一种基于二元高斯非齐次泊松过程的单车数量预测方法与流程
本发明涉及数据挖掘预测技术领域,特别是涉及一种基于二元高斯非齐次泊松过程的单车数量预测方法。
背景技术:
共享单车作为一种新型的交通工具,近年得到了快速的发展。在使用的过程中,单车经常出现分布不均匀的现象,为了方便单车系统管理员的管理,则需要动态地对单车进行调度。而对单车进行调度,则需要提前对站点的单车数量进行预测。由于单车使用受到很多不确定因素的影响,预测单车数量也是一个具有挑战性的任务。
现有的技术中,常用的方法是挖掘影响单车使用的因素,然后结合一些数据挖掘方法(比如回归模型,决策树,神经网络,支持向量机等),训练预测模型,从而达到预测目的。由于影响单车使用的因素较多,且相关数据的获取受到各种限制,通常研究者能够得到的数据有限,导致并不能很全面地研究影响单车使用的因素。同时,天气数据也不是实时地更新,这对于实施性要求高的单车调度任务来说,会产生延时。导致对站点单车的数量预测准确性低,参考价值不高,对单车的调度和用户对单车的使用提供的帮助有限。
技术实现要素:
为了解决上述问题,本发明提供一种基于二元高斯非齐次泊松过程的单车数量预测方法,只需要单车站点历史的单车使用数据就能进行预测,不仅能够在相应数据获取受限的情况下,实现站点单车数量的预测,且可减小天气等不实时更新数据对预测结果的影响,从而显著提高单车数量预测的准确性。为此,本发明采用的技术方案是:
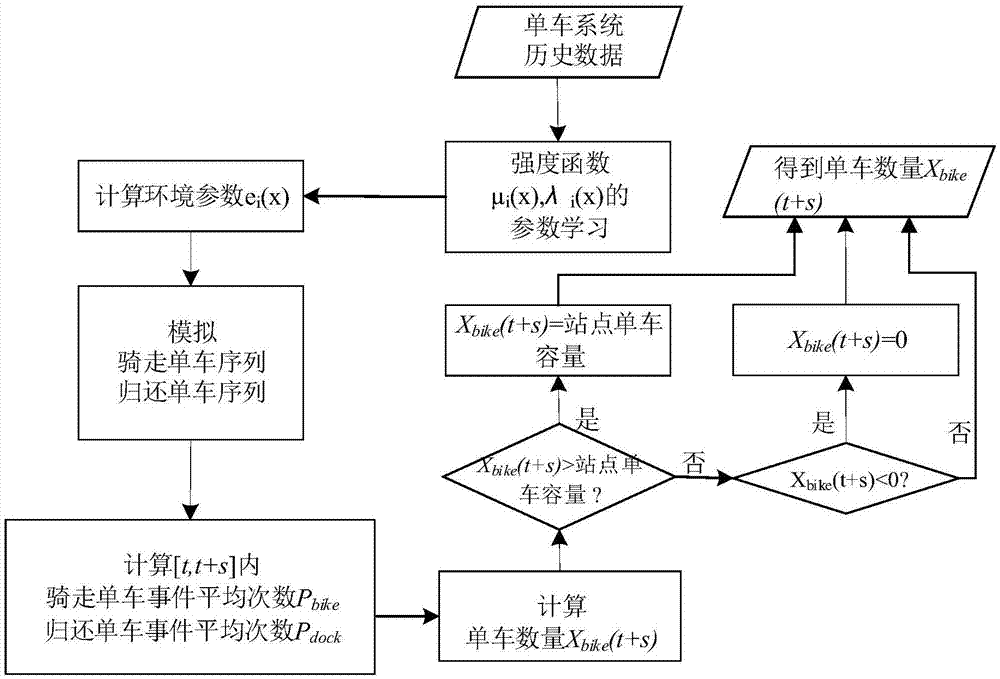
提供一种基于二元高斯非齐次泊松过程的单车数量预测方法,该方法包括以下步骤:
s1、从单车管理系统中提取单车站点预测当日之前的历史数据,所述历史数据包括过去10-15天的用户骑走单车的时间序列和用户归还单车的时间序列;
预测当日的当前时刻用t表示,未来待预测时刻用t+s表示,t取值范围为00:00:00点到23:59:59点;将用户到达并归还单车的过程和用户到达并骑走单车的过程看作泊松过程,对其进行强度函数为μi(x)和λi(x)的非齐次泊松过程建模,并利用该模型对时间变量x求导,得到用户骑走单车和归还单车的概率密度函数;其中,i表示单车站点编号;
s2、根据步骤s1中的历史数据,用二元高斯函数拟合得到μi(x)和λi(x)的表达式,并结合概率密度函数,采用迭代法学习得到μi(x)和λi(x)的参数值,得到参数赋值后的强度函数,同时将所述参数值代入步骤s1得到的概率密度函数;
s3、根据所述单车站点在当前时刻之前的1-3小时内用户骑走单车的时间序列和用户归还单车的时间序列数据,计算环境参数值,并用环境参数值对步骤s2得到的参数赋值后的强度函数进行修正,同时实现对概率密度函数的修正,得到修正后的概率密度函数;
s4、利用s3得到修正后的概率密度函数,分别模拟所述单车站点中用户骑走单车的时间序列和用户归还单车的时间序列,所述模拟的次数为5-10次;
s5、在[t,t+s]时间段,分别计算步骤s4中模拟的用户骑走单车的时间序列和用户归还单车的时间序列中事件的平均次数,所述事件是指用户骑走单车和用户归还单车事件,0<s≤2.5小时;
s6、计算单车数量的预测值,具体计算公式为:
xbike(t+s)=xbike(t)+pbike-pdock
其中,xbike(t+s)表示在t+s时刻的单车数量,xbike(t)表示在t时刻的单车数量,pbike表示步骤s5用户骑走单车事件的平均次数,pdock表示步骤s5用户归还单车事件的平均次数;
s7、对步骤s6所得的预测值进行修正,其修正方法为:当所述预测值大于所述单车站点的单车容量,则令所述预测值等于所述单车站点的单车容量;当所述预测值小于零,则令所述预测值等于零;本领域技术人员很容易理解,由于前述过程中,根据泊松理论进行模拟时,没有设定事件发生次数的上下限,因此,步骤s6中计算得到的单车数量就可能会大于该站点单车容量,或小于零,因此,根据实际情况,用上述修正方法进行修正后,可保证预测方法的可行性和准确性。
