基于深度学习模型创建纸质文档结构化数据的方法和终端与流程
本发明涉及一种基于深度学习模型创建纸质文档结构化数据的方法和终端,属于人工智能纸质文档识别数据处理领域。
背景技术:
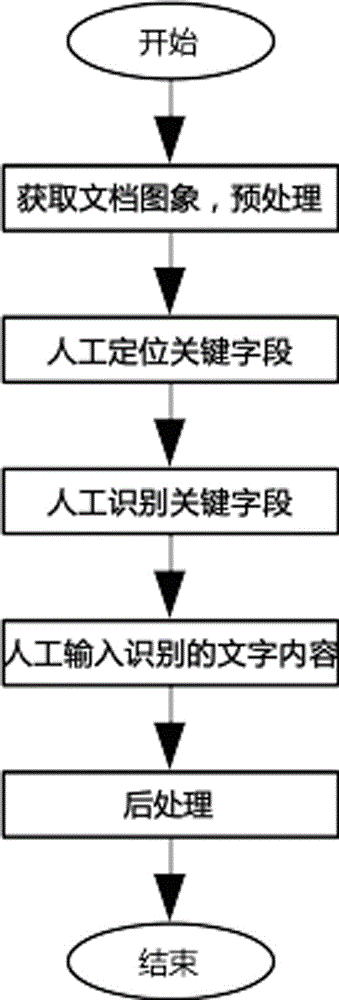
:纸质文档转结构化数据是一种从纸质文档的orc识别结果中的大量文字信息里面提取出关键的字段的信息,比如收据里面的付款方、付款日期和收款方等,并按照一定的结构保存起来的过程。大量的经ocr识别的纸质文档通过文档结构化的处理以后,可以提供高效的文档检索、文档分析以及其它智能化等服务。纸质文档结构化数据处理的关键也是主要的技术难点就是从大量文字中提取出关键字段信息,包括确定所需要的关键字段在文档中所处位置,以及将定位好的的文字识别出来。对于一些具有大业务量和高精确度要求的文档结构化应用,比如发票报销和银行结账等,很多文档结构化系统里面关键的任务都是由人工来完成。一个基于人工的文档结构化系统的工作流程如图1所示,包括人工定位字段、人工识别字段文字、输入识别出来的文字到存档的结构化文档中相应的字段。尽管人工定位字段和人工识别文字有较高的准确度,但是基于人工的文档结构化系统有很多缺陷,比如人工识别速度慢、人工成本昂贵、性能容易受到疲劳等因素影响、需要额外的文字输入时间、文字输入容易带入额外的错误等,不利于建立大规模、高效和经济的文档结构化系统。随着近几年来信息处理技术,尤其是深度学习技术的发展迅猛,文字定位和文字识别的性能得到极大提高,在某些领域文字识别的准确率接近人工识别的水平,帮助实现多种场景应用的落地。深度学习技术在文档结构化系统上也得到一定应用。目前一种采用深度学习技术的文档结构化方案,工作流程如图2所示,包括如下基本步骤:通过对大量文档进行模版分析和统计,确定不同的关键字段在文档中的固定位置;对需要被结构化处理的文档进行预处理,如果不是数字文档,需要预处理扫描存储为数字图像;对关键字段的内容所在位置进行归一化对齐处理;根据不同关键字段对应的固定位置,从待处理的文档中截取出字段对应的图像;利用深度学习ocr技术识别文字;将识别的文字自动存入到结构化文档相应的字段。现有的深度学习技术方案,将字段定位任务简化为从图像中固定位置截取字段对应的图像,利用深度学习ocr技术识别文字,在关键任务上实现了完全自动化,极大提高了计算效率。但是这种文档结构化系统,仅在待截取的字段在所有文档中的位置都固定的情况下有效,限制了该系统的使用范围。实际应用中如果发票打印系统设置不同的关键字段的内容打印位置设置或者关键字段内容长度发生变化,会导致这些关键字段的内容信息发生偏移,超出设置范围,从而引起错误。对于一些票据识别应用,大量的票据通过扫描或者手机拍照等方式存入计算机,很容易引起票据在图像中的位移,而且不同的票据可能有不同的版式,同一字段在图像中的位置不一定相同,这些特点使得上述文档结构化方案对票据识别等业务不太适用。上述文档结构化方案对于易发生位置偏移的应用场景,将纸质文档的orc识别结果转换为结构化文档结的准确度较低。技术实现要素:本发明所要解决的技术问题是:如何提高纸质文档的orc识别结果转换为结构化文档的准确度。为了解决上述技术问题,本发明采用的技术方案为:基于深度学习模型创建纸质文档结构化数据的方法包括:s1、预设文档训练样本集;所述训练样本集中的每一样本包括纸质文档ocr识别结果和与所述纸质文档ocr识别结果对应的标注文档;所述标注文档记录所述文档ocr识别结果中每一关键字段的位置信息和类别信息;s2、使用所述训练样本集训练预设的第一深度学习模型,得到第二深度学习模型;s3、所述第二深度学习模型分析第一纸质文档ocr识别结果,得到所述纸质文档ocr识别结果中每一关键字段的位置信息和类别信息;s4、根据所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息创建与所述第一纸质文档ocr识别结果对应的结构化文档。