ct,ct-1,ct-2,...,ct-n数据输入到步骤2所获得的预测模型,得到预测结果,利用反归一化公式:
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤2.3具体包括如下步骤:
步骤2.3.1、外循环初始化,设定d=1;进行设定误差值的设置;
步骤2.3.2、内循环初始化,设定迭代次数=1,设定当前最小误差为无穷大,设定最大迭代次数;
步骤2.3.3、基于结构风险最小化原理,利用训练集数据进行dgru神经网络的训练;
步骤2.3.4、将验证集数据输入步骤2.3.3训练好的dgru神经网络,利用经验风险函数进行验证集误差的计算;
步骤2.3.5、若验证集误差大于或等于当前最小误差,则直接迭代次数+1;若验证集误差小于当前最小误差,则将验证集误差的值赋予当前最小误差,把当前dgru神经网络作为最优网络,更新并存储最优网络的参数和验证集误差;
步骤2.3.6、若迭代次数小于或等于最大迭代次数,则执行步骤2.3.3;若迭代次数大于最大迭代次数,则d=d+1,然后进行如下判断:若d>dmax则执行步骤2.3.7;若d≤dmax则执行步骤2.3.2;
步骤2.3.7、对比不同d值时最后网络的验证集误差,选取验证集误差最小的最优网络,并读取所对应的dgru神经网络的参数;
步骤2.3.8、依据所选择的网络参数确定dgru神经网络结构的软件可靠性的预测模型。
本发明的有益效果在于:
本发明所述的一种防止数据信息丢失的dgru神经网络,增加了不同层之间的信息传递,增强模型的记忆能力,克服传统gru神经网络信息丢失问题,并且应用dgru建立的预测模型,提高预测精度。
附图说明
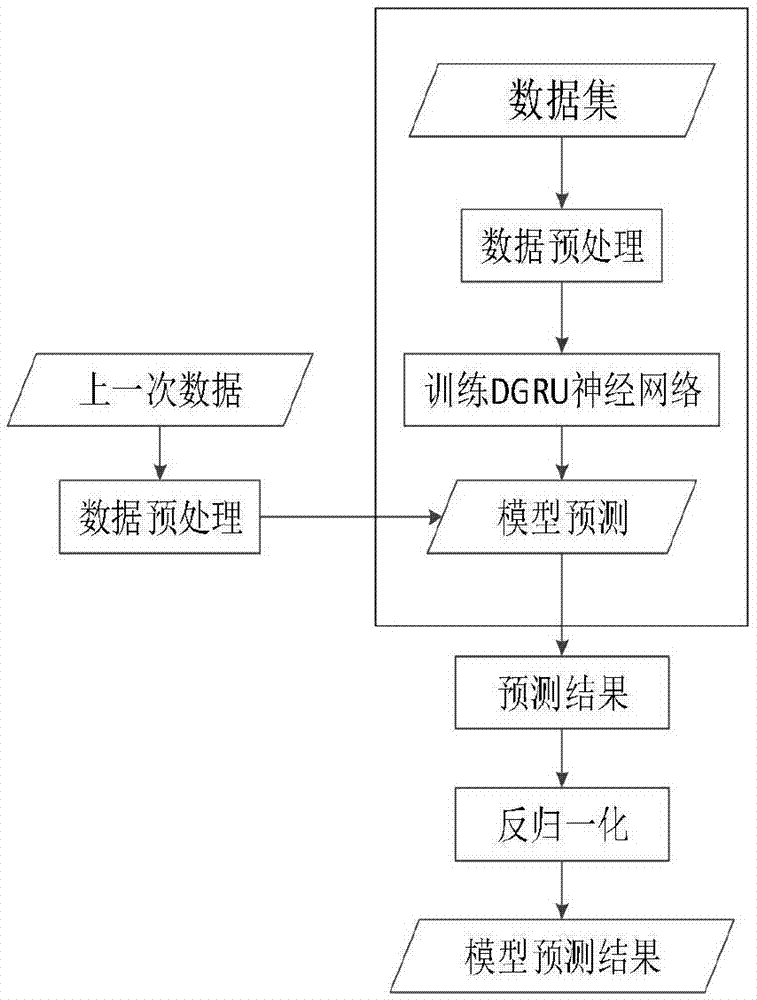
图1为基于dgru神经网络的预测模型框图;
图2为标准gru神经网络结构图;
图3为dgru神经网络结构图;
图4为dgru神经网络训练流程示意图。
具体实施方式
下面结合附图对本发明做进一步描述:
如附图1所示,为基于dgru神经网络的预测模型框图;具体包括如下步骤:
步骤1、对数据集进行数据清洗,包括处理数据不平衡问题、归一化问题;
步骤2、利用数据预处理后的数据集训练dgru神经网络,建立预测模型;
步骤3、根据模型预测结果。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤1具体包括如下步骤:
步骤1.1、数据不平衡问题的处理,首先分析正负样本比例,然后根据数据集的大小采用不同的采样方法处理,如果数据量较充足,采取欠采样的方法,通过减少样本数据较多的类的数量来平衡数据集;如果数据量较少,采取过采样的方法,通过增加数量较少的类的数量来平衡数据集;
步骤1.2、对数据进行归一化处理,从而加快后期模型的建立。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤2具体包括如下步骤:
步骤2.1、将归一化处理后的数据按照序列的时间顺序分为两组,时间顺序靠前的一组作为训练数据集、时间顺序靠后的一组作为验证数据集;
