混合时空平面局部二值模式的自发微表情定位方法与流程
本发明属于计算机视频与图像处理技术领域,涉及一种混合时空平面局部二值模式的自发微表情定位方法。
背景技术:
国家安全、精神医疗等与人们的日常生活息息相关。随着科学技术的发展,人们发现自发微表情的特殊性质有助于确认身份、检测谎言、认知状态等。自发微表情相较于普通表情的最大区别是其发生时不受人控制,因此其能表示人的真实情感。而自发微表情由于机制抑制的特点,发生时面部肌肉运动模块可能只包含部分的普通表情全部肌肉模块,因此其幅度弱、不同类别易混淆,导致很多时候肉眼无法观察到自发微表情的发生。正因为自发微表情发生幅度小、持续时间短,现有的视频中自发微表情定位的研究方法具有很大的提升空间。
在当前的机器学习方法中,视频中自发微表情定位方法多基于连续帧的自发微表情,根据其变化幅度提取相应特征并进行判别,从而找到自发微表情帧序。为达到这一目的,许多高效的定位算法被提出,例如光流法、局部二值模式(localbinarypattern,lbp)等等,这些算法都在视频中定位自发微表情时取得一定的效果。同时,基于神经网络的自发微表情定位方法也能提取其特征并定位。
在上述提到的算法中,许多算法对于视频中连续帧的数据冗余处理与时空特征表示的应用不完全,以至于提取的特征不完备,导致最终的定位精确率较低。本发明旨在克服特征点的计算冗余与时空特征的完备性不足等两个方面问题,提出了具有更高精确率的视频中自发微表情的定位方法。
技术实现要素:
本发明的目的主要是针对当前视频中自发微表情的特征计算冗余、时空特征利用不完备、定位精确率较低等不足,提出了具有高精确率的视频中自发微表情定位方法。
本发明根据自发微表情视频中连续帧的相关性,通过精细匹配实现了像素级人脸区域对齐,从而对头部偏移等干扰具有较强的抗干扰能力。同时在空间轴平面提取扇形区域特征,并在时间轴提取去冗余的线性特征,既减少了特征点冗余计算,又通过非线性特征融合的方式结合时空特征,形成更完备的特征表示,因此能更加鲁棒地表示自发微表情,提高了自发微表情视频中自发微表情定位精确率。
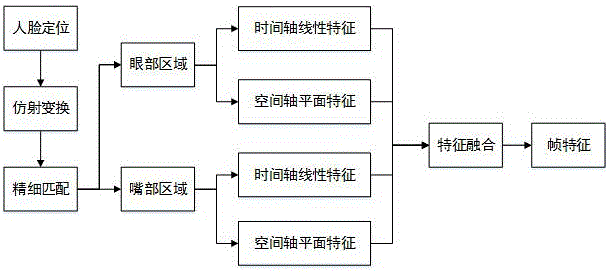
本发明的视频中自发微表情定位方法包含视频中人脸对齐、人脸眼部区域与嘴部区域的时空特征提取、特征融合与视频中自发微表情帧判定。
1)人脸对齐,包括粗匹配对齐与精细匹配对齐。
本发明的人脸对齐的步骤如下所示:
步骤s1:用asm算法对自发微表情视频每帧提取多个脸部标记点,其中内眼角点和鼻尖点,是正面视角中相对稳定的三个点,被用于脸部区域仿射变换,实现脸部区域的粗匹配对齐。
步骤s2:在完成粗匹配对齐的图片基础上,用精细匹配算法最大化相邻帧之间的相似度,将脸部区域分为眼部区域和嘴部区域分别进行精细匹配对齐。
具体地,步骤s2的分解步骤如下:
输入:标准模板图片n,待匹配图片u_p,精确匹配图片n_p;
步骤1:获取标准模板图片n的大小,图片n的长度、宽度分别用n_x、n_y表示。
步骤2:如果x,y值都不为空,执行步骤3;否则,初始化值,令x=1、y=1,执行步骤3。x表示待匹配图片左上角起始点的横坐标,y表示待匹配图片左上角起始点的纵坐标,x与y构成表示点位置的一对坐标。
步骤3:n_value=ncc(n,u_p(x:x+n_x,y:y+n_y)),n_value表示标准模板图片与待匹配图片的相似度数值,u_p(x:x+n_x,y:y+n_y))表示选取x,y作为待匹配图片的起始坐标基准点,n_x、n_y分别为选取图片的长度和宽度。