优选地,所述s4具体为:s41、获取一关键字段的位置信息,得到当前位置信息;s42、截取所述第一纸质文档ocr识别结果中与所述当前位置信息对应的图像信息,得到关键字段图像切片;s43、识别所述关键字段图像切中的字符,得到数据信息;s44、添加所述一关键字段的类别信息和所述文本信息至预设的结构化文档;s45、重复执行s41至s44,直至与所述第一纸质文档ocr识别结果对应的每一关键字段均被遍历。优选地,所述s2具体为:s21、为每一类别信息分配一个唯一的数字编号;s22、所述第一深度学习模型识别所述训练样本集中的一样本,得到信息集合;所述信息集合包括位置信息和类别信息;s23、获取与所述一样本对应的标注文档,得到当前标注文档;s24、比较所述信息集合和所述当前标注文档,计算得到误差值;所述信息集合和所述当前标注文档中的类别信息均使用所述数字编号表示;s25、根据所述误差值调整所述第一深度学习模型的参数;s26、重复执行s22至s25,直至所述误差值小于预设的阈值,得到所述第二深度学习模型。优选地,所述第一深度学习模型用于目标检测。基于深度学习模型创建纸质文档结构化数据的终端,包括一个或多个处理器及存储器,所述存储器存储有程序,并且被配置成由所述一个或多个处理器执行以下步骤:s1、预设训练样本集;所述训练样本集中的每一样本包括纸质文档ocr识别结果和与所述纸质文档ocr识别结果对应的标注文档;所述标注文档记录所述纸质文档ocr识别结果中每一关键字段的位置信息和类别信息;s2、使用所述训练样本集训练预设的第一深度学习模型,得到第二深度学习模型;s3、所述第二深度学习模型分析第一纸质文档ocr识别结果,得到所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息;s4、根据所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息创建与所述第一纸质文档ocr识别结果对应的结构化文档。s1、预设文档训练样本集;所述训练样本集中的每一样本包括纸质文档ocr识别结果和与所述纸质文档ocr识别结果对应的标注文档;所述标注文档记录所述文档ocr识别结果中每一关键字段的位置信息和类别信息;s2、使用所述训练样本集训练预设的第一深度学习模型,得到第二深度学习模型;s3、所述第二深度学习模型分析第一纸质文档ocr识别结果,得到所述纸质文档ocr识别结果中每一关键字段的位置信息和类别信息;s4、根据所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息创建与所述第一纸质文档ocr识别结果对应的结构化文档。优选地,所述s4具体为:s41、获取一关键字段的位置信息,得到当前位置信息;s42、截取所述第一纸质文档ocr识别结果中与所述当前位置信息对应的图像信息,得到关键字段图像切片;s43、识别所述关键字段图像切中的字符,得到数据信息;s44、添加所述一关键字段的类别信息和所述文本信息至预设的结构化文档;s45、重复执行s41至s44,直至与所述第一纸质文档ocr识别结果对应的每一关键字段均被遍历。