步骤2.2、设定dgru神经网络的输入层神经元个数为5,输出层神经元个数为1,设定dgru神经网络隐含层的神经元个数为d,隐含层共3层,d=1,2,3...,dmax,其中dmax为预设值;
步骤2.3、依次在d的每个取值所对应的dgru神经网络结构上,利用训练集数据迭代地训练神经网络中的参数,并利用验证集数据对每次训练后的网络进行评估,更新并保存d的每个取值下性能最优的dgru神经网络,选取性能最优的dgru神经网络结构作为预测模型。
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤3具体包括如下步骤:
步骤3.1、获取软件的最近一次的数据ct,以及最近一次时间以前的失效时间数据ct-1,ct-2,...,ct-n;
步骤3.2、利用步骤1中方法,对ct,ct-1,ct-2,...,ct-n进行数据的归一化处理;
步骤3.3、将经过归一化处理过的ct,ct-1,ct-2,...,ct-n数据输入到步骤2所获得的预测模型,得到预测结果,利用反归一化公式:
一种防止数据信息丢失的dgru神经网络预测模型建立方法,步骤2.3具体包括如下步骤:
步骤2.3.1、外循环初始化,设定d=1;进行设定误差值的设置;
步骤2.3.2、内循环初始化,设定迭代次数=1,设定当前最小误差为无穷大,设定最大迭代次数;
步骤2.3.3、基于结构风险最小化原理,利用训练集数据进行dgru神经网络的训练;
步骤2.3.4、将验证集数据输入步骤2.3.3训练好的dgru神经网络,利用经验风险函数进行验证集误差的计算;
步骤2.3.5、若验证集误差大于或等于当前最小误差,则直接迭代次数+1;若验证集误差小于当前最小误差,则将验证集误差的值赋予当前最小误差,把当前dgru神经网络作为最优网络,更新并存储最优网络的参数和验证集误差;
步骤2.3.6、若迭代次数小于或等于最大迭代次数,则执行步骤2.3.3;若迭代次数大于最大迭代次数,则d=d+1,然后进行如下判断:若d>dmax则执行步骤2.3.7;若d≤dmax则执行步骤2.3.2;
步骤2.3.7、对比不同d值时最后网络的验证集误差,选取验证集误差最小的最优网络,并读取所对应的dgru神经网络的参数;
步骤2.3.8、依据所选择的网络参数确定dgru神经网络结构的软件可靠性的预测模型。
dgru神经网络由输入层、输出层、隐含层组成,隐含层由dgru神经元构成,dgru神经网络的输入数据为经过数据预处理后的t时刻的集群行为数据
标准的gru单元包括遗忘门和更新门。设输入序列为
其中
考虑到各个时段之间的时序关联,t时刻的同一时刻邻近的两层gru单元之间添加一个控制门(controlgate),通过控制同一时刻低层gru的记忆单元向邻近高层记忆单元的信息流传输实现。则dgru网络中t时刻第l+1层隐含单元与第l层隐含单元之间连接的控制门输入的计算公式如下:
其中,上标l+1表示第l+1层的操作,wd表示第l层控制门的权重。控制门也可以用于连接第一层隐含层状态
则dgru中t时刻第l+1层更新门
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!