一种基于MBTiles的地图瓦片存储方法与流程
本发明属于地理信息系统领域,涉及一种地理信息系统中大规模地理空间数据的地图瓦片存储方法。
背景技术:
为了提高网络地理信息服务的获取速度,常将地理空间数据进行处理并裁切成统一规格的多级图片,即“地图瓦片”。为了有效提高这些瓦片的获取和显示效率,在进行瓦片的生成时,常利用一种金字塔结构的多分辨率层次模型进行瓦片的组织和构建,即金字塔模型。金字塔模型通常是基于四叉树结构,以分层分块的方式进行构建。其每层所表示的地理覆盖范围相同,随着逐级切分,从上层到下层,对应的地图比例尺越来越大,表示的地面分辨率也越来越高。下层瓦片是由同范围大比例尺数据在其本层分块策略基础上,再次进行四等分后形成,层数即地图的缩放级别,每层均组成一个瓦片矩阵。因此,对于任意相邻的层,从上到下,瓦片矩阵的行列数呈倍数递增关系,可以快速进行瓦片定位,方便网络调用和显示。
目前,国内外大型地理信息服务的系统和软件大多采用金字塔模型来存储、管理地图瓦片数据。对于瓦片数据的存储,大多数文件系统和传输协议对处理数以百万计的瓦片数量都有一定限制,例如:在fat32格式的文件系统中,一个文件夹中最多含有65536个文件,hfs格式最多能列出32767个文件,ext3格式超过20000个文件时会变得很慢。另外,数以百万计的瓦片数据部署或迁移时的读写和传输性能都不高。arcgis提供了一种紧促性的文件格式bundle,其易于缓存,节约空间,但官方不提供其读取方法,脱离arcgisserver使用bundle格式十分复杂,并且一个bundle文件仅可以保存128*128个瓦片数据,存储空间不具有延展性。因此,将构建好的地图瓦片其存储在一种移植性较好,操作简便,存储空间足够的文件中才能够更好的调用瓦片数据,使基于web的gis地图服务更好地满足大规模的用户需求。
当前,把大规模瓦片数据用类似于arcgis的bundle存储形式存储在基于sqlite的mbtiles文件格式当中,既满足了查询读取速度快,又满足了可移植性好、操作简便的特点。sqlite是一种轻量级数据库,使用简便。最重要的是,sqlite具有跨平台特性,其将数据库中的所有信息都包含在一个文件内,从而实现离散存储的文件统一管理,并且易于备份和移植。mbtiles是一种地图瓦片存储的数据规范,是由mapbox制定的一种将瓦片地图数据存储到sqlite数据库中并可快速使用、管理和分享的规范。利用mbtiles规范对瓦片数据进行存储可大大提高海量地图瓦片的读取速度,比通过瓦片文件方式的读取要快很多,存储瓦片数量不像bundle格式有固定限制,并且操作极为简便,用户可将mbtiles文件作为一个独立的数据库,直接在sqlite中对其进行操作。
由于sqlite本身在并发(包括多进程和多线程)读写方面的性能一直不太理想,数据库可能会被写操作独占,从而导致其它读写操作阻塞或出错。因此将生成的地图瓦片直接缓存到sqlite中效率极低,需要采用合适的方法进行存储以提高瓦片存储效率。
从研究现状来看,现有的gis系统需要将生成的地图瓦片存储在相应的文件中,以提供地图瓦片服务。而在具体存储过程中,没有统一的格式标准,而且较少采用并行化的思路,不能有效利用硬件计算资源。按照传统的存储方式,经常会面临文件数量过多,存储空间不足,整体可移植性不高,处理速度不够快的情况,尤其是存储的格式较为复杂,操作困难,而针对地图瓦片的具体存储,对自定义存储格式的数据结构组织和优化研究较少。
技术实现要素:
为解决上述技术问题,本发明提供了一种基于mbtiles的地图瓦片存储方法。首先对发明中涉及的概念进行说明,地图瓦片模型是一种多分辨率层次模型,从瓦片金字塔的底层到顶层,分辨率越来越低,但表示的地理范围不变,地图瓦片以下简称瓦片。所述地图瓦片数据是包含针对原始高分辨率地图在不同层级下的地图瓦片文件,地图瓦片文件应包含众多瓦片,瓦片应包含其影像数据和瓦片位置信息。所述瓦片位置信息,应是在全球剖分网格体系下,按照墨卡托投影或其他投影方式生成的二维平面地图上的该瓦片所在的层级、行号、列号,应能够通过其位置信息直接找到该瓦片对应地理坐标的经纬度。瓦片坐标编号范围指的是按照投影规则所对应该层级的分辨率下,所有瓦片对应的网格坐标编号范围(即行号、列号范围),本发明是基于开源轻型数据库sqlite实现的。具体技术方案为一种基于mbtiles的地图瓦片存储方法,包括以下步骤:
(s1)获取包含各层级地图瓦片的地图瓦片数据,所述地图瓦片数据为栅格形式,设获取的地图瓦片的最大层级数为max_level;
(s2)初始化,定义迭代变量k,k的初始值为max_level;设置每个mbtiles文件内瓦片的存储数量c×r,其中c表示列数,r表示行数;
(s3)读取第k层级的地图瓦片数据,获取该层级所有瓦片的位置信息、瓦片坐标编号范围,并将该层级的地图瓦片数据读入到内存中;所述瓦片位置信息包括该瓦片所在的层级、行号、列号;所述瓦片坐标编号范围是指在该层级的分辨率下所有瓦片的行号、列号组成的范围;
(s4)根据(s2)中设置的每个mbtiles文件内瓦片的存储数量c×r和(s3)中获取的瓦片坐标编号范围,计算在第k层级下共需要生成的mbtiles文件数量和需要生成的每个mbtiles文件对应的文件坐标编号,并在指定路径下创建空的mbtiles文件;
(s5)将第k层级的所有瓦片,按照每个瓦片的位置信息,计算出所对应存储的mbtiles文件,并将每个瓦片存储于对应的mbtiles文件内;
(s6)将当前层级数k减1,若当前层级数k大于0,则返回(s3);若当前层级数k不大于0,则所有地图瓦片数据已采用mbtiles文件的格式存储完毕。
进一步地,所述步骤(s4)中计算在第k层级下共需生成的mbtiles文件数量及需要生成的每个mbtiles文件对应的文件坐标编号具体方法为:根据每个mbtiles文件内瓦片的存储数量c×r,假设第k层的瓦片坐标编号范围是[min_col,min_row,max_col,max_row],其中该范围为一个矩形四边形,min_col,min_row为左上角列行号,max_col,max_row为右下角列行号。
设所对应生成的mbtiles文件的文件坐标编号范围[min_c,min_r,max_c,max_r],其中该范围为一个矩形四边形,min_c、min_r为左上角列行号,max_c、max_r为右下角列行号,通过以下公式解算:
优选地,本发明将每个mbtiles文件内瓦片的存储数量设置为1024*1024个,但并不限于该存储方法,其他能够实现本发明技术效果的存储方法也同样适用。
进一步地,所述步骤(s4)中按一定组织形式在指定路径下创建空mbtiles文件的具体方法为:根据需生成的每个mbtiles文件的文件坐标编号,在该层级目录下根据列c的值创建目录,并以行r的值命名,存储为mbtiles文件格式,即按照“指定目录/当前层级k/列号c/行号r.mbtiles的路径建立空mbtiles文件,由此建立起mbtiles文件在文件系统中的易于查找的组织形式。
进一步地,所述步骤(s5)中计算出每个瓦片对应存储于的mbtiles文件的具体方法为:假设某个瓦片的瓦片坐标编号为tile_col列和tile_row行,通过计算过程:
进一步地,所述步骤(s5)中将瓦片存储到mbtiles文件中的具体过程为:在将瓦片数据存储到mbtiles文件的过程中,以瓦片数据集为单位采用车轮法,将任务进行划分,用并行化的方法对瓦片进行存储。具体划分方法如下:假设i表示第i个任务,则第i个任务中需要生成的mbtiles文件的坐标编号列号为min_c+[i/(max_c-min_c+1)],行号为min_r+i%(max_c-min_c+1),%表示取余符号。该mbtiles文件对应存储的瓦片数据集范围可根据其位置坐标列号和行号找到。根据生成的mbtiles文件总数确定任务总数,设置任务,将所有任务分配给各进程,以并行的方式同时对所有瓦片进行存储。
