一种在线观点挖掘方法及系统与流程
本发明属于自然语言处理技术领域,具体涉及一种基于有监督学习的在线观点挖掘方法及系统。
背景技术:
21世纪是信息爆炸的时代,各行各业时时刻刻都会产生大量的数据量,据预测,到2020年,全球数据总量将达到35zb。大数据的数据类型中包含有图像数据、文本数据等,而文本数据作为大数据中的一种类型,符合人类语言的特征,即一段文本往往含有主语、谓语、宾语等,因此文本数据往往含有对一个对象的描述,该描述有丰富的情感特征。对文本数据进行情感分析则有多种用途,例如资讯预测、舆情监测、实现能判别情绪的机器、用作局势辅助判断等。
伴随着信息时代的到来,互联网和网络购物也逐渐发展起来,越来越多的人将网络购物作为主要购物途径,购买人在完成购买商品并体验之后会对该商品进行评价,阐述自己的观点。对于这些观点,商家若能准确、快速、大规模地获取到,那么商家就能在未来的产品中保持商品优点,改正缺点;普通用户若能得到,那么用户就能快速得知该商品的整体优劣,以及商品某一指定属性的描述和好评度,极大地提升用户选购商品的效率,改善用户的购物体验。因此,对评论数据的更细粒度的观点挖掘已经成为当今的研究热点之一,然而在大数据时代,隐藏在大规模数据中的信息量是巨大的,但是从大规模数据中获取有价值的信息又是极其困难的。
技术实现要素:
针对上述背景技术中所讲的问题,本发明提出了一种基于有监督学习,结合网络爬虫,批量获取商品的评论并对评论的观点进行更细粒度的挖掘,来从大量的商品评价中挖掘用户观点,让用户能够在线快速获取一件商品的不同粒度的“属性-观点”信息,提升用户获取关于商品多粒度的质量信息的速度,提高用户购物体验,并将这些数据转化为结构化数据进行存储,方便以后使用,能极大提高人们获取商品观点的效率的基于有监督学习的在线观点挖掘方法及系统。
本发明的技术方案如下:
上述的在线观点挖掘方法,包括以下步骤:
1)通过网络爬虫爬取数据
构建一个定向网络爬虫,以实现自动抓取针对电商的商品属性和商品评论信息数据;
2)对爬取的文本数据进行分词
对爬取的文本数据采用分词算法进行预处理,以转换成计算机方便处理的格式;
3)情感分析
对商品细粒度属性和情感进行倾向性分析和观点挖掘;
4)属性的抽取
采用启发式规则方法,在大量文本中总结出需要寻找的“属性-观点”这种特定关系的规律,并基于“短评论包含的评价对象应是单一的”基本假设,实现从评论句中获取商品细粒度属性和情感描述信息。
所述在线观点挖掘方法,其中,所述步骤1)通过网络爬虫爬取数据的流程为:(1)用户输入商品的链接,爬虫抓取该商品的网页内容,从网页内容中解析出商品已有的基本参数;(2)组装获取评论的链接,爬取第一页的评论;(3)将下一页评论的网页加入待爬取队列,并爬取该页评论;(4)循环进行上述步骤(3),直到最后一页评论数据爬取完毕,或者由用户手动停止。
所述在线观点挖掘方法,其中:所述步骤1)中通过网络爬虫爬取的数据主要包括商品已有的基本参数、商品图片和商品的评论内容;所述商品已有的基本参数和商品图片用于将商品直观地展示给用户,商品的评论内容用于情感分类、属性-观点关系抽取,并将结果以图标的形式展示给用户。
所述在线观点挖掘方法,其中:所述步骤2)中的分词算法使用的是斯坦福大学分词工具stanford-corenlp;所述斯坦福大学分词工具stanford-corenlp是基于与词性标注相结合的分词算法实现的。
