一种尿检试纸生理指标自动识别方法与流程
本发明涉及图像处理技术领域,特别涉及一种尿检试纸生理指标自动识别方法。
背景技术:
尿常规是医学检验“三大常规”项目之一,尿常规指标是反映身体健康状况的基本指标之一。尿常规检查内容通常包括尿的颜色、透明度、酸碱度、红细胞、白细胞、蛋白质、比重及尿糖定性等。其中检测指标中蛋白质含量偏高往往和慢性肾炎相关;尿比重偏低往往和慢性肾炎、尿崩症相关;尿糖阳性往往与肾性糖尿、糖尿病及甲状腺功能亢进等相关。不少的慢性肾病、糖尿病早期患者都可以通过尿常规检测筛查出来。目前在医院,大多数尿常规检测都通过尿液分析仪进行。尿液分析仪一般都配有专用的尿检试纸,试纸带上等距分布着若干个测试项目,每个测试项目上都含有专门的化学试剂,与尿液接触后会发生颜色反应,尿液分析仪可以通过分析颜色变化程度来量化相关的生理指标。
尿常规检查对于早期慢性肾病、糖尿病筛查等慢性疾病具有重要的作用。然而虽然尿液分析仪可以精确的测量尿液的各项生理指标,但是大多数尿液分析仪对于个人来说过于昂贵,频繁到医疗机构排队检查既浪费大量的时间,又增加了较高的经济负担,而传统的人眼对比识别的方法容易受到主观因素的影响,识别准确率较低。因此,提出了一种尿检试纸生理指标自动识别方法,使得用户可以通过手机扫描试纸就可得到较为精确的测量结果,具有成本低廉,操作简单,识别准确率高的优点,可以很好满足早期慢性肾脏病、糖尿病等患者的初步筛查以及定期随访需求。
技术实现要素:
本发明一种尿检试纸生理指标自动识别方法是通过图像分割、图像识别技术,自动的解析试纸上各个测试项的生理指标,优点在于可以排除光照干扰,避免人眼比色准确率较低的问题。
为了实现上述目的,本发明采用的技术方案如下:
一种尿检试纸生理指标自动识别方法,包括如下步骤:
步骤(1)获取用户上传的尿检试纸图像,包括测试后试纸样本以及背景卡,尿检试纸图像上包含各个待测试项,对尿检试纸图像进行图像增强处理,所述的图像增强处理依次包括灰度处理、滤波处理、颜色平滑处理;
步骤(2)对获取的尿检试纸进行图像增强处理;
步骤(3)对增强后的图片做自适应阈值分割,得到各个待测试项:指尿检试纸上每个色块位置;
步骤(4)不同手机摄像头参数不同,图片采集的环境也不同,拍出的照片存在一定色差,需要对原图像做色差纠正;
步骤(5)对于每一个测试项训练一个bp神经网络,将步骤4经色差纠正后的色块输入到对应的bp神经网络中,得到色块对应的类别;
步骤(6)根据色块对应的类别比对标准比色卡得到对应的生理指标。
所述步骤(2)的具体流程如下:
步骤(2.0)将上传的图片转化为灰度图片,具体转化公式如下:
gray=0.299*r+0.587*g+0.114*b
其中,r代表红色,g代表绿色,b代表蓝色,
步骤(2.1)对灰度图进行均值滤波,并用gamma变换对图像进行对比度增强,其中均值滤波卷积核大小为5*5,gamma变换参数为1.25;
步骤(2.2)对转换后的图片基于meanshift算法做图像颜色平滑处理。
所述步骤(3)具体算法流程如下:
步骤(3.0)对经步骤(1)处理后的尿检试纸图像进行二值化处理;
步骤(3.1)对二值化后的尿检试纸图像做膨胀处理,减少孤立点和噪点;
步骤(3.2)对膨胀处理后的图像做扫描,标记出图片中所有的连通域,具体算法为:
步骤(3.2.0)逐行扫描图像,将每行中连续的白色像素(白色像素是指rgb值为(255,255,255)的像素点)组成的序列称为团,并记下团的起点,终点和行号;
