一种高质量超面片聚类生成方法与流程
本发明属于计算机图形学领域,涉及一种高质量超面片聚类生成方法。
背景技术:
随着高分辨率几何获取技术和三维立体视觉重建算法的快速发展,一个三维网格模型特别是大规模三维场景的网格模型中所包含的顶点数和几何面片数成倍急剧增长。在这样的背景下,对在有限可用计算资源的条件下有效并高效地处理模型的方法的能力提出了严峻的挑战。如果使用超面片作为大规模场景处理的基本单位,而非直接对大规模多边形网格中最基本粒度的单个多边形面片进行操作,则相应地三维网格模型的处理算法所需考虑的输入数量就会有数十、甚至数百倍降低。超面片的概念,与超像素类似,一个超面片是指由若干相邻的面片组成的面片集合。直观来看,如果用超面片代替对应所包含的模型原本的面片,模型就会得到非常大的简化。也就是通过在三维网格模型上把相邻的若干个面片视作一个超面片,那么其他进行模型处理的算法的处理基本单元就变成了超面片,运行效率即可大幅度提高。与此同时,这对超面片的生成以及超面片的质量提出了很高的要求。
技术实现要素:
本发明提出了一个超面片聚类生成方法,通过对大规模模型表面网格进行处理,将计算机图形学领域中大规模三维场景模型表面相邻的若干面片聚成一个超面片。在此迭代聚类过程中,方法同时考虑了测地线距离和二面角,这使得生成的超面片不仅边缘可以保持原模型的重要尖锐特征,本身也保持凸性、紧致等较好的几何性质。在超面片层次使用其他模型处理算法,可大大减小需要考虑的面片,在不损失精度的情况下起到了类似简化的作用。本方法可对目前流行的基于视觉方法生成的大规模三维场景模型进行处理,处理后的模型可以方便用户进行全局地浏览查看,并可为更高级的大规模场景模型的语义信息提取与分割提供技术支撑。
本发明的技术方案为:
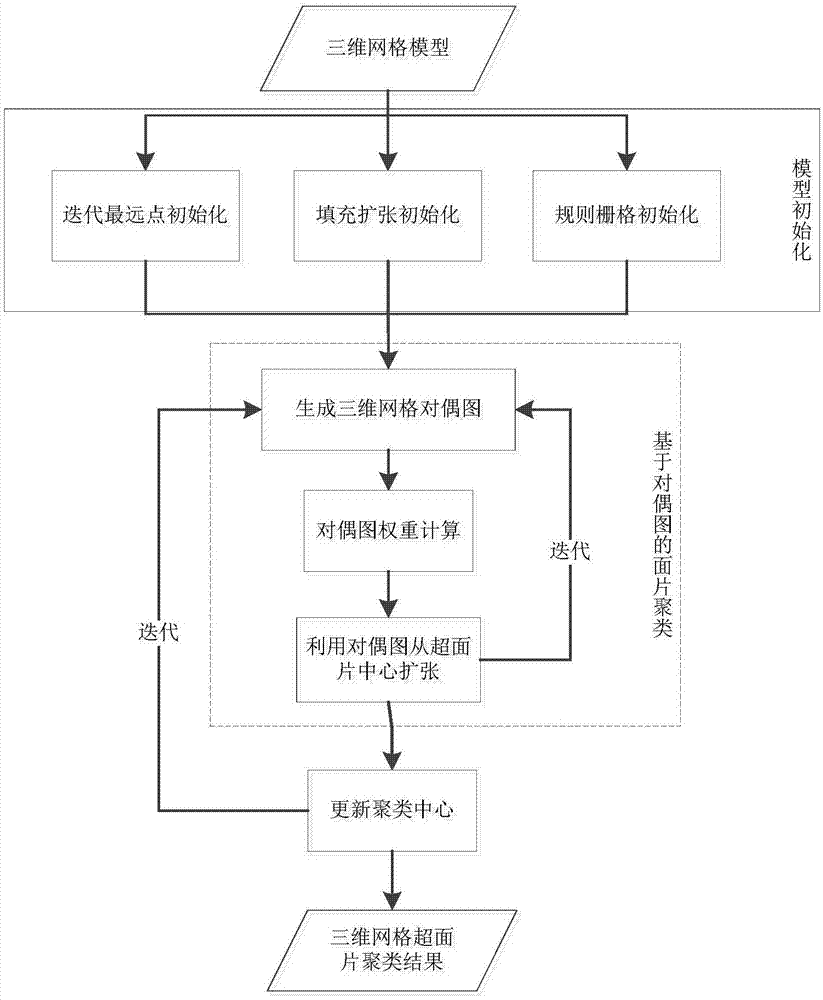
一种高质量超面片聚类生成方法,其步骤包括:
1)对三维场景模型进行初始化,得到三维场景模型中的多个聚类中心;
2)将聚类中心作为超面片中心对该三维模型的所有面片进行分类,得到该三维场景模型的多个超面片;
3)对于任意一个超面片s,对分配到该超面片s的面片面积加权平均,得到一平均值点;将面片重心离该平均值点最近的面片作为该超面片s的新的超面片中心;将每一超面片更新前后的超面片中心做对比,如果均没有发生变化则方法结束;否则继续执行步骤2)。
进一步的,初始化得到该三维场景模型中的多个聚类中心的方法为:首先选取重心距离该三维场景模型重心最近的面片作为第一个聚类中心;然后不断地选取重心到上一次所选聚类中心欧几里得距离最大的面片为一个新的聚类中心,直到聚类中心的数量达到期望的超面片数量。
进一步的,初始化得到该三维场景模型中的多个聚类中心的方法为:首先查找该三维场景模型中面片重心距离该三维场景模型重心最近的面片f,以该面片f的重心为聚类中心,然后通过面的相邻关系向外扩张,若扩张到的面片m到起始面片的距离大于2r,则将该面片m作为下一个超面片的起始面片,并将该面片m的重心作为一个新的聚类中心,然后继续向外扩张;其中,r为一设定的具体数值或者为q*l,l为该三维场景模型包围盒的对角线,q为一比例系数。