优选地,所述s2具体为:s21、为每一类别信息分配一个唯一的数字编号;s22、所述第一深度学习模型识别所述训练样本集中的一样本,得到信息集合;所述信息集合包括位置信息和类别信息;s23、获取与所述一样本对应的标注文档,得到当前标注文档;s24、比较所述信息集合和所述当前标注文档,计算得到误差值;所述信息集合和所述当前标注文档中的类别信息均使用所述数字编号表示;s25、根据所述误差值调整所述第一深度学习模型的参数;s26、重复执行s22至s25,直至所述误差值小于预设的阈值,得到所述第二深度学习模型。优选地,所述第一深度学习模型用于目标检测。本发明具有如下有益效果:1、本发明提供基于深度学习模型创建纸质文档结构化数据的方法和终端,区别于现有技术将字段定位任务简化为从纸质文档ocr识别结果中固定位置截取字段对应的图像,本发明使用训练好的第二深度学习模型先识别出纸质文档ocr识别结果中关键字段的位置信息和类别信息,进而可根据位置信息识别出与所述类别信息对应的文本内容,并以结构化的数据形式保存类别信息及其对应的文本内容。本发明提供的文档结构化方法,关键字段可在纸质文档ocr识别结果中的任一位置,使得在ocr识别过程中发生位置偏移的应用场景中,也能正确识别并匹配关键字段的类别和文本内容,提高了将纸质文档ocr识别结果转换为结构化文档的准确度。同时,对于存在多种布局版本但实质内容相同的纸质文档,使用同一模型即可完成识别出各类别关键字段所在的位置,而无需像现有技术那样,一种布局版本就需要使用一套专用的关键字段位置信息去匹配,极大程度上节省了资源,并提高了将纸质文档通过ocr识别后再转换为结构化文档的效率和准确度。2、进一步地,根据一关键字段的位置信息识别出与所述一关键字段的类别信息对应的文本信息,并将属于同一关键字段的类别信息与文本信息关联,存入结构化文档中,有利于提供高效的文档检索、文档分析以及其它智能化服务。3、进一步地,由于深度学习模型的输出为数字,在标注文档中也使用数字编号表示类别信息,避免将深度学习模型的输出结果转换为对应的信息类别过程中出错,有利于提高比较深度学习模型识别结果和标准结果之间差异的准确度,从而提高使用训练样本集训练得到的第二深度学习模型识别信息类别的准确度。4、进一步地,第一深度学习模型用于目标检测,使得通过训练样本集训练后得到的第二深度学习模型,无论关键字段位于纸质文档的何处,都能够识别出纸质文档中的关键字段,进而获取关键字段的位置信息。区别于现有技术利用大量模版分析和统计关键字段的位置的方法,使用固定的边框在文档固定的位置去框取关键字段,文档定位性能容易受到文档变形、扫描变形、关键字段内容过长或者跨行等因素影响,本发明将深度学习模型目标检测的思想应用到文档关键字段的定位中,具有很高的准确度和灵活性,以及更大的适用范围。附图说明图1为人工文档结构化方法的流程图;图2为现有的纸质文档结构化方法的流程图;图3为本发明提供的基于深度学习模型创建纸质文档结构化数据的方法的具体实施方式的流程框图;图4为训练样本样例;图5为总金额关键字段的字符片段图片样例;图6为本发明提供的基于深度学习模型创建纸质文档结构化数据的终端的具体实施方式的结构框图;标号说明:1、处理器;2、存储器。具体实施方式下面结合附图和具体实施例来对本发明进行详细的说明。请参照图3至图6,本发明的实施例一为:如图3所示,本发明提供一种基于深度学习模型创建纸质文档结构化数据的方法,包括:s1、预设文档训练样本集;所述训练样本集中的每一样本包括纸质文档ocr识别结果和与所述纸质文档ocr识别结果对应的标注文档;所述标注文档记录所述文档ocr识别结果中每一关键字段的位置信息和类别信息。纸质文档包括但不限于文本文档、票据文档;例如,收集1000张票据图片,经过处理后作为样本,一部分样本作为训练样本,一部分作为测试样本。每张票据包括一定数目的字段,其中包括感兴趣的关键字段。每个样本包括纸质文档ocr识别结果,以及一份对关键字段进行标注的文档。