一种从中文临床记录学习高质量词嵌入的方法与流程
本发明属于自然语言处理技术领域,更具体地涉及一种结合相关领域与非相关领域从中文临床记录学习高质量词嵌入的方法。
背景技术:
高质量的词嵌入对于提高生物医学的自然语言处理应用有非常重要的意义。在最近几年,人们对于如何学得高质量的词嵌入以及基于英文医学文本评估词嵌入产生了浓厚的兴趣,并且这一现象已经变的越来越明显。然而基于中文医学文本的研究数量十分有限,特别是中文临床记录的研究被显现出来。基于此,我们提出了一种提高学习词嵌入质量的新方法,这种方法在中文临床记录有限的情况下使用领域外的数据作为补充。此外,在医学概念的相似性的基础上对于词嵌入进行评估。
词嵌入其已经被广泛应用与大量的自然语言处理任务,并且作为近年来的一个热门话题,从英文医学文本当中学习词嵌入,已经被广泛的研究过,这是由于开放数据集的优势,例如,umlsofnlm(bodenreider,2004),pubmed的医学期刊摘要(choietal.,2016a),以及一些已经发布的临床数据(finlayson,etal.,2014;stubbsanduzuner,2015)。这些数据集被广泛地用作生物医学自然语言处理领域的黄金标准用于学习词嵌入(devineetal.,2014;choietal.,2016b)。
然而,从中文医学文本中学习词嵌入的发展已经远远落后,尤其是中文的临床记录。由于对于隐私的考虑,能被使用的中文临床记录十分有限。基于神经网络架构,我们能够学习到更好的词嵌入,例如,广泛使用的skip-gram模型(mikolovetal.,2013a),通常需要大量的训练数据。因此,学习更好的词嵌入,中文临床记录的数量是不够的。
此外,就我们所知,只有数量有限的研究从中文临床记录当中学习词嵌入,更不用说词嵌入的评估了;许多方法已经被适用于从英文医学文本当中学习词嵌入,然而,中文的医学文本,特别是临床记录,具有其独特的语言特征。因此,从中国临床记录中学习词嵌入的方法,迫切需要从英语医学文本中学习的方法。
技术实现要素:
针对上述背景技术中存在的问题,本发明提出了一种从中文临床记录学习高质量词嵌入的方法,其构思合理,在仅仅拥有有限的中文临床记录的情况下,可以结合领域内以及领域外的数据并且通过skip-gram模型从中文临床记录中学得更好的词嵌入。
本发明的技术方案如下:
上述的从中文临床记录学习高质量词嵌入的方法,其包括以下步骤:(1)通过skip-gram模型从中文临床记录学习词向量;(2)使用领域外数据;(3)嵌入中医临床记录学习词的通用框架,提出从中医临床记录学习词嵌入的通用框架;(4)对学习到的新嵌入进行评价,提出对学得词嵌入的评价方法。
所述从中文临床记录学习高质量词嵌入的方法,其中,所述步骤(1)的具体过程为:选定一个数据集d,在数据集d中给定一个训练单词的集合w1,w2,...,w|v|,通过所述skip-gram模型让以下目标j最大化,即
c是数据集d中wi的唯一的上下文单词的数量,并且基础的skip-gram公式定义p(wjwi)通过以下函数:
其中
所述从中文临床记录学习高质量词嵌入的方法,其中,所述步骤(2)的具体过程为:首先,直接应用所述skip-gram模型来学习来自中国临床记录数据集ccrd的嵌入,并且通过中医医学概念相似性度量cmcsm评估学习的嵌入;其次,应用所述skip-gram模型来学习不同组合比例的中国临床记录数据集ccrd和外部数据集odd组合嵌入。
