基于Spark大数据平台的商品需求预测与物流分仓规划方法与流程
本发明涉及大数据分析应用
技术领域:
,涉及电子商务中,尤其是涉及智能家居产品电子商务中,满足电商商品需求预测与物流分仓规划所使用的基于spark大数据平台的商品需求预测与物流分仓规划方法。
背景技术:
:随着科技的迅猛发展,互联网给人们带来了各种各样的便捷服务,电子商务越来越复杂,智能家居是在互联网影响之下物联化的体现,智能家居通过物联网技术将家中的各种设备(如音视频设备、照明系统、窗帘控制、空调控制、安防系统、数字影院系统、影音服务器、影柜系统、网络家电等)连接到一起,提供家电控制、照明控制、电话远程控制、室内外遥控、防盗报警、环境监测、暖通控制、红外转发以及可编程定时控制等多种功能和手段。与普通家居相比,智能家居不仅具有传统的居住功能,兼备建筑、网络通信、信息家电、设备自动化,提供全方位的信息交互功能,甚至为各种能源费用节约资金。对于智能家居电子商务市场而言,时限与价格是用户考虑的两个重要因素,在一般情况下,时限的提升与价格的降低总是存在刚性的外部限制,因此,需要在更深层次上寻求解决之道,分仓备货服务是指由智能家居商家根据销售预测,提前备货至仓库,实现就近发货、区内配送,智能家居商家无需自建仓库也能轻松拥有动辄耗资百亿的一线电商的物流体系,实现极速送达。随着各种节日和电商平台的推波助澜,爆款、特卖等各种形式网购促销活动将会成为常态。智能家居商家若以传统单仓模式发货,很难避免跨省发件量大、物流成本高、发货及派送时间长、用户投诉等问题,因此标准化程度较高、库存深度较深的品牌应该考虑提前分仓备货。每逢大促,消费者最关心的是快递什么时候送到。最有效的办法是通过大数据和算法,让货物直接放到离消费者最近的仓库;以大数据驱动的供应链能够帮助商家大幅降低运营成本,提升用户的体验,对整个智能家居电商行业的效率提升起到重要作用。高质量的智能家居商品需求预测是供应链管理的基础和核心功能。实现高质量的商品需求预测是朝智能化的供应链平台方向更加迈进一步。因此如何实现更精确的需求预测,让货物直接放到离消费者最近的仓库,同时又能够大大地优化运营成本,是至关重要的是是急需解决的问题。spark是一个基于内存的快速高效的提供了支持dag图的分布式并行计算框架分布式大数据处理框架。采用hadoop支持的数据源或文件系统存储数据,包括hdfs,hbase,hive,cassandra等。既可以部署在一个单独的服务器也可以部署在像mesos或yarn这样的分布式资源管理框架之上。并且提供scala,java和python三种程序设计语言的api。利用spark提供的api,开发者可以用标准的api接口创建基于spark的应用。rdd(弹性分布式数据集)是一种抽象数据类型,是数据在spark中的表现形式,也是spark中最核心的模块和类,也是设计精华所在。你可以把它看作是一个有容错机制的大集合,spark提供了persist机制将其缓存到内存中,方便迭代运算和多次使用。rdd是分区记录的,不同区可以分布在不同的物理机上,更好的支持并行计算。rdd还有一个特性是它是弹性的,当在作业运行的过程中,机器的内存溢出时,rdd会与硬盘数据进行交互,虽然会降低效率,但却可以保证作业的正常运行。在rdd上可以进行两种操作:转换和动作。转换:通过一系列的函数操作将现有rdd转换成为一个新的rdd,即返回值仍然是rdd,且rdd可以不断进行转换。由于rdd是分布式存储的,所以整个转换过程也是并行进行的。常用的转换高阶函数如map,flatmap,reducebykey等。动作:返回值不是一个rdd。它可以是一个scala的普通集合,或者是一个值,或者是空,最终或返回到driver程序,或把rdd写入到文件系统中。比如reduce、saveastextfile和collect等函数。sparkapplication在遇到action操作时,sparkcontext会生成job,并将每一个job分为不同的stage,(每个job会被拆分很多组task,每组任务被称为stage,也可称taskset。