基于互联网的金融风险线索发掘方法与流程
本发明涉及网络搜索技术,特别涉及基于互联网的金融风险线索发掘方法。
背景技术:
在国内金融风险缺乏监管、金融风险监管目标不定、可监管来源不足的情况下,各监管单位很难去有效尽早发现风险目标。可疑线索往往在互联网上比比皆是,而传统人为收集线索效率极低,易引发大范围金融风险。如果此问题不予解决,仅依靠传统人为收集可疑线索,使得分辨金融风险能力远远跟不上金融风险爆发速度,将会导致中国互联网金融风险“雷暴式”崩溃,对人民群众、对国家都将造成巨大危害。
现有监管中,最多实现的仍是对人为既定收集的线索进行后期相关数据采集,主要是通过人为设置目标列表实时监测。其中虽然也使用了网络爬虫等技术,但是无法做到前期挖掘与发现,纯属于事后工作,所以无法解决线索发掘问题。
技术实现要素:
本发明要解决的技术问题是,克服现有技术中的不足,提供一种基于互联网的金融风险线索发掘方法。
为解决上述技术问题,本发明采用的解决方案是:
提供一种基于互联网的金融风险线索发掘方法,包括以下步骤:
(1)通过互联网中记载历史金融风险案件的舆情文章,获取金融风险正负面关键词;
(2)设置广搜辞典和金融风险相关正面宣传词典,调取互联网搜索引擎;
(3)利用搜索引擎推荐的热词,分割金融风险线索;
(4)利用金融风险相关负面风险词典,确认在关键目标主体舆情文章中的出现频度,确定金融风险线索可靠度;
(5)通过关键目标准确度,优化正面宣传词典和负面风险词典。
本发明中,所述步骤(1)具体包括:
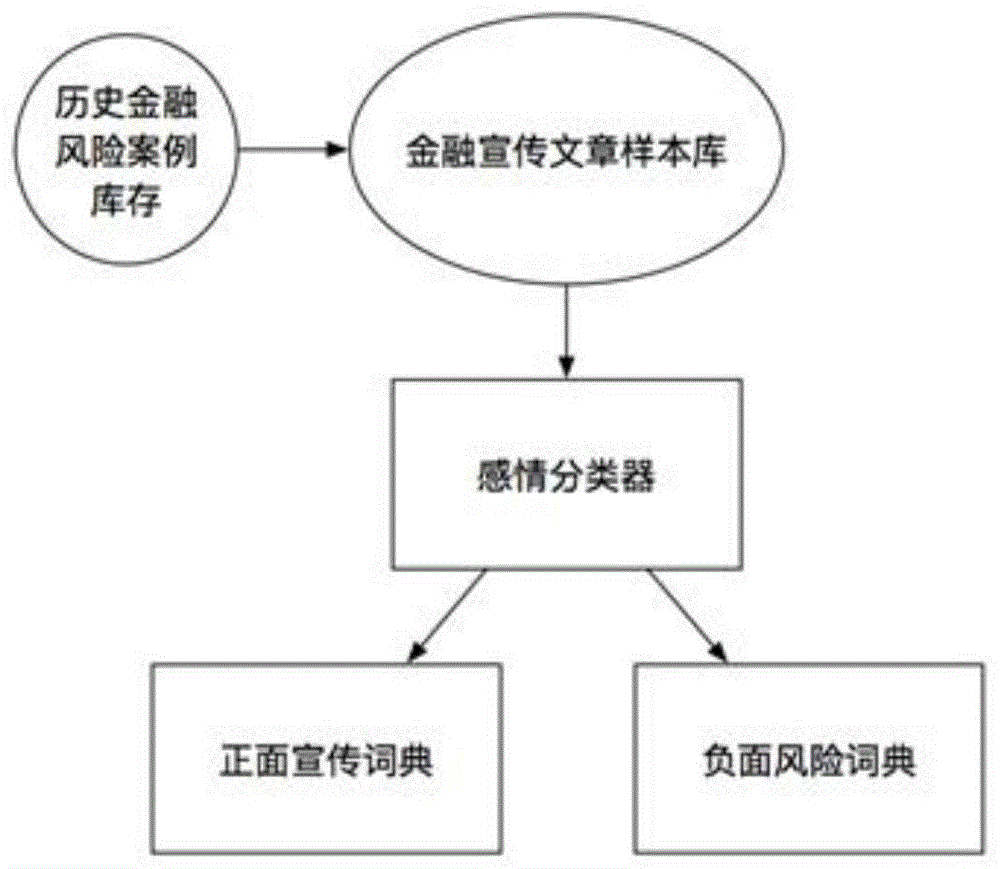
a)建立历史案件库存,其内容是现有历史金融风险案件(可以是任何现有案例的集合),至少需要包含风险目标网站的页面内容和风险目标在公众中的常用名称;
b)利用风险目标在公众中常用名称或风险目标网站页面内容,通过搜索引擎获取相关金融风险舆情文章,汇总得到金融宣传文章样本库;
c)利用感情分类器对金融宣传文章样本库的内容进行分析,对相关词语进行词频统计,取出权重靠前的词语,并区分情感正面词语和情感负面词语;
d)对获得的情感正面词语和情感负面词语进行分类存储(存储形式不局限于文本、数据库),得到正面宣传词典和负面风险词典。
本发明中,所述步骤(2)具体包括:
e)设置广搜辞典,并根据搜索引擎的搜索语法设置遍历规则;调取互联网搜索引擎,对金融风险相关的正面宣传词典中的各个词语进行遍历;
f)以页面解析装置获取遍历过程中各搜索引擎推荐的搜索热词,对获得的推荐结果进行数据存储(存储形式不局限于文本、数据库)。
本发明中,所述步骤(3)具体包括:
g)将正面宣传词典中的词语从引擎推荐的搜索热词中拆解删除,留下金融风险线索目标,并将结果进行数据存储(存储形式不局限于文本、数据库)。
本发明中,所述步骤(4)具体包括:
h)利用金融风险线索目标,通过搜索引擎在互联网中搜寻相关的文章;
i)遍历负面风险词典,根据多个风险词出现的频次计算每篇文章的权重;再整合全部文章的风险权重,得到该条金融风险线索的权重;
j)制定权重线,将权重线设置在能排除99%错误无关词语的权重上,对金融风险线索的风险程度进行评估;
k)将获取的结果作为值得关注金融风险线索进行数据存储(存储形式不局限于文本、数据库)。
本发明中,所述步骤(5)具体包括:
l)长时间持续运行步骤(1)至(4)的操作后,得到积累了正确样本案件的有效线索集合;
m)统计正面宣传词典的命中率,为每个目标关联的正面宣传词语添加一个权重;
n)统计负面风险词典命中率,为每个目标关联的负面风险词语添加一个权重;