所述从中文临床记录学习高质量词嵌入的方法,其中,所述步骤(3)的具体过程为:首先将领域内与领域外数据进行语义单元的抽取即中文分词并且对数据进行后处理,然后用所述skip-gram模型对进行中文分词以及后处理完成后的数据进行训练,最后将训练的结果进行评价。
所述从中文临床记录学习高质量词嵌入的方法,其中:所述中文分词是使用最新的斯坦福corenlp中文分词工具和默认设置来对中国临床记录进行中文分词,以获取文本中的语义单位;所述后处理是删除中国临床记录中的标点符号;
所述步骤(3)中通用框架包括语义单元采集模块和嵌入式学习模块;所述语义单元采集模块用于中文分词和后处理;所述嵌入式学习模块用于学习目标汉语词汇的嵌入,且学习目标汉语词汇包括医学术语和一般领域词汇;所述嵌入式学习模块的学习词嵌入方法采用skip-gram模型完成。
所述从中文临床记录学习高质量词嵌入的方法,其中:所述步骤(4)是通过中医医学概念相似性度量cmcsm来评估学习到的嵌入,所述中医医学概念相似性度量cmcsm被定义为如下:
其中,n是准备好的医学术语数据集中同一级医学术语的组数c,c是一组医学术语,cj和ck是第j个和第k个术语;sim(cj,ck)为who常用的嵌入相似性度量方式。
所述从中文临床记录学习高质量词嵌入的方法,其中:所述skip-gram模型的分层softmax用于嵌入训练过程,其上下文窗口的大小和嵌入的维度分别被设置为5和200。
有益效果:
本发明介绍了如何在有限的域内数据背景下利用外部数据补充中文临床记录来学习更好的嵌入。从医学概念相似性测度出发(choi等,2016b),应用中医医学概念相似性度量来评估嵌入的质量。实验结果表明,结合使用域外数据和域内数据可能会提高学习嵌入的质量;收集适量的域外数据,在嵌入质量和训练时间消耗之间进行权衡,选择好的训练样本是学习更好嵌入的关键因素。结果也证明,更多的数据并不一定带来更令人满意的结果,这与chiu等人的结果一致。
附图说明
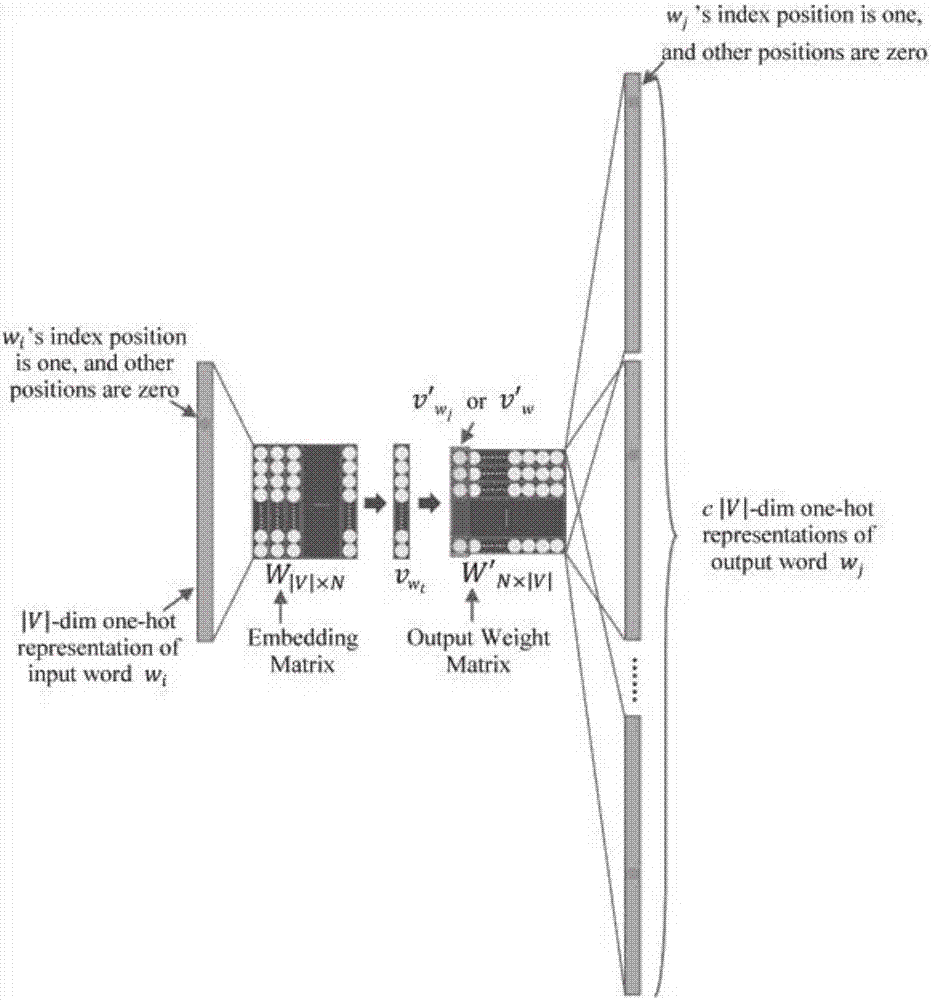
图1为本发明从中文临床记录学习高质量词嵌入的方法中的skip-gram模型图;
图2为skip-gram模型训练样本生成过程的一个样例;
图3为从中国临床记录学习词嵌入的一般框架;
图4为标准医学术语数据集smtd的一个案例。
具体实施方式
本发明从中文临床记录学习高质量词嵌入的方法,是结合相关领域与非相关领域从中文临床记录学习高质量词嵌入的方法,具体包括以下步骤:
(1)通过skip-gram模型(即跳格模型)从中文临床记录学习词向量;
skip-gram模型如图1所示,该skip-gram模型的训练目的是找到词向量,对于预测在一个序列当中的某个目标单词的上下文单词是很有用的,这个序列通常指的是特定学习任务中的一个句子。
具体过程为:选定一个数据集d,在数据集d中给定一个训练单词的集合w1,w2,...,w|v|,skip-gram模型为了让以下目标j最大化。
c是数据集d中wi的唯一的上下文单词的数量,并且基础的skip-gram公式定义p(wjwi)通过这个函数:
其中
在skip-gram模型中,如果两个不同的目标单词wk和wk′(即具有不同的单热表示的单词)具有(非常)相似的同义词,那么该skip-gram模型将输出(非常)类似于这两个目标单词的结果。换句话说,该skip-gram模型的softmax分类器需要给这两个目标词类似的上下文预测,这是因为常用的输出权重矩阵,这意味着这两个目标词将具有相似的嵌入vwk和vwk′;哈里斯(harris,1954)认为,出现在类似语境中的词具有类似的含义。
