一种基于多核高斯分布的知识图谱表示方法与流程
本发明涉及深度学习技术领域,尤其是一种基于多核高斯分布的知识图谱表示方法。
背景技术:
近几年,人工智能和知识图谱的研究备受关注,将知识图谱作为一种已知的知识,结合各种深度学习算法以提升各种人工智能任务效果的方法亦是近几年的研究热点,如基于知识图谱的机器人系统。知识图谱的有效表达是对知识图谱进行研究和利用的基础工作,他能将杂乱的数据进行关联并整理成结构化知识提供给用户,这一特征决定了他在许多领域都会有重要的应用,例如现有的搜索引擎都是基于关键字匹配进行搜索的,而当知识图谱建立起来后,在输入某个关键词后,就可以返回这个关键词的属性,类别、以其他实体的关系等关联信息,这样可以更准确、完善的为用户提供所需要的信息,知识图谱是实现语义搜索、机器自动问答、互联网广告推荐、个性化电子阅读等一序列应用的基石,而是否能有效地对知识图谱进行有效的表示直接决定他在这些领域所发挥作用的大小。
将知识图谱映射到低维的向量空间使得我们可以方便的利用知识图谱的信息,而且已有的大量工作表明,对比其他方法,这种方法训练过程简单,效果更佳。现知识图谱的嵌入表示方法主要是将知识图谱的实体和关系映射为低维空间的一个点,再用平移距离模型和语义匹配模型进行学习。但实际上,一个实体可能具有不同的语义,比如,“苹果”既可能表示一个公司,也可能表示一种水果,这是两种完全不同的语义,只用一个点表示会造成语义信息混乱。语义经常是一个范围,比如,“音乐家”既表明这是一个人,也表明他是懂音乐的,在语义上,“音乐家”应该和“人”、“音乐”都是有交集的一个范围,只用一个点的表示可能会造成语义范围模糊。由于实体可能具有多语义性且语义具有范围,用一个确定的点来表示实体并不是很合理。而且,因此,找到一种既可以将知识图谱映射到低维的向量空间,又考虑到实体的多语义性和语义的范围属性的知识图谱表示方法对知识图谱的研究和利用有极大的价值。
技术实现要素:
针对现有技术的不足,本发明提供一种基于多核高斯分布的知识图谱表示方法,该方法能够充分地考虑实体的多语义信息和各种语义的语义范围。
本发明的技术方案为:一种基于多核高斯分布的知识图谱表示方法,包括负样本采样、
多核高斯分布的实体、关系表示,利用基于翻译思想的平移距离模型对实体和关系的表示进行学习,具体包括以下步骤:
s1)、负样本采样
s101)、针对知识图谱每一个三元组(源实体,关系,目标实体),在实体集合中随机选取实体以概率p替换源实体或者以1-p的概率替换目标实体构造负样本;
s2)、多核高斯分布的实体、关系表示
s201)、假定知识图谱中的每个实体有k个语义,每个语义用一个高斯分布表示,则每个实体用k个高斯分布表示,即
其中,psi表示第s个实体的第i个高斯分布,μsi表示第s个实体的第i个高斯分布的均值,∑si表示第s个实体的第i个高斯分布的协方差;
s202)、对于知识图谱中的每个关系r,用于一个高斯分布
s3)、实体和关系的表示的学习
s301)、采用基于翻译的思想学习实体、关系的嵌入表示,把关系r看成是源实体h到目标实体t翻译过程,即t=r+h;
s302)、采用kl距离度量法度量两个高斯分布之间的距离,即度量h-t的分布与关系r的分布距离;
s303)、采用pairwise方法训练实体、关系的潜入表示。
