一种基于无监督学习的单目视觉定位方法与流程
本发明涉及视觉定位领域,更具体地,涉及一种基于无监督学习的单目视觉定位方法。
背景技术:
单目视觉定位技术解决的问题是,利用单目摄像头采集的视频流,恢复过程中单目摄像头的运动轨迹。
现有的基于深度学习的视觉定位方法一般分为有监督学习和无监督学习两种,基于有监督学习的视觉定位方法的缺点是需要大量的人工标注样本,耗费大量的人力且需要昂贵的高精度设备,成本较高。
而现有的基于无监督学习的视觉定位方法并不成熟。参考文献一提出了一种基于无监督学习的双目视觉定位框架,使用一个autoencoder的cnn结构将双目摄像头的左图映射为对应的深度图,再通过深度图和双目摄像头的右图重建左图,得到重建误差,进行无监督学习。参考文献二提出一种双目摄像头左右一致性的方法,可改善第一论文中重建误差的约束不足的问题。然而,这两种方法都存在需要双目摄像头设备的支持,无法在单目摄像头视频流上工作的问题。参考文献三为能单独用于单目视觉定位,提出了基于无监督学习的单目视觉定位框架,在双目视觉定位框架的基础上加一个autoencoder结构的cnn,用于估计单目摄像头采集的前后两张图片之间的位姿变换,用来代替双目摄像头的外参矩阵。然而,这种方法的缺点在于,用于估计深度图的卷积神经网络只考虑了视频流中的单帧图像作为输入,没有考虑相邻图像对深度图的估计会产生影响,导致定位效果不好。
参考文献一:ravigarg,vijaykumar,gustavocarneiro,ianreid.“unsupervisedcnnforsingleviewdepthestimation:geometrytotherescue”,eccv2016.
参考文献二:clementgodard,oisinmacaodha,gabrielbrostow.“unsupervisedmonoculardepthestimationwithleft-rightconsistency”,cvpr2017.
参考文献三:tinghuizhou,matthewbrown,noahsnavely,davidlowe,“unsupervisedlearningofdepthandego-motionfromvideo”,cvpr2017.
技术实现要素:
本发明为克服上述现有技术所述的估计深度图时没有考虑相邻图像帧的影响等至少一种缺陷,提供一种基于无监督学习的单目视觉定位方法,能够有效提高可扩展性和定位效果。
为解决上述技术问题,本发明的技术方案如下:
一种基于无监督学习的单目视觉定位方法,包括以下步骤:
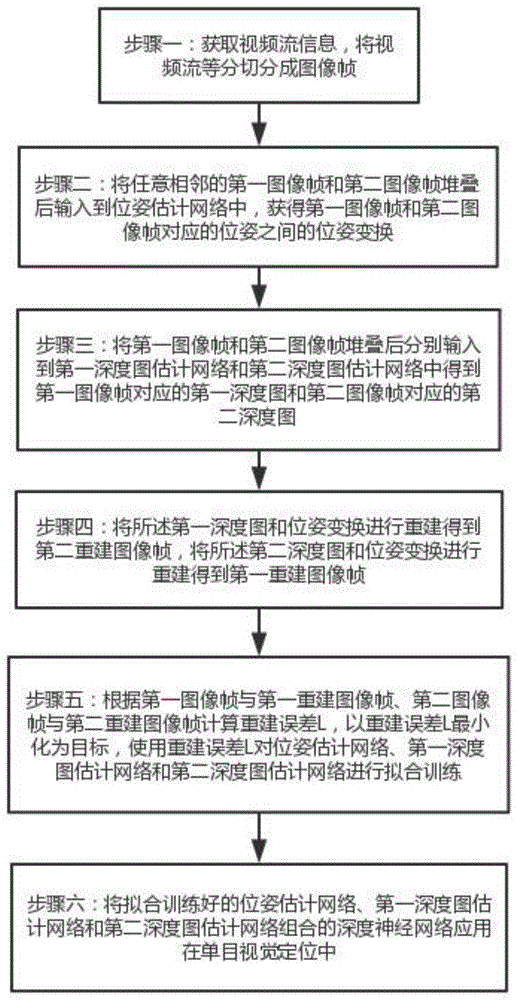
s1:获取视频流信息,将视频流等分切分成图像帧;
s2:将任意相邻的第一图像帧和第二图像帧堆叠后输入到位姿估计网络中,获得第一图像帧和第二图像帧对应的位姿之间的位姿变换;
s3:将第一图像帧和第二图像帧堆叠后分别输入到第一深度图估计网络和第二深度图估计网络中得到第一图像帧对应的第一深度图和第二图像帧对应的第二深度图;
s4:将所述第一深度图和位姿变换进行重建得到第一重建图像帧,将所述第二深度图和位姿变换进行重建得到第二重建图像帧;
s5:根据第一图像帧与第一重建图像帧、第二图像帧与第二重建图像帧计算重建误差l,以重建误差l最小化为目标,使用重建误差l对位姿估计网络、第一深度图估计网络和第二深度图估计网络进行拟合训练;
