集群环境下的学生智助方法和系统与流程
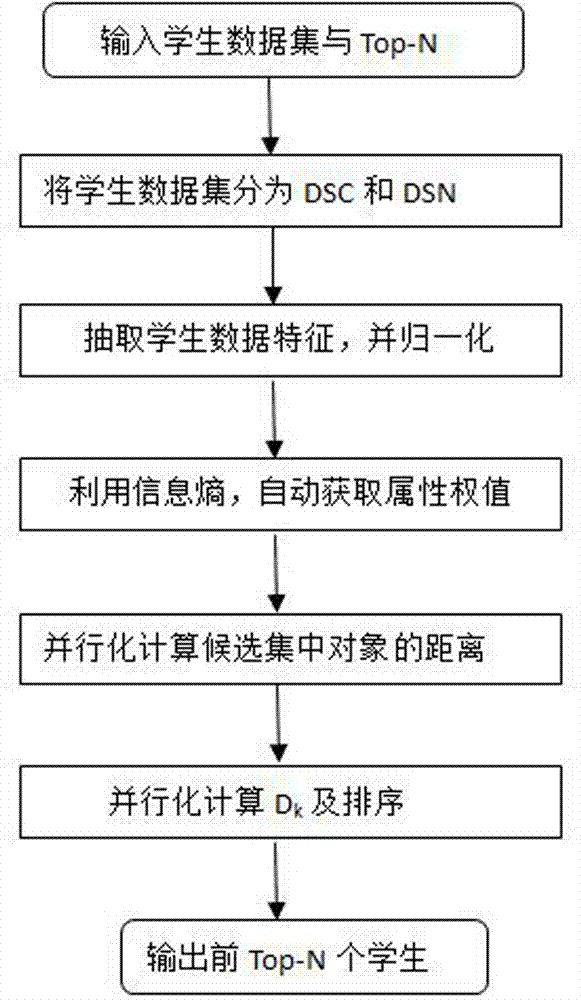
本发明集群环境下的学生智助方法和系统,属于大数据应用
技术领域:
。
背景技术:
:贫困大学生一直以来都是我国民生关注的重点,帮扶是高校和相关部门的一项人文关怀政策,如何落地最考验这份人文关怀的诚意与智慧。虽说目前各高校的认定标准已充分细化,可以体现认定的严格,但现有的贫困生判别方法较少考虑属性重要性对判别的影响,准确性较低,由此带来的“误伤”却不容忽视。如今既有学生的家庭信息档案,又有校园卡的消费记录,如何通过学生在校的客观数据和表现对学生的贫困状态进行综合考量,避免在学生贫困状态评定中出现的主观性和随机性,提供一种结构简单、准确性较高、性能优越的智助系统是值得研究和探索的新的应用领域。技术实现要素:为解决现有技术存在的不足,本发明公开了集群环境下的学生智助方法和系统,该智助方法和系统结构简单、准确性较高、性能优越,避免在学生贫困评定中出现的主观性和随机性,具有受人为因素小、伸缩性强和精度高等优点,进而使学校能够更加科学、公平、方便、高效地评判贫困生。本发明通过以下技术方案实现:集群环境下的学生智助方法,包括以下步骤:a)以学校为单位,根据学生自愿申请原则,将学生数据集分为贫困生候选集dsc和非贫困生数据集dsn;b)利用学校确定的贫困生名额与非贫困生名额比例,计算top-n的值;c)数据特征量的提取,根据数据库包含的字段名称,抽取数据特征量及特征个数,提取待分析学生行为数据的维度特征,并将每维特征归一化;d)采用信息熵自动获取每维特征的属性权值wl;e)集群环境下,引入属性权值wl,针对候选集dsc中的每个对象,利用map-reduce框架并行计算候选集dsc中每个对象与数据集dsn中每个对象间的权值欧式距离dij,形成距离矩阵d;f)通过对距离矩阵d进行累加和分析并排序,得出前top-n名学生数据,定义为贫困生。所述特征归一化的计算公式为:式中,xil表示第i个对象xi在第l维属性上的取值,min(xil)表示数据集中xil的最小值,max(xil)表示数据集中xil的最大值,x′il表示标准化后的结果,该方法实现对原始数据的等比例缩放。该方法实现对原始数据的等比例缩放。所述特征量为学号,生源地,家庭成员数,餐均消费额,消费总额,刷卡次数,学生成绩相对排名,图书馆进出次数。所述信息熵自动获取每维特征的属性权值的方法,包括以下步骤:设属性集xi={xi1,xi2,xi1,…,xil}假设xil是第i个对象xi的第l维属性上的取值,wl是第l维属性的权值,且0≤wl≤1,1)首先对数据集中每维属性取均值,低于均值的就视为没有发生,高于均值的视为发生,根据样本发生个数与样本总数的频度比值依次计算属性集xi中各属性的概率值p(xil);2)设u是论域,x1,x2…,xl是论域u的一个划分,其上有概率分布:则称为信息源x的信息熵,其中对数取2为底,而某个pi为零时,则理解为0·log0=0;3)在步骤2)的基础上,计算h(x)并且归一化,从而得到各维属性权值wl,归一化计算方法为:其中,h(xl)表示某对象x在第l维的信息熵;wl为属性的权值。权值欧式距离计算函数采用计算方法为:式中,xil,xjl分别是对象i和j在第l维属性上的取值,wl是第l维属性的权值,且0≤wl≤1。所述距离矩阵d为:令式中,dk是矩阵d中第k行的和。所述利用map-reduce框架并行计算候选集dsc中每个对象与数据集dsn中每个对象间的权值欧式距离dij,形成距离矩阵d的方法包括以下步骤:map阶段:1)首先通过sqoop将学生数据集导入hdfs;2)读取hdfs中的文件,每一行解析成一个<k,v>,k为行号,v为对象,每一个键值对调用一次map函数,所覆写map函数调用权重距离计算函数;3)对不同分区中的数据进行排序、分组。