一种爬取微信公众号信息的方法与流程
本发明涉及互联网通信技术领域,更具体地,涉及一种爬取微信公众号信息的方法。
背景技术:
目前,微信公众号中的内容的查看方式主要有两种:一种是通过搜狗微信的搜索功能查看公众号内容,一种是通过手机微信app查看微信公众号内容。现有的微信公众号爬虫程序大多数是通过搜狗微信搜索微信公众号的方式爬取,效率低,而且搜狗微信搜索有反爬虫规则,获取到微信公众号内容有限,不能在短时间内获取大量的公众号内容。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种爬取微信公众号信息的方法。
为解决上述技术问题,本发明的技术方案如下:
一种爬取微信公众号信息的方法,其特征在于,它包括以下步骤:
s1:确定待爬取公众号名称,将待爬取公众号的编号入库;
s2:依照预设的爬虫匹配规则,根据公众号名称爬取待爬取公众号,得到待爬取公众号的相关信息;
s3:将爬虫获取的待爬取公众号相关信息进行入库处理,处理后的待爬取公众号的相关信息入库;
s4:设置爬虫定时执行时间,根据待爬取公众号的相关信息定时爬取待爬取待爬取公众号文章,将爬虫获取的公众号文章入库;
s5:显示公众号文章。
进一步地,步骤s1具体包括以下两种情况:
s11:模糊匹配,即用户不清楚待爬取的公众号的准确名字,初步确定待爬取的公众号后,把其编号入库作为待爬取的公众号;
s12:精确匹配,即用户清楚待爬取的公众号的准确名字,通过精确键入公众号名称或者编号,直接入库,并作为待爬取的公众号。
进一步地,步骤s2所述的预设的爬虫匹配规则的设置方法为:通过scrapy框架爬取指定页面的html源码,并按照库结构和样式规则表,编写匹配规则;所述的待爬取公众号的相关信息包括待爬取公众号的编号、名称、发表的文章名称、发表的文章。
进一步地,步骤s3所述的入库处理就是进行加工和预处理,具体包括去重、按照指定格式编排、记录入库时间。
进一步地,步骤s4所述的定时执行时间设置为一天。
进一步地,步骤s5所述的显示公众号文章就是利用javaweb相关技术将本地存储公众号内容查询展示到前端页面上。
进一步地,数据源微信搜狗内部含有限制爬虫执行的机制,会过滤爬虫请求的机制,例如同一ip频繁访问会被禁止访问,所以必须满足以下条件才能正常执行爬虫:
p1:爬虫执行过程中需要不停切换浏览器头部信息,可以通过scrapy提供的内部api切换http请求头中包含的浏览器头部信息;
p2:爬虫执行间隔不能太短,由于需要获取的内容比较多,微信搜狗不允许短时间内发送多个请求,各个请求之间最好有一定的时间间隔,具体时间间隔自行调试;
p3:不同的爬虫尽量不要异步执行,虽然可以使用操作系统多线程执行,但由于网络带宽资源一定,异步执行爬虫会抢用带宽资源,导致意外发生。
p4:使用ip代理池,由于数据源微信搜狗具有禁止同一ip过度访问资源的机制,可以通过使用ip代理的方式来执行爬虫。
与现有技术相比,本发明技术方案的有益效果是:利用scrapy框架提供的爬虫技术爬取目标微信公众号的历史内容,且实现按天实时爬取,同步更新目标公众号的内容,并利用javaweb相关技术将本地存储公众号内容查询展示到前端页面上。
附图说明
图1为本发明实施例的流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
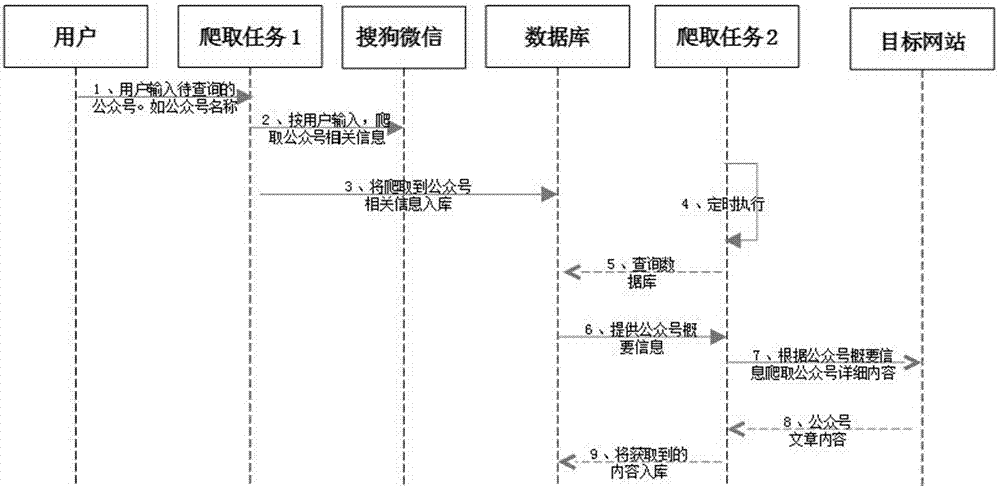
