一种基于布局约束的视频文字追踪方法与流程
本发明涉及一种视频处理领域,尤其是自然场景拍摄视频中的文字追踪方法。
背景技术:
视频中的文字包含高层语义信息、通常与视频内容密切相关。因此,视频文字的提取在许多基于媒体分析的应用中发挥着重要作用,例如盲人辅助系统、驾驶辅助系统、自主移动机器人等。视频文字的提取通常包括文字检测和文字跟踪,文字检测完成对视频帧图像中文字目标的定位,文字追踪完成在连续图像序列中将相同的文字区域对应起来。视频中的文字通常具有时间冗余特性,即文字在视频中会存在一段时间后消失。利用该特性,通过文字追踪技术可以提高视频文字检测的稳定性和精度。另外,文字追踪还能够为视频分析提供其他相关信息,例如:在视频时间序列中文字出现和消失的时间点、文字在某段时间的运动轨迹等。一些实时处理系统还可以利用文字在视频中的时间冗余特性提高系统处理速度。由此可见,文字追踪技术在基于视频分析应用中具有重要的作用。
现有的视频文字追踪方法无法很好的处理相机大幅度移动时多文字的追踪问题。因为在自然场景中,文字通常不会单个出现,而是以密集形式出现。这些文字往往具有相同的尺寸、长宽比和颜色特征,而多数的追踪算法提取的特征无法很好的区分这些文字,会造成错误的匹配而无法正确追踪文字。随着相机的大幅度移动时,这种情况会更加严重。
基于上述问题,本发明提出了一种基于布局约束的视频文字追踪方法,以解决大幅度相机移动下的多文字追踪。
技术实现要素:
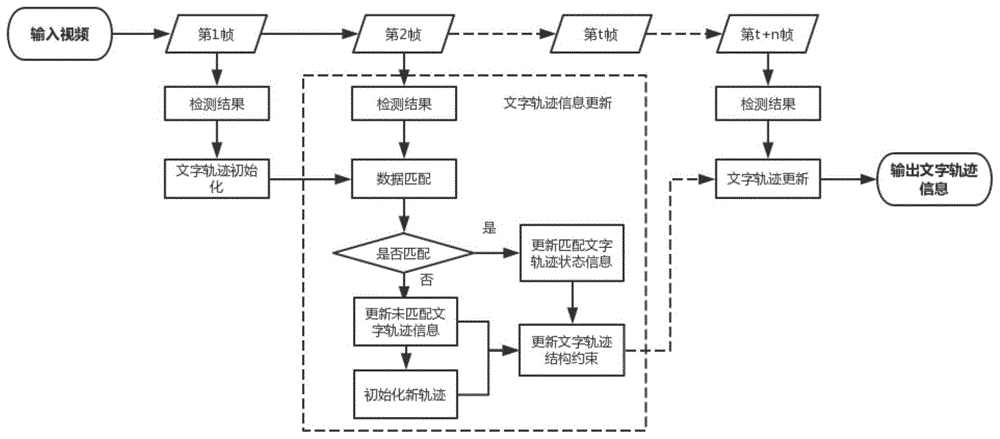
为了解决大幅度相机移动下的多文字追踪问题,本发明提出了一种基于布局约束的视频文字追踪方法。本发明的方法流程如附图1所示。该方法的输入为视频和视频单帧图像的文字检测结果,输出为每个文字区域在视频中的轨迹,即在每一帧中的空间信息(位置坐标与宽高)。首先,通过初始视频帧的文字区域检测结果进行文字轨迹的初始化,然后将上一帧的文字轨迹与当前帧的文字区域检测结果送入本发明的追踪方法中进行文字轨迹的更新,重复该过程直到视频处理完成,最终得到文字追踪结果。文字轨迹更新的核心是将当前帧检测到的文字区域对应到已有的文字轨迹,该过程可以视为一种数据匹配问题。本发明针对此问题设计一个新的数据匹配代价函数,通过求解代价函数的得到最佳匹配结果。本发明在数据匹配代价函数中引入布局约束,通过文字区域间的整体外观结构进行文字追踪,可以有效避免因为相机大幅度运动导致错误追踪结果,具有更好的追踪效果。本发明的具体细节如下。
1、设计数据匹配代价函数
首先定义当前帧中文字轨迹所包含的文字区域。设视频第t帧文字轨迹中第i个文字区域的状态为
对于每两个文字区域,需要建立其位置和速度的相互关系,这种相互关系可以视为一种结构约束,结构约束可由公式(1)所示:
其中
追踪任务是将文字区域检测结果匹配到已有的文字轨迹上,设第t帧中第p个文字区域检测结果信息为
本发明中使用二值符号ai,p表示文字轨迹与文字区域检测结果匹配情况,当文字轨迹i与文字区域检测结果p相匹配,则ai,p=1,否则ai,p=0。对于第t-1帧中的文字轨迹与第t帧中的文字区域检测结果,其数据匹配情况可由公式(2)描述:
a=argminc(st-1,rt-1,dt)(2)
其中a={ai,p|i∈nt-1,p∈mt},本方法中一个文字轨迹最多匹配到一个文字区域检测结果,c(st-1,rt-1,dr)表示文字轨迹与文字区域检测结果所有可能的配对集合。而最佳的匹配结果为该集合最小值argminc(st-1,rt-1,dt)。
