一种基于深度强化学习的推荐算法的制作方法
本发明涉及推荐方法领域,更具体地,涉及一种基于深度强化学习的推荐算法。
背景技术:
目前,分析用户行为,让系统“猜测”出用户感兴趣的物品,提升用户体验,是一项庞大的系统工程。常用的推荐算法包括协同过滤算法、基于内容的推荐算法、基于关联规则的推荐算法,而这些算法存在以下问题:(1)冷启动问题:很难决定向新用户推荐何种物品,很难决定新物品向哪个用户进行推荐,导致新用户、新物品无法得到科学合理的推荐;(2)长尾现象:对于热门的物品进行大量的推荐,而对于比较冷门的物品进行较少的推荐,导致热门的物品越来越热门,冷门的物品越来越冷门,也导致推荐系统无法推荐新颖的物品,不能给用户带来惊喜;(3)用户隐私保护:推荐系统需要利用用户的历史行为信息、甚至用户的人口统计属性信息,一个不能很好保护用户隐私的系统会让用户缺少安全感,不愿提供个人信息,甚至造成无法提供有效推荐;(4)常用的推荐算法都属于机器学习领域,都需要大量的历史数据集,对于刚上线的电子商务系统来说,没有用户、交易数据积累,是不现实的。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于深度强化学习的推荐算法。
为解决上述技术问题,本发明的技术方案如下:
一种基于深度强化学习的推荐算法,其特征在于,它包括以下步骤:
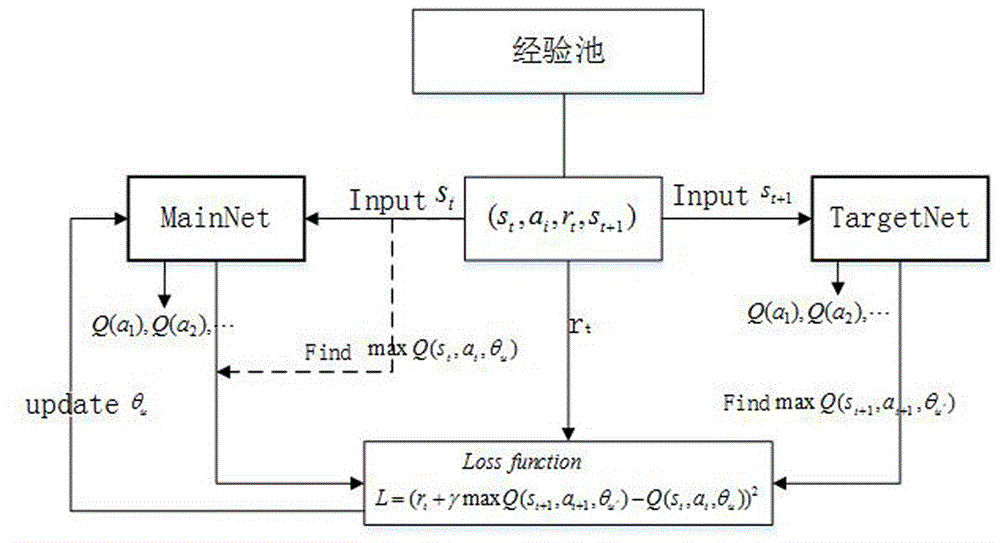
s1:初始化经验池,设置其容量w,经验池是商品推荐动作的集合,用于存储训练样本,开始训练之前经验池为空;
s2:建立mainnet神经网络,并对其进行初始化,所述的mainnet神经网络是主神经网络,用于得到推荐列表;
s3:建立targetnet神经网络,并对其进行初始化,所述的targetnet神经网络用于训练模型参数,得到最优模型参数;
s4:设定训练片段总数m;
s5:依据t时刻用户最近浏览的n个商品,初始化当前状态st,若用户最近浏览的商品为空,以n个热门商品代替;
s6:当前状态st作为mainnet神经网络的输入,得到当前状态st下可选动作的q值列表q(st,at,θu),其中,st是当前状态,at是执行动作,θu是mainnet神经网络的参数;
s7:根据执行动作at,用户按照自己的兴趣进行点击/购买/忽略后,计算奖赏rt和下一状态st+1;
s8:将商品推荐动作集合(st,at,rt,st+1)存入经验池中;
s9:循环执行步骤s6-s8,直至经验池中存放着w个训练数据;
s10:随机从经验池中取出m个训练数据,将训练数据中的每一个下一状态st+1作为targetnet神经网络的输入,得到下一状态st+1下可选动作的q值列表q(st+1,at+1,θu′);
s11:更新mainnet神经网络的参数θu;
s12:每经过c轮迭代,其中c为预设的迭代数值,将mainnet神经网络的参数复制给targetnet神经网络。
进一步地,步骤s2中所述的初始化包括:初始化参数θu,输入为当前状态st,输出为当前状态st下可选动作的q值列表q(st,at,θu)。
进一步地,所述的当前状态st表示如下:
其中,
进一步地,步骤s3中所述的初始化包括:初始化参数θu′,输入为下一状态st+1,输出为下一状态st+1下可选动作的q值列表q(st+1,at+1,θu′)。
进一步地,步骤s6具体包括以下步骤:
s61:计算的当前状态st下可选动作的q值,计算公式如下:
q(st,at)=eπ[rt+1+γrt+2+γ2rt+3+...|s=st,a=at]
其中,γ是折扣系数,st是当前状态,at是当前动作,rt+1是t+1时刻的奖励函数值,rt+2是t+2时刻的奖励函数值,rt+3是t+3时刻的奖励函数值,eπ是q(s,a,θu)值最大时的回报函数值,是一个状态决策函数;
s62:生成当前状态st下可选动作的q值列表q(st,at,θu)。
进一步地,步骤s7中所述的执行动作at表示如下:
其中,k为推荐给用户的商品个数,
进一步地,步骤s7中所述的奖赏rt的定义是:在当前状态下如果发生商品点击的动作,则奖赏为用户点击的商品个数;在当前状态下如果发生商品购买的动作,则奖赏为用户购买商品的价格;其他情况下,奖赏值0。
