一种基于并存率与关联规则的心理行为分析方法与流程
本发明涉及一直基于并存率与关联规则的心理行为分析方法,属于数据关联规则挖掘技术领域。
背景技术:
关联规则最初提出的动机是针对购物篮分析(marketbasketanalysis)问题提出的。1993年,agrawal等人在首先提出关联规则概念,同时给出了相应的挖掘算法ais,但是性能较差。1994年,他们建立了项目集格空间理论,并依据上述两个定理,提出了著名的apriori算法,至今apriori仍然作为关联规则挖掘的经典算法被广泛讨论,以后诸多的研究人员对关联规则的挖掘问题进行了大量的研究。
该算法已经被广泛的应用到商业、网络安全等各个领域,但还没有应用到心理行为关联分析领域。同时,算法对数据并没有进行预处理操作,导致结果不够精确,本发明所提出的并存率就是用来过滤无用或干扰的数据,从而得出更加准确、显著的关联规则。
技术实现要素:
本发明要解决的技术问题是提供一直基于并存率与关联规则的心理行为分析方法,将关联规则算法进行优化后应用到相关心理行为词汇分析中,为心理学、微表情等学科提供了更加精准、高效的心理行为关联分析方法。
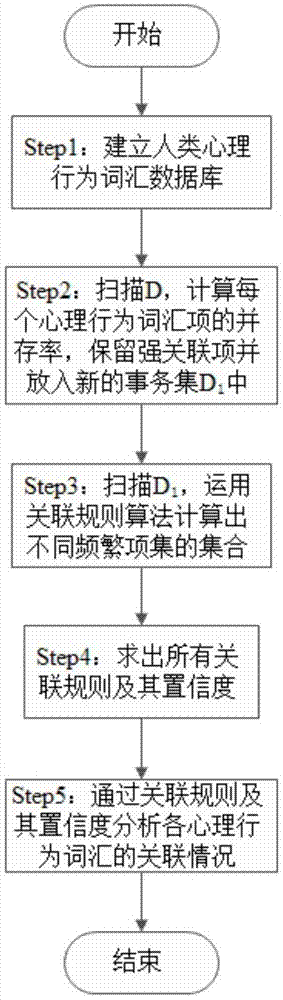
本发明的技术方案是:一种基于并存率与关联规则的心理行为分析方法,具体步骤为:
step1、建立人类心理行为词汇数据的事务数据库,心理测试者的编号作为标识符tid,每一测试者的所有心理行为词汇作为一个事务t,所有事务的集合为事务集d;
step2、扫描事务集d,每个心理行为词汇作为一个项,计算每个项的并存率ρ与它们的和,从而求出最小并存率阈值min_com,保留ρ≥min_com的心理行为词汇项,否则作为噪声剔除,再将所有保留项放入新的事务集d1中;
step3、扫描新事务集d1,每个心理行为词汇作为一个候选1项集c1,所有c1的集合为c1,设置一个最小支持度阈值min_sup,当c1的支持度计数support_count(c1)大于等于min_sup时,则c1成为频繁1项集l1,所有l1的集合为l1,通过将l1与自身相连接产生候选2项集c2,所有c2的集合为c2,如果c2中第i个候选2项集c2(i)的某个子集为第x个候选1项集c1(x),且它不是l1的元素时,则将c2(i)从c2中删除;满足min_sup的c2作为频繁2项集l2,其集合为l2;依次循环类推,得到不同频繁项集l2、l3、……lk-1、lk的集合l2、l3……lk-1、lk,其中lk-1、lk分别代表频繁k-1项集和频繁k项集,lk-1、lk则为它们各自的集合;
step4、设置一个最小置信度阈值min_conf;每个频繁项集l所产生的每个非空子集为s,若子集(l-s)与s的支持度计数之比大于等于最小置信度阈值min_conf,则输出强关联规则
step5、将所计算出来的所有强关联规则按照其置信度confidence的大小进行排序,当出现一个或多个心理行为词汇时,通过关联规则得出与该心理行为词汇相关联的其他心理行为词汇。
进一步,所述步骤step1中,人类心理行为词汇数据的事务数据库具有所有心理测试者的全部心理行为词汇数据信息,数据字段包括测试者标识符字段与其心理行为词汇数据字段。
进一步,所述步骤step2中具体为:
(1)扫描事务集d,计算每一个项的并存率ρ,第i项的并存率ρi计算公式为:
式(1)中,support_count(mi)为第i项的总支持度计数;support_count(si)为第i项的单存项支持度计数;
(2)通过上述所得各项并存率,求出它们的和与项数之比,比值即为最小并存率阈值min_com,计算公式为:
式(2)中,n是项的总数;
(3)当第i项的并存率低于最小并存率阈值:
ρi<min_com(3)
则剔除第i项的所有数据,否则,作为强关联项数据保留并放入新的事务集d1中,进行下一步的数据处理;
单存项:某一事务t中仅存在一个项,即该项在事务集d中有单独存在的项集;
并存项:某一事务t中存在多个项,每一个项都称为并存项;