在连续帧中,具有相同背景的文字间相互距离不会发生太大变化。当相机运动时,文字与其它文字应保持相似的外观。在文字追踪中,本方法同时考虑相邻帧中文字的相似性和与其相联系的其他文字外观的相似性,这种相邻帧中文字周围布局外观的相似性即布局约束。基于布局约束的代价函数c(st-1,rt-1,dt)如公式(3)所示:
其中
式中
公式(3)中
式中hb(s)表示rgb颜色空间归一化直方图特征,b是特征总数,b是索引,
2、代价函数优化与求解
为了简化计算,本发明使用公式(8)和公式(9)约束轨迹和检测结果的匹配,当不满足条件时,视为ai,p=0。公式(8)和(9)如下所示:
式中sa和sb表示两个文字区域间的状态,当区域间距离和相对速度过大时,则认为两者不能进行匹配。在本发明中τ取值为10。
最后,根据公式(2)可以计算出所有配对文字区域代价值,并得到一个nt-1×mt的相似度矩阵。使用文献1“kuhnhw.thehungarianmethodfortheassignmentproblem[j].navalresearchlogistics,1955,(1-2):83-97.”提出的方法可以计算出最佳匹配结果。结果为一个2×q的矩阵,该矩阵为文字轨迹索引号与文字区域检测结果索引号的匹配矩阵,其中q为匹配个数。利用该匹配矩阵,能够更新已有文字轨迹在当前帧中新的空间信息(位置坐标和宽高),即完成当前帧的文字区域追踪。例如:第t-1帧有3条正在追踪的文字轨迹,第t帧有3个检测到的文字区域,经过本发明算法计算后得到的匹配矩阵如(10)所示:
该矩阵第一列表示文字轨迹索引号,第二列表示文字区域检测结果索引号。其表示第1条文字轨迹对应的是第2个检测到的文字区域,第2条文字轨迹对应的是第1个检测到的文字区域,第3条文字轨迹对应的是第3个检测到的文字区域。根据该匹配矩阵,将第t帧的3个检测到的文字区域相应坐标和宽高信息替换对应文字轨迹中的空间信息,完成第t帧文字轨迹的更新。
3、有益效果
本发明能够在大规模相机移动时准确追踪到视频中的文字轨迹。本发明使用文字追踪领域公知数据库minetto进行测试。minetto数据库共包括5段场景文字视频,视频帧分辨率为640×480。在测试阶段中,将视频与每帧视频图像的文字检测结果输入到本发明追踪算法中,算法输出每个文字区域在视频中的轨迹,即文字区域在每帧中的空间信息(位置坐标与宽高)。通过计算多目标追踪准确率(motp)、多目标追踪正确率(mota)和轨迹索引变化次数(ids)三个公知评价指标来衡量本发明算法的有效性。与文献2“peiwy,yangc,mengly,etal.scenevideotexttrackingwithgraphmatching[j].ieeeaccess,2018,6:19419-19426.”中方法相比,本发明提出的基于布局约束的视频文字追踪在minetto数据库上性能极大地改进,具体为:motp指标提高了6%,mota提高了19%,ids提升了一倍。
附图说明
图1是基于布局约束的视频文字追踪方法流程图。
具体实施方式
参照图1,本发明提出的基于布局约束的视频文字追踪方法的具体步骤如下:
步骤1:输入视频和文字检测结果
