一种基于公钥加密算法的模乘装置及协处理器的制作方法
本发明涉及信息安全技术领域,具体涉及一种基于公钥加密算法的模乘装置及协处理器。
背景技术:
rsa(公钥加密算法)是由罗纳德·李维斯特(ronrivest)、阿迪·萨莫尔(adishamir)和伦纳德·阿德曼(leonardadleman)一起提出,rsa就是他们三人姓氏开头字母拼在一起组成的,rsa公约密钥算法是公钥密码体系中应用最为广泛发展最为成熟的一种非对称加密算法,其基本运算是大整数模乘运算、幂运算,应用于在线支付、个人身份数据、数据下载等身份认证、数字签名、数字认证等领域。通常会采用硬件实现的蒙哥马利模乘器进行计算。但现有技术中,随着密钥长度(基指数)增大,使得数据处理路径过长,从而导致数据处理耗时过长、运行主频低,并且硬件开销随基指数的增加而不断加大,影响平均性能和增加成本。
因此,现有技术还有待于改进和发展。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的平均性能差、实现频率低、硬件开销大的缺陷,提供一种基于公钥加密算法的模乘装置及协处理器,旨在可扩展高基蒙哥马利模乘算法的基础上,对多字高基蒙哥马利模乘器加以改进,以基为16的蒙哥马利模乘器实现1024位的公钥加密算法算法,提高模乘运算速度,改善现有技术中公钥加密算法运算平均性能低的缺陷,同时提高了运算时钟主频并降低硬件开销,方便了用户。
本发明解决技术问题所采用的技术方案如下:
一种基于公钥加密算法的模乘装置,所述基于公钥加密算法的模乘装置包括:
用于实现公钥加密算法的循环累加操作的运算模块;
用于存储操作数以及实现模约减操作的模约减模块;
用于存储乘数的第一存储器、用于存储被乘数的第二存储器、用于存储模数的第三存储器、用于存储运算结果的第四存储器;及
用于传递运算结果的先进先出寄存器;
所述第一存储器的输出端、第二存储器的输出端、第三存储器的输出端以及先进先出寄存器的输出端均连接所述运算模块的输入端,所述运算模块的输出端分别连接所述先进先出寄存器的输入端和所述模约减模块的输入端,所述模约减模块的输出端连接所述第四存储器的输入端。
所述的基于公钥加密算法的模乘装置,其中,所述运算模块包括依次串联连接的若干个处理单元,每个所述处理单元的输入端均连接所述第一存储器的输出端,所述第二存储器与所述第三存储器的输出端均连接所述第一个处理单元的输入端,最后一个处理单元的输出端分别连接所述模约减模块的输入端和先进先出寄存器的输入端,先进先出寄存器的输出端连接第一个处理单元的输入端。
所述的基于公钥加密算法的模乘装置,其中,最后一个处理单元输出的值输入至第一个处理单元作为被乘数或者作为输出结果。
所述的基于公钥加密算法的模乘装置,其中,每个所述处理单元包括串联的第一级保留进位加法器和第二级保留进位加法器、若干个多路复用器以及若干寄存器,每个所述寄存器存储操作数、预计算值以及中间结果,每个所述多路复用器存储中间结果以及预计算值。
所述的基于公钥加密算法的模乘装置,其中,第一存储器输出的n位乘数经过第一级保留进位加法器相加,最低位由上一处理单元的进位值填满;第一级保留进位加法器的输出除最高位进位外和上一处理单元输入的预计算值,作为第二级保留进位加法器的输入,其中,1≤n≤16。
所述的基于公钥加密算法的模乘装置,其中,采用高基蒙哥马利模乘算法通过单次扫描多位乘数(x)输出运算结果。
一种基于公钥加密算法的协处理器,连接于单片机,包括依次连接的若干个处理单元、若干个块随机存储器以及片上总线从控制器,每个所述块随机存储器分别连接对应处理单元并对应存储乘数、被乘数、幂指数、模数、预计算参数、平方操作的底数以及运算结果,每个所述处理单元为上述所述的基于公钥加密算法的模乘装置中的处理单元。
所述的基于公钥加密算法的协处理器,其中,还包括并联在所述处理单元与所述片上总线从控制器之间的控制寄存器和状态寄存器。
所述的基于公钥加密算法的协处理器,其中,每个所述块随机存储器的读写操作根据与之对应连接的处理单元的运算状态来自动选择处理单元或片上总线从控制器控制。
所述的基于公钥加密算法的协处理器,其中,当所述处理单元处于未启动时,选择所述片上总线从控制器控制所有的块随机存储器的读写操作;当所述处理单元处于启动计算时,自动切换为处理单元控制与之对应的每个所述块随机存储器的读写操作;当所述处理单元处于计算结束时,重新切换为所述片上总线从控制器控制所有的块随机存储器的读写操作。