进一步地,所述步骤(s5)中按照存储规范将瓦片存储于mbtiles文件中的具体方法为:依据mbtiles规范,利用瓦片的信息在mbtiles文件中创建map表和images表,其中map表中包含zoom_level,tile_column,tile_row,tile_id四个字段,分别存储瓦片所在层级、位置坐标和瓦片的字符串标识,并以(zoom_level,tile_column,tile_row)为主键。若瓦片不自带字符串tile_id,可自动生成一个tile_id。images表中包含tile_id和tile_data字段,分别存储瓦片的字符串标识和瓦片的影像数据,并以tile_id为主键。其中瓦片的影像数据tile_data转化为二进制blob格式存储于mbtiles中。
进一步地,所述步骤(s5)中对mbtiles文件进行优化的具体方法为:去除重复数据并添加索引以提高查询速度。在mbtiles文件中,根据images表的tile_data字段,查询重复的数据,返回重复数据的tile_id,只保留其中一个,并在map表中找到其他重复数据的tile_id,替换为保留数据的tile_id,再在images表中将重复数据删除,以达到去除重复数据的效果。对map表和images表建立索引,在map表中建立tile_column字段和tile_row字段的联合索引,对images表的tile_id字段建立索引。
采用本发明获得的有益效果是:(1)本发明所生成的地图瓦片文件采用基于sqlite的mbtiles格式存储,可移植性强,文件数量少,易于备份和移植,又由于sqlite的轻便性使得文件可以在不修改任何参数的情况下直接在多种平台上进行操作。(2)本发明使得地图瓦片的读取速度得到极大提升。由于将所有瓦片的数据存储于数据库中并在数据库中建立了高效的索引,大幅度地提升了瓦片数据的查询和读取速度。(3)本发明使得地图瓦片的存储格式进行了优化。本发明相比于arcgis的bundle存储格式,单个文件存储的瓦片数量没有固定限制,可以调整,并且读取数据操作简便,在读取瓦片数据的时间上也有一定的提升。(4)本发明在将瓦片数据存储到mbtiles文件的过程中,采用并行化处理方法,使用多个进程同时处理数据,以最大化地利用多核硬件环境,极大地提高了数据处理效率,缩短了数据存储时间。
附图说明
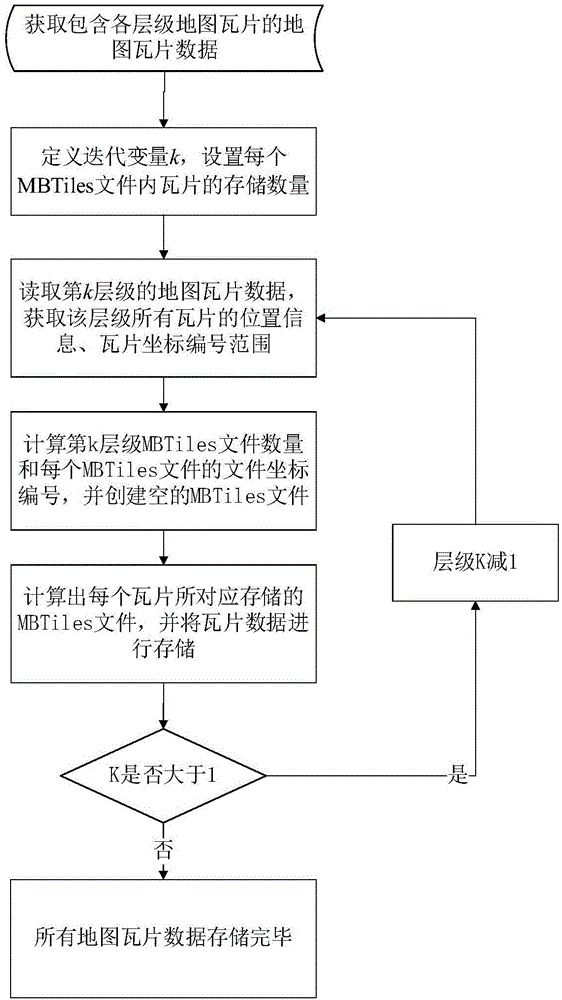
图1是本发明的总体流程示意图;
图2是本发明的地图瓦片文件存储组织形式示意图;
图3是本发明将瓦片数据存为mbtiles文件的实施例示意图;
图4是本发明在存储过程中采用并行方法进行任务划分实施例示意图;
图5是本发明mbtiles文件内map表和images表结构示意图;
图6是本发明完成存储地图瓦片任务,调整mbtiles内瓦片数据的存储个数时,在读取数据时间上的对比图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种基于mbtiles的地图瓦片存储方法,该方法能够有效地对地图瓦片进行存储,极大增加了可移植性,提高了瓦片读取速度,提高服务响应效率。
下面,结合附图和具体实施例对本发明作进一步说明。
图1是本发明的总体流程示意图。具体过程如下:
首先获取包含各层级瓦片的地图瓦片数据。在得到该地图瓦片的最大层级数max_level后,定义迭代变量k记录当前层级,初始值为max_level。其次,设置每个mbtiles文件内瓦片的存储数量c×r,其中c表示列数,r表示行数,以便于后续的mbtiles文件坐标编号的计算。根据k的值进入循环体,读取第k层级的所有瓦片数据和对应的瓦片坐标编号。并根据已设置的每个mbtiles文件内瓦片存储数量c×r,计算在该层级下共需要生成的mbtiles文件数量和每个mbtiles文件对应的文件坐标编号,从而在指定路径下按一定的组织形式创建这些空的mbtiles文件以便后续将瓦片数据的存储。之后,把已读取的第k层级所有瓦片,按照每个瓦片的瓦片坐标编号,找到其对应存储于的mbtiles文件,并按照存储规范将每个瓦片存储于对应的mbtiles文件内。将当前层级数k减1,若当前层级数k大于0,则返回循环体,按照同样的方式对下一层级的瓦片进行存储;若当前层级数k不大于0,则原始的地图瓦片数据已采用mbtiles文件的格式存储完毕。
图2是本发明的地图瓦片存储组织形式示意图:本发明的地图瓦片存储组织形式,是将所有的瓦片根据其瓦片编号,按照本发明提供的方法和规则将该瓦片编号和其影像数据存储于mbtiles文件中。在计算出mbtiles文件位置坐标后,按照瓦片所处层级和mbtiles文件所在行号对mbtiles文件以行号命名,并直接以.mbtiles格式存储。如图2所示,lev代表层级号,在每个层级文件夹下又将各mbtiles文件按照列号c分别存储于各自以列号命名的文件夹中,再在列文件夹内创建空的mbtiles文件并以行号r命名。由此构成瓦片金字塔地图数据在文件系统中的存储组织形式。从图中可发现,本发明的存储组织形式,将数量庞大的瓦片按一定规则在指定目录(实施例中,指定目录可以为存储盘下的根目录)下存储于一个或多个mbtiles文件中,极大地减少了文件数量,提高了文件备份、移动的速度,具有极强的可移植性。
图3是将影像数据存为mbtiles文件的示例。本实施例将每个mbtiles文件内瓦片的存储数量设置为1024*1024,即最多有相邻的10485764个瓦片数据存储在同一个mbtiles文件内。假设瓦片的位置坐标编号范围[2000,2000,5000,5000],通过计算过程
图4是本发明在存储过程中采用并行方法进行任务划分实施例示意图。在将瓦片数据存储到mbtiles文件的过程中,以瓦片数据集为单位采用车轮法,将任务进行划分。图中描述的是文件坐标编号范围为[102,89,105,93]的20个mbtiles文件,被8个进程进行切分的任务划分示例,每个mbtiles文件存储对应的瓦片数据集。其原理就是各进程按照进程号从小到大的顺序,根据mbtiles位置坐标系下行号和列号的顺序,从上到下,从左到右依次进行分配。当一个周期完毕后,接着上一周期的位置重复进行上述类似操作,直至各进程将所有mbtiles文件分配完毕。可以通过如下公式计算得到每个进程所分配得到的mbtiles文件的行列号:假设i表示第i个任务,则属于第i个任务需要生成的mbtiles文件的位置坐标编号列号为min_c+[i/(max_c-min_c+1)],行号为min_r+i%(max_c-min_c+1)。每个进程再根据进程总数n,按照进程号的顺序将任务依次分配,根据任务,找到对应的mbtiles文件和瓦片数据集,多进程同时对瓦片数据进行存储。由于sqlite在数据库并发读写方面的性能一直不太理想,数据库可能会被写操作独占,从而导致其它读写操作阻塞或出错。采用此车轮法将任务分配到多进程同时处理,每个进程只针对1个瓦片数据就,存储到1个mbtiles文件,有效规避了sqlite对支持并发事物效果不理想的缺点,最大化地利用多核硬件环境,极大地提高了瓦片数据的存储效率,缩短了存储时间。