s6:将拟合训练好的位姿估计网络、第一深度图估计网络和第二深度图估计网络组合的深度神经网络应用在单目视觉定位中。
在本技术方案的s1步骤中,可通过单目摄像头或使用已有的数据集获取视频流信息,并充分考虑了所输入的视频流的所有信息,将任意相邻的两帧图像帧作为输入,通过位姿估计网络与深度图估计网络的重建得到重建图像帧,以重建误差最小化为目标,对位姿估计网络和深度图估计网络进行拟合训练,将最终拟合训练完毕的位姿估计网络、第一深度图估计网络和第二深度图估计网络组成的深度神经网络最终应用于单目视觉定位中。相比现有的使用单帧图像作为输入的方法,本技术发不敢更具有几何意义,更能有效提高其定位效果。
优选地,s2步骤中的位姿估计网络包括卷积神经网络cnn和全连接层,在本技术方案中,图像帧先经过卷积神经网络cnn提取图像特征后再通过全连接层输出该图像帧对应的位姿变换。
优选地,s2步骤的具体步骤包括:
s2.1:将第一图像帧和第二图像帧堆叠后通过卷积神经网络cnn提取图像特征;
s2.2:将第一图像帧和第二图像帧所提取的图像特征分别通过全连接层,输出第一图像帧和第二图像帧对应位姿之间的位姿变换。
优选地,s2.2步骤中的位姿变换通过李代数表示。
优选地,s3步骤中的的深度估计网络包括卷积神经网络cnn和反卷积结构的解码器,在本技术方案中,图像帧先经过卷积神经网络cnn提取图像特征后再通过反卷积结构的解码器,输出相邻两图像帧对应的深度图。
优选地,s3步骤的具体步骤包括:
s3.1:将第一图像帧和第二图像帧分别通过第一深度图估计网络中的卷积神经网络cnn完成图像特征的提取;
s3.2:将s3.1所提取的图像特征通过第一深度图估计网络中的反卷积结构的解码器,输出第一图像帧对应的第一深度图;
s3.3:将第一图像帧和第二图像帧分别通过第二深度图估计网络中的卷积神经网络cnn完成图像特征的提取;
s3.4:将s3.3所提取的图像特征通过第二深度图估计网络中的反卷积结构的解码器,输出第二图像帧对应的第二深度图。
优选地,s3.2步骤中的深度图中的深度值为深度的倒数,即逆深度,使用逆深度的好处是可以更好地表示深度是无穷远的情况,并且计算过程中能够简化运算。
优选地,s4步骤中的第一重建图像帧和第一图像帧的关系满足:
p2=k*t*d1(p1)*k-1*p1
其中,
优选地,s5步骤中重建误差l的计算公式为:
其中,i1(p1)为第一图像帧i1中p1像素点对应的坐标,i2(p2)为第二图像帧i2中p2像素点对应的坐标。
与现有技术相比,本发明技术方案的有益效果是:通过相邻两帧图像作为输入进行拟合的深度图估计函数,能够有效地提高定位效果;提出位姿估计网络和深度图估计网络组合的框架性的设计,可根据需求对其中的网络模块进行替换,可扩展性强。
附图说明
图1为本发明的流程图。
图2为本实施例的位姿估计网络的结构示意图。
图3为本实施例的深度图估计网络的结构示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
如图1所示,为本发明的流程图。
步骤一:通过单目摄像头获取视频流信息,并将视频流切分成图像帧。
步骤二:将任意相邻的第一图像帧和第二图像帧堆叠后输入到位姿估计网络中,获得第一图像帧和第二图像帧对应的单目摄像头位姿之间的位姿变换。如图2所示,为本实施例的位姿估计网络的结构示意图,其中,位姿估计网络包括卷积神经网络cnn和全连接层。具体步骤如下:
s1:将输入的两帧图像进行堆叠,形成一张通道数为6的输入图像;