步骤(3.2.1)在逐行扫描中,对于除第一行外的所有行里的某一个团r,如果团r与上一行中的所有团都没有重合区域,则给团r一个新的标号;如果团r仅与上一行中一个团有重合区域,则将上一行中与团r有重合区域的团的标号赋给团r;如果团r与上一行中的2个及以上的团有重合区域,则记r表示上一行中与该团有重合区域的所有团集合,将r中团的最小标号赋给团r,并将r中任意两个团之间的标号对都加入到等价对集合c中,表示因为团r的连接作用现在r中的任意两个团之间都是等价的r;
步骤(3.2.2)将集合c中等价对转换为等价序列,例如{(1,2),(2,3),(4,5),(5,7),(6,7)}转换为{(1,2,3),(4,5,6,7)},对于在等价序列中的所有团赋予相同的的新标号;
步骤(3.2.3)将每个团的标号填入标记图像中,有相同标号的团就组成一个连通域。
步骤(3.3)对上一步骤找到的连通域,计算其最小外围矩阵,过滤掉最小外围矩阵面积不在[450,1000]之间或者外围矩阵长宽比不在[1/1.2,1.2]之间或者连通域非凸的所有连通域,剩下的连通域即为待测试项所在的色块。
所述步骤(3.0)包括以下步骤:
对经步骤1处理后的尿检试纸图像的每个像素点p(i,j),其中i,j分别表示该点距图像左上角位置的横向和纵向距离,记wij表示点p(i,j)处的灰度值,计算以像素点p(i,j)为中心,blocksize范围内其它点灰度值的高斯加权平均
所述步骤(4)采用的是基于bp神经网络2的色差纠正技术,具体步骤如下:
步骤(4.0)色差纠正网络数据预处理:在用户上传的数据中包含背景卡,背景卡上有标准比色卡,这些标准比色卡上每个色块的rgb数值是已知的,因此网络的输入为待纠正的标准比色卡每个色块的rgb,真实值为已知的对应的实际数值,由于bp神经网络具有很强的拟合能力,可以直接在rgb色彩空间做色差纠正,无需转换到lab或者hsv空间;
步骤(4.1)初始化bp神经网络,采用的网络结构包含输入层、隐藏层、输出层。输入层有3个神经元,分别对应于待纠正数据的r,g,b值;
隐藏层包含50个神经元,采用relu激活函数,公式为f(x)=max(x,0)。输出层有3个神经元,分别对应预测的r,g,b值;输出层与隐藏层激活函数为sigmoid,公式为
步骤(4.2)迭代优化参数,通过随机梯度下降算法对网络参数进行优化;具体流程为:
步骤步骤(4.2.0)首先定义优化目标函数,
示正则化项的权重;
步骤(4.2.1)从数据集中抽取若干条数据作为一个批次总计m个样本,按照如下公式更新:
步骤(4.2.2)重复步骤(4.2.1)过程直至网络收敛或者达到最大的迭代次数;
步骤(4.3)网络训练完成后即可用于色差纠正,输入待纠正的rgb值,输出为纠正后的rgb值。
所述步骤(5)包括如下步骤:
步骤(5.0)分类网络数据预处理:将每个测试项色块像素值统一缩放成16*16,每个像素灰度值归一化到(0,1)区间,并对数据做pca降维到100维向量;
步骤(5.1)初始化bp神经网络,采用的网络结构包含输入层、隐藏层、输出层、softmax层;输入层有100个神经元,对于与输入色块降维后的灰度值;隐藏层包含200个神经元,采用relu激活函数,公式为f(x)=max(x,0)。输出层单元数目与该测试项有多少个类别对应,输出层与隐藏层激活函数为relu;输出层后接softmax层,对输出的数值归一化,表示对应类别的概率,归一化公式为