所述在线观点挖掘方法,其中:所述步骤3)中的情感分析又称作倾向性分析和观点挖掘,其是对带有人类主观情感的文本数据的分析过程简称且包含了处理文本、总结文本规律和产生分析结果。
所述在线观点挖掘方法,其中,所述步骤3)的情感分析采用有监督情感分类框架,具体流程为:首先我们将通过网络爬虫爬取的数据进行预处理,接下来将处理好的数据大致分为两个部分,一部分是训练数据,另一部分是测试数据,然后将训练数据用于模型的训练,当模型训练完成后,将之前预留好的测试数据用于模型的测试,并根据分类结果评判模型的效果,若模型的效果令人满意,接下来则进行所述步骤4)属性抽取过程,若模型的效果达不到预期的效果则分析原因,重新训练模型。
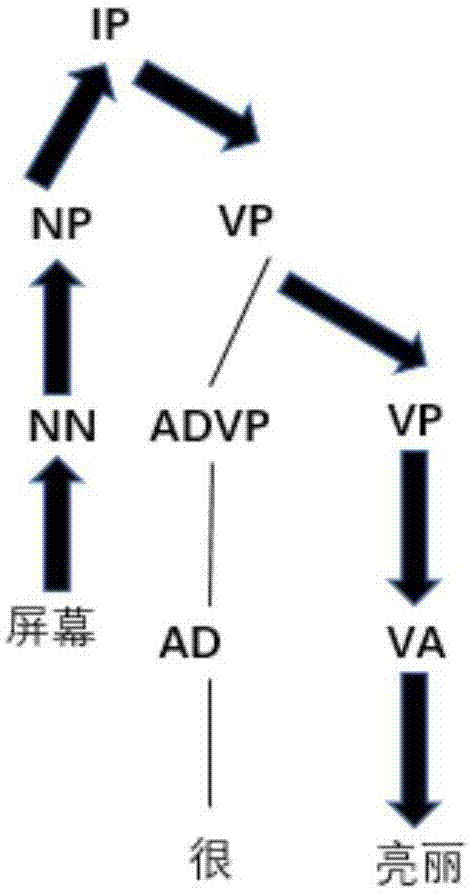
所述在线观点挖掘方法,其中,所述步骤4)中所述“属性-观点”抽取的细节为:使用斯坦福大学语法分析器stanford-parser将句子的句法树解析出来,然后以简单从句ip为单位,找到ip下的名词nn,然后向右搜索动词短语vp,再一直向下搜索vp,直到找到表语形容词va,该va即为nn的形容词。
一种在线观点挖掘系统,其中:所述系统包括网络爬虫模块、数据处理模块和观点挖掘模块;所述网络爬虫模块主要用于实现商品图片下载、实现商品已有的基本参数下载和实现商品评论下载;所述数据处理模块主要用于实现分词功能和实现去除停用词功能;所述观点挖掘模块主要用于实现实现情感分析功能和实现属性-观点关系抽取功能。
所述的在线观点挖掘系统,其中:所述网络爬虫模块的具体工作流程为:首先让用户输入需要爬取商品的链接,后台判断该商品的链接是否符合规则,若不符合规则,提供url模板给用户参考,若满足规则爬虫抓取该商品的网页内容,从网页内容中解析出商品已有的基本参数;封装获取评论的链接,爬取第一页的评论;将下一页评论的网页加入待爬取队列,并爬取该页评论,循环爬取,直到最后一页评论数据爬取完毕,或者由用户手动停止;所述数据处理模块的具体工作流程为:首先输入待分词的句子,后台用斯坦福大学的分词器对该句子进行分词,并将句子当中的停用词去除,最终将分好词的数据进行保存。
所述在线观点挖掘系统,其中:所述观点挖掘模块的具体工作流程为:首先将已分词成功的数据划分为训练数据以及测试数据,将训练数据利用最大熵模型进行训练,模型训练成功后将测试数据放入利用最大熵模型训练好的模型当中进行测试,如若测试结果满足需求,则将利用最大熵模型训练好的模型进行保存,否则调整参数以及特征重新训练模型,并且将测试数据使用斯坦福大学语法分析器进行观点的挖掘。
有益效果:
本发明在线观点挖掘方法及系统基于有监督学习,结合网络爬虫,批量获取商品的评论并对评论的观点进行更细粒度的挖掘,来从大量的商品评价中挖掘用户观点,让用户能够在线快速获取一件商品的不同粒度的“属性-观点”信息,提升用户获取关于商品多粒度的质量信息的速度,提高用户购物体验,并将这些数据转化为结构化数据进行存储,方便以后使用,能极大提高人们获取商品观点的效率。
附图说明
图1为本发明在线观点挖掘方法的语法分析结果实例图;
图2为本发明在线观点挖掘方法的有监督情感分类流程图;
图3为本发明在线观点挖掘系统的网络爬虫模块的流程图;
图4为本发明在线观点挖掘系统的数据处理模块的流程图;
图5为本发明在线观点挖掘系统的观点挖掘模块的流程图。