标注文档记载每个关键字段在纸质文档ocr识别结果中的位置和关键字段的类别信息。纸质文档ocr识别结果的标注可以采取纯人工的方法,或者采用深度学习预标注然后使用人工修正的方法。图4为一份样本样例,是一张通用定额发票,里面标注了四个关键字段(发票类型,发票代码,发票号码和总金额)的位置和类别。用作训练和测试的样本,可不断补充。s2、使用所述文档训练样本集训练预设的第一深度学习模型,得到第二深度学习模型。具体为:s21、为每一类别信息分配一个唯一的数字编号;s22、所述第一深度学习模型识别所述文档训练样本集中的一样本,得到信息集合;所述信息集合包括位置信息和类别信息;优选地,所述第一深度学习模型用于目标检测。例如,目前已有一些比较成熟的用于目标检测的深度学习模型,faster-rcnn,ssd和yolo等,可以用来检测图像中是否有给定的目标,比如猫、狗、飞机等。本实施例采用现有的目标检测的深度学习网络模型,作为待训练的第一深度学习模型,但是是创新地用来检测不同的关键字段。不同的关键字段属于不同的种类,同一关键字段的内容可以变化。其中,第一深度学习模型用于目标检测,使得通过文档训练样本集训练后得到的第二深度学习模型,无论关键字段位于纸质文档ocr识别结果的何处,都能够识别出所述纸质文档ocr识别结果中的关键字段,进而获取关键字段的位置信息。区别于现有技术利用大量模版分析和统计关键字段的位置的方法,使用固定的边框在文档固定的位置去框取关键字段,文档定位性能容易受到文档变形、扫描变形、关键字段内容过长或者跨行等因素影响,本发明将深度学习模型目标检测的思想应用到文档关键字段的定位中,具有很高的准确度和灵活性,以及更大的适用范围。s23、获取与所述一样本对应的标注文档,得到当前标注文档;s24、比较所述信息集合和所述当前标注文档,计算得到误差值;所述信息集合和所述当前标注文档中的类别信息均使用所述数字编号表示;其中,由于深度学习模型的输出为数字,在标注文档中也使用数字编号表示类别信息,避免将深度学习模型的输出结果转换为对应的信息类别过程中出错,有利于提高比较深度学习模型识别结果和标准结果之间差异的准确度,从而提高使用文档训练样本集训练得到的第二深度学习模型识别信息类别的准确度。s25、根据所述误差值调整所述第一深度学习模型的参数;s26、重复执行s22至s25,直至所述误差值小于预设的阈值,得到所述第二深度学习模型。其中,本实施例中深度学习模型结构采用卷积神经网络和长短时记忆网络(longshorttermmemory,lstm)以及ctc的结构。卷积神经网络具有多个阶段(stage),每个阶段都包含一定数目的卷积模块(提取图象特征)和池化层(缩小特征图大小)等。例如,训练样本输入到第一深度学习模型训练之前,每种感兴趣的关键字段会被分配一个唯一的数字编号。第一深度学习模型将检测输入的训练样本里面的关键字段,输出每个检测到的关键字段的位置及关键字段对应的数字编号。训练过程中,训练样本直接输入到第一深度学习模型中,在计算机里面可以作为一个3维矩阵来表示训练样本。比如i_(w0,h0,c0),这里w0代表输入训练样本中纸质文档ocr识别结果的宽度(像素的个数),h0代表纸质文档ocr识别结果的高度,c0代表纸质文档ocr识别结果的颜色通道,彩色图片有红蓝绿三个颜色通道,灰度图片只有一个颜色通道。然后将训练样本的标注文档中的关键字段的位置信息和以数字编号表示的类别信息与第一深度学习模型的输出进行比较,计算定位和分类的加权综合误差,根据定位和分类的综合误差反向输入到第一深度学习模型,调整深度学习网络的参数,然后继续学习,将训练好的第一深度学习模型在测试样本集上做测试,直到第一深度学习模型定位和分类误差降低到一定程度具有了较好的定位分类能力之后停止训练,得到训练好的第二深度学习模型。