一种数据治理系统的制作方法
本发明涉及计算机数据处理技术领域,具体涉及一种数据治理系统。
背景技术:
随着信息技术的发展,使得众多的信息系统积累了海量的数据,对这些海量的数据来进行准确定位、分析、优化等操作可使得这些数据更好的服务于各类业务需求,可是很多数据并不是完全准确或规范的,这就增加了对数据的挖掘分析的难度,可能造成资源浪费、决策失误等。通常采用数据治理的方法对脏数据进行处理,得到标准干净数据,以供数据统计、数据挖掘等使用。
现有的很多数据治理方法需要人工的方式进行检查和更改数据,或者需要编写相应的计算机程序脚本对数据进行治理,以获得符合要求的数据。这种通过人工检查的方式耗时耗力,效率低下,当数据量庞大时,人工操作是无法满足数据治理需求的;而编写的计算机程序只能针对特定的脏数据的特定规则,不灵活,针对不同的数据源就需要编写不同的程序或脚本,工作量大,效率较低。
技术实现要素:
本发明实施例提供了一种数据治理系统,以克服现有技术中采用人工方式进行数据治理方法耗时耗力,效率低下,不能满足大量数据的治理要求的问题;并且克服编写计算机程序进行数据治理的方式,适用范围小、不灵活、工作量大、效率低等问题。
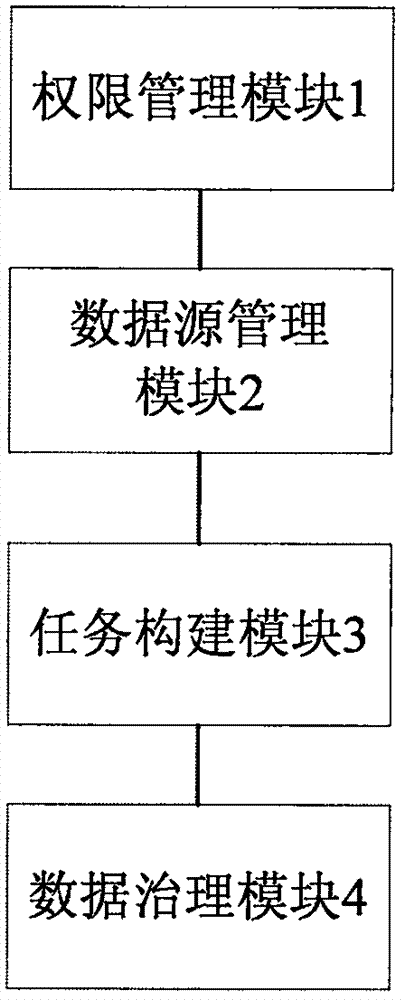
本发明实施例提供了一种数据治理系统,包括:权限管理模块、数据源管理模块、任务构建模块及数据治理模块,其中,所述权限管理模块对用户的身份信息进行验证,并根据验证结果授予用户操作权限;所述数据源管理模块从数据源数据库中获取待治理数据,并将所述待治理数据发送至数据治理模块;所述任务构建模块获取用户输入的数据治理要求,根据所述数据治理要求及所述用户操作权限为所述待治理数据构建数据治理任务;所述数据治理模块接收所述待治理数据,并根据所述数据治理任务对所述待治理数据进行数据治理,生成治理结果。
可选地,所述任务构建模块包括:治理模型选择子模块、治理模型构建子模块、治理任务构建子模块及存储子模块,其中,所述存储子模块用于存储多个预设治理模型;所述治理模型构建子模块根据所述数据治理要求构建新治理模型;所述治理模型选择子模块根据所述数据治理要求从所述新治理模型及所述多个预设治理模型中选择执行治理任务的各治理模型;所述治理任务构建子模块根据所述数据治理要求对所述执行治理任务的各治理模型生成所述数据治理任务。
可选地,所述数据治理任务包括:所述执行治理任务的各治理模型的执行顺序列表及执行时间信息。
可选地,所述数据治理模块包括:预处理子模块,用于接收所述待治理数据,并将所述待治理数据进行格式转换,生成标准数据;数据治理执行子模块,用于根据所述执行顺序列表及所述执行时间信息对所述标准数据进行数据治理,生成所述治理结果。
可选地,所述数据治理系统还包括:治理日志生成模块,根据所述数据治理模块对所述待治理数据的数据治理过程进行记录,生成数据治理日志。
可选地,所述数据治理日志包括:治理任务信息、治理时长信息、治理结果信息。
可选地,所述数据治理系统还包括:治理评价模块,根据所述数据治理要求对所述治理结果进行评价,生成评价结果;当所述评价结果为合格时,所述数据治理模块将所述治理结果发送至用户端。
可选地,当所述评价结果为不合格时,所述任务构建模块重新根据所述数据治理要求及所述用户操作权限为所述待治理数据构建新数据治理任务;所述数据治理模块根据所述新数据治理任务对所述待治理数据进行数据治理,生成新治理结果。
可选地,所述数据治理系统还包括:治理数据库,用于对所述治理结果及所述数据治理日志进行存储。