进一步地,步骤s10具体包括以下步骤:
s101:随机从经验池中取出m个训练数据;
s102:计算下一状态st+1下可选动作的q值,计算公式如下:
q(st+1,at+1)=eπ[rt+1+γrt+2+γ2rt+3+...|s=st+1,a=at+1]
其中,γ是折扣系数,st+1是下一状态,at+1是下一动作,rt+2是t+2时刻的奖励函数值,rt+3是t+3时刻的奖励函数值,rt+4是t+4时刻的奖励函数值;
s103:生成下一状态st+1下可选动作的q值列表q(st+1,at+1,θu′)。
进一步地,步骤s11具体包括以下步骤:
s111:计算当前状态st下的targetq值,计算公式如下:
targetq=rt+γmaxq(st+1,at+1,θu′)
其中,rt是当前动作的奖赏,γ是折扣系数,st+1是下一状态,at+1是下一动作,θu′是targetnet神经网络的参数,q(st+1,at+1,θu′)是targetnet神经网络输出的下一状态st+1下可选动作的q值列表;
s112:计算损失函数,损失函数取得最小值时,更新mainnet神经网络的参数θu,损失函数如下:
l(θu)=e[(targetq-q(st,at,θu))2]
=e[(rt+γmaxq(st+1,at+1,θu′)-q(st,at,θu))2]
其中,e是求均值,rt是当前动作的奖赏,γ是折扣系数,q(st,at,θu)是当前状态st下可选动作的q值列表,q(st+1,at+1,θu′)是下一状态st+1下可选动作的q值列表,st是当前状态,at是当前动作,st+1是下一状态,at+1是下一动作,θu是mainnet神经网络的参数,θu′是targetnet神经网络的参数。
进一步地,当前状态st中的sex为用户的长期特征,用于区分不同的群体,对于不同的用户群体,在相同的推荐列表下,也会做出不同的选择;当前状态st中的holiday、month、day、weather为外部条件特征,不同的外部条件特征会很大程度上改变用户的购物行为,比如用户在节假日的行为更活跃。
进一步地,当用户对执行动作at没有点击或购买动作时,推荐列表不变,当用户动对执行作at有点击或购买时,推荐列表改变,即将推荐列表中前面的浏览商品去掉,补上刚产生过点击或购买行为的商品。
与现有技术相比,本发明技术方案的有益效果是:(1)数据优势,采用基于深度强化学习的推荐算法,克服了传统机器学习的缺点,不需要历史数据,只要网站存在交易行为,逐步学习,自我优化和完善;(2)采用可选动作的q值列表,充分考虑到物品的相关性,将执行动作定义为推荐给用户的商品列表;(3)构建包括mainnet神经网络和targetnet神经网络的双网络结构,提高了算法稳定性。
附图说明
图1为本发明一种基于深度强化学习的推荐算法的流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
结合图1,本发明的具体实施步骤如下:
一种基于深度强化学习的推荐算法,其特征在于,它包括以下步骤:
s1:初始化经验池,设置其容量w=100000,经验池是商品推荐动作的集合,用于存储训练样本,开始训练之前经验池为空;
s2:建立mainnet神经网络,并对其进行初始化,所述的mainnet神经网络是主神经网络,用于得到推荐列表,初始化内容包括:按标准正态分布初始化网络参数θu,输入为当前状态st,输出为当前状态st下可选动作的q值列表q(st,at,θu);
s3:建立targetnet神经网络,并对其进行初始化,所述的targetnet神经网络用于训练模型参数,得到最优模型参数,初始化内容包括:按标准正态分布初始化参数θu′,输入为下一状态st+1,输出为下一状态st+1下可选动作的q值列表q(st+1,at+1,θu′);
s4:设定训练片段总数m=64;
s5:依据t时刻用户最近浏览的n个商品,其中n=10,初始化当前状态st,若用户最近浏览的商品为空,以n个热门商品代替;
s6:当前状态st作为mainnet神经网络的输入,得到当前状态st下可选动作的q值列表q(st,at,θu);