s8、根据步骤s6和s7,计算得到所述单车站点在t+s时刻的单车数量。
进一步的是,步骤s1中,用户骑走单车的概率密度函数表达式为:
其中,
用户归还单车的概率密度函数表达式为:
其中,
进一步的是,所述步骤s2中,
其中,c1,c2,a1,a2,b1,b2为强度函数表达式中的参数。
进一步的是,在步骤s3中,所述环境参数值的计算公式为:
其中
则修正后的用户骑走单车的概率密度函数公式为:
则修正后的用户归还单车的概率密度函数公式为:
进一步的是,在步骤s4中,模拟用户骑走单车的时间序列的过程包括以下步骤:
s41、设初始时间t0为t,初始化用户骑走单车的时间序列变量q;
s42、利用拒绝采样方法生成间隔时间τ,模拟用户骑走单车采用的公式为:
s43、令t0=t0+τ,然后将t0存入q;
s44、判断t0是否大于t+s,如果t0大于t+s,则结束模拟,否则,返回步骤s42;
模拟用户归还单车的时间序列的过程包括以下步骤:
s51、设初始时间t0为t,初始化用户骑走单车的时间序列变量q′;
s52、利用拒绝采样方法生成间隔时间τ,模拟用户归还单车采用的公式为:
s53、令t0=t0+τ,然后将t0存入q′;
s54、判断t0是否大于t+s,如果t0大于t+s,则结束模拟,否则,返回步骤s42。
进一步的是,步骤s2中,所述迭代法为梯度下降法。
本发明方法的理论过程如下:
目前的共享单车系统,在每个单车站点,都有一定的停车位,也有一定的单车数量。每个用户会随机地到达该站点,要么骑走一辆单车,要么归还一辆单车。单车系统会实时地记录每个站点单车被骑走的时间和单车归还的时间。
通过数据分析,我们发现对每个单车站点而言,用户到达并骑走单车的时间序列
为了简化表达,对于用户骑走单车的过程和用户归还单车的两个过程,我们只选择用户骑走单车的过程进行介绍。因为这两个过程使用发方法是一样的。
根据泊松过程理论,在时间范围[v,v’)内,每个站点用户到达满足以下分布:
其中
对于事件:单车站点在
可以理解为,在
对x求导得到其概率密度函数为:
用户到达并骑走单车的时间序列
如果用该单车站点w天的历史数据进行训练,则对于w天的时间序列
其中l为每天事件发生的个数,通过迭代方法学习强度函数的参数,即c,a1,a2,b1,b2。
此外,由于强度函数估算的是第w+1天的单车使用量变化趋势,不能反应短时间内现实因素(环境因素)对单车使用量的影响,因此我们寻求结合环境参数对强度函数进行修正,以达到提高预测准确率的效果。
根据图2所示的计算方法示意图,可以利用概率密度函数和[t,t-△t]时间范围内单车估计全天单车使用量,用这个估计值作为
对式(7)进行线性拟合修正,得到环境参数:
对于式(8)的说明:
利用式(8)得到的值对强度函数进行修正,得到用户骑走单车的概率密度函数:
再利用式(9),进行算法模拟,得到用户骑走单车事件发生的次数。
同理可得,用户归还单车事件发生的次数。
再利用步骤s6-s7,则可得出单车站点在t+s时刻的单车数量。
采用本技术方案的有益效果:
第一,相对于现有技术,本发明方法利用非齐次泊松过程建模单车使用过程,利用学习训练方法进行参数训练,并利用环境参数进行修正,得到的预测模型显著提高站点单车在未来的一定时间(2小时)内的数量预测的准确性和及时性,且只需要单车站点历史的单车使用数据就能进行预测,即能够在相应数据获取受限的情况下,实现站点单车数量的准确预测,能满足适用范围更广。
第二,本发明方法考虑了环境参数的影响,并利用环境参数进行修正,显著提高了单车数量预测的准确性。
第三,本发明利用二元高斯函数建模非齐次泊松过程的强度函数,准确的反映了单车系统的实际使用情况。
附图说明
图1是本发明方法的流程图;
图2是本发明方法的环境参数推导原理图;