该skip-gram模型为使用deeplearning4j实现的skip-gram模型;其中,该skip-gram模型的分层softmax用于嵌入训练过程,其上下文窗口的大小和嵌入的维度分别被设置为5和200;该skip-gram模型的分层softmax被广泛用于从文本中学习嵌入,并且通常是学习最佳嵌入的最佳设置(choietal,2016b)。
(2)使用领域外数据;
首先,直接应用skip-gram模型来学习来自中国临床记录数据集ccrd的嵌入,并且通过中医医学概念相似性度量cmcsm评估学习的嵌入;其次,应用skip-gram模型来学习不同组合比例的中国临床记录数据集ccrd和外部数据集odd(实验当中有介绍)组合嵌入。
根据上述步骤(1)中skip-gram模型的介绍,可以总结出,如果两个单词在训练语料库中具有相似的上下文,那么skip-gram模型就有动机学习这两个单词的相似嵌入。换句话说,要更清楚地区分两个单词需要更多的证据,即添加不同的上下文单词来说明要区分的单词之间的区别。
因此,提出一个假设:将领域数据即通用领域中文文本添加到中文临床记录也就是领域数据中将有助于从中文临床记录中学习临床数据。这意味着中国临床记录中的医学术语具有特定领域的用途,但并未广泛用于域外数据。然而,一般的域名在外域数据中有着广泛的用途,这与使用医学术语相反。将域外数据与中国临床记录相结合,可以改善一般域词的上下文词的多样性,但没有损害医学术语上下文的副作用。反过来,可以从组合数据中学习更好的嵌入。
(3)嵌入中医临床记录学习词的通用框架,提出从中医临床记录学习词嵌入的通用框架;
首先,将领域内与领域外数据进行语义单元的抽取即中文分词,并且对数据进行后处理,然后用skip-gram模型对进行中文分词以及后处理完成后的数据进行训练,最后将训练的结果进行评价。
上述步骤(3)中的通用框架包括语义单元(即目标汉语单词)采集模块和嵌入式学习模块。
该语义单元(即目标汉语单词)采集模块用于中文分词和后处理;其中,中文分词是使用最新的斯坦福corenlp中文分词工具和默认设置来对中国临床记录进行中文分词,以获取文本中的语义单位;后处理为删除中国临床记录中的标点符号。此外,出现在准备好的标准术语数据库中的相邻单词不会被分割;后处理过程被用来提高中文分词的开放域工具的性能,这可能会影响学习嵌入的质量(zhangetal.,2016)。
该嵌入式学习模块用于学习目标汉语词汇的嵌入,且学习目标汉语词汇包括医学术语和一般领域词汇;该嵌入式学习模块的学习词嵌入方法采用skip-gram模型完成。
与其他关于医学文本学习嵌入的研究不同,上述步骤(3)中通用框架中的训练数据不仅来自中国的临床记录,而且还结合了通用域数据,用于为一般域词提供不同的上下文信息中国的临床记录。由于中国临床记录数量有限,为了避免双向数据分布问题,只有将适量的外域数据与中国临床记录相结合才能获得更好的嵌入。实验结果显示,当外域数据量为中国临床记录基础大小的1000倍时,可以实现最佳嵌入。详细结果见实验结果。
(4)对学习到的新嵌入进行评价,提出对学得词嵌入的评价方法;
通过中医医学概念相似性度量cmcsm来评估学习到的嵌入,所述中医医学概念相似性度量cmcsm被定义为如下:
其中,n是准备好的医学术语数据集中同一级医学术语的组数c,ci是一组医学术语并且属于c,cj和ck是在ci中的第j个和第k个术语;sim(cj,ck)是who常用的嵌入相似性度量方式(levyetal.,2015),使用协同正弦测量,中医医学概念相似性度量cmcsm的值越高,获得的嵌入越好。