步骤4:选取以(x,y)为圆心,1为半径的邻域点(x{1...8},y{1...8})。x{1...8}表示依次取圆心周围的8个邻域点的横坐标,y{1...8}表示依次取圆心周围的8个邻域点的纵坐标,从而依次构成其中某个邻域点的一组坐标。
步骤5:value{1...8}=ncc(n,u_p(x{1...8}:x{1...8}+n_x,y{1...8}:y{1...8}+n_y)),value{1...8}表示标准模板图片与以新坐标为基准选取的待匹配图片进行相似度计算,依次得到8个相似度数值。
步骤6:value_max=max(n_value,value{1...8}),value_max表示取上述计算得到的所有相似度数值的最大值。
步骤7:如果n_value==value_max,则n_p=u_p(x:x+n_x,y:y+n_y);否则,令x=x_value_max、y=y_value_max,执行步骤4。x_value_max表示最大相似度值所对应待匹配图片左上角起始点的横坐标,y_value_max表示最大相似度值所对应待匹配图片左上角起始点的纵坐标。
输出:精确匹配图片n_p。
具体地,ncc的计算公式如式(1)所示。
其中λ∈[λ1,λ2],为标准模板可以选择应用于匹配模板的区间值。滑动匹配窗口的位置被定位于区间[σ,σ+w-1]内,σ为匹配起始位置,w为窗口的大小。f(n)、
具体地,max为取最大值。
具体地,=为赋值运算符。
具体地,==为相等运算符。
具体地,:为区间表示。
具体地,{1..8}表示以1为半径的周围8邻域点。
具体地,以新坐标为基准选取的待匹配图片指以邻域点坐标为坐标基准点,选取待匹配图片。
2)人脸眼部区域与嘴部区域的时空特征提取,即从眼部区域与嘴部区域,分别提取空间轴扇形平面特征与去冗余时间轴线性特征。
本发明的时空特征提取的步骤如下所示:
s3:使用lbp方法分别提取眼部区域与嘴部区域的空间轴扇形平面特征。
s4:使用lbp方法分别提取眼部区域与嘴部区域的更紧凑、更有效的去冗余时间轴线性特征。
具体地,空间轴扇形平面采样点的提取方式如式(2)所示。
其中,在以c为中心点、半径为r的圆上,当其采样点为gn,n∈[0,ps]时,以gn为中心、向圆的两周展开r/2的弧长构成一段圆弧。ps为空间轴平面采样点的个数,
具体地,去冗余时间轴线性采样点的提取方式如式(3)所示。
其中,pt为时间轴线性采样点的个数。ln表示在每条直线上半径r的范围中提取到的特征点。m(ln,r)表示直线包含所有采样点的均值。gc表示中心点c的像素值。
具体地,将采样点转化为特征向量的方式为:分别统计lbps与lbpt中相同数值的个数,并将其分别排列组成向量,即为该次采样的lbp特征向量hs、ht。
3)特征融合为采用非线性的特征融合方式,将空间轴平面和时间轴线性提取得到的特征向量融合为更完备的特征向量表示。
具体地,融合成列向量的计算公式如式(4)所示。
具体地,式(4)中[]表示特征向量的列排列。
hs、ht分别为空间轴扇形平面、时间轴线性上的特征向量,ps、pt分别为其采样点的个数。
4)视频中自发微表情帧判定为通过相关性的计算与阈值的设定,定位出自发微表情视频中自发微表情帧所在序位,本发明选取帧特征大于阈值的帧作为自发微表情帧。
具体地,相关性的计算如式(5)、式(6)所示。
χ2表示不同特征向量之间的关联程度,用于度量特征向量之间的“距离”,
其中,cj表示第j帧的帧特征,
具体地,阈值的设定如式(7)所示。
t=cmean+p×(cmax-cmean)(7)
其中,t表示阈值,p∈[0,1],根据自发微表情帧定位正确率决定其取值。cmean、cmax分别表示当前视频中帧特征的均值和最大值。