并存率ρ:某并存项与其他并存项同时存在的概率。
进一步,所述步骤step3中,为得到频繁k项集的集合lk,通过将频繁k-1项集的集合lk-1与自身相连接产生候选k项集的集合ck。
进一步,所述步骤step4的关联规则置信度大小的计算如公式(4)所示:
其中:
式(4)和(5)中,min_conf为最小置信度阈值,l为频繁项集,l所产生的每个非空子集为s,support_count(l)、support_count(s)、support_count(l-s)分别为括号内字母的支持度计数,
本发明的有益效果是:本发明与现有技术相比,主要提供了并存率对关联规则算法进行数据优化,通过优化后的关联规则算法对人类的心理行为词汇起到关联分析作用,为心理学、微表情等学科提供了更加精准、高效的分析方法。
附图说明
图1是本发明步骤流程图;
图2是本发明步骤step2步骤流程图;
图3是本发明步骤step3步骤流程图;
图4是本发明实施例中step3的计算频繁项集流程图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-3所示,一种基于并存率与关联规则的心理行为分析方法,先建立一个人类心理行为词汇数据的事务数据库;然后求出各心理行为词汇并存项的并存率与最小并存率,从而保留强关联项并生成新的事务集;接着,将新事务集中每个心理行为词汇作为一个项,引入关联规则算法计算出不同项数的频繁项集;其次,由各频繁项集产生相应的强关联规则,并计算出各强关联规则的置信度大小;最后,通过各强关联规则的置信度大小,将这些频繁项集进行排序,结果将能直观表示出各心理行为词汇的关联程度。
具体步骤为:
step1、建立人类心理行为词汇数据的事务数据库,心理测试者的编号作为标识符tid,每一测试者的所有心理行为词汇作为一个事务t,所有事务的集合为事务集d;
step2、扫描事务集d,每个心理行为词汇作为一个项,计算每个项的并存率ρ与它们的和,从而求出最小并存率阈值min_com,保留ρ≥min_com的心理行为词汇项,否则作为噪声剔除,再将所有保留项放入新的事务集d1中;
step3、扫描新事务集d1,每个心理行为词汇作为一个候选1项集c1,所有c1的集合为c1,设置一个最小支持度阈值min_sup,当c1的支持度计数support_count(c1)大于等于min_sup时,则c1成为频繁1项集l1,所有l1的集合为l1,通过将l1与自身相连接产生候选2项集c2,所有c2的集合为c2,如果c2中第i个候选2项集c2(i)的某个子集为第x个候选1项集c1(x),且它不是l1的元素时,则将c2(i)从c2中删除;满足min_sup的c2作为频繁2项集l2,其集合为l2;依次循环类推,得到不同频繁项集l2、l3、……lk-1、lk的集合l2、l3……lk-1、lk,其中lk-1、lk分别代表频繁k-1项集和频繁k项集,lk-1、lk则为它们各自的集合;
step4、设置一个最小置信度阈值min_conf;每个频繁项集l所产生的每个非空子集为s,若子集(l-s)与s的支持度计数之比大于等于最小置信度阈值min_conf,则输出强关联规则
step5、将所计算出来的所有强关联规则按照其置信度confidence的大小进行排序,当出现一个或多个心理行为词汇时,通过关联规则得出与该心理行为词汇相关联的其他心理行为词汇。
进一步,所述步骤step1中,人类心理行为词汇数据的事务数据库具有所有心理测试者的全部心理行为词汇数据信息,数据字段包括测试者标识符字段与其心理行为词汇数据字段。
进一步,所述步骤step2中具体为:
(1)扫描事务集d,计算每一个项的并存率ρ,第i项的并存率ρi计算公式为:
式(1)中,support_count(mi)为第i项的总支持度计数;support_count(si)为第i项的单存项支持度计数;
(2)通过上述所得各项并存率,求出它们的和与项数之比,比值即为最小并存率阈值min_com,计算公式为:
式(2)中,n是项的总数;
(3)当第i项的并存率低于最小并存率阈值:
ρi<min_com(3)
则剔除第i项的所有数据,否则,作为强关联项数据保留并放入新的事务集d1中,进行下一步的数据处理;
单存项:某一事务t中仅存在一个项,即该项在事务集d中有单独存在的项集;
并存项:某一事务t中存在多个项,每一个项都称为并存项;
并存率ρ:某并存项与其他并存项同时存在的概率。
进一步,所述步骤step3中,为得到频繁k项集的集合lk,通过将频繁k-1项集的集合lk-1与自身相连接产生候选k项集的集合ck。
进一步,所述步骤step4的关联规则置信度大小的计算如公式(4)所示:
其中:
式(4)和(5)中,min_conf为最小置信度阈值,l为频繁项集,l所产生的每个非空子集为s,support_count(l)、support_count(s)、support_count(l-s)分别为括号内字母的支持度计数,
实施例2:如图1-4所示,一种基于并存率与关联规则的心理行为分析方法,所述方法的具体步骤如下:
step1、建立人类心理行为词汇数据的事务数据库,心理测试者的编号作为标识符tid,每一测试者的所有心理行为词汇作为一个事务t,所有事务的集合为事务集d;具体地:
为方便阐述本发明,暂定所建数据库中有如下10种心理与行为,同时假设其编号规则如下:
假设所建数据库中有如下7位心理测试者某一时段内的心理及其行为数据信息:
step2、扫描事务集d,每个心理行为词汇作为一个项,计算每个项的并存率ρ与它们的和,从而求出最小并存率阈值min_com。保留ρ≥min_com的心理行为词汇项,否则作为噪声剔除,再将所有保留项放入新的事务集d1中;具体地:
经计算后得出每一个心理行为数据项的并存率结果如下表:
接着求出最小并存率阈值min_com=78.33%,从而将i8,i9,i10作为噪声剔除,i1,i2,i3,i4,i5,i6,i7则作为强关联项数据保留并放入新的事务集d1中。
step3、扫描新事务集d1,每个心理行为词汇作为一个候选1项集c1,所有c1的集合为c1,设置一个最小支持度阈值min_sup,当c1的支持度计数support_count(c1)大于等于min_sup时,则c1成为频繁1项集l1,所有l1的集合为l1,通过将l1与自身相连接产生候选2项集c2,所有c2的集合为c2,如果c2中第i个候选2项集c2(i)的某个子集为第x个候选1项集c1(x),且它不是l1的元素时,则将c2(i)从c2中删除;满足min_sup的c2作为频繁2项集l2,其集合为l2;依次循环类推,得到不同频繁项集l2、l3、……lk-1、lk的集合l2、l3……lk-1、lk,其中lk-1、lk分别代表频繁k-1项集和频繁k项集,lk-1、lk则为它们各自的集合;具体地:
设置最小支持度阈值min_sup=2,则通过关联规则算法算法计算频繁项集的流程如图4所示,由图4的计算流程得出结果:
l2={{i1,i2},{i2,i4},{i2,i5},{i2,i6},{i5,i6}},l3={{i1,i2,i4},{i2,i5,i6}};
step4、设置一个最小置信度阈值min_conf;每个频繁项集l所产生的每个非空子集为s,若子集(l-s)与s的支持度计数之比大于等于最小置信度阈值min_conf,则输出强关联规则
设置最小置信度阈值min_conf=60%,结合step3所得关联规则,求出所有的强关联规则,并计算出其置信度,部分结果如下:
step5、将所计算出来的所有强关联规则按照其置信度confidence的大小进行排序,当出现一个或多个心理行为词汇时,通过关联规则得出与该心理行为词汇相关联的其他心理行为词汇。具体地:
将step4所得强关联规则按其置信度大小排序,即当人类心理或行为出现i1(说谎)时,则人类有可能同时伴随一下的心理或行为1.i2(假笑);2.i2^i4(假笑、转移视线);当读者借阅图书i2^i5(假笑、挑眉毛),则人类有可能同时伴随一下的心理或行为i6(轻视)。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!