相较于现有技术,本发明提供的一种基于公钥加密算法的模乘装置及协处理器的有益效果如下:
1.具有可扩展特点,是对现有的可扩展的高基蒙哥马利模乘算法的改进,能实现基数为16的1024位的公钥加密算法运算,通过先进先出寄存器传递计算结果以处理长度可变的操作数。
2.本发明所采用的保留进位加法器能够降低数据通路延时,使得效率大大提高。
3.利用2个加法器以及多路复用器以及16个处理单元组成的阵列,实现了性能的提高,大大减少了硬件开销,并且提高了运算主频。
4.本发明设计的模乘装置,随着基指数的增加,数据路径的增大,降低总体性能面积,从而提高运算速率。
5.对于乘数、被乘数连续不断变化的情形,通过模约减操作以及加法操作,使得计算量减少,操作执行更高。
6.以基为16的蒙哥马利模乘器实现1024位的公钥加密算法加解密ip以及实现了高速公钥加密算法加解密等的即插即用。
附图说明
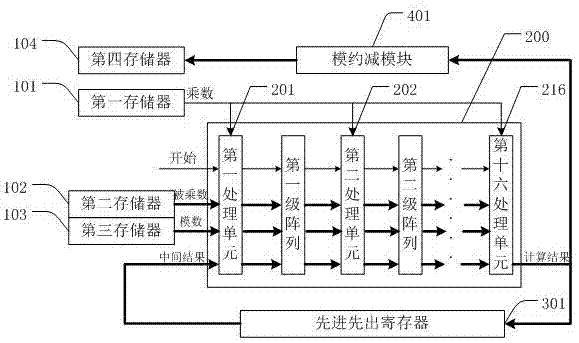
图1是本发明提供的一种基于公钥加密算法的模乘装置的结构框图。
图2是本发明的单个处理单元的结构框图。
图3是本发明的保留进位加法器的结构框图。
图4是本发明提供的基于公钥加密算法的协处理器嵌入系统芯片的结构框图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明所提供的一种基于公钥加密算法的模乘装置以及协处理器均是基于采用一种改进的高基蒙哥马利模乘算法实现,其算法步骤如下所示:
1:s=0
2:forj=0ton-1
3:s=s+xj*y
4:s=s+s0*m
5:s=s/2
endfor
6:ifs≥mthens=s-m
endif
其中,x是乘数,y是被乘数,m是模数,且x、y、m均为位长为n的整数,j是循环变量,且是整数,s是中间计算的结果,s0是。该算法中步骤3是表示x*y的操作分解,步骤5是表示s*2-n的分解,步骤4是为了调整步骤5而进行的模约减处理。
在上述算法中,对于二进制的蒙哥马利模乘,xj的取值为0或1,则该算法的实现实际上是两个加法器之后做一次右移操作,以移位代替除法(除以2)。
由上述可知,做一次基为1(即radix2)的n位蒙哥马利模乘运算需要做两次n位的加法和一次右移操作,最后再将n位的通过模约减操作得到的结果与n位的模数作比较判断得到模乘值,操作简单,易实现。
实施例一
请参见图1,图1是本发明提供的一种基于公钥加密算法的模乘装置的结构框图。如图1所示,一种基于公钥加密算法的模乘装置,包括:
用于实现公钥加密算法的循环累加操作的运算模块200;即从存储器中读取中间计算的结果,并将最后结果输出至存储器中;
用于存储操作数以及实现模约减操作的模约减模块401(reduct);所述模约减模块401包括一个n位的减法器(图未标识),用于完成本发明的高基蒙哥马利模乘算法的最后的模约减操作,即将上述算法步骤中的第一步骤操作得到的处于0-2n的结果约减为0-n的操作数,以此用于后续比较判断操作。
用于存储乘数(xin)的第一存储器101、用于存储被乘数(yin)的第二存储器102、用于存储模数(min)的第三存储器103、用于存储运算结果(sin)的第四存储器104(result);及
用于传递运算结果(如中间结果,sin)的先进先出寄存器301;即实现最后一个处理单元215到第一个处理单元201的计算结果的传递。在本发明实施例中,针对于1024位的公钥加密算法运算,所述先进先出寄存器301是由大小为128*16位的双口寄存器(ram)构成,用fifo(firstinputfirstoutput,先入先出队列)表示先进先出寄存器301。其中,运算结果可以是中间结果,可以是最终结果、输出结果。
如图1所示,所述第一存储器101的输出端、第二存储器102的输出端、第三存储器103的输出端以及先进先出寄存器301的输出端均连接所述运算模块200的输入端,所述运算模块200的输出端分别连接所述先进先出寄存器301的输入端和所述模约减模块401的输入端,所述模约减模块401的输出端连接所述第四存储器104的输入端。
其中,所述运算模块200包括依次串联连接的若干个处理单元,用pe表示,即若干个pe处理单元,在本发明实施例中,所述处理单元的个数为16,对应于图1中标示的201…216,即16个处理单元串联构成16级的运算阵列,这样就实现了基为16的蒙哥马利模乘运算。
