流式数据列存储方法、装置、设备和存储介质与流程
本发明涉及流式数据存储领域,尤其涉及一种流式数据列存储方法、装置、设备和存储介质。
背景技术:
近年来,随着互联网的迅猛发展,数据的快速增长成了许多行业共同面临的机遇与挑战。在当今网络环境下,大量数据源是实时的,不间断的,要求对用户的响应时间也是实时的。这些数据以流式的形式被采集、计算与查询,如实时消息系统,对流入的数据均采取流式方式处理。其每时每刻都有各式各样的、海量的网络数据流入,流入速度各异,且数据结构复杂多样,包括二进制文件、文本文件、压缩文件等。对于此类系统,需要底层存储系统能够支持:对流入的数据以统一格式存储,对上层应用提供统一接口,方便检索,并且对实时性也有一定要求。
针对现今的大数据趋势,涌现了一批大数据处理平台,比如kafka,flume等。具体为前置应用把消息通过流式的方式输入到消息队列中,然后消息队列再通过某种形式把这些数据写入到磁盘,比如hdfs,或者本地磁盘。
由于实时消息系统的流式处理形式,使得消息最终都是以行存储的形式写入磁盘,比如json,或者普通文本。而在大数据处理中,很多情况下需要数据以列存储的形式进行保存,这时候传统的flume等工具就无法满足需求。
技术实现要素:
有鉴于此,有必要针对现有实时消息系统中的数据均是以行存储的形式写入文件系统,而不是以列存储的形式写入文件系统,提供一种流式数据列存储方法、装置、设备和存储介质。
一种流式数据列存储方法,包括如下步骤:
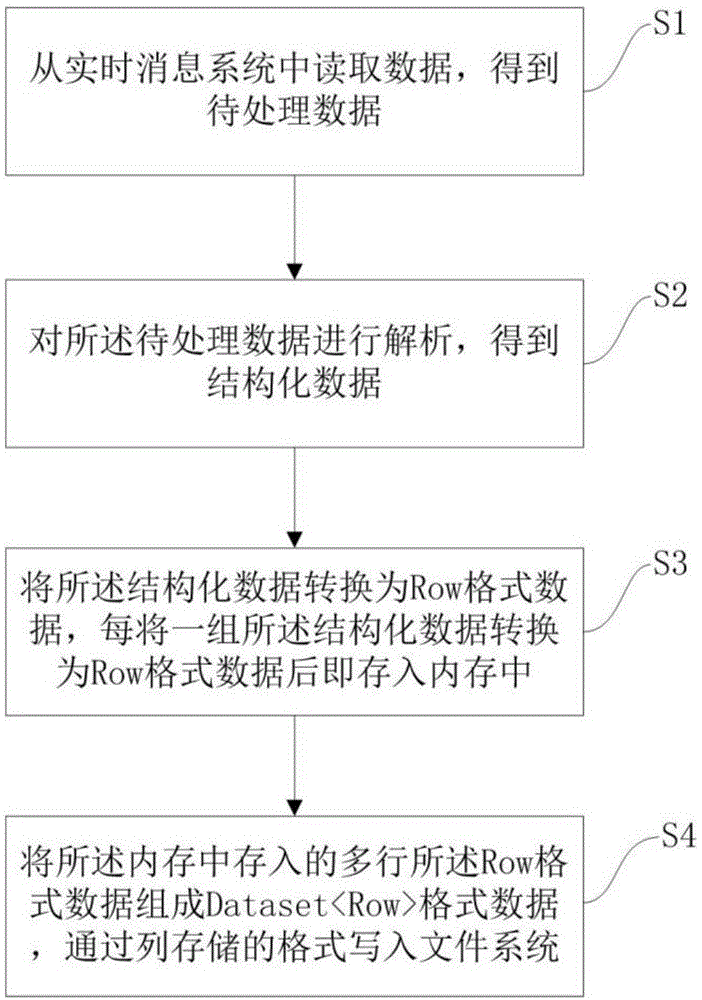
从实时消息系统中读取数据,得到待处理数据;
对所述待处理数据进行解析,得到结构化数据;
将所述结构化数据转换为row格式数据,每将一组所述结构化数据转换为
row格式数据后,即存入内存中;
将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,
通过列存储的格式写入文件系统。
在其中一个实施例中,所述从实时消息系统中读取数据,得到待处理数据,包括:
获取所述实时消息系统的访问权限,并连接到所述实时消息系统;
设定执行周期,按照所述执行周期从所述实时消息系统中读取数据。
在其中一个实施例中,所述对所述待处理数据进行解析,得到结构化数据,包括对所述待处理数据的格式进行判断后,按照判断结果采用不同的方法进行解析,具体包括:
若所述待处理数据为json格式,则调用fastjson将所述json格式的待处理数据解析为所述结构化数据;
若所述待处理数据为csv格式,则根据所述待处理数据的内容,并通过dataframe()方法给所述csv格式的待处理数据添加结构化信息,得到所述结构化数据。
在其中一个实施例中,所述将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,通过列存储的格式写入文件系统,包括:
通过数据框架的方法将多行所述row格式数据组成所述dataset<row>格式数据;
通过parquet()将所述dataset<row>格式数据转换为parquet格式数据,并使用spark.read()将parquet格式数据写入文件系统。
在其中一个实施例中,所述设定执行周期,按照所述执行周期从所述实时消息系统中读取数据,包括:
从所述实时消息系统中第一条数据所在位置开始读取;
接收读取完毕的指令,停止读取,并记录读取完毕的位置;
获取上次读取完毕的位置,从上次读取完毕的位置开始读取,直到接收到读取完毕的指令,停止读取,并记录读取完毕的位置。
在其中一个实施例中,所述若所述待处理数据为json格式,则调用fastjson将所述json格式的待处理数据解析为所述结构化数据,包括:
提取所述json格式的待处理数据的字段信息;
根据所述字段信息对所述json格式的待处理数据进行排序,得到所述结构化数据。