进一步的,初始化得到该三维场景模型中的多个聚类中心的方法为:首先对该三维场景模型所在的三维空间用边长为r的立方体栅格进行划分,然后将该三维场景模型包围盒的一个顶点为零点,对该三维场景模型所有面片重心坐标中的x、y和z坐标值做以2r为除数的整数除法,将得到的三个商组合起来得到一个哈希值,将具有相同哈希值的所有面片构成一个聚类中心。
进一步的,根据步骤2)确定的超面片中心对该三维场景模型的面片进行分类,得到该三维场景模型的超面片的方法为:
51)设置当前面片f到所有超面片中心的初始距离均为正无穷;
52)将每一超面片中心作为源点,计算每个超面片中心到面片f的距离;当从一个超面片s的超面片中心cs到当前面片f的最短路距离l比此刻当前面片所存储的距离值小,则更新面片f距离超面片中心cs的最短距离为l,并重新记录距离面片f最近的超面片中心为当前的超面片中心cs;
53)根据步骤52)的记录结果,将记录到同一超面片中心的面片构成一个超面片。
进一步的,首先建立该三维场景模型的对偶图,然后基于该对偶图计算每个超面片中心到面片f的距离;其中,该对偶图中每条边的权重计算方法为:使用一对具有相邻边的面片fi和fj的重心gi和gj计算近似测地权重geo(fi,fj)=||gi-mij||+||mij-gj||,其中两面片fi和fj之间的相邻边eij的中点为mij;计算角度权重
进一步的,所述步骤52)中,当所有到当前源点在设定距离阈值之内的面片都被访问过之后便终止步骤52)。
进一步的,该距离阈值为超面片跨距r的倍数;
进一步的,利用公式
与现有技术相比,本发明的积极效果为:
本发明的优势在于所聚类生成的超面片表示的三维模型具有高质量,能够较好地保持原始模型数据的重要特征和几何性质,同时可大大减少后续所需模型网格处理的数据量。本发明的方法具有尺度不变性,而且对不同的分辨率的网格模型均有效。
附图说明
图1为本发明的步骤流程图;
图2为对偶图示例。
具体实施方式
下面结合附图对本发明进行进一步详细描述。
本发明的方法主要可以分为三个大步骤:初始化、更新聚类中心和三角网格面片的聚类,其中第二个和第三个步骤会被反复交替迭代,直到收敛时方法停止。
1.模型初始化
1.1迭代最远点初始化
基于迭代最远点初始化的方法的步骤:第一步选取重心距离整个模型重心(模型所有顶点的加和平均)最近的三角形,作为第一个聚类中心;随后,不断地选取重心到最近的已有的聚类中心欧几里得距离最大的三角形为新一个聚类中心,直到聚类中心的数量达到期望的超面片数量。迭代求解聚类中心的形式化描述即:
这里gi表示第i个三角形面片fi的重心,ci表示已经被选出的第i个聚类中心,i=1,2,…n,n为已选出的聚类中心总数,gc表示已选出的聚类中心的重心,cn+1为待求的下一个聚类中心。这样的初始化步骤适合在期望的超面片数量已经确定的情况下使用。
1.2可选的其它初始化方法
如果希望得到的超面片有一个近似的超面片覆盖区域的“跨距”r,那么有另外两种可选的初始化方法。需要补充的是,这里的“跨距”r既可以指定某一个具体数值,也可以是通过计算模型包围盒的对角线的某一个固定的比例,以保证输入模型的尺度变化不会对结果造成影响。这两种固定超面片半径的初始化方法为:
●填充扩张初始化