本发明是建立在视频文字检测结果上。文字检测可分为线上检测和线下检测。对于线上检测,首先输入视频,随后逐帧或跳帧检测文字,将检测结果输入本发明中进行文字追踪,然后再进行下一帧文字检测,重复该过程直到视频处理完成。对于线下检测,首先输入视频,然后进行文字检测直到视频处理完成,最后将视频和每一帧的检测结构输入到本发明中进行文字追踪。本发明提出的追踪方法可以同时应用到线上检测和线下检测。
步骤2:文字轨迹初始化
对视频第一帧的检测结果进行轨迹初始化,将每一个检测到的文字区域视为一个新的文字轨迹并进行索引编号,然后计算所有文字区域的状态st,其状态中速度(ut,vt)初始化为(0,0),t=1。并根据公式(1)计算两两文字区域间的结构约束rt,t=1。同时根据约束公式(8)和(9)去除不符合要求的结构约束,记录剩余结构约束r1与文字轨迹状态s1。
步骤3:文字轨迹更新
文字轨迹更新阶段,通过第t帧的文字区域检测结果与第t-1帧中已有的文字轨迹进行匹配,将匹配到的文字区域检测结果相应空间信息(位置坐标和宽高)替换对应文字轨迹中文字区域的空间信息。该阶段输入为第t-1帧的文字轨迹状态st-1、结构约束rt-1和第t帧文字区域检测结果dt,输出为更新后的文字轨迹空间信息。
步骤3.1:数据匹配
对第t-1帧的文字轨迹和第t帧的文字区域检测结果进行配对,一共形成nt-1×mt个配对组合。然后利用公式(3)计算所有配对的代价值得到一个nt-1×mt的相似度矩阵。使用公式(3)前首先利用公式(8)进行约束判断,当不满足条件时,跳过公式(3)的计算,将该配对代价值设为999。使用文献1“kuhnhw.thehungarianmethodfortheassignmentproblem[j].navalresearchlogistics,1955,(1-2):83-97.”提出的方法可以计算出最佳匹配结果。结果为一个2×q的矩阵,该矩阵为文字轨迹索引号与文字区域检测结果索引号的匹配矩阵,其中q为匹配个数。
步骤3.1:更新匹配到轨迹
如果文字轨迹与当前文字区域检测结果相匹配,则利用文献3“linksikf.anintroductiontothekalmanfilter[j].1995.”中提出的卡尔曼滤波算法使用文字区域检测结果
步骤3.2:更新未匹配轨迹
现有的文字检测算法往往会出现漏检现象,导致文字轨迹未能匹配到文字区域检测结果。此时利用已更新后的文字轨迹状态st和第t-1帧的结构约束rt-1对未匹配到的文字轨迹使用公式(11)进行预测,公式如下所示:
其中nr为匹配到文字轨迹的个数,(x,y)为文字区域区域中心坐标,(δx,δy)为结构约束中的中心坐标距离差值。将预测的区域中心坐标替换未匹配到文字轨迹中的旧坐标,并记录替换次数,当替换次数大于3时,视为该文字轨迹消失,从文字轨迹中删除该轨迹信息。
步骤3.3:初始化新的轨迹
如果第t帧文字区域检测结果p未能与任何文字轨迹匹配,则认为出现新的文字轨迹,建立新轨迹状态
步骤3.4:更新文字轨迹结构约束
根据公式(1)计算两两文字轨迹间的结构约束。同时根据约束公式(8)和(9)去除不符合要求的结构约束,记录剩余结构约束rt。
步骤3.5:输出更新轨迹
输出第t帧更新后的文字轨空间信息(位置坐标和宽高),记录并更新所有轨迹存活次数。
步骤4:输出文字轨迹信息
重复步骤3直到视频处理完成,根据文字在视频中的时间冗余特性,即文字在视频中往往会存在一段后才会消失。本发明利用该时间冗余特性过滤非文字区域,当轨迹的存活次数小于等于15帧时,判断此轨迹非文字区域,删除该文字轨迹信息。经过过滤处理,最终输出剩余的文字轨迹信息。
- 还没有人留言评论。精彩留言会获得点赞!