在其中一个实施例中,所述将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,通过列存储的格式写入文件系统之后,还包括:
根据所述待处理数据的列信息对存储路径进行分割;
调用partitionby()函数,将所述待处理数据中列名相同的列,按照所述列中不同的值存储于不同目录。
一种流式数据列存储装置,包括如下模块:
数据获取模块,设置为从实时消息系统中读取数据,得到待处理数据;
数据解析模块,设置为对所述待处理数据进行解析,得到结构化数据;
数据转换模块,设置为将所述结构化数据转换为row格式数据,每将一组所述结构化数据转换为row格式数据后,即存入内存中;
数据存储模块,设置为将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,通过列存储的格式写入文件系统。
一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被一个或多个所述处理器执行时,使得一个或多个所述处理器执行上述流式数据列存储方法的步骤。
一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个所述处理器执行上述流式数据列存储方法的步骤。
上述流式数据列存储方法、装置、设备和存储介质,包括:设定执行周期,并按照执行周期从实时消息系统中读取数据,得到待处理数据;对所述待处理数据进行解析,得到结构化数据;将所述结构化数据转换为row格式数据,每将一组所述结构化数据转换为row格式数据后,即存入内存中;将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,通过列存储的格式写入文件系统。本技术方案通过sparkstreaming对实时消息系统中的流式数据进行处理,解决了当前无法把实时消息系统中的流式数据保存为列存储格式的问题,极大地提高了后续对大量数据处理的速度,也节省了把行存储结构转换为列存储结构的时间,使用sparkstreaming作为计算框架,极大地利用分布式计算提高了转换和存储性能。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。
图1为本发明的一种流式数据列存储方法的整体流程图;
图2为本发明的一种流式数据列存储方法中的数据获取过程的示意图;
图3为本发明的一种流式数据列存储方法中的数据解析过程的示意图;
图4为本发明的一种流式数据列存储方法中的数据存储过程的示意图;
图5为本发明的一种流式数据列存储装置的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
图1为本发明的一种流式数据列存储方法的整体流程图,如图1所示,一种流式数据列存储方法,包括以下步骤:
步骤s1,从实时消息系统中读取数据,得到待处理数据。
其中,本发明的一种流式数据列存储装置主要包括sparkstreaming程序,本发明主要依托sparkstreaming对实时消息系统的流式数据进行处理,从而实现将实时消息系统中的流式数据转换为列存储的形式写入文件系统。实时消息系统中的数据为流式数据,实时消息系统也是流式数据的处理组件。
其中,sparkstreaming包括数据获取模块、数据解析模块、数据转换模块和数据存储模块。
上述步骤执行时,数据获取模块的其中一个子模块每隔一段时间发出数据获取指令,另一个子模块则接收上述数据获取指令,接收到数据获取指令后,执行指令,从实时消息系统中读取数据,得到待处理数据。
步骤s2,对所述待处理数据进行解析,得到结构化数据。
上述步骤执行时,数据获取模块将得到的待处理数据发送给数据解析模块,数据解析模块对待处理数据进行解析,并根据待处理数据的不同格式采用不同的方法进行解析。从实时消息系统中获取的数据,其数据结构复杂多样,包括二进制文件、文本文件、压缩文件等各种格式的数据。数据解析模块接收到不同格式的待处理数据后,采用不同方法进行解析,最终将待处理数据统一解析为结构化数据,再发送给数据转换模块。