s3、所述第二深度学习模型分析第一纸质文档ocr识别结果,得到所述纸质文档ocr识别结果中每一关键字段的位置信息和类别信息。s4、根据所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息创建与所述第一纸质文档ocr识别结果对应的结构化文档。具体为:s41、获取一关键字段的位置信息,得到当前位置信息。其中,当前位置信息为能完全包含所述一关键字段的最小方形的四个顶点坐标。s42、截取所述第一纸质文档ocr识别结果中与所述当前位置信息对应的图像,得到关键字段图片。其中,一个关键字段对应一个关键字段图片。s43、识别所述关键字段图片中的字符,得到文本信息。其中,在所述s43之前,需训练用于识别关键字段图片中的字符的第三深度学习模型;所述第三深度学习模型用于识别所述关键字段图片中的字符,得到文本信息。具体为:收集一定数量的字符片段图片(比如100000张),经过处理后作为深度学习字符识别的样本,一部分样本作为训练样本,一部分作为测试样本。每张图片对应一个关键字段。每个字符片段样本包括字符片段图片以及一份与字符片段图片对应的标注文档。与字符片段图片对应的标注文档里面,记载字符片段图片的字符内容。字符片段样本的标注可以采取纯人工的方法,或者采用深度学习预标注然后使用人工修正的方法。图5所示为一个总金额关键字段的字符片段图片样例,与该字符片段对应的标注文档记载的字符内容为4500.00。用作训练的样本,可不断补充。利用训练样本集训练用于字符识别的第三深度模型。训练样本输入到深度学习模型训练之前,字符标注会被转换成数字标注,每个感兴趣的汉字、英文字母、数字和标点符号都会被映射成一个唯一不相同的数字编号。深度学习将检测输入的训练图片里面的每个字符并输出检测到的字符对应的数字编号,也就是对检测到的字符进行分类。训练过程中,字符片段图片直接输入到深度学习网络,在计算机里面可以作为一个3维矩阵来表示。训练样本的数字编号用于和深度学习模型的输出进行比较,计算识别误差并调整网络参数。通过深度学习网络的卷积模块后,训练图片的特征将被提取,输出一定通道数目的特征图,比如f_(w1,h1,c1),此处w1、h1和c1分别表示经过卷积模块后的特征图的宽度、高度和通道数。经过多阶段的卷积模块和池化层后,卷积网络输出的特征图(记为f_(wn,hn,cn))被作为输入送入到长短时记忆(lstm)网络。在特征图的宽度方向上每一列(对应一个像素宽度)的特征信息(包括高度维度和通道维度)逐一输入到lstm网络,每一列输出所有可能字符以及一种额外字符(表示无字符)的概率。lstm网络的输出经过ctc模块的处理,输出识别的有效字符的整数代号,经过映射转换输出深度学习模型识别得到的有效字符。对深度学习模型识别得到的有效字符和训练样本自带的标注文档进行比较,可以计算深度学习网络识别的误差,根据识别误差反向输入到深度学习模型,调整深度学习模型的参数,然后继续学习,直到深度学习网络识别误差降低到一定程度具有了较好的识别能力之后停止训练,得到第三深度学习模型。其中,也可使用传统的识别模型识别所述关键字段图片中的字符,得到文本信息。s44、添加所述一关键字段的类别信息和所述文本信息至预设的结构化文档。其中,本实施例的结构化文档包括类别字段和文本内容字段;结构化文档中的每一条记录存储与纸质文档ocr识别结果中的一个关键字段相关的信息。例如,将图4所示的票据经ocr识别后转换为结构化文档如表1所示:表1类别文本内容billtittle厦门市顺丰速运有限公司定额发票invoicecode135021454352invoiceno00369040totalamount壹佰元整s45、重复执行s41至s44,直至与所述第一纸质文档ocr识别结果对应的每一关键字段均被遍历。