具体地,如图1所示,每个所述处理单元的结构大小相同,且每个处理单元的输入端均连接所述第一存储器101的输出端,所述第二存储器102的输出端与所述第三存储器103的输出端均连接所述第一个处理单元201的输入端,最后一个处理单元216的输出端分别连接所述第四存储器104的输入端和先进先出寄存器301的输入端,先进先出寄存器301的输出端连接第一个处理单元201的输入端。
这样,最后一个处理单元216输出的值输入至第一个处理单元201作为被乘数或者作为输出结果。
以上利用有限个逻辑资源(即16个处理单元和1个寄存器)和4个存储器计算任意长度或者长度可变的模乘运算,并且,对于乘数和被乘数不断变化的情形。
进一步地,如图2所示,图2是本发明所提供的模乘装置中单个处理单元的结构框图,每个所述处理单元(如201或202或…216)包括串联的第一级保留进位加法器10和第二级保留进位加法器11、用于多路数据共享一个通路以及接收复合数据流的若干个多路复用器6001以及若干个寄存器,每个所述多路复用器6001均包括第一输入端s1、第二输入端s2和输出端d,具体地,所述第一级保留进位加法器(如图3的10)与第一多路复用器串联或并联后共接于第二多路复用器以构成第一数据通路601,所述第二级保留进位加法器(如图3的11)与第三多路复用器串联或并联后共接于第四多路复用器以构成第二数据通路602,所述第一数据通路601与所述第二数据通路602结构相同,所述第一多路复用器、第二多路复用器、第三多路复用器以及第四多路复用器结构均相同,对应于图2中的6001,其中,每个所述寄存器存储操作数、预计算值以及中间结果,每个所述多路复用器6001存储中间结果以及预计算值。
每个所述处理单元的模乘运算处理过程如下:
第一存储器101输出的n位乘数经过第一级保留进位加法器10相加,最低位由上一处理单元的进位值填满;第一级保留进位加法器10的输出除最高位进位外和上一处理单元输入的预计算值,作为第二级保留进位加法器11的输入,其中,1≤n≤16。优选的,本实施例中,n=16。
这样,基为1(radix2)的蒙哥马利模乘算法实现时,每个处理单元(pe)包含2个位宽为w位的保留进位加法器,每个处理单元处理1位的乘数x,这样多个处理单元组成阵列后通过控制逻辑驱动数据流完成一次对乘数x的蒙哥马利模乘的遍历。因此,采用高基蒙哥马利模乘算法通过单次扫描多位乘数(x)输出运算所得的最后结果以实现快速公钥加密算法的模乘方法,如基为4(radix4)、基为8(radix8)、基为16(radix16)、基为32(radix32)结构的蒙哥马利模乘运算。采用本发明设计方案,一方面,随着基指数的增加,所实现的运行主频越低,另一方面,减少运算时间的同时,降低硬件开销,从而提升平均性能、提高效率。
需要说明的是,本实施例中采用多路复用器,可使多路数据信息共享一通路,当复用线路上的数据流连续时,这种共享方式可取得良好效果。显然,这样做比每台终端各用一根通信线路传送也更为经济。多路复用器总是成对使用的。
进一步地,本发明为了降低数据通路的时延,采用具有保留进位特点的保留进位加法器,即carrysavearray结构的加法器。具体地,图3是本发明的保留进位加法器的结构框图,第一保留进位加法器10与第二保留进位加法器11结构相同,接收中间计算过程中乘数、被乘数以及模数,其中,w为每次处理的字长。
本发明上述模乘装置的设计,在提高了公钥加密算法运算性能的同时,减少了硬件消耗,并提高了运算主频,实现了1024位的公钥加密算法,并且一次加密运算仅需5.5ms,同时硬件消耗仅有34个16*16的mac以及4500个reg(命令),所用资源极少。
实施例二
本发明还提供一种基于公钥加密算法的协处理器,基于实施例一中的基为16的1024位公钥加密算法加解密ip,嵌入到具有arm核的fpga(fieldprogrammablegatearray,现场可编程逻辑阵列)平台中,以实现高速公钥加密算法加解密等运算的即插即用。也就是说,该协处理器400作为从设备通过amba总线与具备arm核单片机500(m3)进行数据通信连接,而产生的操作数由m3通过amb总线传输到所述的基于公钥加密算法的协处理器400进行相应的操作处理。
