基于GapStatistic的风电场机群划分方法与流程
本发明属于风力发电领域,具体涉及一种基于gapstatistic的风电场机群划分方法。
背景技术:
风力发电是目前世界可再生能源开发技术中,最成熟、最具大规模开发和商业化前景的能源利用方式,加快风电开发利用对于实现世界能源的可持续发展具有重要的战略意义。但是与常规能源不同,风电具有“间歇性”和“随机性”的特点,风电场输出功率的波动性将会对电力系统的安全、稳定和经济运行带来诸多不利的影响。研究如何建立简单,有效的风电场模型是解决风电接入系统及并网运行的技术问题的基础。
工程应用中,通常将风电场等值为一台风力发电机组,然而,对于大型的风电场,由于地形地貌以及尾流效应和时滞的影响,使用单台机等值方法通常会存在较大误差。有研究采用不同聚类算法对风电机组进行机群划分,建立风电场动态等值的多机表征模型,但是没有研究对风电场聚类过程中的最佳聚类数进行计算,从而不能达到最优的聚类效果。
技术实现要素:
本发明要解决的技术问题是:提供针一种基于gapstatistic的风电场机群划分方法,以解决目前没有研究对风电场聚类过程中的最佳聚类数进行计算,从而不能达到最优的聚类效果问题。
本发明技术方案:
一种基于gapstatistic的风电场机群划分方法,它包括:
步骤1、采集某一段时刻内,风电场内所有风力机输出的有功功率作为风力机的状态变量,作为需要聚类的数据集保存;
步骤2、利用k-means方法对状态变量数据集进行聚类,将整个风电场内的风电机群划分1,...,kmax类;
步骤3:利用gapstatistic算法对不同聚类结果进行处理,确定风电场聚类问题所判定类的最优数目为ks;
步骤4:选取步骤2中聚类数目为ks的聚类结果为最优聚类结果。
步骤1所述采集某一段时刻内,风电场内所有风力机输出的有功功率作为风力机的状态变量,作为需要聚类的数据集保存的方法为:采集的风电场内所有风力机在某一时段内输出的有功功率作为状态变量,有功功率在该段时间的采样点为m个,建立有功功率矩阵p为
式中:xi,j表示第i台风电机组在第j个时刻测得的风速,p中样本数量为n,维数为m。
步骤2所述利用k-means方法对状态变量数据集进行聚类,将整个风电场内的风电机群划分1,...,kmax类的方法包括:
2a)、将所有样本组分为依次分为1,…,kmax个簇,kmax为所设定的最大聚类数目;任意选择k个样本作为k个簇ca的初始聚类中心,样本点中心形式为
xa=(xa,1,xa,2,…,xa,m)(2)
式中,a=1,2,…,k;ca为第a个簇样本集合;
2b)、计算任意一个样本点xi到k个聚类中心的欧式距离为
将样本点xi划分到使欧式距离d最小的簇ca,遍历所有样本组,完成第一次划分;
2c)、计算每个簇中的样本均值,并计算标准测度函数分别为
式中,
2d)、以每个簇的样本均值为新的初始聚类中心,重复步骤2b)—步骤2d),直到标准测度函数收敛;得到聚类数为k时最终的聚类结果。
步骤3所述利用gapstatistic算法对不同聚类结果进行处理,确定风电场聚类问题所判定类的最优数目的方法包括:
3a)、确定聚类的紧凑测度;用给定群集ca中包含na个点的点之间的群集内欧式距离的总和表示,da越小,聚类的紧凑性越好
聚类数为k类的聚类紧凑性用标准化的簇内平方误差和wk表示为:
该方差量wk是确定最佳簇数的简单过程的基础;
3b);引入参考的测度值;用簇内平方误差和wk确定最佳聚类数目;
用gapstatistic方法,引入参考的测度值,来作为“肘点”选择的方法;参考数据集由montecarlo采样的方法获得,使用不同数量的簇k=1,...,kmax对每个参考数据集进行聚类;计算对应的测度值gap;