图3是在bayarea单车系统上,本发明方法(bgip)与对比方法的预测效果对比图;
图4是在hubway单车系统上,本发明方法(bgip)与对比方法的预测效果对比图;
图5是在bayarea单车系统上,本发明方法(bgip)与本发明方法(bgip)未考虑环境参数时的预测效果对比图;
图6是在hubway单车系统上,本发明方法(bgip)与本发明方法(bgip)未考虑环境参数时的预测效果对比图。
图
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明作进一步阐述。
在本实施例中,如图1-6所示,一种基于二元高斯非齐次泊松过程的单车数量预测方法,该方法包括以下步骤:
s1、从单车管理系统中提取单车站点预测当日之前的历史数据,所述历史数据包括过去10-15天的用户骑走单车的时间序列和用户归还单车的时间序列;
预测当日的当前时刻用t表示,未来待预测时刻用t+s表示,t取值范围为00:00:00点到23:59:59点;将用户到达并归还单车的过程和用户到达并骑走单车的过程看作泊松过程,对其进行强度函数为μi(x)和λi(x)的非齐次泊松过程建模,并利用该模型对时间变量x求导,得到用户骑走单车和归还单车的概率密度函数;其中,i表示单车站点编号;
s2、根据步骤s1中的历史数据,用二元高斯函数拟合得到μi(x)和λi(x)的表达式,并结合概率密度函数,采用迭代法学习得到μi(x)和λi(x)的参数值,得到参数赋值后的强度函数,同时将所述参数值代入步骤s1得到的概率密度函数;
s3、根据所述单车站点在当前时刻之前的1-3小时内用户骑走单车的时间序列和用户归还单车的时间序列数据,计算环境参数值,并用环境参数值对步骤s2得到的参数赋值后的强度函数进行修正,同时实现对概率密度函数的修正,得到修正后的概率密度函数;
s4、利用s3得到修正后的概率密度函数,分别模拟所述单车站点中用户骑走单车的时间序列和用户归还单车的时间序列,所述模拟的次数为5-10次;
s5、在[t,t+s]时间段,分别计算步骤s4中模拟的用户骑走单车的时间序列和用户归还单车的时间序列中事件的平均次数,所述事件是指用户骑走单车事件和用户归还单车事件,0<s≤2.5小时;
s6、计算单车数量的预测值,具体计算公式为:
xbike(t+s)=xbike(t)+pbike-pdock
其中,xbike(t+s)表示在t+s时刻的单车数量,xbike(t)表示在t时刻的单车数量,pbike表示步骤s5用户骑走单车事件的平均次数,pdock表示步骤s5用户归还单车事件的平均次数;
s7、对步骤s6所得的预测值进行修正,其修正方法为:当所述预测值大于所述单车站点的单车容量,则令所述预测值等于所述单车站点的单车容量;当所述预测值小于零,则令所述预测值等于零;
s8、根据步骤s6和s7,计算得到所述单车站点在t+s时刻的单车数量。
作为一种优化方案,步骤s1中,用户骑走单车的概率密度函数表达式为:
其中,
用户归还单车的概率密度函数表达式为:
其中,
作为一种优化方案,所述步骤s2中,
其中,c1,c2,a1,a2,b1,b2为强度函数表达式中的参数。
作为一种优化方案,在步骤s3中,所述环境参数值的计算公式为:
其中
则修正后的用户骑走单车的概率密度函数公式为:
则修正后的用户归还单车的概率密度函数公式为:
作为一种优化方案,在步骤s4中,模拟用户骑走单车的时间序列的过程包括以下步骤:
s41、设初始时间t0为t,初始化用户骑走单车的时间序列变量q;
s42、利用拒绝采样方法生成间隔时间τ,模拟用户骑走单车采用的公式为:
s43、令t0=t0+τ,然后将t0存入q;
s44、判断t0是否大于t+s,如果t0大于t+s,则结束模拟,否则,返回步骤s42;
模拟用户归还单车的时间序列的过程包括以下步骤:
s51、设初始时间t0为t,初始化用户骑走单车的时间序列变量q′;
s52、利用拒绝采样方法生成间隔时间τ,模拟用户归还单车采用的公式为:
s53、令t0=t0+τ,然后将t0存入q′;
s54、判断t0是否大于t+s,如果t0大于t+s,则结束模拟,否则,返回步骤s42。
作为一种优化方案,步骤s2中,所述迭代法为梯度下降法。
下面以具体的实施例来做进一步的说明。
实施例1
本实施例的运行环境为:matlab2016b,java(jdk1.7),windows10,cpu(corei7(7500u),8gbram。
在本实施例中,对于bayarea单车系统,单车站点a(i=10),假设当前的日期为2013年8月23号,上午10点,单车数量为10,即xbike(10点)=10,预测单车站点a在未来的12点30分时刻的单车数量。
具体步骤包括:
s1、根据单车站点a的历史数据,从bayarea单车管理系统中提取提取过去10-15天(即13号~22号,不包括23号)的单车骑行时间序列数据(用户骑走单车的时间序列
s2、根据公式(4)-(6)并结合时间序列
s3、根据公式(7)和(8)计算环境参数ei(x)的值,采用的数据是当日(23号)时间范围7点至10点时间段内的单车数据,并用环境参数值对步骤s2得到的强度函数进行修正,进而实现对概率密度函数的修正;
s4、利用s3得到的概率密度函数,分别模拟所述单车站点a中用户骑走单车的时间序列和用户归还单车的时间序列,所述模拟的次数为5次;
s5、在10点至12点30分时间段,分别计算步骤s4中模拟的用户骑走单车的时间序列和用户归还单车的时间序列中事件的平均次数,所述事件是指用户骑走单车和用户归还单车事件,其具体次数为16次和12次;
s6、计算单车数量的预测值,具体计算公式为:
xbike(12点30分)=xbike(10点)+pbike-pdock
s7、对步骤s6所得的预测值进行修正,其修正方法为:当所述预测值大于所述单车站点a的单车容量,则令所述预测值等于单车站点a的单车容量;当所述预测值小于零,则令所述预测值等于零;
s8、根据步骤s6和s7,计算得到单车站点a在12点30分时刻的单车数量为14。
实施例2
本实施例的运行环境为:matlab2016b,java(jdk1.7),windows10,cpu(corei7(7500u),8gbram。
在本实施例中,对于hubway单车系统,单车站点a(i=20),假设当前的日期为2011年8月23号,上午9点,单车数量为8,即xbike(9点)=8,预测单车站点a在未来的上午10点时刻的单车数量。
具体步骤包括:
s1、根据单车站点a的历史数据,从hubway单车管理系统中提取提取过去10天(即1号~10号,不包括11号)的单车骑行时间序列数据(用户骑走单车的时间序列
s2、根据公式(4)-(6)并结合时间序列
s3、根据公式(7)和(8)计算环境参数ei(x)的值,采用的数据是当日(11号)时间范围8点至9点时间段内的单车数据,并用环境参数值对步骤s2得到的强度函数进行修正,进而实现对概率密度函数的修正;
s4、利用s3得到的概率密度函数,在9点至10点时间段,分别模拟所述单车站点a中用户骑走单车的时间序列和用户归还单车的时间序列,所述模拟的次数为5次;
s5、分别计算步骤s4中模拟的用户骑走单车的时间序列和用户归还单车的时间序列中事件的平均次数,所述事件是指用户骑走单车和用户归还单车事件,其具体次数为8次和7次;
s6、计算单车数量的预测值,具体计算公式为:
xbike(10)=xbike(9)+pbike-pdock
s7、对步骤s6所得的预测值进行修正,其修正方法为:当所述预测值大于所述单车站点a的单车容量,则令所述预测值等于单车站点a的单车容量;当所述预测值小于零,则令所述预测值等于零;
s8、根据步骤s6和s7,计算得到单车站点a在10点时刻的单车数量为9。