s7:根据执行动作at,用户按照自己的兴趣进行点击/购买/忽略后,计算奖赏rt和下一状态st+1;
s8:将商品推荐动作的集合(st,at,rt,st+1)存入经验池中;
s9:循环执行步骤s6-s8,直至经验池中存放着w个训练数据,其中w=100000;
s10:随机从经验池中取出m个训练数据,其中m=64,将训练数据中的每一个下一状态st+1作为targetnet神经网络的输入,得到下一状态st+1下可选动作的q值列表q(st+1,at+1,θu′);
s11:更新mainnet神经网络的参数θu;
s12:每经过c轮迭代,c=5,将mainnet神经网络的参数复制给targetnet神经网络。
具体地,所述的当前状态st表示如下:
其中,
具体地,步骤s6具体包括以下步骤:
s61:计算的当前状态st下可选动作的q值,计算公式如下:
q(st,at)=eπ[rt+1+γrt+2+γ2rt+3+...|s=st,a=at]
其中,γ是折扣系数,st是当前状态,at是当前动作,rt+1是t+1时刻的奖励函数值,rt+2是t+2时刻的奖励函数值,rt+3是t+3时刻的奖励函数值,eπ是q(s,a,θu)值最大时的回报函数值,是一个状态决策函数;
s62:生成当前状态st下可选动作的q值列表q(st,at,θu)。
具体地,步骤s7中所述的执行动作at表示如下:
其中,k为推荐给用户的商品个数,
具体地,步骤s7中所述的奖赏rt的定义是:在当前状态下如果发生商品点击的动作,则奖赏为用户点击的商品个数;在当前状态下如果发生商品购买的动作,则奖赏为用户购买商品的价格;其他情况下,奖赏值0。
具体地,步骤s10具体包括以下步骤:
s101:随机从经验池中取出m个训练数据,其中m=64;
s102:计算下一状态st+1下可选动作的q值,计算公式如下:
q(st+1,at+1)=eπ[rt+1+γrt+2+γ2rt+3+...|s=st+1,a=at+1]
其中,γ是折扣系数,st+1是下一状态,at+1是下一动作,rt+2是t+2时刻的奖励函数值,rt+3是t+3时刻的奖励函数值,rt+4是t+4时刻的奖励函数值;
s103:生成下一状态st+1下可选动作的q值列表q(st+1,at+1,θu′)。
具体地,步骤s11具体包括以下步骤:
s111:计算当前状态st下的targetq值,计算公式如下:
targetq=rt+γmaxq(st+1,at+1,θu′)
其中,rt是当前动作的奖赏,γ是折扣系数,st+1是下一状态,at+1是下一动作,θu′是targetnet神经网络的参数,q(st+1,at+1,θu′)是targetnet神经网络下一状态st+1下可选动作的q值列表;
s112:计算损失函数,损失函数取得最小值时,更新mainnet神经网络的参数θu,损失函数如下:
l(θu)=e[(targetq-q(st,at,θu))2]
=e[(rt+γmaxq(st+1,at+1,θu′)-q(st,at,θu))2]
其中,e是求均值,rt是当前动作的奖赏,γ是折扣系数,q(st,at,θu)是当前状态st下可选动作的q值列表,q(st+1,at+1,θu′)是下一状态st+1下可选动作的q值列表,st是当前状态,at是当前动作,st+1是下一状态,at+1是下一动作,θu是mainnet神经网络的参数,θu′是targetnet神经网络的参数。
具体地,当前状态st中的sex为用户的长期特征,用于区分不同的群体,对于不同的用户群体,在相同的推荐列表下,也会做出不同的选择;当前状态st中的holiday、month、day、weather为外部条件特征,不同的外部条件特征会很大程度上改变用户的购物行为,比如用户在节假日的行为更活跃。
具体地,当用户对执行动作at没有点击或购买动作时,推荐列表不变,当用户对执行动作at有点击或购买时,推荐列表改变,即将推荐列表中前面的浏览商品去掉,补上刚产生过点击或购买行为的商品。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!