步骤(5.2)迭代优化参数,通过随机梯度下降算法对网络参数进行优化;具体流程为:
步骤(5.2.0)首先定义优化目标函数为带二次正则项的交叉熵
步骤(5.2.1)从数据集中抽取若干条数据作为一个批次总计m个样本,按照如下公式更新:
步骤(5.2.2)重复5.2.1过程直至网络收敛或者达到最大的迭代次数。
步骤(5.3)网络训练完成后即可用于类别预测,输入图像,输出为对应的类别。
本发明的有益效果是:
本发明属于图像处理技术领域,具体为一种尿检试纸生理指标自动识别方法。其核心是通过一系列图像增强、图像分割与识别算法自动量化尿检试纸测试项的指标。用户使用试纸尿检后,通过手机端拍照采集试纸图像,上传到云端;云端集成了图像处理方法,经过处理后将结果返回到手机。云端图像处理算法首先对用户上传的图像做增强处理;然后对图像做分割找到各个测试项所在的色块;随后对图像做基于bp(backpropagation)神经网络的色差纠正;最后对色差纠正后的图像色块做基于bp神经网络的分类,得到对应的离散化的生理指标。
该识别方法简单精确,避免了光照干扰以及人眼比色准确率低的问题,可用于慢性肾病患者、糖尿病患者、高血压患者等慢性疾病的早期诊断和随访以及健康人群的早期筛查。
附图说明
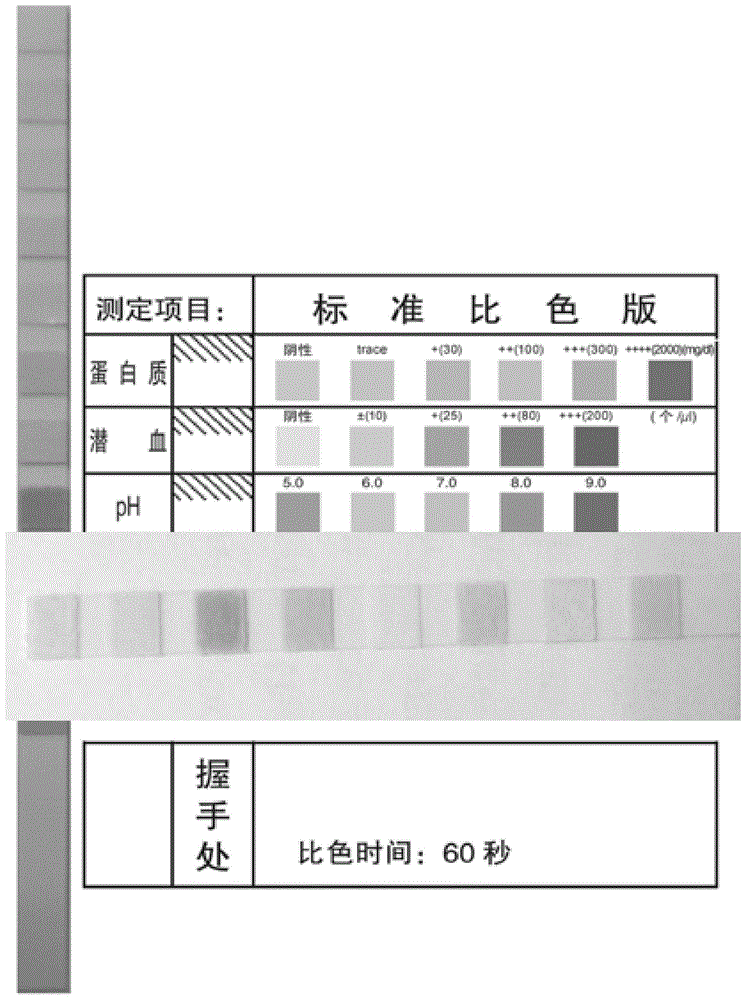
图1是本发明的尿检试纸与背景卡比对的示意图,待测定项目包括:蛋白质、潜血和ph值。
图2是本发明的实施例的用户上传的尿检试纸图片。
图3是图2的用户上传的尿检试纸图片经过图像处理之后的示意图。
图4是对图3的图像经过处理和删选之后得道的试纸测试项所在色块的示意图。
图5是将图像输入到色差纠正网络得到颜色纠正后的图像。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应对理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
如图1至至图5,一种尿检试纸生理指标自动识别方法,包括如下步骤:
步骤(1)获取用户上传的尿检试纸图像,包括测试后试纸样本以及背景卡,尿检试纸图像上包含各个待测试项,对尿检试纸图像进行图像增强处理,所述的图像增强处理依次包括灰度处理、滤波处理、颜色平滑处理;
步骤(2)对获取的尿检试纸进行图像增强处理;
步骤(3)对增强后的图片做自适应阈值分割,得到各个待测试项:指尿检试纸上每个色块位置;
步骤(4)不同手机摄像头参数不同,图片采集的环境也不同,拍出的照片存在一定色差,需要对原图像做色差纠正;
步骤(5)对于每一个测试项训练一个bp神经网络,将步骤4经色差纠正后的色块输入到对应的bp神经网络中,得到色块对应的类别;
步骤(6)根据色块对应的类别比对标准比色卡得到对应的生理指标。
所述步骤(2)的具体流程如下:
步骤(2.0)将上传的图片转化为灰度图片,具体转化公式如下:
gray=0.299*r+0.587*g+0.114*b
其中,r代表红色,g代表绿色,b代表蓝色,
步骤(2.1)对灰度图进行均值滤波,并用gamma变换对图像进行对比度增强,其中均值滤波卷积核大小为5*5,gamma变换参数为1.25;
步骤(2.2)对转换后的图片基于meanshift算法做图像颜色平滑处理。
所述步骤(3)具体算法流程如下:
步骤(3.0)对经步骤(1)处理后的尿检试纸图像进行二值化处理;