本发明的有益效果:
本发明为降低定位点偏移对人脸匹配效果产生的干扰,提出精细匹配算法最大化相邻帧之间的相似度,从而实现脸部区域像素级精度的对齐。同时将脸部区域分为眼部区域和嘴部区域,因为该区域表情表达最为凸显。
本发明提出混合时空平面lbp算法分别对视频中眼部区域与嘴部区域提取特征。在空间轴平面特征提取时,为尽可能地保留采样点周围的像素信息,采用扇形区域采样;在时间轴特征提取时,为了去除现有方式导致的信息冗余,使用更紧凑、更有效的时间轴线性特征提取方法。
本发明采用非线性的特征融合方式融合不同采样点个数的空间轴与时间轴特征向量,相较于普通的串联合并特征向量方法,本方法更具有鲁棒性。
本发明为了消除背景噪声的影响,以及增加相邻帧之间的对比强度,将特征向量转化为不同的帧特征。比较帧特征可以更加清楚地区分自发微表情帧与非表情普通帧。
附图说明
图1表示本发明的流程图。
图2表示仿射变换后人脸对齐结果与未经对齐结果的比较。
图3表示空间轴采样示例图。
图4表示时间轴采样示例图。
图5表示本发明中精细匹配的阈值判定示例图。
图6表示ulbp算法中精细匹配的阈值判定示例图。
图7表示本发明中粗匹配的阈值判定示例图。
图8表示ulbp算法中粗匹配的阈值判定示例图。
具体实施方式
下面将结合附图对本发明加以详细说明,应指出的是,所描述实施例仅旨在便于对本发明的理解,而对其不起任何限定作用。
下面将参考附图详细介绍本发明的实施例。
图1是本发明视频中自发微表情定位方法的流程图,展示了从自发微表情视频输入到最终定位结果输出的整个流程。
本实施例选用cas(me)2自发微表情数据库中完整的自发微表情视频作为测试数据库。
1)图1中的人脸定位为使用asm算法对自发微表情视频每帧提取68个脸部标记点,其中内眼角点和鼻尖点,是正面视角中相对稳定的三个点,具有良好的定位能力。
2)图1中的仿射变换为实现脸部区域对齐的变换方式,目的是实现脸部区域的粗匹配对齐。如图2所示,其表示未经变换(如图2(a))与经过仿射变换(如图2(b))的自发微表情视频帧中的人脸区域比较。
3)图1中的精细匹配是为消除粗匹配对齐后的人脸图片像素级偏移的方法,同时为了减少计算量,将脸部区域分为眼部区域和嘴部区域分别进行精细匹配对齐,具体实施方式如下所示。
输入:标准模板图片n,待匹配图片u_p,精确匹配图片n_p。
步骤1:获取标准模板图片n的大小,图片n的长度、宽度分别用n_x、n_y表示。
步骤2:如果x,y值都不为空,执行步骤3;否则,初始化值,令x=1、y=1,执行步骤3。x表示待匹配图片左上角起始点的横坐标,y表示待匹配图片左上角起始点的纵坐标,x与y构成表示点位置的一对坐标。
步骤3:n_value=ncc(n,u_p(x:x+n_x,y:y+n_y)),n_value表示标准模板图片与待匹配图片的相似度数值,u_p(x:x+n_x,y:y+n_y))表示选取x,y作为待匹配图片的起始坐标基准点,n_x、n_y分别为选取图片的长度和宽度。
步骤4:选取以(x,y)为圆心,1为半径的邻域点(x{1...8},y{1...8})。x{1...8}表示依次取圆心周围的8个邻域点的横坐标,y{1...8}表示依次取圆心周围的8个邻域点的纵坐标,从而依次构成其中某个邻域点的一组坐标。
步骤5:value{1...8}=ncc(n,u_p(x{1...8}:x{1...8}+n_x,y{1...8}:y{1...8}+n_y)),value{1...8}表示标准模板图片与以新坐标为基准选取的待匹配图片进行相似度计算,依次得到8个相似度数值。
