一种软件bug报告分类系统及分类方法与流程
本发明涉及一种计算机软件测试方法,尤其是一种软件bug报告的分类系统及方法。
背景技术:
在对软件bug报告严重性自动识别分类技术的研究中,目前主要有两个挑战:一是噪音问题(数据的样本维度和单词维度都很高);二是数据不平衡问题。一些研究者试图解决bug报告分类问题时,对于高维问题提出了六种基于过滤器的特征排序技术,以减少可用软件评估标准的数量,比如有将特征选择算法与实例选择算法相结合以减少bug数据集的规模并提高数据的质量。而对于数据不平衡问题,现有技术有采用为每个类在训练集和测试集中选择相同数量bug报告的方法。然而,从原始数据集手工选择的错误报告可能是有遗漏的,这将导致训练出的分类器的泛化能力较弱。针对训练集问题的不均衡分布,也有在先技术提出了四种使用广泛的不平衡学习策略(ils)来解决来自四个不同开源项目的bug报告的不平衡分布。这个方法结合使用了常见的4种文本属性降噪的方法(ig,ch,su,rf)和样本降噪的方法(icf,lvq,drop,pop),来从双重维度(属性维度和样本维度)降低bug报告的噪音。该方法首先使用4种文本属性降噪方法来去除噪音属性,然后根据约减之后的数据进行训练分类,选择出最好的属性降噪方法;然后再使用4种样本降噪的方法去除噪音样本,选择出最好的样本去噪方法。最后组合最好的属性去噪方法和样本去噪方法来达到双重去噪的效果。但是该方法并没有考虑到数据样本不平衡问题,导致分类性能低。
技术实现要素:
针对在先技术存在的缺陷,本发明要解决的技术问题是提出了一种基于去除文本噪音和数据不平衡的软件bug报告分类系统及方法,不仅解决去除文本噪音问题,并且进一步解决去除文本噪音之后的数据不平衡问题。
本发明的技术方案是这样实现的:
一种软件bug报告分类系统,包括训练部分和测试部分,
所述训练部分包括:
数据集获取模块,用于获取数据集,并对获取的数据集进行数据“清洗”,通过词干化、去停用词把无意义的单词删除;
数据约简模块,用于将特征选择和实例选择相结合的方式来处理初始数据集;
不平衡数据集处理模块,用于通过用rsmote方法处理不平衡数据集;
所述测试部分包括:
bug报告输入模块,用于输入要进行分类的bug报告;
结果分类输出模块,用于bug报告的结果分类和输出,其中包括用choquet模糊积分集成的多个已训练过的分类器。
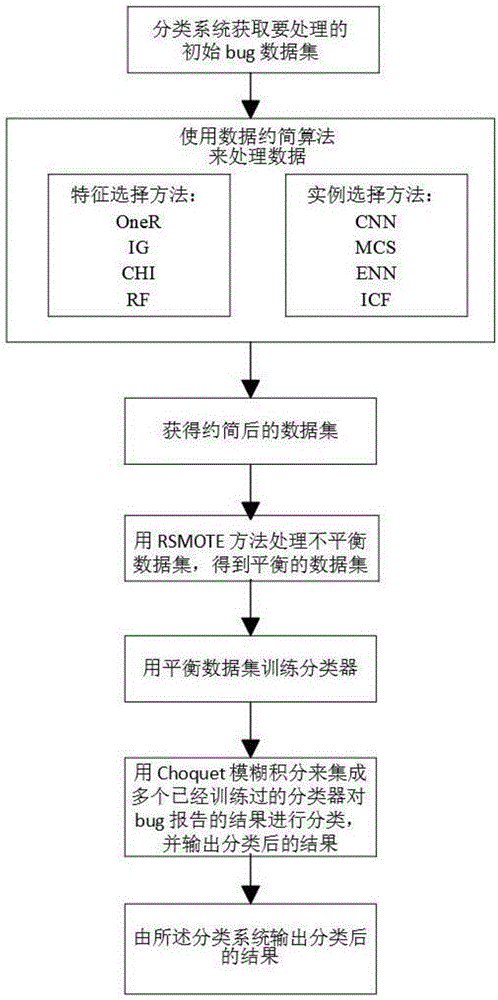
一种上述软件bug报告分类系统的分类方法,包括以下步骤:
s1,分类系统获取要处理的初始bug数据集,并对该数据集进行数据“清洗”,使用词干化,去停词,把无意义的单词删除;
s2,使用数据约简算法来处理数据,所述数据约简过程采用特征选择与实例选择相结合的方式处理初始数据集,特征选择旨在减少单词维度,获得相关单词的子集,实例选择旨在减少样本维度,获得相关bug报告的子集;
s3,获得约简后的数据集,通过约简得到的高质量数据集作为初始数据集的代表性数据集;
s4,用rsmote方法处理不平衡数据集,得到平衡数据集;
s5,用获得的平衡数据集训练分类器;
s6,用choquet模糊积分来集成多个已经训练过的分类器对bug报告的结果进行分类;
s7,分类系统输出分类后的结果。
进一步的,上述方法所述步骤s2中为了避免单个约简算法可能会产生的偏差和偶然性,使用了四种常用的特征选择算法:oner,ig,chi和rf;以及四个实例选择算法:cnn,mcs,enn和icf。