如图1所示,本实施例运用python3.5的环境,首先下载scrapy依赖包,运行scrapy命令创建爬虫项目;其次安装python的编辑工具,用pip命令安装必要的函数依赖包。本发明一种爬取微信公众号信息的方法,具体实施步骤如下:
s1:根据用户输入,确定待爬取公众号名称,将待爬取公众号的编号入库;
s2:依照预设的爬虫匹配规则,根据公众号名称爬取待爬取公众号,得到待爬取公众号的相关信息;
s3:将爬虫获取的待爬取公众号相关信息进行入库处理,处理后的待爬取公众号的相关信息入库;
s4:设置爬虫定时执行时间,根据待爬取公众号的相关信息定时爬取待爬取待爬取公众号文章,将爬虫获取的公众号文章入库;
s5:显示公众号文章。
具体地,步骤s1具体包括以下两种情况:
s11:模糊匹配,即用户不清楚待爬取的公众号的准确名字,初步确定待爬取的公众号后,把其编号入库作为待爬取的公众号;
s12:精确匹配,即用户清楚待爬取的公众号的准确名字,通过精确键入公众号名称或者编号,直接入库,并作为待爬取的公众号。
具体地,步骤s2所述的预设的爬虫匹配规则的设定方法为:通过scrapy框架爬取指定页面的html源码,并按照库结构和样式规则表,编写匹配规则;所述的待爬取公众号的相关信息包括待爬取公众号的编号、名称、发表的文章名称、发表的文章。
具体地,步骤s3所述的入库处理就是进行加工和预处理,具体包括去重、按照指定格式编排、记录入库时间。
具体地,步骤s4所述的定时执行时间设置为一天。
具体地,步骤s5所述的显示公众号文章就是利用javaweb相关技术将本地存储公众号内容查询展示到前端页面上。
具体地,数据源微信搜狗内部含有限制爬虫执行的机制,会过滤爬虫请求的机制,例如同一ip频繁访问会被禁止访问,所以必须满足以下条件才能正常执行爬虫:
p1:爬虫执行过程中需要不停切换浏览器头部信息,可以通过scrapy提供的内部api切换http请求头中包含的浏览器头部信息;
p2:爬虫执行间隔不能太短,由于需要获取的内容比较多,微信搜狗不允许短时间内发送多个请求,各个请求之间最好有一定的时间间隔,具体时间间隔自行调试;
p3:不同的爬虫尽量不要异步执行,虽然可以使用操作系统多线程执行,但由于网络带宽资源一定,异步执行爬虫会抢用带宽资源,导致意外发生。
p4:使用ip代理池,由于数据源微信搜狗具有禁止同一ip过度访问资源的机制,可以通过使用ip代理的方式来执行爬虫。
具体地,本实施例采用mysql数据库来存储指数据,公众号搜索表有如下字段:
user:用户名称,varchar类型;
wxname:公众号名称,varchar类型;
wxno:公众号编号,varchar类型;
imgurl:公众号图片永久链接,varchar类型;
createdate:数据采集时间;
updatedate:数据更新时间;
wxnameurl:微信文章链接地址;
公众号细节表:detail
introduction:文章介绍,varchar类型;
title:文章标题,varchar类型;
wxname:公众号名称,varchar类型;
wxno:公众号编号,varchar类型;
createdate:数据采集时间,varchar类型
updatedate:数据更新时间,varchar类型;
wxnameurl:微信文章链接地址,varchar类型
contentlink:原文链接,varchar类型
html:网站文章内容html文本media类型
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!