式中,b是采样次数;e*{logwk}为用montecarlo采样得到的参考数据集求得簇内平方误差和wk的期望值,
3c)、修正误差,寻找最佳聚类数;为了修正montecarlo采样带来的误差,计算sk即标准差进行矫正
选择满足下式的最小的k作为最有的聚类个数
gap(k)≥gap(k+1)-sk+1(13)。
本发明有益效果:
本发明基于风电机组实测运行数据,采用gapstatistic方法在基于k-means的聚类基础上,确定风电场聚类问题所判定类的最优数目,提高了风电场等值的聚类效果,并为不同聚类数对应的聚类效果的提供了理论支撑,建立的风电场动态等值模型能较准确地反映风电场的动态响应特性;解决了目前没有研究对风电场聚类过程中的最佳聚类数进行计算,从而不能达到最优的聚类效果问题。
附图说明
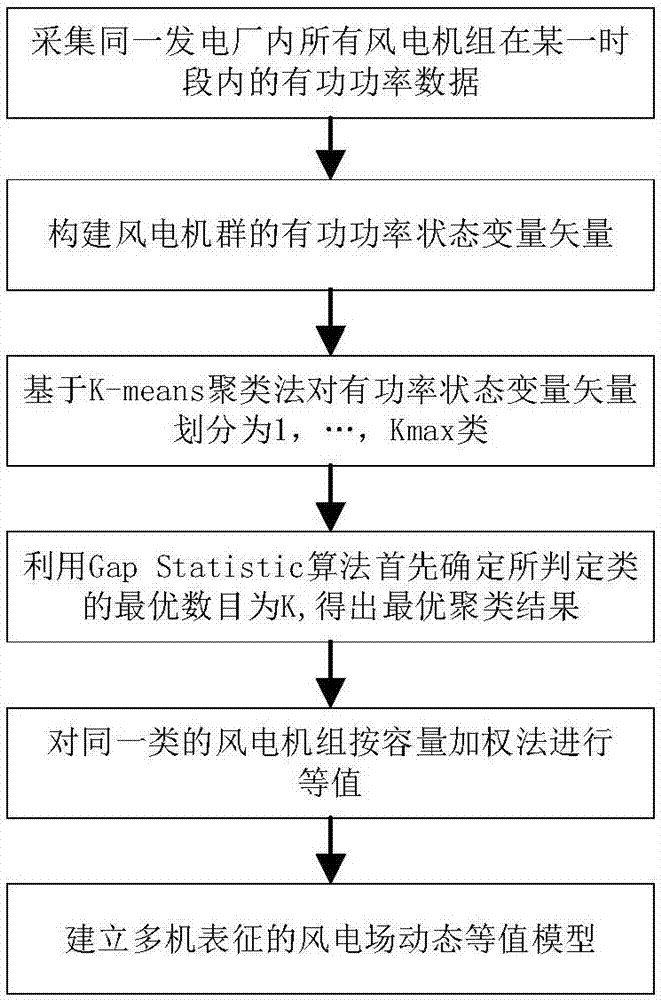
图1是本发明步骤框图;
图2是本发明求取最佳聚类数的算法流程图;
图3是基于实测风电场数据的测度值曲线及最优聚类数的求取结果示意图。
具体实施方式
一种基于gapstatistic风电场机群划分方法,所述方法包括步骤:
步骤1:采集一段时刻内风电场内所有风力机输出的有功功率作为风力机的状态变量,作为需要聚类的数据集保存;采集时段一般是24小时。
步骤2:利用k-means方法对状态变量数据集进行聚类,将整个风电场内的风电机群划分1,...,kmax类;
步骤3:利用gapstatistic算法对不同聚类结果进行处理,确定风电场聚类问题所判定类的最优数目为ks;
步骤4:选取步骤2中聚类数目为ks的聚类结果为最优聚类结果;
步骤1中,采集一段时刻内风电场内所有风力机输出的有功功率作为风力机的状态变量,作为需要聚类的数据集保存,其过程为:
1a).根据步骤1中采集的风电场内所有风力机在某一时段内输出的有功功率作为状态变量,有功功率再该段时间的采样点为m个,建立有功功率矩阵p为
其中,xi,j表示第i台风电机组在第j个时刻测得的风速;p中样本数量为n,维数为m;
步骤2中,利用k-means方法对步骤1中得到状态变量数据集进行聚类,将整个风电场内的风电机群划分1,...,kmax类,其过程为:
2a).将所有样本组分为依次分为1,…,kmax个簇,kmax为所设定的最大聚类数目;以聚类数为k为例进行说明。任意选择k个样本作为k个簇ca的初始聚类中心,样本点中心形式为
xa=(xa,1,xa,2,…,xa,m)(2)
式中,a=1,2,…,k;ca为第a个簇样本集合。
2b).计算任意一个样本点xi到k个聚类中心的欧式距离为
将所有样本点划分到使欧式距离d最小的簇ca,遍历所有样本组,完成第一次划分;
2c).计算每个簇中的样本均值,并计算标准测度函数分别为
式中,
2d).以每个簇的样本均值为新的初始聚类中心,重复步骤2b)—步骤2c),直到标准测度函数收敛;得到聚类数为k时最终的聚类结果。
步骤3中利用gapstatistic算法对不同聚类结果进行处理,确定风电场聚类问题所判定类的最优数目,其过程为:
3a).确定聚类的紧凑测度;可用给定群集ca中包含na个点的点之间的群集内欧式距离的总和表示,da越小,聚类的紧凑性越好。
聚类数为k类的聚类紧凑性可用标准化的簇内平方误差和wk表示为:
该方差量wk是确定最佳簇数的简单过程的基础。