本实施例提供基于深度学习模型创建纸质文档结构化数据的方法,区别于现有技术将字段定位任务简化为从图像中固定位置截取字段对应的图像,本发明使用训练好的第二深度学习模型先识别出文档ocr识别结果中关键字段的位置信息和类别信息,进而可根据位置信息识别出与所述类别信息对应的文本内容,而不是仅根据文档图像来进行处理,训练精准度更高。并以结构化的数据形式保存类别信息及其对应的文本内容。本发明提供的文档结构化方法,关键字段可在纸质文档ocr识别结果上的任一位置,使得在通过扫描或拍照方式将纸质文档ocr识别结果存入计算机等易引起关键字段在纸质文档ocr识别结果中发生位置偏移的应用场景中,也能正确识别并匹配关键字段的类别和文本内容,提高了将纸质文档ocr识别结果转换为结构化文档的准确度。同时,对于存在多种布局版本但实质内容相同的纸质文档ocr识别结果,使用同一模型即可完成识别出各类别关键字段所在的位置,而无需像现有技术那样,一种布局版本就需要使用一套专用的关键字段位置信息去匹配,极大程度上节省了资源,并提高了将纸质文档ocr识别结果转换为结构化文档的效率和准确度。相比较于现有的人工方案和固定位置文字识别方案,可以大幅度提高创建结构化文档的速度和准确度,降低结构化文档创建系统的成本,有利于增加结构化文档创建系统的规模,支持更多的用户。本发明的实施例二为:如图6所示,本发明还提供一种基于深度学习模型的创建纸质文档结构化数据的终端,包括一个或多个处理器1及存储器2,所述存储器2存储有程序,并且被配置成由所述一个或多个处理器1执行以下步骤:s1、预设文档训练样本集;所述文档训练样本集中的每一样本包括纸质文档ocr识别结果和与所述纸质文档ocr识别结果对应的标注文档;所述标注文档记录所述纸质文档ocr识别结果中每一关键字段的位置信息和类别信息。例如,收集1000张票据图片,经过处理后作为样本,一部分样本作为训练样本,一部分作为测试样本。每张票据包括一定数目的字段,其中包括感兴趣的关键字段。每个样本包括纸质文档ocr识别结果,以及一份对关键字段进行标注的文档。标注文档记载每个关键字段在纸质文档ocr识别结果中的位置和关键字段的类别信息。文档标注可以采取纯人工的方法,或者采用深度学习预标注然后使用人工修正的方法。图4为一份样本样例,是一张通用定额发票,里面标注了四个关键字段(发票类型,发票代码,发票号码和总金额)的位置和类别。用作训练和测试的样本,可不断补充。s2、使用所述训练样本集训练预设的第一深度学习模型,得到第二深度学习模型。具体为:s21、为每一类别信息分配一个唯一的数字编号;s22、所述第一深度学习模型识别所述训练样本集中的一样本,得到信息集合;所述信息集合包括位置信息和类别信息;优选地,所述第一深度学习模型用于目标检测。例如,目前已有一些比较成熟的用于目标检测的深度学习模型,faster-rcnn,ssd和yolo等,可以用来检测图像中是否有给定的目标,比如猫、狗、飞机等。本实施例采用现有的目标检测的深度学习网络模型,作为待训练的第一深度学习模型,但是是创新地用来检测不同的关键字段。不同的关键字段属于不同的种类,同一关键字段的内容可以变化。其中,第一深度学习模型用于目标检测,使得通过训练样本集训练后得到的第二深度学习模型,无论关键字段位于纸质文档ocr识别结果的何处,都能够识别出纸质文档ocr识别结果中的关键字段,进而获取关键字段的位置信息。区别于现有技术利用大量模版分析和统计关键字段的位置的方法,使用固定的边框在文档固定的位置去框取关键字段,文档定位性能容易受到文档变形、扫描变形、关键字段内容过长或者跨行等因素影响,本发明将深度学习模型目标检测的思想应用到文档关键字段的定位中,具有很高的准确度和灵活性,以及更大的适用范围。