一种基于准确人车分离的警戒方法及装置与流程
本发明属于视频监控领域,具体涉及一种视频监控中基于准确人车分离的警戒方法及装置。
背景技术:
随着科技和社会的发展,视频监控系统应用的越来越广泛,现有的相机警戒功能越来越无法满足实际应用的需求,主要体现在,当前的警戒场景下的需求不仅需要相机具有对运动目标的检测功能,还需要相机能够自动对检测出的运动物体进行准确无误的分类,由于警戒场景下触发报警的目标多为人或者车,因此需要一种方法对报警目标的属性进行准确识别分类,现有的警戒相机采用级联、svm等检测分类方法可以在一定程度上识别出报警目标属性,但因其对场景的要求十分严格,且识别准确度较低,很难广泛推广应用。
技术实现要素:
本发明的目的是提供一种基于准确人车分离的警戒方法及装置,用于警戒监控场景下对触发报警的目标快速准确的定位和识别,帮助监控人员分析触发报警的目标是人还是车。
为达到上述目的,本发明的技术方案是这样实现的:
一种基于准确人车分离的警戒方法,包括:
1)利用背景建模技术获取警戒区域中的运动区域,使用团块检测方法确定出候选区域,根据候选区域扣取送检图像的roi;
2)将扣取的送检图像送入训练好的深度学习检测网络,对图像中的人、车进行检测和识别,输出其外接矩形、类别以及置信度。
进一步的,步骤1)的具体方法包括利用背景建模技术得到前景图像,使用团块检测方法,把相邻的前景点进行目标融合,并取其外接矩形作为运动团块,并根据运动团块的尺寸比以及团块内前景点数占总像素数的比例排除掉与人、车差异较大的团块,把剩下的作为作为候选区域,根据候选区域扣取送检图像。
进一步的,步骤2)所述检测的方法包括:
201)构建人车训练数据集;
202)根据人车特征构建深度学习训练网络架构;
203)配置训练参数开始训练;
204)用训练模型对人车进行检测。
更进一步的,步骤201)所述构建人车训练数据集的具体方法包括:从海量警戒相机抓拍图像中,获取不同角度、不同光照情况下具有触发警戒报警条件的人、车图像,将原始1920x1080像素图像缩放到1080x720、540x360,得到三组多尺度图像,对每副图像以最小边作为边长,分别对每一张图像从左右截取两张正方形图像作为训练图像,随后使用标注工具在图像中标注人、车的位置和类别,生成xml格式的标注文件,将图像保存作为数据集,取80%的数据作为训练数据集,其余数据作为测试集。
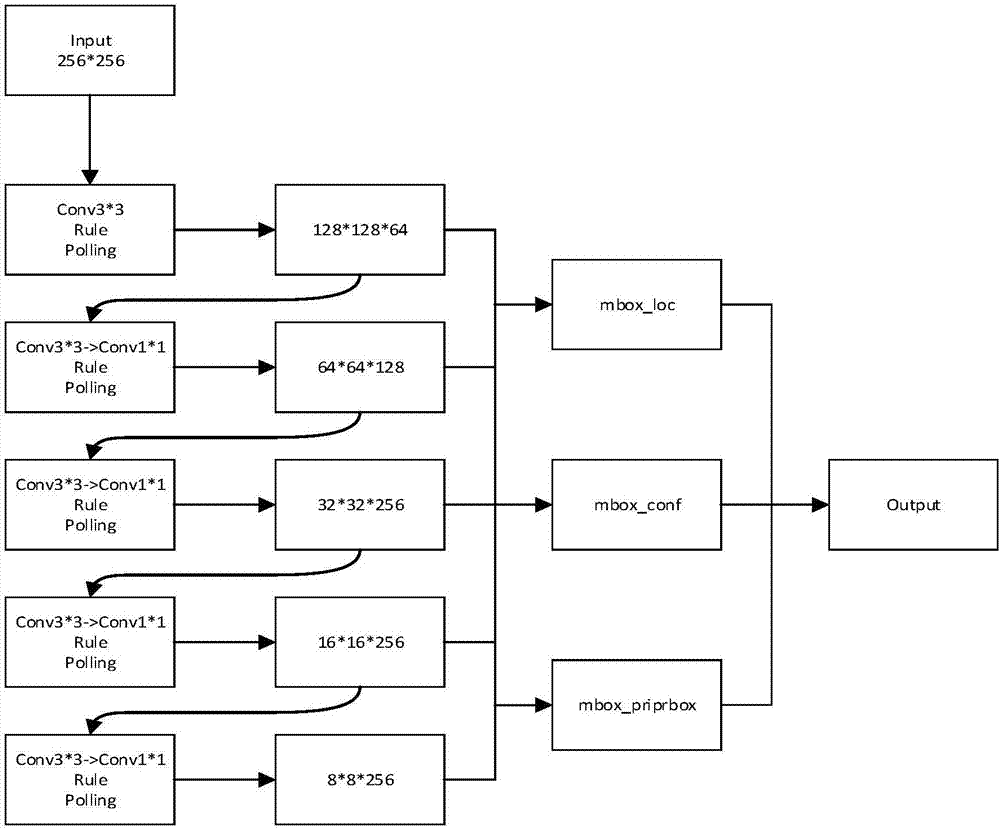
更进一步的,步骤202)所述根据人车特征构建深度学习训练网络架构的方法包括:构建的网络分为特征提取与多融合检测两部分,特征提取网络从第二层开始采用conv3*3与conv1*1的交替的卷积网络结构,将一层得到的64个featuremap,分成两组每组各32个,将第二层的128个3*3的filter也分成两组,各自与对应的featuremap做卷积运算,然后用1*1的filter将两组卷积运算得到的featuremap串联起来得到新的featuermap作为检测层和下一层卷积的输入,后面层计算方式与此相同,多融合检测部分收集不同尺寸的featuremap,利用预测框的位置(x,y,w,h)与置信度confidence跟真实值的位置进行计算损失,得到mbox_loss,最终输出使得损失值最小的(x,y,w,h)与confidence,并通过输出的confidence向量判断目标框所属的类别。