图6为本发明在线观点挖掘系统的实验中对比各模型分类结果的f值平均值曲线图。
具体实施方式
本发明在线观点挖掘方法,包括以下步骤:
1)通过网络爬虫爬取数据
构建一个定向网络爬虫,以实现自动抓取针对电商的商品属性和商品评论信息数据。
本发明构建了一个定向网络爬虫,针对电商的商品属性和商品评论,按照一定规则,自动地抓取这些信息;本实施例中采用网络爬虫技术实现用户输入京东商品描述网页链接,在线地、实时地将该商品网页链接对应的商品信息和评论进行抓取的功能;涉及网络爬虫的相关技术如下:httpclient,htmlcleaner,xpath,mysql。
上述步骤1)通过网络爬虫爬取数据的流程为:
(1)用户输入商品的链接,爬虫抓取该商品的网页内容,从网页内容中解析出商品已有的基本参数;
(2)组装获取评论的链接,爬取第一页的评论;
(3)将下一页评论的网页加入待爬取队列,并爬取该页评论;
(4)循环进行上述步骤(3),直到最后一页评论数据爬取完毕,或者由用户手动停止;
上述步骤1)通过网络爬虫爬取的数据主要包括商品已有的基本参数、商品图片和商品的评论内容;其中,商品已有的基本参数和商品图片用于将商品直观地展示给用户,商品的评论内容用于情感分类、属性-观点关系抽取,并将结果以图标的形式展示给用户。
由于apachehttpclient工具小巧方便,比javajdk中自带的网络访问工具更轻巧,而且httpclient支持最新的网络协议,因此本系统选用apachehttpclient作为访问网络资源的工具。在数据处理方面,java对象转成json字符串时使用net.sf.json工具包,解析json字符串时使用org.json工具包。
在大数据时代,如何得到完整全面的数据极其不容易,要做到大数据时代的分析,仅仅靠人工收集的远远不够的,这时就需要网络爬虫的力量。网络爬虫已经应用于搜索引擎等产品中,它能像蜘蛛一样将互联网上的信息爬取下来并存储。
2)对爬取的文本数据进行分词
对爬取的文本数据采用分词算法进行预处理,以转换成计算机方便处理的格式。
上述步骤2)中的分词算法使用斯坦福大学分词工具(stanford-corenlp),其是基于与词性标注相结合的分词算法实现的;本发明研究的商品评论观点挖掘任务也需要中文分词算法进行预处理。
中文分词(chinesewordsegmentation)是指将一段中文文本以词语为单位分割开;不同于英文文本,英文文本在词语与词语之间已经有空格作为分割符将词语分开,但是中文文本是没有这样的分割符的;而在机器学习领域,以句子为单位进行分析,效果显然是不好的,因为两篇文章很少出现两句一模一样的句子,所以中文文本只有经过分词之后才能用于机器学习等领域;例如中文文本“屏幕很亮丽”,分词之后即为“屏幕很亮丽”,这时才能转换成词向量等计算机方便处理的格式。现阶段,分词算法按实现方式可分为三大类,分别是基于理解的分词算法、基于字符串匹配的分词算法和基于统计的分词算法;而按同词性标注相结合与否,分词算法又可以分为相结合分词算法和不相结合分词算法。中文分词旨在将中文文本转化为机器方便处理的以词语为单位的形式,是其它应用的基础;在现阶段,分词能应用于搜索引擎、机器翻译、语音合成、翻译等任务上。
3)情感分析
对商品细粒度属性和情感进行倾向性分析和观点挖掘。