步骤6:value_max=max(n_value,value{1...8}),value_max表示取上述计算得到的所有相似度数值的最大值。
步骤7:如果n_value==value_max,则n_p=u_p(x:x+n_x,y:y+n_y);否则,令x=x_value_max、y=y_value_max,执行步骤4。x_value_max表示最大相似度值所对应待匹配图片左上角起始点的横坐标,y_value_max表示最大相似度值所对应待匹配图片左上角起始点的纵坐标。
输出:精确匹配图片n_p。
需要说明的是,标准模板图片为每个自发微表情视频中的第一帧图片,以其为标准参照物。待匹配图片为视频中除第一帧之外的其余所有图片。
具体地,ncc的计算公式如式(1)所示。
其中λ∈[λ1,λ2],为标准模板可以选择应用于匹配模板的区间值。滑动匹配窗口的位置被定位于区间[σ,σ+w-1]内,σ为匹配起始位置,w为窗口的大小。f(n)、
需要说明的是,将脸部区域分为眼部区域和嘴部区域,因为该区域表情表达最为凸显,同时也减少相关性匹配的计算时间复杂度。
需要说明的是,精确匹配图片为最终的输出结果,即精细匹配后的图片输出,用于之后的帧特征计算。
4)图1中的眼部区域和嘴部区域为上一步骤中得到的同一自发微表情视频中的不同脸部区域的图片。
5)图1中的空间轴平面特征为分别以空间轴为基准,提取眼部区域和嘴部区域的特征。特征的提取包括采样点的确定与采样点和特征向量的转换两方面。
空间轴平面的采样点确定如下所示:
其中,在以c为中心点、半径为r的圆上,当其采样点为gn,n∈[0,ps]时,以gn为中心、向圆的两周展开r/2的弧长构成一段圆弧。ps为空间轴平面采样点的个数,
需要说明的是,空间轴平面的采样点确定可参照图3,其中c为采样点的中心,r为采样半径。
据此,得到空间轴平面的采样点lbps。
采样点和特征的转换如下所示:
将采样点转化为特征向量的方式为分别统计lbps中相同数值的个数,并将其分别排列组成列向量,即为该次采样的lbp特征向量hs。
6)图1中的时间轴线性特征为分别以时间轴为基准,提取眼部区域和嘴部区域的特征。特征的提取包括采样点的确定与采样点和特征的转换两方面。
时间轴线性的采样点确定如下所示:
其中,pt为时间轴线性采样点的个数。ln表示在每条直线上半径r的范围中提取到的特征点。m(ln,r)表示直线包含所有采样点的均值。gc表示中心点c的像素值。
需要说明的是,时间轴线性的采样点确定可参照图4,c表示该次采样的中心点,所在的图片为当前的图片。灰色竖线穿过的白色点表示时间轴上未被选取的特征点,为需要纳入该次采样的采样点。
据此,得到时间轴线性的采样点lbpt。
采样点和特征的转换如下所示:
将采样点转化为特征向量的方式为分别统计lbpt中相同数值的个数,并将其分别排列组成列向量,即为该次采样的lbp特征向量ht。
7)图1中的特征融合为将同一区域的空间轴平面特征向量hs和时间轴线性特征向量ht以非线性的方式融合成一个特征向量。
特征融合方式如下所示:
式(4)中[]表示特征向量的列排列。
hs、ht分别为空间轴平面、时间轴线性上的特征向量,ps、pt分别为其采样点的个数。
需要说明的是,采样点ps的个数为图3中除中心点之外的黑点的个数,采样点pt的个数为图4中除中心点之外的黑点和白点的个数总和。
需要说明的是,最终的特征向量由眼部区域和嘴部区域分别融合得到的特征向量合并组成。
8)图1中的帧特征是将最终的特征向量通过相关性的计算与阈值的设定,从而定位出自发微表情视频中自发微表情帧所在序位,设定帧特征大于阈值的帧为自发微表情帧。
相关性的计算如式(5)、式(6)所示。