步骤(3.1)对二值化后的尿检试纸图像做膨胀处理,减少孤立点和噪点;
步骤(3.2)对膨胀处理后的图像做扫描,标记出图片中所有的连通域,具体算法为:
步骤(3.2.0)逐行扫描图像,将每行中连续的白色像素(白色像素是指rgb值为(255,255,255)的像素点)组成的序列称为团,并记下团的起点,终点和行号;
步骤(3.2.1)在逐行扫描中,对于除第一行外的所有行里的某一个团r,如果团r与上一行中的所有团都没有重合区域,则给团r一个新的标号;如果团r仅与上一行中一个团有重合区域,则将上一行中与团r有重合区域的团的标号赋给团r;如果团r与上一行中的2个及以上的团有重合区域,则记r表示上一行中与该团有重合区域的所有团集合,将r中团的最小标号赋给团r,并将r中任意两个团之间的标号对都加入到等价对集合c中,表示因为团r的连接作用现在r中的任意两个团之间都是等价的r;
步骤(3.2.2)将集合c中等价对转换为等价序列,例如{(1,2),(2,3),(4,5),(5,7),(6,7)}转换为{(1,2,3),(4,5,6,7)},对于在等价序列中的所有团赋予相同的的新标号;
步骤(3.2.3)将每个团的标号填入标记图像中,有相同标号的团就组成一个连通域。
步骤(3.3)对上一步骤找到的连通域,计算其最小外围矩阵,过滤掉最小外围矩阵面积不在[450,1000]之间或者外围矩阵长宽比不在[1/1.2,1.2]之间或者连通域非凸的所有连通域,剩下的连通域即为待测试项所在的色块。
所述步骤(3.0)包括以下步骤:
对经步骤1处理后的尿检试纸图像的每个像素点p(i,j),其中i,j分别表示该点距图像左上角位置的横向和纵向距离,记wij表示点p(i,j)处的灰度值,计算以像素点p(i,j)为中心,blocksize范围内其它点灰度值的高斯加权平均
所述步骤(4)采用的是基于bp神经网络3的色差纠正技术,具体步骤如下:
步骤(4.0)色差纠正网络数据预处理:在用户上传的数据中包含背景卡,背景卡上有标准比色卡,这些标准比色卡上每个色块的rgb数值是已知的,因此网络的输入为待纠正的标准比色卡每个色块的rgb,真实值为已知的对应的实际数值,由于bp神经网络具有很强的拟合能力,可以直接在rgb色彩空间做色差纠正,无需转换到lab或者hsv空间;
步骤(4.1)初始化bp神经网络,采用的网络结构包含输入层、隐藏层、输出层。输入层有3个神经元,分别对应于待纠正数据的r,g,b值;
隐藏层包含50个神经元,采用relu激活函数,公式为f(x)=max(x,0)。输出层有3个神经元,分别对应预测的r,g,b值;输出层与隐藏层激活函数为sigmoid,公式为
步骤(4.2)迭代优化参数,通过随机梯度下降算法对网络参数进行优化;具体流程为:
步骤步骤(4.2.0)首先定义优化目标函数,
示正则化项的权重;
步骤(4.2.1)从数据集中抽取若干条数据作为一个批次总计m个样本,按照如下公式更新:
步骤(4.2.2)重复步骤(4.2.1)过程直至网络收敛或者达到最大的迭代次数;
步骤(4.3)网络训练完成后即可用于色差纠正,输入待纠正的rgb值,输出为纠正后的rgb值。
所述步骤(5)包括如下步骤:
步骤(5.0)分类网络数据预处理:将每个测试项色块像素值统一缩放成16*16,每个像素灰度值归一化到(0,1)区间,并对数据做pca降维到100维向量;