o)将正面宣传词典和负面风险词典中的各词语按权重进行梯度排序后,设置词典准确线用于划分词语,淘汰词典准确线以下的词语;
p)利用词典准确线进行词语定期淘汰,得到更好的正面宣传词典和负面风险词典。
与现有技术相比,本发明的技术效果是:
1、本发明可以减少传统人为收集线索的工作量,快速发现线索,提高金融监管效率,减少大范围金融风险爆发可能。
2、本发明能够解决人力分辨金融风险能力远远跟不上金融风险爆发速度的问题,为金融监管、处置部门提供高效的监管工具。
附图说明
图1为字典初始化设置阶段的工作流程图;
图2为搜索引擎推荐分析阶段的工作流程图;
图3为目标主体分离阶段的工作流程图;
图4为舆情主体明确阶段的工作流程图;
图5为评分优化字典阶段的工作流程图。
具体实施方式
本发明利用到的部分术语说明:
搜索引擎技术背景:搜索引擎(searchengine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。搜索引擎在大量分析用户数据的情况下,会计算用户最新最关注的内容、最相关的内容、互联网搜索最多的内容,来满足用户的扩展搜索。
网络爬虫技术背景:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。实现网络爬虫使用的编程语言多样,也衍生出了大量插件可供使用。
正则表达式:又称规则表达式(英语:regularexpression,在代码中常简写为regex、regexp或re),属于计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。格式化文本内容经常以此类方式批量获取关注目标。
评分卡技术:评分卡有多种实现方法和优化手段,是机器学习的雏形。用以优化样本群,淘汰低命中率特征,提高命中率特征权重的技术。
负面风险词典:遍历负面风险词典,给每篇文章计算多个风险词出现的权重,再整合全部文章的风险权重,给此条金融风险线索计算一个权重。现有技术中权重评估算法极多。
搜索引擎文章获取:通过编程语言(不限于python、java等),通过金融风险线索在搜索引擎中搜寻相关的文章。
金融风险线索拆解:通过编程语言(不限于python、java等),将正面宣传词典中使用的词语从热词中拆解删除,留下金融风险线索。
页面解析装置:通过编程语言(不限于python、java等),将各搜索引擎推荐热词收集,并将整面宣传词典中使用的词语从热词中删除,仅仅留下金融风险线索。
广搜词典:包含历年中英文常用单词、词句列表,不局限于中英文等语言,数量不定,不局限于每年权威或非正式统计词表。
感情分类器:现有成熟技术,能将舆情文章以及词语区分感情。感情分类器还有一个的功能,对相关词语进行词频统计,取出权重靠前词语,词频统计有成熟有效的方案。
下面结合附图,对本发明的具体实施方式进行详细描述。
本发明中基于互联网的金融风险线索发掘方法,包括以下步骤:
(1)通过互联网中记载历史金融风险案件的舆情文章,获取金融风险正负面关键词(即舆情文章字典初始化设置阶段);具体包括:
a)建立历史案件库存,其内容是现有历史金融风险案件,至少需要包含风险目标网站的页面内容和风险目标在公众中的常用名称;
b)利用风险目标在公众中常用名称或风险目标网站页面内容,通过搜索引擎获取相关金融风险舆情文章,汇总得到金融宣传文章样本库;
c)利用感情分类器对金融宣传文章样本库的内容进行分析,对相关词语进行词频统计,取出权重靠前的词语,并区分情感正面词语和情感负面词语;