分组指的是相同key的value放到一个集合中;4)对分组后的数据进行按照value中的学号进行归约;reduce阶段:1)接收的是分组后的数据,然后计算dk,处理后,产生新的<k,v>输出;2)对新的<k,v>按照dk排序,按照dk排序后的前top-n个对象,定义为贫困生,并写入hdfs中。所述top-n的个数动态可调。集群环境下的学生智助系统,包括:属性归一化模块,抽取学生数据特征并归一化;属性权值自动获取模块,运用信息熵获取每维特征的属性权值;并行计算模块,利用map-reduce框架并行化计算每个候选对象的距离,排序后输出前top-n个数据对象,定义为贫困生。本发明与现有技术相比具有以下有益效果:本方法充分利用现有的大数据分析技术,从贫困生的信息挖掘出发,根据贫困生信息特征包括生源地,家庭成员数,餐均消费额,消费总额,刷卡次数,学生成绩相对排名,图书馆进出次数,首先将数据集中贫困生和非贫困生有效分离,运用信息熵获取属性权值,消除了人为主观性因素,在此基础上,并行化计算每个候选对象的距离和,排序,输出前top-n个数据对象,定义为贫困生。从而避免在学生贫困评定中出现的主观性和随机性,具有受人为因素小、伸缩性强和精度高等优点,进而使学校能够更加真实、公平、方便、高效地评判贫困生。本系统重新定义了贫困生,引入dk,dk越大,判定为贫困生的可能性越大;本系统在计算对象之间距离的时候,又引入属性权值,在缺乏先验知识时,运用信息熵自动获取属性权值,消除了人为主观性因素的影响;在计算量较大的距离矩阵d的过程中,采用基于map-reduce计算框架并行处理,极大的提高运算效率;根据学校确定的贫困生名额与非贫困生名额比例,top-n个数动态可调,人为因素影响小、伸缩性强。附图说明下面结合附图对本发明做进一步的说明。图1为本发明方法流程图。图2为基于map-reduce的并行计算模型图。具体实施方式下面结合具体实施例对本发明做进一步的详细说明,但是本发明的保护范围并不限于这些实施例,凡是不背离本发明构思的改变或等同替代均包括在本发明的保护范围之内。实施例图1所示为本发明方法流程图,在本实施例中,如图1所述,本发明集群环境下的学生智助方法,包括以下步骤:1.以学校为单位,按照学生自愿申请原则,将学生数据集分为贫困生候选集dsc和非贫困生数据集dsn;2.利用学校确定的贫困生名额与非贫困生名额比例,计算top-n的值;3.数据特征量的提取,根据数据库包含的字段名称,抽取数据特征量及特征个数,数据特征量包括但不限于:学号,生源地,家庭成员数,餐均消费额,消费总额,刷卡次数,学生成绩相对排名,图书馆进出次数;提取待分析学生行为数据的维度特征,并将每维特征归一化,所述特征归一化的计算公式为:式中,xil表示第i个对象xi在第l维属性上的取值,min(xil)表示数据集中xil的最小值,max(xil)表示数据集中xil的最大值,x′il表示标准化后的结果,该方法实现对原始数据的等比例缩放。4.在缺乏先验知识时,采用信息熵自动获取每维特征的属性权值wl;包括以下步骤:设属性集xi={xi1,xi2,xi1,…,xil}假设xil是第i个对象xi的第l维属性上的取值,wl是第l维属性的权值,且0≤wl≤1,1)首先对数据集中每维属性取均值,低于均值的就视为没有发生,高于均值的视为发生,根据样本发生个数与样本总数的频度比值依次计算属性集xi中各属性的概率值p(xil);2)设u是论域,x1,x2…,xl是论域u的一个划分,其上有概率分布:则称为信息源x的信息熵,其中对数取2为底,而某个pi为零时,则理解为0·log0=0;3)在步骤2)的基础上,计算h(x)并且归一化,从而得到各维属性权值wl,归一化计算方法为:其中,h(xl)表示某对象x在第l维的信息熵;wl为属性的权值。5.集群环境下,引入属性权值wl,针对候选集dsc中的每个对象,利用map-reduce框架并行计算候选集dsc中每个对象与数据集dsn中每个对象间权值欧式距离dij,形成距离矩阵d;采用基于map-reduce计算框架并行处理,极大的提高了运算效率。