下面结合实验,对本发明的技术方案作进一步阐述。
实验以及实验结果如下:
为了验证所提出的方法的性能,本研究中使用了三个实验数据集,其中包括从成都中医药大学教学医院收集的中国临床记录数据集(ccrd),一个大规模的外部数据集(odd)从nlpcc2018共享任务42获得,以及标准医学术语数据集(smtd)。
表1列出了这些数据集的详细信息。
表1实验数据集的详细信息。
本发明使用deeplearning4j实现的skip-gram模型,该skip-gram模型的分层softmax用于嵌入训练过程,其上下文窗口的大小和嵌入的维度分别被设置为5和200;该skip-gram模型的分层softmax被广泛用于从文本中学习嵌入,并且通常是学习最佳嵌入的最佳设置(choietal,2016b)。
首先,直接应用skip-gram模型来学习来自ccrd的嵌入,并且通过cmcsm评估学习的嵌入;此外,从ccrd采样5个子数据集,以评估不同大小的数据集对学习嵌入质量的影响;采样数据集的大小分别是原始ccrd中实例的80%,60%,40%,20%和10%;抽样过程是一个无需替换的递归抽样;此外,运行了上述过程10次以进一步评估结果的稳定性;结果被用作基线并且被显示在表2中。
表2skip-gram模型从ccrd中学习嵌入的cmcsm结果。
在表2中发现,越多的中国临床记录被用于学习嵌入,cmcsm结果的偏差越小。这意味着更多的数据意味着更加稳定的嵌入学习结果。此外,一个有趣的结果是,所有中国临床记录的使用不一定导致最高质量的嵌入。这意味着如果只使用域内数据来学习嵌入,应该收集尽可能多的训练数据,并从收集的数据中选择有用的样本。
其次,应用skip-gram模型来学习不同组合比例的ccrd和odd组合嵌入。结果列于表3,表明通过将odd结合到ccrd中,在不同条件下学习的嵌入的质量得到显着改善;此外,odd的更多数据被结合到ccrd中,将会学习更好的嵌入。在最好的情况下(将“t2-60%”数据集与“odd-all”数据集相结合),cmcsm增加了3.8倍。
表3skip-gram模型从ccrd和odd的组合中获得的嵌入cmcsm结果。“tn-x%”表示“数据集是ccrd的x%数据,用于学习tn表2中嵌入的最高质量”,“ccrd-all”表示使用ccrd中的所有实例。“odd-n”表示“当前使用的odd的大小是”n“×2505。”“odd-all”是指使用odd中的所有样本。2505是ccrd的基本规模,其大约等于ccrd的10%。
值得注意的是,当使用odd中的所有数据时,并不总能获得表3每一行中学习嵌入的最高质量。这个结果与前面提到的结果一致,表明应该尽可能多地收集用于学习嵌入的数据,并且需要注意合理选择训练样本。另外,结果表明,当odd的量是ccrd的基础尺寸的1000倍时,将实现最佳嵌入。
此外,结果表明,在实践中,应该考虑嵌入质量和训练时间消耗之间的折中。图4显示随着组合的odd数据量的增加,从ccrd的基础大小学习的嵌入的cmcsm的增长率急剧下降。此外,当组合的odd数据的量超过基准尺寸的50倍时,增长率几乎收敛。虽然,正如所知,用跳跃模型学习嵌入的数据越多,消耗的时间也就越多。因此,应该考虑花费大量培训时间来换取质量改善很少的情况是否值得。此外,质量改善小有时可能不会提高下游生物医学应用的性能。
本发明构思合理,在仅仅拥有有限的中文临床记录的情况下,可以结合领域内以及领域外的数据并且通过skip-gram模型从中文临床记录中学得更好的词嵌入。
- 还没有人留言评论。精彩留言会获得点赞!