3b).引入参考的测度值;用簇内平方误差和wk可确定最佳聚类数目;随着聚类数目增多,每一个类别中数量越来越少,距离越来越近,因此wk值肯定是随着聚类数目增多而减少的,所以关注的是斜率的变化,当wk减少得很缓慢时,就认为进一步增大聚类数效果也并不能增强,存在得这个“肘点”就是最佳聚类数目。
可用gapstatistic方法,引入参考的测度值,来作为“肘点”选择的方法。参考数据集可以由montecarlo采样的方法获得,使用不同数量的簇k=1,...,kmax对每个参考数据集进行聚类。计算对应的测度值gap为:
式中,b是总的采样次数;e*{logwk}为用montecarlo采样得到的参考数据集求得簇内平方误差和wk的期望值,
3c).修正误差,寻找最佳聚类数;为了修正montecarlo采样带来的误差,计算sk即标准差进行矫正:
选择满足下式的最小的k作为最有的聚类个数。
gap(k)≥gap(k+1)-sk+1(13)
该想法试图找到一种方法来标准化logwk与数据的空引用分布的比较,例如一种没有明显分类的分布。他们对最佳簇数k的估计是根据logwk落在该参考曲线下方最远的值。
步骤4中选取步骤2中聚类数目为ks的聚类结果为最优聚类结果,其过程为:
聚类结果为将将风电场机群划分为ks类,划分集群为
下面结合实例和附图对本发明作进一步说明,但不应以此限制本发明的保护范围。
先请参阅图1,图2,图1是本发明基于gapstatistic方法风电场机群划分方法的基本步骤框图,图2是基于gapstatistic方法求取最佳聚类数的算法流程图。
计算方法具体实现如下:
1)采集一段时刻内风电场内所有风力机输出的有功功率作为风力机的状态变量为p如式(1)所示。
2)利用k-means方法对步骤1中得到状态变量数据集进行聚类,将整个风电场内的风电机群划分1,...,kmax类。
首先任意选择k个样本作为k个簇ca的初始聚类中心xa,如式(2)所示,由式(3)计算任意一个样本点xi到k个聚类中心的欧式距离,然后将所有样本组xi划分到使欧式距离d最小的簇ca,遍历所有样本组,完成第一次划分。
根据式(4)和式(5)计算每个簇中的样本均值
以每个簇的样本均值为新的初始聚类中心,重复上述步骤,直到标准测度函数收敛。得到聚类数为k时最终的聚类结果。其他聚类数的聚类步骤相同。
3)利用gapstatistic算法对不同聚类结果进行处理,确定风电场聚类问题所判定类的最优数目,流程如图2所示。
首先根据式(6)确定聚类的紧凑测度da,根据式(7)计算标准化的簇内平方误差和wk作为确定最佳簇数的简单过程的基础。
生成参考数据集并使用不同数量的簇k=1,...,kmax对每个参考数据集进行聚类。然后根据式(8),式(9)计算估计的gap值。
修正误差,寻找最佳聚类数。为了修正montecarlo采样带来的误差,计算sk即标准差进行矫正。基于式(10),由式(11)计算标准差sd(k)并由式(12)定义sk。
选择满足式(13)的最小的k作为最有的聚类个数。
4)选取步骤2中聚类数目为ks的聚类结果为最优聚类结果。
5)以某地区实际风电场为例进行分析,该风电场内共有33台风电机组,其中机组类型为ge1.5mw,风电场总装机容量为49.5mw。
选取2018年1月1日24h的实测数据进行分析,该时段内,有3台风机离网运行,将该风电机组的实测功率数据剔除。对场内30台并网运行的风电机组采用本文提出的基于gapstatistic方法风电场机群划分方法,划分结果如表1所示。
表1基于gapstatistic方法风电场机群划分方法的分群结果
不同聚类数对应的gap值和最优聚类数的选取结果如图3所示。
- 还没有人留言评论。精彩留言会获得点赞!