如图4所示,所述协处理器400通过abm总线连接于单片机500(即m3),具体为,通过amb总线与所述单片机500中的处理器501(即armahbmaster)进行数据通信,所述处理器400包括依次连接的若干个处理单元(即图中16个处理单元201…216)、若干个块随机存储器402(即blockram)以及片上总线从控制器404(即ahbslave),每个所述块随机存储器402分别连接对应的处理单元并对应的存储乘数、被乘数、幂指数、模数、预计算参数、平方操作的底数以及运算结果,即共7个块随机存储器402,每个块随机存储器402的大小相同,均为64bit*16bit,这7个块随机存储器402分别对应存储乘数、被乘数、幂指数、模数、预计算参数、平方操作的底数以及运算结果这7个数据。其中,所述处理单元指的是实施例一中所述的基于公钥加密算法的模乘装置中的处理单元。其中,ahb总线称为片上总线,amba总线称为高性能高处理总线。
如图4所示,所述协处理器400还包括并联在所述处理单元(即pe处理单元)与所述片上总线从控制器404之间的用于控制并存储值的控制寄存器406和用于查询处理单元的运算状态的状态寄存器408,所述控制寄存器406与所述状态寄存器408是成对存在,且位长n均为16位。
具体地,每个所述块随机存储器402的读写操作根据与之对应连接的处理单元(201…216)的运算状态来自动选择处理单元或片上总线从控制器控制404。其中,所述运算状态包括未启动状态、启动运算状态以及运算结束状态。即当所述处理单元(201…216)处于未启动时,选择所述片上总线从控制器404控制所有的块随机存储器402的读写操作;当所述处理单元(201…216)处于启动计算时,自动切换为处理单元(201…216)控制与之对应的每个所述块随机存储器402的读写操作;当所述处理单元(201…216)处于计算结束时,重新切换为所述片上总线从控制器404控制所有的块随机存储器402的读写操作。
因此,采用16级的运算阵列,即形成16级的数据流ns=16;操作数每字位宽为16bit,即nw=16,则所述公钥加密算法400与单片机500(m3)实现公钥加密算法的模乘方法的操作过程如下:
1)m3将明文通过ahb总线写入到fpga中的blockram中;
2)m3将公钥/私钥通过ahb总线写入到fpga中的blockram中;
4)m3将由模乘装置输出的模数值通过ahb总线写入到blockram中;
5)m3通过ahb总线写入状态寄存器的值;
6)m3通过ahb总线写入控制寄存器的值,启动pe运算;
7)m3等待pe的中断或通过ahb总线查询状态寄存器的值,如果收到中断或查询到结束状态,则通过ahb总线启动第四存储器104的读操作,将本次模幂运算结果取回。
本发明利用fpga仿真验证,用有限个处理单元,仅仅16个,使得本发明设计的模乘装置(即基为16、字长为16的蒙哥马利模乘结构)具有较好的性能,并且更少的硬件开销,达到较高的运行主频,并得到更高的性能面积比,具体如表1所示。
表1为本发明在soc(systemonchip集成芯片、阵列)平台上的实现结果
上表实现了1024位rsa,一次加密运算仅需5ms,降低硬件开销同时,达到较高的运行主频,并得到更高的性能面积比。
本发明的基于公钥加密算法的协处理器是基于基为16、字长为16的蒙哥马利模乘装置设计的。
综上所述,本发明公开了一种基于公钥加密算法的模乘装置及协处理器,所述基于公钥加密算法的模乘装置包括:用于实现公钥加密算法的循环累加操作的运算模块;用于存储操作数以及实现模约减操作的模约减模块;用于存储乘数的第一存储器、用于存储被乘数的第二存储器、用于存储模数的第三存储器、用于存储运算结果的第四存储器;及用于传递运算结果的先进先出寄存器;所述第一存储器的输出端、第二存储器的输出端、第三存储器的输出端以及先进先出寄存器的输出端均连接所述运算模块的输入端,所述运算模块的输出端分别连接所述先进先出寄存器的输入端和所述模约减模块的输入端,所述模约减模块的输出端连接所述第四存储器的输入端。本发明旨在改进现有的可扩展高基蒙哥马利模乘算法的基础,以基为16的蒙哥马利模乘器实现1024位的公钥加密算法算法以及高速公钥加密算法加解密等的即插即用,降低硬件开销的同时,提高模乘运算速度和效率,优化性能,方便用户。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!