s23、获取与所述一样本对应的标注文档,得到当前标注文档;s24、比较所述信息集合和所述当前标注文档,计算得到误差值;所述信息集合和所述当前标注文档中的类别信息均使用所述数字编号表示;其中,由于深度学习模型的输出为数字,在标注文档中也使用数字编号表示类别信息,避免将深度学习模型的输出结果转换为对应的信息类别过程中出错,有利于提高比较深度学习模型识别结果和标准结果之间差异的准确度,从而提高使用文档训练样本集训练得到的第二深度学习模型识别信息类别的准确度。s25、根据所述误差值调整所述第一深度学习模型的参数;s26、重复执行s22至s25,直至所述误差值小于预设的阈值,得到所述第二深度学习模型。其中,本实施例中深度学习模型结构采用卷积神经网络和长短时记忆网络(longshorttermmemory,lstm)以及ctc的结构。卷积神经网络具有多个阶段(stage),每个阶段都包含一定数目的卷积模块(提取图象特征)和池化层(缩小特征图大小)等。例如,训练样本输入到第一深度学习模型训练之前,每种感兴趣的关键字段会被分配一个唯一的数字编号。第一深度学习模型将检测输入的训练样本里面的关键字段,输出每个检测到的关键字段的位置及关键字段对应的数字编号。训练过程中,训练样本直接输入到第一深度学习模型中,在计算机里面可以作为一个3维矩阵来表示训练样本。比如i_(w0,h0,c0),这里w0代表输入训练样本中纸质文档ocr识别结果的宽度(像素的个数),h0代表纸质文档ocr识别结果的高度,c0代表纸质文档ocr识别结果的颜色通道,彩色图片有红蓝绿三个颜色通道,灰度图片只有一个颜色通道。然后将训练样本的标注文档中的关键字段的位置信息和以数字编号表示的类别信息与第一深度学习模型的输出进行比较,计算定位和分类的加权综合误差,根据定位和分类的综合误差反向输入到第一深度学习模型,调整深度学习网络的参数,然后继续学习,将训练好的第一深度学习模型在测试样本集上做测试,直到第一深度学习模型定位和分类误差降低到一定程度具有了较好的定位分类能力之后停止训练,得到训练好的第二深度学习模型。s3、所述第二深度学习模型分析第一纸质文档ocr识别结果,得到所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息。s4、根据所述第一纸质文档ocr识别结果中每一关键字段的位置信息和类别信息创建与所述第一纸质文档ocr识别结果对应的结构化文档。具体为:s41、获取一关键字段的位置信息,得到当前位置信息。其中,当前位置信息为能完全包含所述一关键字段的最小方形的四个顶点坐标。s42、截取所述第一纸质文档ocr识别结果上与所述当前位置信息对应的图像,得到关键字段图片。其中,一个关键字段对应一个关键字段图片。s43、识别所述关键字段图片中的字符,得到文本信息。其中,在所述s43之前,需训练用于识别关键字段图片中的字符的第三深度学习模型,所述第三深度学习模型用于识别所述关键字段图片中的字符,得到文本信息。具体为:收集一定数量的纸质文档的字符片段图片(比如100000张),经过处理后作为深度学习字符识别的样本,一部分样本作为训练样本,一部分作为测试样本。每张图片对应一个关键字段。每个字符片段样本包括字符片段图片以及一份与字符片段图片对应的标注文档。与字符片段图片对应的标注文档里面,记载字符片段图片的字符内容。字符片段样本的标注可以采取纯人工的方法,或者采用深度学习预标注然后使用人工修正的方法。图5所示为一个总金额关键字段的字符片段图片样例,与该字符片段对应的标注文档记载的字符内容为4500.00。