本发明的另一方面,还提供了一种基于准确人车分离的警戒装置,包括:
扣取模块,用于利用背景建模技术获取警戒区域中的运动区域,使用团块检测方法确定出候选区域,根据候选区域扣取送检图像的roi;
深度学习模块,用于将扣取的送检图像送入训练好的深度学习检测网络,对图像中的人、车进行检测和识别,输出其外接矩形、类别以及置信度。
进一步的,所述扣取模块具体用于:利用背景建模技术得到前景图像,使用团块检测方法,把相邻的前景点进行目标融合,并取其外接矩形作为运动团块,并根据运动团块的尺寸比以及团块内前景点数占总像素数的比例排除掉与人、车差异较大的团块,把剩下的作为作为候选区域,根据候选区域扣取送检图像。
进一步的,所述深度学习模块包括:
数据集单元,用于构建人车训练数据集;
架构单元,用于根据人车特征构建深度学习训练网络架构;
训练单元,用于配置训练参数开始训练;
检测单元,用于使用训练模型对人车进行检测。
更进一步的,数据集单元具体用于:从海量警戒相机抓拍图像中,获取不同角度、不同光照情况下具有触发警戒报警条件的人、车图像,将原始1920x1080像素图像缩放到1080x720、540x360,得到三组多尺度图像,对每副图像以最小边作为边长,分别对每一张图像从左右截取两张正方形图像作为训练图像,随后使用标注工具在图像中标注人、车的位置和类别,生成xml格式的标注文件,将图像保存作为数据集,取80%的数据作为训练数据集,其余数据作为测试集。
更进一步的,架构单元具体用于:构建的网络分为特征提取与多融合检测两部分,特征提取网络从第二层开始采用conv3*3与conv1*1的交替的卷积网络结构,将一层得到的64个featuremap,分成两组每组各32个,将第二层的128个3*3的filter也分成两组,各自与对应的featuremap做卷积运算,然后用1*1的filter将两组卷积运算得到的featuremap串联起来得到新的featuermap作为检测层和下一层卷积的输入,后面层计算方式与此相同,多融合检测部分收集不同尺寸的featuremap,利用预测框的位置(x,y,w,h)与置信度confidence跟真实值的位置进行计算损失,得到mbox_loss,最终输出使得损失值最小的(x,y,w,h)与confidence,并通过输出的confidence向量判断目标框所属的类别。
与现有技术相比,本发明具有如下的有益效果:
本发明对目标类别的判别以及位置的精确定位具有较强的鲁邦性,也可准确的过滤掉非人、车引起的警戒报警。
附图说明
图1是本发明实施例的深度学习训练网络架构示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
本发明提出一种基于准确人车分离的警戒方法,其技术方案包括以下步骤:
1.利用背景建模技术获取警戒区域中的运动区域,使用团块检测方法确定出候选区域,根据候选区域扣取送检图像的roi;