task是被送到某个executor上的工作单元)。每个sparkapplication获取专属的executor,一个executor对应一个jvm进程,该进程负责运行task。来自不同application的task运行在不同的jvm进程中。该进程在application期间一直驻留,并以多线程方式运行tasks。每个节点可以起一个或多个executor;每个executor由若干core、memery组成,每个executor的每个core一次只能执行一个task;每个task执行的结果就是生成了目标rdd的一个partiton,task被执行的并发度=executor数目*每个executor核数。技术实现要素:针对上述
背景技术:
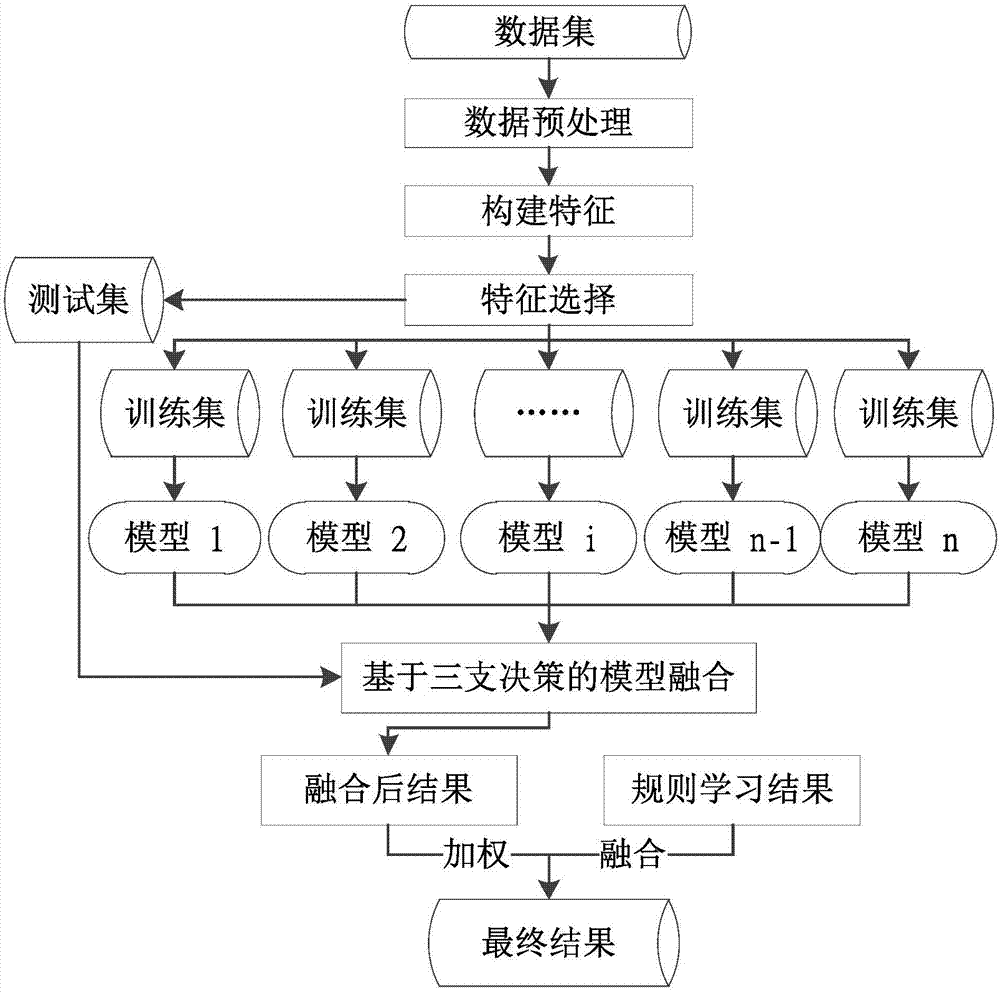
所阐述的问题,本发明目的是提供基于spark大数据平台的商品需求预测与物流分仓规划方法,解决现有智能家居商品需求预测与物流分仓规划中信息效率低、成本高的问题,能够有效帮助智能家居商家大幅降低运营成本,降低收货时效,提升用户的体验。为了达到上述目的,本发明提供如下技术方案:基于spark大数据平台的商品需求预测与物流分仓规划方法,其特征在于:包括如下步骤:q1、数据预处理,从数据库中获取相关数据文件,包括商品粒度相关特征相关商品用户行为特征、商品和分仓区域粒度相关特征、分仓区域的补少补多的成本等相关信息然后,将数据库中因近期上架或者下架导致没有销量记录的商品进行填0处理,以保证数据连续性;即:创建将sparkcontext对象,然后用它的textfile(url)函数创建分布式数据集rdd,其中rdd中数据包括智能家居商品粒度相关特征,包括id,类目,品牌,日期,价格、相关商品用户行为特征包括浏览人数、加购物车人数,购买人数,流量、商品和分仓区域粒度相关特征、分仓区域的补少、补多的成本等信息,创建完成的分布式数据集就可以被并行操作;其次,调用mappartitions算子将<特征1,特征2,…,特征m>形式的样本采用0将因近期上架或者下架导致没有销量记录的的商品的相关字段补齐,以保证数据连续性;调用zipwithindex算子,给每一条样本做一个标号,将创建的rdd转化成<标号,商品id,仓库code,特征1,特征2,…,特征m>形式,最后调用filter算子根据商品交易日期将整个数据集划分成测试集testrdd和训练集trainrdd,并调用persist算子将得到的trainrdd持久化内存中;q2、特征构建,采用滑动窗口法构建特征,对trainrdd调用mappartitions算子,编写相应的统计函数,统计每个partition上的样本在不同时间段内(窗口)的相关信息构建相应的特征,选择每个特定的时间点后n天作为一个窗口,该窗口各个商品,仓库库存的总销量作为label特征值,滑动m个窗口,对特定的时间点前n天作为一个窗口,进行特征构建,统计该窗口前n天的各种类目特征值的和值sum和平均值avg,统计商品在最近n天的交易数的特征值,包括最大值、最小值、标准差,统计其类目id在最近n天的交易数的特征值,包括最大值、最小值、标准差以及排名值,占比,后n天的总销量作为label,滑动m个窗口,经过一系列的数据变换将创建的trainrdd转化成<标号,商品id,仓库code,特征1,特征2,…,特征m,特征m+1,…,特征n,label>形式;q3、特征值选择,采用xgboost,选择排名topk的特征,计算相似度,去除冗余特征,选择q2中构建特征的相关特征值,然后用xgboost模型去学习,最得到特征的重要性排序,选取topk个重要特征计算相似度,剔除掉那些不重要的特征;q4、模型选择,训练多个回归模型,首先对trainrdd使用lr、svr、rf、gbrt、xgboostsparkmllib机器学习库中的算法和第三方分布式学习算法训练多个回归模型,将各个模型预测结果调用union算子得到多有模型的预测结果定义为model_rdd;其次,调用groupby算子根据商品id进行聚合。