其中,上述方法中,步骤s101)中,p由知识图谱中每一个关系的源实体和目标实体的比例确定,并且在知识图谱中,每一个关系存在着一对一、一对多、多对一、多对多的属性,如果关系是一对多,替换源实体的概率p将会更大;如果关系是多对一,p则会更小;这种负样本采样方式会降低产生假阴性标签的概率。
本发明的有益效果为:通过使用多核高斯分布表示知识图谱中的每一个实体,考虑了实体具有多语义的特性和每一语义都具有语义范围的天然属性,在一定程度上解决了知识图谱中实体因为多语义特性引起的语义歧义的问题,也在一定程度上改进了传统方法没有考虑语义范围的缺点。同时,对比其他方法,这种方法训练过程简单,效果更佳。
附图说明
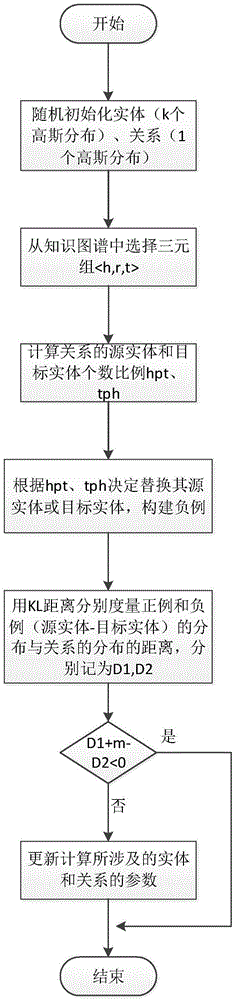
图1为本发明的流程示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
如图1所示,一种基于多核高斯分布的知识图谱表示方法,包括负样本采样、多核高斯分布的实体、关系表示,利用基于翻译思想的平移距离模型对实体和关系的表示进行学习,具体包括以下步骤:
s1)、随机初始化实体与关系,假设知识图谱由实体集合s=(s1,s2,...,sn)和关系集合r=(r1,r2,...,rz)组成,其中,n表示实体的个数,z表示关系的个数;
在知识图谱中,每一个事实用一个三元组(源实体h,关系r,目标实体t)表示;
在知识图谱中的每个实体有k个语义,每个语义用一个高斯分布表示,则每个实体用k个高斯分布表示,即
对于知识图谱中的每个关系r,用于一个高斯分布
s2)、初始化变量t=0,用于累计训练次数;初始化变量loss=0,用于计算损失值;
s3)、计算关系r的源实体h和目标实体t的比例,对于每一个关系r,计算每一个源实体h对应的目标实体t个数tph,计算每一个目标实体t对应的源实体h的个数hpt;
s4)、构造负例,从知识图谱中随机取出三元组(源实体h,关系r,目标实体t),以概率
s5)、计算正例<h,r,t>和负例<h′,r′,t′>的kl距离,从h,t,h′,t′的k个高斯分布中各选取一个分布,分布记为:
其中,ε(h,r,t)为样本(h,r,t)的(h-t)的分布与r的分布的距离,pr为关系r的分布,pe为(h-t)的分布,dkl(pe,pr)为pe,p的kl距离,x为μe,∑e每一维的值,μe为pe分布的均值,∑e为pe分布的协方差,μr为关系r的均值,∑r为关系r的协方差,tr(x)为x的迹,det(x)为x的行列式,(x)t表示x转置,ke为均值以及协方差的嵌入维度。
s6)、学习实体和关系的表示,如果d1+m-d2>0,则根据梯度方向传播算法更新正例<h,r,t>和负例<h′,r′,t′>中的实体和关系的参数,该算法的损失函数如公式:
loss=∑(h,r,t)∈τ∑(h′,r′,t′)∈τ′[ε(h,r,t)+m-ε(h′,r′,t′)]+公式(2)
其中,m为正负例的分割边界,τ为正样本集合,τ′负样本集合,ε(h,r,t)为正样本(h-t)的分布与r分布的距离,ε(h′,r′,t′)为负样本与(h′-t′)的分布与r′的分布的距离,
s7)、重复步骤s2)-s6),直至loss<l或t>t,其中,l,t分别为设置的损失值和训练次数。
上述实施例和说明书中描述的只是说明本发明的原理和最佳实施例,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 还没有人留言评论。精彩留言会获得点赞!