进一步的,上述方法所述步骤s4中用rsmote方法处理不平衡数据集的具体步骤如下:
s4-1,初始化参数并计算约减之后的数据集的不平衡度;
s4-2,对于每个bug报告,使用欧氏距离去找到与其最相似的k个bug报告,并从这k个bug报告中随机选择bug报告;
s4-3,在高维空间生成新的合成少数类bug报告;
s4-4,如果新的合成少数类bug报告不符合指定的约束,rsmote将重新生成少数类bug报告,直到合成少数类bug报告符合指定的约束,数据集达到平衡;
s4-5,得到平衡的数据集。
本发明的有益效果在于:
1.通过将特征选择和实例选择结合,减少了样本维度和单词维度上的数据规模,获得了更小规模且质量更高的约简数据集。
2.通过改进rsmote的随机采样技术,减弱了bug报告的不平衡程度。
3.通过使用基于choquet模糊积分的集成训练方法,结合多个rsmote提高了对bug报告严重性的识别程度,同时避免了随机采样的不确定性。
附图说明
附图1为本发明软件bug报告分类方法流程图。
具体实施方式
下面结合附图对本发明具体实施方式进行详述:
本发明所述的软件bug报告分类系统集成了数据约简技术和通过模糊积分实现的多rsmotebug报告分类技术,该系统主要包括训练部分和测试部分,
所述训练部分包括:
数据集获取模块,用于获取数据集,并对获取的数据集进行数据“清洗”,通过词干化、去停用词把无意义的单词删除;
数据约简模块,用于将特征选择和实例选择相结合的方式来处理初始数据集;
不平衡数据集处理模块,用于通过用rsmote方法处理不平衡数据集;
所述测试部分包括:
bug报告输入模块,用于输入要进行分类的bug报告;
结果分类输出模块,用于bug报告的结果分类和输出,其中包括用choquet模糊积分集成的多个已训练过的分类器。
如附图所示,本发明所述软件bug报告分类系统的分类方法包括以下步骤:
s1,分类系统获取要处理的初始bug数据集,并对该数据集进行数据“清洗”,使用词干化,去停词,把无意义的单词删除;
s2,使用数据约简算法来处理数据,所述数据约简过程采用特征选择与实例选择相结合的方式处理初始数据集,特征选择旨在减少单词维度,获得相关单词的子集,实例选择旨在减少样本维度,获得相关bug报告的子集;
s3,获得约简后的数据集,通过约简得到的高质量数据集作为初始数据集的代表性数据集;
s4,用rsmote方法处理不平衡数据集,得到平衡数据集;
s5,用获得的平衡数据集训练分类器;
s6,用choquet模糊积分来集成多个已经训练过的分类器对bug报告的结果进行分类;
s7,分类系统输出分类后的结果。
其中,所述步骤s2中为了避免单个约简算法可能会产生的偏差和偶然性,使用了四种常用的特征选择算法:oner,ig,chi和rf;以及四个实例选择算法:cnn,mcs,enn和icf。
其中,所述步骤s4中用rsmote方法处理不平衡数据集的具体步骤如下:
s4-1,初始化参数并计算约减之后的数据集的不平衡度;
s4-2,对于每个bug报告,使用欧氏距离去找到与其最相似的k个bug报告,并从这k个bug报告中随机选择bug报告;
s4-3,在高维空间仿真生成新的少数类bug报告;
s4-4,如果新的少数类bug报告不符合指定的约束,rsmote将重新生成少数类bug报告,直到新生成的少数类bug报告符合指定的约束,数据集达到平衡;
s4-5,得到平衡的数据集。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!