用作训练的样本,可不断补充。利用训练样本集训练用于字符识别的第三深度模型。训练样本输入到深度学习模型训练之前,字符标注会被转换成数字标注,每个感兴趣的汉字、英文字母、数字和标点符号都会被映射成一个唯一不相同的数字编号。深度学习将检测输入的训练图片里面的每个字符并输出检测到的字符对应的数字编号,也就是对检测到的字符进行分类。训练过程中,字符片段图片直接输入到深度学习网络,在计算机里面可以作为一个3维矩阵来表示。训练样本的数字编号用于和深度学习模型的输出进行比较,计算识别误差并调整网络参数。通过深度学习网络的卷积模块后,训练图片的特征将被提取,输出一定通道数目的特征图,比如f_(w1,h1,c1),此处w1、h1和c1分别表示经过卷积模块后的特征图的宽度、高度和通道数。经过多阶段的卷积模块和池化层后,卷积网络输出的特征图(记为f_(wn,hn,cn))被作为输入送入到长短时记忆(lstm)网络。在特征图的宽度方向上每一列(对应一个像素宽度)的特征信息(包括高度维度和通道维度)逐一输入到lstm网络,每一列输出所有可能字符以及一种额外字符(表示无字符)的概率。lstm网络的输出经过ctc模块的处理,输出识别的有效字符的整数代号,经过映射转换输出深度学习模型识别得到的有效字符。对深度学习模型识别得到的有效字符和训练样本自带的标注文档进行比较,可以计算深度学习网络识别的误差,根据识别误差反向输入到深度学习模型,调整深度学习模型的参数,然后继续学习,直到深度学习网络识别误差降低到一定程度具有了较好的识别能力之后停止训练,得到第三深度学习模型。其中,也可使用传统的识别模型识别所述关键字段图片中的字符,得到文本信息。s44、添加所述一关键字段的类别信息和所述文本信息至预设的结构化文档。其中,本实施例的结构化文档包括类别字段和文本内容字段;结构化文档中的每一条记录存储与纸质文档ocr识别结果中的一个关键字段相关的信息。例如,将图4所示的票据转换为结构化文档如表2所示:表2s45、重复执行s41至s44,直至与所述第一纸质文档ocr识别结果对应的每一关键字段均被遍历。本实施例提供基于深度学习模型创建纸质文档结构化数据的终端,区别于现有技术将字段定位任务简化为从图像中固定位置截取字段对应的图像,本发明使用训练好的第二深度学习模型先识别出纸质文档ocr识别结果中关键字段的位置信息和类别信息,进而可根据位置信息识别出与所述类别信息对应的文本内容,并以结构化的数据形式保存类别信息及其对应的文本内容。本发明提供的文档结构化方法,关键字段可在纸质文档ocr识别结果上的任一位置,使得在通过扫描或拍照方式将纸质文档ocr识别结果存入计算机等易引起关键字段在纸质文档ocr识别结果中发生位置偏移的应用场景中,也能正确识别并匹配关键字段的类别和文本内容,提高了将纸质文档ocr识别结果转换为结构化文档的准确度。同时,对于存在多种布局版本但实质内容相同的纸质文档ocr识别结果,使用同一模型即可完成识别出各类别关键字段所在的位置,而无需像现有技术那样,一种布局版本就需要使用一套专用的关键字段位置信息去匹配,极大程度上节省了资源,并提高了将纸质文档ocr识别结果转换为结构化文档的效率和准确度。相比较于现有的人工方案和固定位置文字识别方案,可以大幅度提高创建结构化文档的速度和准确度,降低结构化文档创建系统的成本,有利于增加结构化文档创建系统的规模,支持更多的用户。以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的
技术领域:
,均同理包括在本发明的专利保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1