图5是mbtiles文件内map表和images表结构。mbtiles是由mapbox制定的一种将瓦片地图数据存储到sqlite数据库中并可快速使用,管理和分享的规范。可将mbtiles文件看作一个数据库文件。依据mbtiles规范,在mbtiles文件中创建map表和images表,其中map表中包含zoom_level,tile_column,tile_row,tile_id四个字段,分别存储瓦片所在层级、位置坐标和瓦片的字符串标识,并以(zoom_level,tile_column,tile_row)为主键。若瓦片不自带标识信息,可自动生成一个标识信息存储于tile_id字段中。images表中包含tile_id和tile_data字段,分别存储瓦片的字符串标识和瓦片的影像数据,并以tile_id为主键。其中瓦片的影像数据tile_data转化为二进制blob格式存储于mbtiles中。当所有瓦片数据存储完毕后,可以根据mbtiles文件内的表结构,对mbtiles文件进行进一步优化。在去除重复数据方面,根据images表的tile_data字段,查询重复的数据,返回重复数据的tile_id,只保留其中一个,并在map表中找到其他重复数据的tile_id,替换为保留数据的tile_id,再在images表中将重复数据删除,以达到去除重复数据的效果。由于一个mbtiles文件内可能会存储大量瓦片数据,在查询指定的瓦片影像数据时会耗时很长,必须为map表和images表建立索引以提升查询效率。对images表,直接建立tile_id字段的索引即可,而对于map表,则需建立tile_column字段和tile_row字段的联合索引。在查询指定的瓦片影像数据时,由于存储组织形式,zoom_level可在文件系统的层级文件夹中直接找到,在mbtiles文件内通常会同时执行tile_column和tile_row的条件查询,因此只需要建立两字段的联合索引,即能够缩短查询时间,又能节省存储空间。
图6是调整改变mbtiles文件内瓦片数据的存储个数时,不同数量的读取数据时间对比图,横坐标表示瓦片存储数量及对应的文件数量,纵坐标表示读取时间(单位:ms)。其中瓦片存储数量表示每个mbtiles文件内瓦片的存储数量c×r,分为6类,“all”表示将所有瓦片数据存储于同一mbtiles文件内。对湖南花垣地区在第20层级下的532952个瓦片数据进行存储,采用不同存储方式从而生成的mbtiles文件数量如图中“文件数量”所示。本实施例中采取的时间统计方法为:对该范围的全部瓦片,随机选取1000个瓦片,对瓦片数据进行查找并返回对应mbtiles文件内该瓦片的tile_data字段中的blob二进制数据,并统计总时间。对每种不同的存储方法,均计算10次,取时间记录的平均值。由图中可以看出,当每个mbtiles文件内瓦片的存储数量越大时,瓦片数据读取的时间越少,效率越高,把全部瓦片存储于同一个mbtiles文件内,查询1000个瓦片并返回数据的时间仅为179ms。但在实际操作中,存储数据量较大的地图瓦片数据时,由于单个mbtiles文件大小的最大限制,不能将所有瓦片数据存储于同一个mbtiles下,因此仍需要设置每个mbtiles文件内瓦片的存储数量,由本实施例知,设置的存储数量在不超过限定的情况下,越大越好。而同样将该地区的瓦片在arcgis中切片,并采用bundle的格式进行存储。由于arcgis官方不提供对bundle格式内瓦片的读取方法,本实施例通过自行设计的bundle文件读取程序,对bundle内瓦片数据进行读取,并计算时间。在测试中得到在bundle中随机读取1000个瓦片数据的速度平均值为405ms。由此可知,按照本发明对地图瓦片数据进行存储,在数据的读取速度上较arcgis的bundle格式有较大的提高。
- 还没有人留言评论。精彩留言会获得点赞!