步骤s3,将所述结构化数据转换为row格式数据,每将一组所述结构化数据转换为row格式数据后,即存入内存中。
上述步骤执行时,数据转换模块将数据解析模块发来的结构化数据转换为row格式数据,暂时存入数据存储模块中。
在其中一个优选的实施例中,通过spark.createrow()将解析后的结构化数据转换为row格式数据。
其中,row格式是sparkstreaming自带的一种格式,并且row格式为一种带列信息的数据结构,其实质为一行数据。
步骤s4,将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,通过列存储的格式写入文件系统。
上述步骤执行时,经过数据转换模块转换好的row格式数据暂时存入数据存储模块,每隔一段时间,把累加的多行row格式数据组成dataset<row>格式数据,一次性以列存储的格式写入文件系统。
其中,dataset<row>格式是sparkstreaming自带的一种格式,dataset<row>格式是很多行row格式组成的矩阵,是row格式数据的有序集合,dataset<row>即为列信息结构,将dataset<row>格式的数据转换为列存储的格式即是数据以列的形式存在。
本实施例,通过sparkstreaming对实时消息系统中的流式数据进行解析处理,将每一条数据转换为sparkstreaming中的row格式数据,并将多行row格式数据合并累加暂时放到数据存储模块中,再组成dataset<row>格式一次性写入文件系统,解决了当前流式数据无法列存储的问题,使用sparkstreaming作为计算框架,提高了数据的转换和存储性能。
在一个实施例中,图2为本发明的一种流式数据列存储方法中的数据获取过程的示意图,如图2所示,一种流式数据列存储方法的数据获取过程,包括如下步骤:
步骤s101,获取所述实时消息系统的访问权限,并连接到所述实时消息系统。
上述步骤执行时,通过使用远程连接权限的用户名和密码获取所述实时消息系统的访问权限,并通过hibernate对象关系映射框架与所述实时消息系统进行连接。
步骤s102,设定执行周期,按照所述执行周期从所述实时消息系统中读取数据。
上述步骤执行时,设定sparkstreaming程序的执行周期,并将执行周期作为参数值传入sparkstreaming程序。
在其中一个优选的实施例中,也可以将执行周期作为固定值写在程序中,设定在sparkstreaming程序的配置参数中。
在其中一个优选的实施例中,执行周期可以设置为每次读取时间间隔相同,也可以根据实时消息系统数据流入速度的快慢设置为读取时间间隔不相同。
本实施例,将执行周期作为参数值传入sparkstreaming程序中,比较灵活,将执行周期作为固定值写在程序中,可以确保数值的安全性较高,而且执行周期可以根据实时消息系统数据流入速度的快慢灵活设置。
在一个实施例中,图3为本发明的一种流式数据列存储方法中的数据解析过程的示意图,如图3所示,一种流式数据列存储方法的数据解析过程,包括如下步骤:
步骤s201,若所述待处理数据为json格式,则调用fastjson将所述json格式的待处理数据解析为所述结构化数据。
上述步骤执行时,若从实时消息系统中获取的数据为json格式,使用相关库进行对其进行解析,在其中一个优选的实施例中,使用fastjson对其进行解析。
具体的,若从实时消息系统中获取的数据为{"id":0,"name":"alice","age":21}的json格式数据,其结构包括3个字段,分别为id、name和age,分别代表id、姓名和年龄。使用fastjson对其进行解析之后,则会解析为一个包含id,name,age的结构化数据,之后,再将解析之后的数据转换为sparkstreaming自带的row格式数据。