2.将扣取的送检图像送入训练好的深度学习检测网络,对图像中的人、车进行检测和识别,输出其外接矩形、类别以及置信度;
所述步骤1中利用背景建模技术得到前景图像,使用团块检测方法,把相邻的前景点进行目标融合,并取其外接矩形作为运动团块。设矩形运动团块表示为(x,y,w,h),前景图像对应区域含有前景点数n1,总像素点数n2,则选择符合以下条件的团块作为作为候选区域,根据候选区域扣取送检图像;
0.15<(w/h)<2且(n1/n2)>0.3
所述步骤2中将扣取的送检图像送入训练好的深度学习检测网络,对图像中的人、车进行检测和识别,输出其外接矩形、类别以及置信度。具体实施如下:
1)构建人车训练数据集;
为使模型具有良好的范化能力,适应各种场景,从海量警戒相机抓拍图像中,获取不同角度、不同光照情况下具有触发警戒报警条件的人、车图像,由于采集的警戒图像多为(1920x1080)像素的图像,为增强网络模型的多尺度识别能力,将原始图像缩放到(1080x720)、(540x360)得到三组多尺度图像,同时为方便网络训练,对每副图像以最小边作为边长,分别对每一张图像从左右截取两张正方形图像作为训练图像,随后使用标注工具在图像中标注人、车的位置和类别,生成xml格式的标注文件,将图像保存到jpegimages文件夹,xml标注文件放入annotations文件夹,作为数据集,取80%的数据作为训练数据集,其余数据作为测试集;
2)根据人车特征构建深度学习训练网络架构;
如图1,构建的网络分为特征提取与多融合检测两部分,特征提取网络从第二层开始采用conv3*3与conv1*1的交替的卷积网络结构,将一层得到的64个featuremap,分成两组每组各32个,将第二层的128个3*3的filter也分成两组,各自与对应的featuremap做卷积运算,然后用1*1的filter将两组卷积运算得到的featuremap串联起来得到新的featuermap作为检测层和下一层卷积的输入,后面层计算方式与此相同,多融合检测部分收集不同尺寸的featuremap,利用预测框的位置l(x,y,w,h)(mbox_loc的输出)与置信度confidence(mbox_cof的输出)跟真实值g(x,y,w,h)进行计算损失,得到mbox_loss,计算公式为:
其中p表示目标所属类别,
最终输出使得损失值最小的(x,y,w,h)与confidence,并通过输出的confidence向量判断目标框所属的类别。
3)配置训练参数开始训练;
网络输入参数的调整对模型的准确率和召回率改善至关重要,主要调整的网络输入参数有图像预处理参数,对图像做亮度、色度、饱和度的调整达到数据增强的目的,以及训练参数batchsize、学习率,通过反复训练得到bachsize的最佳值,训练过程中学习率采用自适应调整的方法,调整公式。
d为常数取10-5
4)用训练模型对人车进行检测;
使用训练好的模型对送检图像检测输出送检图像中人或车的位置(x,y,w,h)与置信度。保留尺寸合适以及置信度达到阈值的目标作为输出。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!