最后调用map算子,如果某个(商品id,仓库code)的补少成本大于补多成本,则我们倾向于预测多一点,故取单模型预测结果中的最大值再乘以1.1,反之取单模型预测结果中的最小值再乘以0.9,经过一系列的数据变换将得到<商品id,仓库code,未来时间段内分仓区域目标库存>形式的模型学习结果model;q5、模型预测结果与规则预测结果进行融合,融合系数为0.75model+0.25rule,其中rule规则学习定义为:预测窗口前n天的销量分别记作day1,day2,…dayn,对每个商品,如果补少成本大于补多成本,则预测为n*max(day1,day2,…dayn),反之预测为n*min(day1,day2,…dayn),最终将testrdd转化成<商品id,仓库code,未来时间段内分仓区域目标库存>,定义为rule_rdd,最终将得到每个商品在分仓区域中未来某时间段目标库存。本发明基于spark大数据平台对智能家居商品需求预测与分仓规划方法,能够有效帮助智能家居商家大幅降低运营成本,降低收货时效,提升用户的体验,更加符合数据量快速增长的实际商用场景。附图说明图1本发明的流程示意图。图2本发明的特征工程阶段rdd变化图。具体实施方式下面将结合本发明的附图和实施例,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。根据图1和2所示,本发明以智能家居产品的电子商务产品和物流库存为实施例,说明基于spark大数据平台的商品需求预测与物流分仓规划方法,包括如下步骤:q1、数据预处理阶段:从相关智能家居产品数据库中获取相关数据信息,并将多表数据进行整合方便后续使用,然后进行预处理操作,将数据记录中因近期上架或者下架导致没有销量记录的商品进行填0处理,以保证数据连续性;其次根据需要选择是否进行归一化操作。最后,根据要预测时间长短划分数据,将整体划分成训练集,验证集以及测试集。创建将sparkcontext对象,然后用它的textfile(url)函数创建分布式数据集rdd,其中rdd中数据包括智能家居商品粒度相关特征,包括id,类目,品牌,日期,价格、相关商品用户行为特征包括浏览人数、加购物车人数,购买人数,流量、商品和分仓区域粒度相关特征、分仓区域的补少、补多的成本等信息,创建完成的分布式数据集就可以被并行操作;其次,调用mappartitions算子将<特征1,特征2,…,特征m>形式的样本采用0将因近期上架或者下架导致没有销量记录的的商品的相关字段补齐,以保证数据连续性;调用zipwithindex算子,给每一条样本做一个标号,将创建的rdd转化成<标号,商品id,仓库code,特征1,特征2,…,特征m>形式,最后调用filter算子根据商品交易日期将整个数据集划分成测试集testrdd和训练集trainrdd,并调用persist算子将得到的trainrdd持久化内存中。其中数据结构如下表1、表2所示:表1商品粒度相关特征表2商品分仓区域的补少、补多的成本字段类型含义示例item_idbigint商品id333442store_codestring仓库code1money_astring商品补少补多cost10.44money_bstring商品补少补多cost20.88q2、特征构建:采用滑动窗口法构建特征,选取每个特定的时间点后n天作为一个窗口,该窗口各个商品,仓库库存的总销量作为特征值label,滑动m个窗口,对特定的时间点前n天作为一个窗口,进行特征构建:即统计该窗口前1/2/3/5/7/9/…/n天的各种类目特征的sum和avg,统计该窗口前n天的各种类目特征值的和值sum和平均值avg,统计商品在最近n天的交易数的特征值,包括最大值、最小值、标准差,统计其类目id在最近n天的交易数的特征值,包括最大值、最小值、标准差以及排名值,占比以及满足多项式交叉特征值。