步骤s202,若所述待处理数据为csv格式,则根据所述待处理数据的内容,并通过dataframe()方法给所述csv格式的待处理数据添加结构化信息,得到所述结构化数据。
其中,不同于json和avro等格式的数据,csv格式的数据一般只包含数据信息,不包含结构信息。如上述步骤s201中提到的{"id":0,"name":"alice","age":21}的json格式数据,如果是csv格式,则其数据内容只有0,alice,21。这样格式的数据,无法通过数据内容确定每一列所表示的意思,需要根据用户对数据的认知,设定第一列为id,第二列为姓名,第三列为年龄,即根据数据的内容自行添加结构化信息,将数据解析为结构化数据,再将数据转换为row格式数据。
上述步骤执行时,通过spark.createdataframe(rowjavardd,type)方法来给数据添加结构化信息。其中,rowjavardd指的是数据信息,type为结构信息。
本实施例,对不同格式的数据采用不同的解析方法,使数据统一解析为结构化数据,再将数据转换为row格式数据,节省了数据处理的时间,且提高了数据处理的准确度。
在一个实施例中,图4为本发明的一种流式数据列存储方法中的数据存储过程的示意图,如图4所示,一种流式数据列存储方法的数据存储过程,包括如下步骤:
步骤s301,通过数据框架的方法将多行所述row格式数据组成所述dataset<row>格式数据。
在其中一个优选的实施例中,使用spark.createdataframe(rowjavardd,type)将多行row格式数据组成dataset<row>格式数据,其中,rowjavardd表示数据信息,type表示结构信息。
步骤s302,通过parquet()将所述dataset<row>格式数据转换为parquet格式数据,并使用spark.read()将parquet格式数据写入文件系统。
上述步骤执行时,使用spark.read().parquet(filename)将dataset<row>格式数据以parquet格式,写入文件系统。
上述步骤执行时,如果要以parquet格式进行列存储,使用parquet()将dataset<row>格式数据转换为parquet格式,具体的,使用parquet(filename)将dataset<row>格式数据转换为parquet格式,parquet是一种支持列式存储的文件格式。
上述步骤执行时,使用spark.read()将转换后的parquet格式的数据,写入文件系统。
本步骤中,还可以通过其他列存储格式将数据写入文件系统。
文件系统包括本地文件(file://)和hdfs(hdfs://),亦可包括其他spark所支持的其他文件系统,比如亚马逊s3(s3://)。一般是通过文件名来制定,比如要写入hdfs根目录下的data文件夹,则可以设置为hdfs:///data/。
本实施例,通过使用spark.createdataframe(rowjavardd,type)将多行row格式数据组成dataset<row>格式数据,使流式数据转换为列数据结构,为后续数据列存储打好基础。使用spark.read()将组成的dataset<row>格式的数据写入文件系统,实现了流式数据以列存储的格式写入文件系统。
在一个实施例中,按照所述执行周期从所述实时消息系统中读取数据,包括如下具体步骤:
从所述实时消息系统中第一条数据所在位置开始读取。
接收读取完毕的指令,停止读取,并记录读取完毕的位置。
获取上次读取完毕的位置,从上次读取完毕的位置开始读取,直到接收到读取完毕的指令,停止读取,并记录读取完毕的位置。
上述步骤执行时,当程序为首次读取数据时,则从实时消息系统中第一条数据所在位置开始读取,直到读取时产生的最新数据读取完,此时,会接收到读取完毕的指令,则停止读取,sparkstreaming自动记录下读取完毕的位置。