同样从所有三角面片中选择其重心距离整个模型重心最近的三角形面片开始,以此三角面片的重心为聚类中心,然后通过面的相邻关系(有公共边的两个面片被认为是相邻的)向外扩张,若扩张到的面片到起始点的距离大于2r,那么该面片将被用作下一个超面片的起始点,并将该面片的重心作为一个新的聚类中心。具体来说,当扩张到一个距离当前超面片起始点超过r时,如果此时没有已发现的新的起始点,那么将此面片标记为新的起始点;如果此时已有新的起始点则不进行任何操作。
●规则栅格初始化
这种初始化方法首先把模型所在的三维空间用大小为r的立方体栅格进行划分,并且指定立方体栅格中的基本单元立方体的边长度为r。在实现时,不妨视模型包围盒的某一个顶点为零点,这样对模型所有面重心x、y和z坐标做以2r为除数的整数除法,得到的三个商组合起来的可以得到一个哈希值,那么具有相同哈希值的所有面片就构成一个超面片。
2.基于对偶图的面片聚类
步骤1初步得到了多个聚类中心,本步骤则针对多个聚类中心来计算出三维模型中的每个面片该归属于哪个聚类中心,某个面片归属于哪个聚类中心则表明与该聚类中心一起构成一个超面片。先介绍对偶图的概念。对三维网格模型来说,其对偶图如图2所示,每一个顶点对应着原模型中的一个面,而模型上每存在一个与两个面相邻的边(流形上每条边最多与两个面相邻),对偶图中就有一条边连接代表这两个邻接面的顶点。如图2所示,图2中加粗表示的顶点是对偶图中的顶点,实线边则是对偶图中的边;未加粗的顶点、虚线边分别为网格模型中的顶点和边,围成的区域是网格模型的面。
对模型上的每一个三角面片,本方法希望计算出该三角面片在模型的对偶图上到最近的超面片中心的距离,以及更重要的找出距离该三角面片最近的那个超面片中心。在这一步骤的初始化阶段,设置当前面片f到所有超面片中心的距离均为正无穷。接下来,取出在上一步中已经计算出的所有超面片中心,并把每一个超面片中心作为源点,通过执行dijkstra算法来计算得到每个超面片中心到拓扑临近的所有面片f的距离(且该面片f未被标记属于其他的聚类中心)。在该过程中,每当从一个超面片s到达一个三角面片f时,如果从这个超面片中心cs到当前面片f的最短路距离比此刻当前面片所存储的距离值小(此时所存储的值或来源于从其他超面片中心扩张搜索到当前面片的路径的距离值或者初始化的无穷大值),那么更新这个面片f距离超面片中心cs的最短距离值,并重新记录距离这个面片f最近的超面片中心为当前的cs。
在该过程中,有两个值得注意的关键点,第一个是关于在对偶图上每条边的权重的取法(2.1),第二点是dijkstra算法中广度优先扩张的终止条件(2.2),下面将对这两点的具体做法详细说明。
2.1对偶图权重计算
既然要为对偶图上的边选取权值,就要由对偶图中的一条边连接的两个顶点对应的是原模型上一对有着相邻边的面片考虑到这对相邻面片之间的相互关系。因此,本方法将从两个方面表示这个权重,分别是测地权重和角度权重,这样便可兼顾表面距离和夹角的尖锐程度。
1.近似测地权重:本发明使用这一对具有相邻边的面片fi和fj的重心gi和gj来计算近似的离散测地距离,除此之外,再令这两个面片之间的相邻边eij的中点为mij,那么近似侧地距离的计算公式为:
geo(fi,fj)=||gi-mij||+||mij-gj||