选择2015年7月10至2015年12月13日时间段内进行训练,滑动11个窗口,窗口长度选择两周14天进行特征提取,特征包括该窗口前1/2/3/5/7/9/…/14天的各种类目特征值的和值sum和平均值avg,统计商品在最近14天的交易数的特征值,包括最大值、最小值、标准差,统计其类目id在最近14天的交易数的特征值,包括最大值、最小值、标准差以及排名值,占比以及满足多项式交叉特征值。每个窗口长度最后一天往后统计14天内的销售总件数求和作为特征值label。见表3滑动窗口说明表3滑动窗口日期说明q3、特征值选择:基于spark进型数据变换,采用xgb选择排名topk的特征,计算相似度,去除冗余特征。具体操作为:对trainrdd调用xgboost的分布式版本对输入的n个特征计算重要性。然后调用sortby算法和filter算子选取topk个重要性特征,此时trainrdd转化成<标号,商品id,仓库code,特征x1,特征x2,…,特征xk,label>形式。最后调用mappartitions算子计算特征间的皮尔逊相关系数,根据特征间的相似度大小剔除冗余特征。并对调用persist算子将得到的trainrdd持久化内存中。比如:构建了400个相关特征,然后选择xgboost模型去学习,则会输出每个特征的重要性系数,这里我们选择tok40,即选择了重要性排在前40的特征;然而这40个特征可能存在冗余。因此通过计算特征间的相似度,常用的相似度计算方法包括皮尔森相关系数、余弦相似度等。这40个特征中比如特征1与特征10相似度高达0.999,则可选择去除特征1或者特征10,只保留其中一个特征。具体去除那个还用考虑其与其他特征的关系。q4、模型选择:对trainrdd依次调用lr、svr、rf、gbrt、xgboost等sparkmllib机器学习库中的算法和第三方分布式学习算法训练多个回归模型,并将各个模型预测结果调用union算子得到多有模型的预测结果定义为model_rdd。然后调用groupby算子根据商品id进行聚合。最后调用map算子,如果某个(商品id,仓库code)的补少成本大于补多成本,则我们倾向于预测多一点,故取单模型预测结果中的最大值再乘以1.1,反之取单模型预测结果中的最小值再乘以0.9。经过一系列的数据变换将得到<商品id,仓库code,未来时间段内分仓区域目标库存>形式的模型学习结果。表4各模型预测值举例图商品仓位lrsvrrfgbrtxgboostb000230455410010c00034060702010若智能家居商品b补多成本为10元,补少成本为100元,则该智能家居商品在0002仓库中的预测结果值为100*1.1=110;若智能家居商品c补多成本为80元,补少成本为40元,则该智能家居商品在0003仓库中的预测结果值为10*0.9=9;q5、模型预测结果与规则预测结果进行融合:预测窗口前n天的销量分别记作day1,day2,…dayn,对每个商品,如果补少成本大于补多成本,则预测为n*max(day1,day2,…dayn),反之预测为n*min(day1,day2,…dayn);比如:预测窗口前两周的销量分别记作sale1,sale2,对每个(商品,仓位),如果补少成本大于补多成本,则预测为2*max(sale1,sale2),反之预测为2*min(sale1,sale2)。融合预测结果,将模型预测结果与规则预测结果进行融合,融合系数为0.75model+0.25rule;如图2所示模型间进行融合,模型融合结果为m1,然后与规则进行融合,融合结果为m2,利用模型m2,如表1、表2所示历史数据,根据不同的智能家居产品的历史数据,可在spark大数据平台上,预测未来它们在仓库中所需的如表4所示的存货量,相比较表4而言,表4只是单模型的输出结果,m2是多模型与规则的融合结果,效果会更佳。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1