情感分析又称作倾向性分析和观点挖掘,是对带有人类主观情感的文本数据的分析过程简称,这个过程包含了处理文本、总结文本规律和产生分析结果;本发明进行的研究进行了商品细粒度属性和情感的挖掘分析。用户对商品的带有主观观点的评价对商品优劣区别有着明显的导向作用,而将评价对象与对该对象的描述抽取出来意义重大,可以让用户了解商品质量整体的好坏,也可快速了解该商品某一特定属性质量的好坏。
上述步骤3)情感分析采用有监督情感分类框架,具体流程为:首先我们将通过网络爬虫爬取的数据进行预处理,如中文分词、词语筛选、去除标点符号,接下来将处理好的数据大致分为两个部分,一个部分是训练数据,一部分是测试数据,并将训练数据用于模型的训练,当模型训练完成后,将之前预留好的测试数据用于模型的测试,并根据分类结果评判模型的效果,若模型的效果令人满意,则进行接下来属性抽取的步骤,若模型的效果达不到预期的效果则分析原因,重新训练模型。
4)属性的抽取
采用启发式规则方法,在大量文本中总结出需要寻找的“属性-观点”这种特定关系的规律,并基于“短评论包含的评价对象应是单一的”基本假设,实现从评论句中获取商品细粒度属性和情感描述信息。
上述步骤4)中“属性-观点”抽取的细节为:使用斯坦福大学语法分析器(stanford-parser)将句子的句法树解析出来,然后以简单从句(ip)为单位,找到ip下的名词(nn),然后向右搜索动词短语(vp),再一直向下搜索vp,直到找到表语形容词(va),该va即为nn的形容词,语法分析结果实例如图1所示。
电商网站通常对一个商品有部分的参数和参数对应的值,这些数据都是直接存在的客观的数据,通过网络爬虫可以对这些属性进行爬取。而用户的评论中往往也隐含了对该商品的属性和描述。
本发明基于有监督学习的在线观点挖掘系统,包括网络爬虫模块1、数据处理模块2和观点挖掘模块3。
如图3所示,该网络爬虫模块1主要用于实现商品图片下载、实现商品已有的基本参数下载和实现商品评论下载;具体流程为:首先让用户输入需要爬取商品的链接,后台判断该商品的链接是否符合规则,若不符合规则,提供url模板给用户参考,若满足规则爬虫抓取该商品的网页内容,从网页内容中解析出商品已有的基本参数;封装获取评论的链接,爬取第一页的评论;将下一页评论的网页加入待爬取队列,并爬取该页评论,循环爬取,直到最后一页评论数据爬取完毕,或者由用户手动停止。网络爬虫模块1功能表如表格6所示:
表格1
如图4所示,该数据处理模块2主要用于实现分词功能和实现去除停用词功能;具体工作流程为:首先输入待分词的句子,后台用斯坦福大学的分词器对该句子进行分词,并将句子当中的停用词去除,最终将分好词的数据进行保存。数据处理模块2功能表如表格7所示:
表格2
如图5所示,该观点挖掘模块3主要用于实现实现情感分析功能和实现属性-观点关系抽取功能,具体工作流程为:首先将已分词成功的数据划分为训练数据以及测试数据,将训练数据利用最大熵模型进行训练,模型训练成功后将测试数据放入利用最大熵模型训练好的模型当中进行测试,如若测试结果满足需求,则将该利用最大熵模型训练好的模型进行保存,否则调整参数以及特征重新训练模型,并且将测试数据使用斯坦福大学语法分析器进行观点的挖掘。该观点挖掘模块3的功能表如表格8所示:
表格3
本发明在线观点挖掘系统能够实现最大熵模型,并在下方介绍最大熵模型的数学原理。
以下为根据实验结果选择的最大熵模型,实验结果如下所示:
本发明在线观点挖掘系统中具体实现了两种分类模型,分别是朴素贝叶斯模型和最大熵模型,并且调用了一种开源的分类模型,即支持向量机模型(supportvectormachines,svm)。下面介绍朴素贝叶斯模型和最大熵模型的数学原理:
(1)朴素贝叶斯
贝叶斯定理如公式1所示:
p(y|x)表示事件x已经发生的前提下,事件y发生的概率。
给定训练集(x,y),其中每个训练集样本x都包括n维特征,即x=(x1,x2,...xn),训练集共有m种标签,即y=(y1,y2,...ym)。
给定新样本x,计算它属于哪个类别的概率,并找出最大值。那么问题就转化为求解公式2:
则公式1可以改写为公式3:
由全概率公式可将公式3分解为公式4:
给出条件概率,如公式5所示:
p(x|ym)=p(x1,x2,...,xn|ym)公式5
对于公式5引入独立性的假设,假设特征与特征之间互不影响,互相独立。在这个假设前提下,条件概率(公式5)可转化为公式6:
将公式6代入公式4有公式7:
此时公式2可表示为公式8:
对于所有的ym,公式8中的分母的值都是一样的,所以在最后得到最大ym时可以忽略分母部分,即公式8最终表示为公式9:
(2)多项式朴素贝叶斯模型
多项式模型适用于特征是离散分布的情况;
先验概率如公式10所示:
其中,n代表总的训练样本数量,m代表分类标签的数量,
条件概率如公式11所示:
其中
在进行分类时,若测试样本中某个特征值xi没在训练集中找到则会使p(xi|ym)=0,此时后验概率的值等于0,然后公式9的乘积就会为0,会使公式失效,所以需要对对公式10进行平滑处理,公式10进行平滑处理之后可表示为公式12:
其中α是平滑值。
公式11可表示为公式13:
当α=1时,将平滑处理叫做拉普拉斯平滑,当0<α<1时,将平滑处理叫做利德斯通平滑,α=0时即为原公式。从难易程度和有效性来说,本发明采用拉普拉斯平滑。
(3)伯努利朴素贝叶斯模型
伯努利朴素贝叶斯模型与多项式朴素贝叶斯模型同样只适用于特征空间是离散的情况,但是与多项式贝叶斯模型不一样的是伯努利模型特征出现一次或多次都记为出现1次,不出现则记为0次。以文本分类为例,某个单词在文档中出现过,则该特征值为1,否则为0。
先验概率同公式12。
条件概率如公式14所示:
(4)最大熵模型
1)目标函数
最大熵模型是基于条件概率的。概率分布的目标函数是最大化条件熵,条件熵公式如公式15所示:
其中,x为输入输入变量,即事件;y为输出变量,即结论;z=x*y,x为所有的输入变量集合,y为所有输出变量集合。注意,z不仅是包含训练集中的输入变量和输出变量的组合,而是包含所有的可能性组合。
2)约束条件
最大熵模型需要满足两个基本条件:
a)测试集与训练集的分布相同,可表示为公式16:
其中,fi为第i维特征,e(fi)为先验分布的期望,
b)概率约束条件,可表示为公式17:
3)最终的最大熵模型可表示为18:
对p(y|x)求x的偏导,偏导数等于0时即为最优解,因此最大熵模型的公式p(y|x)可以表示为公式19:
所以
下面结合具体实验进行验证:
(1)实验目的
a)验证模型的有效性;
b)对比各模型分类结果的f值;
f值计算方法:分类正确实例数量/总测试数据实例数量*100%。
(2)数据来源及规模
京东商品评论数据,人工标注数据集的好评、差评。其中,训练数据:好评实例10000条,差评实例10000条;测试数据:好评实例983条,差评实例983条。