2.角度权重:我们考虑面片fi和fj在边eij处的无符号二面角θij,并把这个角度除以π使之正则化到[0,1]区间内,再用它乘上边eij的长度||eij||,这样就可以使得权重免受模型分辨率或者尺度的影响了。下一步通过检查θij是锐角或者钝角,以确定一个系数η(eij):
这里∈是一个较小的常数,例如0.2,这就意味着通过一个非常尖锐的角度连接到一个相邻的面片要比通过平缓的角度要花费更大的代价;至此,可以得出角度权重的最终表达式:
在对两方面的权重都做了说明之后,我们通过加权平均近似测地权重和角度权重,获得面片fi和fj的总体权重w:
这里d为输入模型的包围盒对角线长度。因为近似测地权重和角度权重的结果都是长度单位的,所以两者加权之和再除以包围盒对角线长度同样使得整体权重被正则化,亦和模型的全局尺度无关。参数α则决定了近似测地权重和角度权重之间的相互重要程度,α的值越大,得到的超面片会更贴近模型自身的形状和尖锐特征,但是同时也会造成面片相对不紧致,每个超面片的面积大小方差也会更大。
2.2扩张终止条件
如果按照传统的dijkstra算法流程,完整计算出当前源点到所有面片的最短路径,会花费大量的时间。为了提升程序的运行效率,本发明在当所有到当前源点在设定距离阈值之内的面片都被访问过之后便终止了算法。这个距离阈值可以取步骤1中所期望的超面片跨距r的倍数,例如本发明使用的值为2r。而在希望得到的超面片数量是一个给定值k的情况下,本发明给出一个合适的计算方式为:选择令
此时可能发生一种特殊情况,是在所有的最短路扩张已经完成之后,仍有一些三角面没有被任何一个超面片中心为源点扩张达到过。此时,我们依次检查所有面片,每次找到一个这样的面,就以这个面片为起始点做一次扩展。事实上,这样的情况只可能在第一次迭代中出现,之后随着超面片覆盖了整个网格便不复存在。
通过上述迭代过程,我们就找到了每一个超面片中心及其临近的面片所聚类构成的一个超面片。而最终我们将一个大规模的网格模型表示成了由一系列超面片所表示的形式。
3.更新聚类中心
经过上述步骤2,模型的多个聚类中心得到确定,而且模型所有的三角面片都分配到以某一个聚类中心所形成的超面片,接下来计算每一个超面片的中心。对于任意一个超面片,求所有分配到该超面片的三角面的面积加权平均,而如果一个三角面片的重心离这个平均值点最近,则该三角面片就是新的聚类中心,作为一个超面片中心,即
其中
gi表示第i个三角形面片fi的重心,sk表示当前第k个超面片,csk为超面片sk对应的超面片中心,ai是超面片sk中的第i个面片fi的面积。每次按照这条规则更新过超面片中心之后,都需要和更新之前的超面片中心做对比,如果所有的聚类中心的取值都没有发生变化,就说明算法已经收敛了,聚类算法结束。否则迭代进行上面的基于对偶图的面片聚类步骤以对新形成的聚类中心寻找更优的聚类,然后迭代执行更新聚类中心的步骤。
以上包含了本发明优选实施例的说明,这是为了详细说明本发明的技术特征,并不是想要将发明内容限制在实施例所描述的具体形式中,依据本发明内容主旨进行的其他修改和变型也受本专利保护。本发明内容的主旨是由权利要求书所界定,而非有实施例的具体描述所界定。
- 还没有人留言评论。精彩留言会获得点赞!