所述权值欧式距离计算函数采用计算方法为:式中,xil,xjl分别是对象i和j在第l维属性上的取值,wl是第l维属性的权值,且0≤wl≤1。所述距离矩阵d为:令式中,dk是矩阵d中第k行的和,dk越大说明对象i与dsn数据集中其他对象距离越远,贫困程度越高。如图2所示,为基于map-reduce的并行计算模型图,所述利用map-reduce框架并行计算候选集dsc中每个对象与数据集dsn中每个对象间的权值欧式距离dij,形成距离矩阵d的方法包括以下步骤:map阶段:1)首先通过sqoop将学生数据集导入hdfs;2)读取hdfs中的文件,每一行解析成一个<k,v>,k为行号,v为对象,每一个键值对调用一次map函数,所覆写map函数调用权重距离计算函数;3)对不同分区中的数据进行排序、分组,分组指的是相同key的value放到一个集合中;4)对分组后的数据进行按照value中的学号进行归约;reduce阶段:1)接收的是分组后的数据,然后计算dk,处理后,产生新的<k,v>输出;2)对新的<k,v>按照dk排序,按照dk排序后的前top-n个对象,定义为贫困生,并写入hdfs中。6.通过对距离矩阵进行计算分析排序,得出前top-n名学生数据,定义为贫困生。集群环境下的学生智助系统,包括:属性归一化模块,抽取学生数据特征并归一化;属性权值自动获取模块,运用信息熵获取属性权值;并行计算模块,利用map-reduce框架并行化计算每个候选对象的距离,排序后输出前top-n个数据对象,定义为贫困生。本发明从贫困生的信息挖掘出发,根据贫困生信息特征(生源地,家庭成员数,餐均消费额,消费总额,刷卡次数,学生成绩相对排名,图书馆进出次数),首先将数据集中贫困生和非贫困生有效分离,运用信息熵获取属性权值,消除了人为主观性因素,在此基础上,并行化计算每个候选对象的距离和,排序后输出前top-n个数据对象,定义为贫困生。从而避免在学生贫困评定中出现的主观性和随机性,具有受人为因素小、伸缩性强和精度高等优点,进而使学校能够更加科学、公平、方便、高效地评判贫困生。应用示例:假设学校拥有学生31000人,1000人提出申请,学校今年的政策名额为0.25%,则{dsn数据集}=30000,{dsc数据集}=1000,top-n=78,矩阵d的大小为:1000*30000,dsn数据集的情况如表1所示,dsc数据集的情况如表2所示。表1dsn数据集表2dsc数据集按照说明书中属性权值自动获取的方法,计算得到表3数据,通过和数据集对比分析,数据集在test-1维度上偏离很小,可视作没有发生偏离,而仅仅是在其他维属性有偏离,这表明表3中计算所得的权值数据符合客观实际,能准确体现出属性的重要程度,在计算对象之间的距离的时候,较小的权值可减弱这两维属性对分析目标的影响,具有合理性,因此在指导挖掘时更为精确。表3属性权值自动获取方法xp(x)h(x)归一化h(x)w餐均消费额0.580.4560.2510.25月消费总额0.50.50.2750.28刷卡次数0.580.4560.2510.25成绩相对排名0.080.2920.1600.16…test-10.920.1110.0610.06更进一步,设n={dsn},m={dsc},l={属性维度},则总的时间复杂度为o(m×n×l)通常此计算规模很大,单机很难一次性处理全部数据,为此,本方法采用集群并行处理,集群环境为:3个计算节点,每个计算节点为双路intele58核处理器,64gb内存,150g固态硬盘,480g固态硬盘*2,4tsata7200rpm企业盘*2,1+1冗余电源。软件平台选用hadoop2.x,通过map-reduce计算模型,输出top-n个学生,定义为贫困生。本发明不会限制于本文所示的实施例,而是要符合与本文所公开的原理和新颖性特点相一致的最宽范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1