d)对获得的情感正面词语和情感负面词语进行分类存储(存储形式不局限于文本、数据库),得到正面宣传词典和负面风险词典。
(2)设置广搜辞典和金融风险相关正面宣传词典,调取互联网搜索引擎(搜索引擎推荐分析阶段);具体包括:
e)设置广搜辞典,并根据搜索引擎的搜索语法设置遍历规则;调取互联网搜索引擎,对金融风险相关的正面宣传词典中的各个词语(可取两个,也可以取多个)进行遍历;
广搜词典包含历年中英文用单词、词句列表,不局限于中英文等语言,数量不定,不局限于每年权威或非正式统计词表。例如,可选择中国常用汉字三千字。
f)以页面解析装置(以编程语言实现,不限于python、java等)获取遍历过程中各搜索引擎推荐的搜索热词,对获得的推荐结果进行数据存储。
以百度为例,“+”符号代表“连接”的意思,此处“+”符号可选用空格代替。
(3)利用搜索引擎推荐的热词,分割金融风险线索(目标主体分离阶段);具体包括:
g)将正面宣传词典中的词语()从引擎推荐的搜索热词中拆解删除(以编程语言实现,不限于python、java等),留下金融风险线索目标,并将结果进行数据存储。
(4)利用金融风险相关负面风险词典,确认在关键目标主体舆情文章中的出现频度,确定金融风险线索可靠度(舆情主体明确阶段);具体包括:
h)利用金融风险线索目标,通过搜索引擎在互联网中搜寻相关的文章(以编程语言实现,不限于python、java等);
i)遍历负面风险词典,根据多个风险词出现的频次计算每篇文章的权重;再整合全部文章的风险权重,得到该条金融风险线索的权重;权重评估算法极多,此处可使用最简单的一种,按照词语出现次数进行加数操作。
j)制定权重线,将权重线设置在能排除99%错误无关词语的权重上,对金融风险线索的风险程度进行评估;
k)将获取的结果作为值得关注金融风险线索进行数据存储。
(5)通过关键目标准确度,优化正面宣传词典和负面风险词典(评分优化字典阶段)。具体包括:
l)长时间持续运行步骤(1)至(4)的操作后,得到积累了正确样本案件的有效线索集合;
m)统计正面宣传词典的命中率,为每个目标关联的正面宣传词语添加一个权重;
n)统计负面风险词典命中率,为每个目标关联的负面风险词语添加一个权重;
o)将正面宣传词典和负面风险词典中的各词语按权重进行梯度排序后,设置词典准确线用于划分词语,淘汰词典准确线以下的词语;例如,可将权重定为3(即至少三个有效线索使用到此词语)。
p)利用词典准确线进行词语定期淘汰,得到更好的正面宣传词典和负面风险词典。
作为示例的实例:
1.首先通过对已有的金融风险案件库a中的数百个金融风险目标的网站、金融风险目标名称进行分析。通过金融风险目标名称在搜索引擎上找到大量舆情文章;对舆情文章、金融风险网站进行第一步骤的碰撞分析,获取正面字典库y,负面字典库n。
2.选取广搜词典x,遍历广搜词典中元素x与正面词典中元素y,组合成搜索词“x(空格)y”,并在搜索引擎,例如百度上搜索。通过程序获取其下方九个推荐热词n1,存入库n1中
3.通过将库n1中的n1中的正面词典中元素y从推荐热词n1中分离,获取真实金融风险关键词n2,存入库n2中
4.通过n2库中的关键词,去搜索引擎上直接搜索,通过第四步爬取前十篇相关文章,并统计负面字典库n中词语在文章中出现权重,如果一篇文章有则权重加一,满足十篇文章皆有负面字典库n中词语的关键词才进入金融风险目标库z,其余丢弃
5.为每个正面字典库y和负面字典库n中的元素y和n设置一个权重,每次由此关键词成功通过了一个金融风险z,则为这个y或n权重加一。持续运行一段时间后,淘汰权重最低的y或n。
- 还没有人留言评论。精彩留言会获得点赞!