s2:对输入的6通道图像用5*5的卷积核进行卷积操作,然后接着对特征图做一次下采样操作,使其大小减半;
s3:对特征图接连做6次3*3的卷积操作,每两次卷积操作之后,做一次下采样操作,使其大小减半。
s4::将s3得到的特征图用3*3的卷积核做一次卷积操作,得到的特征图就是对输入的两帧图像提取得到的特征。
s5:将提取得到的特征通过若干个全连接层进行处理,输出一个6维的向量,即为第一图像帧和第二图像帧对应的单目摄像头位姿之间的位姿变换,所述位姿变换通过李代数表示。
步骤三:将上述第一图像帧和第二图像帧堆叠后分别输入到第一深度图估计网络和第二深度图估计网络中获得第一图像帧对应的第一深度图和第二图像帧对应的第二深度图。如图3所示,为本实施例的深度图估计网络的结构示意图,其中深度图估计网络包括包括卷积神经网络cnn和反卷积结构的解码器。如第一图像帧和第二图像帧输入第一深度图估计网络的具体流程如下:
s1:将输入的第一图像帧和第二图像帧进行堆叠,形成一张通道数为6的输入图像;
s2:对输入的6通道图像用5*5的卷积核进行卷积操作,并将卷积得到的特征图保留一份副本,然后接着对特征图做一次下采样操作,使其大小减半;
s3:对特征图接连做6次3*3的卷积操作,每两次卷积操作之后,将特征图保留一份副本,然后做一次下采样操作,使大小减半;
s4:将得到的特征图用3*3的卷积核做一次卷积操作,得到的特征图就是对输入的两帧图像提取得到的特征;
s5:对s4得到的特征用3*3卷积核对特征做一次卷积操作;
s6:重复做3次如下操作:对特征图用3*3的卷积核做一次反卷积操作,使得特征图的大小变为原来的2倍,并与之前保留的相应大小的特征图做一次堆叠,然后用3*3的卷积核做一次卷积操作;
s7:对s6最终得到的特征图用5*5的卷积核做一次反卷积操作,并与之前保留的相应大小的特征图做一次堆叠,再用5*5的卷积核做一次卷积操作,得到与输入图像大小相等的一帧图像,即为输出的第一深度图,其中深度图中的深度值为该像素点深度的倒数。
第一图像帧和第二图像帧输入第二深度图估计网络的具体流程与上述流程相同,区别在于第一深度图估计网络与第二深度图估计网络中的参数经过训练后有所区别。
图2和图3中,形状的缩放表示特征图以2倍的大小缩小或者放大,连接线表示特征图堆叠。这样设计的原因在于,输出的深度图大小需要与输入图像的大小保持一致,而卷积层可以保持特征图的大小不变或者缩小特征图的大小,反卷积层可以增大特征图的大小。
步骤四:将所述第一深度图和位姿变换进行重建得到第一重建图像帧,将所述第二深度图和位姿变换进行重建得到第二重建图像帧。以第一重建图像帧为例,使用第一深度图和位姿变换进行重建的公式如下:
p2=k*t*d1(p1)*k-1*p1
其中,
步骤五:根据第一图像帧与第一重建图像帧、第二图像帧与第二重建图像帧计算重建误差l,以重建误差l最小化为目标,使用重建误差l对位姿估计网络、第一深度图估计网络和第二深度图估计网络进行拟合训练。
根据输出的第一重建图像帧和第二重建图像帧,可通过计算重建误差用以训练深度神经网络,重建误差l的计算公式为:
其中,i1(p1)为第一图像帧i1中p1像素点对应的坐标,i2(p2)为第二图像帧i2中p2像素点对应的坐标。
步骤六:将拟合训练好的位姿估计网络、第一深度图估计网络和第二深度图估计网络组合的深度神经网络应用在单目视觉定位中。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!