其中,首次读取数据是指第一次启动程序时的读取,sparkstreaming程序为永久运行,如果不暂停,可以一直运行下去。由于实时消息系统的数据是源源不断的被写入的,所以每次数据读取完毕时,由sparkstreaming记录下每次读取完毕的位置,以便下次读取。
以后每次读取数据时,获取上次读取完毕的位置,从上次读取完毕的位置开始读取,直到接收到读取完毕的指令,停止读取,并记录读取完毕的位置。
本实施例,每次读取完毕,都会记录下读取完毕的位置,便于下次读取,且不易出错,提高了数据获取的速度和质量。
在一个实施例中,调用fastjson将所述json格式的待处理数据解析为所述结构化数据,包括如下具体步骤:
提取所述json格式的待处理数据的字段信息;
根据所述字段信息对所述json格式的待处理数据进行排序,得到所述结构化数据。
从实时消息系统中获取的数据为{"age":21,"id":0,"name":"alice",}的json格式数据,使用fastjson将数据的字段信息提取出来,分别为age、id、和name,分别代表年龄、id和姓名。再根据字段信息对待处理数据进行排序,比如,排好序的数据结构为{"id","name","age"},则{"id","name","age"}即为结构化数据。
在一个实施例中,数据转换模块根据需要决定是否对解析后的结构化数据进行修改。若存储时需要按照年月日进行存储,若从实时消息系统中获取的数据含有时间戳,如“2017-09-2108:16:05.011”,而存储时需要按照年月日进行存储,则需要把时间戳中的年月日信息提取出来。
在一个实施例中,可以根据待处理数据的列信息对存储路径进行分割,通过partitionby()函数,将所述待处理数据中列名相同的列,按照所述列中不同的值存储于不同目录。
上述步骤执行时,通过spark.read().partitionby()对存储路径进行分割,比如参数填写为newdf.write().mode(savemode.append).partitionby("stream","year","month","day","hour").orc("orc"),指的是根据stream,year,month,day字段来进行路径的分割。
partitionby是分析性函数的一部分,它和聚合函数groupby不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partitionby用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,partitionby返回的是分组里的每一条数据,并且可以对分组数据进行排序操作。
本实施例,通过使用partitionby函数实现了对存储路径的分割,方便了后续对大量数据的处理。
一种流式数据列存储装置,如图5所示,包括如下模块:
数据获取模块,设置为从实时消息系统中读取数据,得到待处理数据;
数据解析模块,设置为对所述待处理数据进行解析,得到结构化数据;
数据转换模块,设置为将所述结构化数据转换为row格式数据,每将一组所述结构化数据转换为row格式数据后,即存入内存中;
数据存储模块,设置为将所述内存中存入的多行所述row格式数据组成dataset<row>格式数据,通过列存储的格式写入文件系统。
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行计算机可读指令时实现上述各实施例中所述的流式数据列存储方法的步骤。
在一个实施例中,提出了一种存储有计算机可读指令的存储介质,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例中所述的流式数据列存储方法的步骤。其中,所述存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明一些示例性实施例,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!