(3)实验步骤
1)将全部测试数据作为测试数据,以下实验均基于此测试数据;
2)实验1:将全部训练数据作为实验1的训练数据(占总训练数据的100%)作为实验1的训练数据训练模型,并对测试数据进行分类;
3)实验2:将实验1中的10000条好评随机抽取9000条,实验1中的10000条差评随机抽取9000条(占总训练数据的90%)作为实验2的训练数据训练模型,并对测试数据进行分类;
4)实验3:将实验2中的9000条好评随机抽取8000条,实验2中的9000条差评随机抽取8000条(占总训练数据的80%)作为实验3的训练数据训练模型,并对测试数据进行分类;
5)实验4:将实验3中的8000条好评随机抽取7000条,实验3中的8000条差评随机抽取7000条(占总训练数据的70%)作为实验4的训练数据训练模型,并对测试数据进行分类;
6)实验5:将实验4中的7000条好评随机抽取6000条,实验4中的7000条差评随机抽取6000条(占总训练数据的60%)作为实验5的训练数据训练模型,并对测试数据进行分类;
7)实验6:将实验5中的6000条好评随机抽取5000条,实验5中的6000条差评随机抽取5000条(占总训练数据的50%)作为实验6的训练数据训练模型,并对测试数据进行分类;
8)实验7:将实验6中的5000条好评随机抽取4000条,实验6中的5000条差评随机抽取4000条(占总训练数据的40%)作为实验7的训练数据训练模型,并对测试数据进行分类;
9)实验8:将实验7中的4000条好评随机抽取3000条,实验7中的4000条差评随机抽取3000条(占总训练数据的30%)作为实验8的训练数据训练模型,并对测试数据进行分类;
10)实验9:将实验8中的3000条好评随机抽取2000条,实验8中的3000条差评随机抽取2000条(占总训练数据的20%)作为实验9的训练数据训练模型,并对测试数据进行分类;
11)实验10:将实验9中的2000条好评随机抽取1000条,实验9中的2000条差评随机抽取1000条(占总训练数据的10%)作为实验10的训练数据训练模型,并对测试数据进行分类;
说明:实验1由于选取100%训练数据,多次重复实验没有意义,故只做一次实验1。重复实验2至实验10,每个实验做10次并记录,实验数据及结论见4.4节。
实验数据及结论
实验数据
说明:表格1、表格2、表格3、表格4的第一列为实验批次,第一行为训练数据实例数量占总训练数据实例数量的百分比。
表格4最大熵模型分类f值
表格5多项式朴素贝叶斯模型分类f值
表格6伯努利朴素贝叶斯模型分类f值
表格7svm模型分类f值
实验结论
各分类模型在有监督学习的情况下,都能对未标注文本进行分类,模型有效性得到验证;
由上述表格1,表格2,表格3、表格4和图3可知,将短文本的评论数据作为训练和测试数据的情况下,多次实验均证明最大熵模型的分类f值最高。因此,本系统选用最大熵模型作为最终的分类模型。
本发明基于有监督学习,结合网络爬虫,批量获取商品的评论并对评论的观点进行更细粒度的挖掘,来从大量的商品评价中挖掘用户观点,让用户能够在线快速获取一件商品的不同粒度的“属性-观点”信息,提升用户获取关于商品多粒度的质量信息的速度,提高用户购物体验,并将这些数据转化为结构化数据进行存储,方便以后使用,能极大提高人们获取商品观点的效率。
- 还没有人留言评论。精彩留言会获得点赞!