实施例3
如图3和4所示,在实施例1和2两个单车系统中,对当前时刻(实施例1为2013年8月23号10点,实施例2为2011年8月23号上午9点)之后的时刻进行连续性的单车数量预测,验证了本方法的可用性以及其达到的效果,验证指标为均方根误差(root-mean-square-error,rmse),其计算公式为:
其中,k表示预测时间集合,
rmse值越小,表示准确率越高。
单车预测效果如图3和图4所示,在bayarea单车系统和hubway单车系统上,对比方法为ha、arma和qmp,其中:
ha(historicalaverage),记载于z.yang,j.hu,y.shu,p.cheng,j.chen,andt.moscibroda,“mobilitymodelingandpredictioninbike-sharingsystems,”ininternationalconferenceonmobilesystems,applications,andservices,2016,pp.165–178,文献名称中文翻译为:自行车共享系统的移动建模和预测;
arma(auto-regressiveandmovingaverage),记载于p.vogelandd.c.mattfeld,“strategicandoperationalplanningofbike-sharingsystemsbydatamining:acasestudy,”ininternationalconferenceoncomputationallogistics,2011,pp.127–141,文献名称中文翻译为:以数据挖掘为目的的自行车共享系统的战略和业务规划:案例研究。
qmp(queuingmodelpredictor),记载于n.gast,g.massonnet,d.reijsbergen,andm.tribastone,“probabilis-ticforecastsofbike-sharingsystemsforjourneyplanning,”2015,pp.703–712,文献名称中文翻译为:关于旅行计划的自行车共享系统的概率预测。
从图3和图4的对比结果来看,在短期的预测时间内(至少在2小时内),本发明方法的rmse值均小于对比方法,也就是说,其预测的效果均好于对比方法,预测准确性更高。2小时对于用户或者系统管理员来说,已经可以满足要求。因为,如果用户查询一个站点是否有车,那么他应该是在很短的时间之后会去该站点骑车;对系统管理员来说,他们对单车的调度,必须尽快地完成,以满足用户的使用需求,所以需要的预测的时间也不会太久。因此,本方法具有实际的较高实际使用意义。
实施例4
如图5和图6所示,在实施例1和2的基础上,分别在考虑和不考虑环境参数对预测结果的影响的情况下,对当前时刻(实施例1为2013年8月23号10点,实施例2为2011年8月23号上午9点)之后的时刻进行连续性的单车数量预测则,同样用均方根误差(root-mean-square-error,rmse)进行计算,结果如图5和图6所示,图中bgip表示本发明的方法考虑环境参数的预测结果,bgipwithoutei(x)表示本发明的方法不考虑环境参数的预测结果。
结果显示,在任何时间,bgip都比bgipwithoutei(x)的均方根误差小,因此,bgip比bgipwithoutei(x)的预测准确率更高,说明本发明方法考虑的环境参数对发明的技术效果贡献较大,使本发明在对站点单车进行预测时,预测准确率进一步的提高。
需要说明的是,在图3-6中,横坐标的时间初始值0,与本申请中的当前时刻t对应,在不同的实施例中,t不同,因此,初始值0对应的时刻也不同。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!