χ2表示不同特征向量之间的关联程度,用于度量特征向量之间的“距离”,
其中,cj表示第j帧的帧特征,
阈值的设定如式(7)所示。
t=cmean+p×(cmax-cmean)(7)
其中,t表示阈值,p∈[0,1],根据自发微表情帧定位正确率决定其取值。cmean、cmax分别表示当前视频中帧特征的均值和最大值。
需要说明的是,为选取自发微表情所在的顶点帧,利用阈值t对所有得到的帧特征cj进行划分,大于阈值的部分即为检测得到的自发微表情位序。
实施例:
本发明在cas(me)2数据库上进行实验,该自发微表情库被广泛用于自发微表情帧定位和分类。
1)cas(me)2数据库
cas(me)2(chineseacademyofsciencesmacro-expressionandmicro-expression)数据库,为中国科学院关于自发微表情公开的数据库。cas(me)2数据库的视频分辨率为640×480像素,每秒30帧。该数据库a部分包含94个自发微表情视频。该数据库包含126个消极(negative)表情片段、124个积极(positive)表情片段、25个惊讶(surprise)表情片段以及82个其他种类(others)表情片段。为验证本发明对头部偏移具有鲁棒性,随机选取其中80%的视频进行实验。
2)实验1:粗匹配与精细匹配分析对比实验
以图5为例进行分析,该示例图为经过精细匹配处理后的本发明的效果图。自发微表情所在帧除第1002帧之外全部被检测出。根据图5-图8所示,第1002帧未被检测出,主要是因为该帧自发微表情幅度太弱。
另外由图5可见,第174帧、632帧、1038帧虽均被检测出,但这三帧均为视频中被采集对象眨眼睛(眨眼睛是否为表情仍存在争议),使得所在视频帧的帧特征超过阈值,从而导致检测结果偏差。同时,可以发现虽然眨眼睛会产生影响,但是其强度有时是低于自发微表情发生的强度,所以其幅值小于自发微表情幅值。在阈值设置比较大时虽判定帧数较少,但可以在一定程度上去除眨眼睛带来的影响。不幸的是,对于自发微表情而言,眨眼睛所带来的影响是无法通过阈值增大而去除的,所以阈值大小的选择对于检测结果也具有重要的意义。
从图5、图6的对比中观察得到,虽然本发明与均匀局部二值模式(uniformlbp,ulbp)算法都可以检测出大部分的自发微表情帧,但是图5的峰值凸显性明显高于图6(第825帧为干扰帧),表明本发明比ulbp算法对自发微表情更为敏感,在抗干扰能力上具有鲁棒性。同时,从图7、图8的对比中可知,在只有粗匹配的处理条件下,本发明命中自发微表情片段的个数更多,即命中率更高。另外,相对于图5、图6而言,从图7、图8中可以明显地观察到干扰帧的幅值小于自发微表情帧。
3)实验2:几类自发微表情片段检测分析实验
如表1所示,对于消极、惊讶和其他这三类表情,本发明都有一定提高,证明本发明对于自发微表情变化捕捉比ulbp算法更为有效和全面。然而对于积极类表情,本发明与ulbp算法相比命中率无明显提高,是因为积极类表情相比其他表情尤其是消极类表情,眼睛区域和嘴巴区域变化明显,更易于检测。
表1四类自发微表情定位结果对照表
4)实验3:不同算法分析实验
评估公式如式(8)、式(9)所示:
如表2所示,本发明的精确率是最优的。由于实验中为减少眨眼睛等因素带来的影响以及提高精准率,将阈值设得比较高,所以在检测出自发微表情时提取的相关帧数较少,从而导致召回率低。其中,算法mdmd是主方向最大差分(maindirectionalmaximaldifference)的简称。
表2精确率与召回率对照表
- 还没有人留言评论。精彩留言会获得点赞!