步骤(5.1)初始化bp神经网络,采用的网络结构包含输入层、隐藏层、输出层、softmax层;输入层有100个神经元,对于与输入色块降维后的灰度值;隐藏层包含200个神经元,采用relu激活函数,公式为f(x)=max(x,0)。输出层单元数目与该测试项有多少个类别对应,输出层与隐藏层激活函数为relu;输出层后接softmax层,对输出的数值归一化,表示对应类别的概率,归一化公式为
步骤(5.2)迭代优化参数,通过随机梯度下降算法对网络参数进行优化;具体流程为:
步骤(5.2.0)首先定义优化目标函数为带二次正则项的交叉熵
步骤(5.2.1)从数据集中抽取若干条数据作为一个批次总计m个样本,按照如下公式更新:
步骤(5.2.2)重复5.2.1过程直至网络收敛或者达到最大的迭代次数。
步骤(5.3)网络训练完成后即可用于类别预测,输入图像,输出为对应的类别。
meanshift算法为现有技术,具体参见comaniciud,meerp.meanshift:arobustapproachtowardfeaturespaceanalysis[j].ieeetransactionsonpatternanalysisandmachineintelligence,2002,24(5):603-619.
基于bp神经网络为现有技术,具体参见rumelhart,davide.,geoffreye.hinton,andronaldj.williams."learningrepresentationsbyback-propagatingerrors."nature323.6088(1986):533.
下面以一份尿检试纸展示该方法的具体实施方式:
(1)图2为用户上传的尿检试纸图片。
(2)对获取的图片增强处理,对图片进行均值滤波和gamma变换;用meanshift算法进行图像的平滑处理,得道如图3所示图像,可以看出处理后的图片去掉了各个色块之间以及测试试纸边缘的干扰,有助于之后的二值化和连通域分析。
(3)对平滑处理后的图片进行自适应阈值分割,首先是对图像进行局部自适应阈值分析,得到二值化后的图像;随后对二值化的图像做连通域分析和形态学膨胀处理;最后是通过面积,长宽比以及凸性筛选出符合条件的连通域,即为试纸测试项所在色块,如图4。
(4)将图像输入到色差纠正网络得到颜色纠正后的图像,如图5。
(5)将色差纠正后的图像的每个色块裁剪为16*16,经pca降维到100维向量后输入到bp神经网络分类器,得到每个类别的概率。每个色块经算法预测后会得到一个类别概率,选择概率最高的类别作为分类结果。例如:图4中潜血这一项预测的结果为第一类概率为75.2%,第二类概率为10.3%,第三类概率为8.4%,第四类概率为4.1%,第五类概率为2.0%,则最终潜血这一项的结果为第一类,其他测试项同理可得。
(6)根据类别得到对应的生理指标,图4中潜血预测结果为第一类,对应的生理指标为阴性,其他测试项同理可得。
以上显示和描述了本发明专利的基本原理、主要特征和本发明专利的优点。本行业的技术人员应该了解,本发明专利不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明专利的优选例,并不用来限制本发明专利,在不脱离本发明专利精神和范围的前提下,本发明专利还会有各种变化和改进,这些变化和改进都落入要求保护的本发明专利范围内。本发明专利要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!