可选地,所述数据治理系统还包括:信息查询模块,用于获取用户的查询请求,根据所述查询请求、所述用户操作权限,对所述治理结果和/或所述治理日志进行查询。
本发明技术方案,具有如下优点:
本发明实施例提供的数据治理系统包括:权限管理模块,用于对用户身份信息进行验证,并根据验证结果授予用户操作权限;数据源管理模块,用于获取待治理数据并将其发送至数据治理模块;任务构建模块,用于获取用户的数据治理要求,并根据要求及用户的操作权限构建数据治理任务;数据治理模块,用于根据数据治理任务对待治理数据进行数据治理生成治理结果。从而实现了对海量数据的多样化数据治理的功能,用户仅需要简单操作就可以自动进行数据治理任务,具有适用范围广,数据治理方式更为灵活,数据治理时间短的特点,从而降低了工作人员的工作量,提高了数据治理效率。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中数据治理系统的结构示意图;
图2为本发明实施例中数据治理系统的另一结构示意图;
图3为本发明实施例中维表的示例图;
图4为本发明实施例中事实表的示例图;
图5为本发明实施例中数据治理系统的另一结构示意图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
本发明实施例提供了一种数据治理系统,如图1所示,该数据治理系统包括:权限管理模块1、数据源管理模块2、任务构建模块3及数据治理模块4,其中,权限管理模块1对用户的身份信息进行验证,并根据验证结果授予用户操作权限;数据源管理模块2从数据源数据库中获取待治理数据,并将待治理数据发送至数据治理模块4;任务构建模块3获取用户输入的数据治理要求,根据数据治理要求及用户操作权限为待治理数据构建数据治理任务;数据治理模块4接收待治理数据,并根据数据治理任务对待治理数据进行数据治理,生成治理结果。
通过上述各个组成部分的协同合作,本发明实施例的数据治理系统,实现了对海量数据的多样化数据治理的功能,用户仅需要简单操作就可以自动进行数据治理任务,具有适用范围广,数据治理方式更为灵活,数据治理时间短的特点,从而降低了工作人员的工作量,提高了数据治理效率。
以下将结合具体示例对本发明实施例提供的数据治理系统进行详细的说明。
具体地,在一实施例中,上述的权限管理模块1,对用户的身份信息进行验证,并根据验证结果授予用户操作权限。在实际应用中,为了方便用户进行使用并便于对系统进行维护,需要对使用系统的不同用户设置不同的操作权限,例如,普通用户仅能构建部分数据治理任务,而高级别的用户可以获得更多的操作权限等,为了便于管理,系统中可以根据实际需要预设部分对应权限的角色,例如:系统管理员、业务审核员、业务操作员、审计管理员、审核管理员等,并且还可以根据需要设置修改角色的权限等。
具体地,在一实施例中,上述的数据源管理模块2,从数据源数据库中获取待治理数据。在实际应用中,用户将可以将需要进行治理的多个待治理数据统一存入数据源数据库中,当用户使用系统进行数据治理时,从数据源数据库中选择其中一个待治理数据进行数据治理,并在治理完成后,再从数据源数据库中重新选择其他待治理数据进行数据治理。该数据源管理模块2中还包含了新建、更新、删除获取的待治理数据源等功能,该数据源管理模块2支持txt、csv、excel等多种文件格式,上述的数据源数据库可以是mysql、oracle等数据库,本发明并不以此为限。
在一较佳实施例中,如图2所示,上述的任务构建模块3包括:治理模型选择子模块31、治理模型构建子模块32、治理任务构建子模块33及存储子模块34,其中,
存储子模块34用于存储多个预设治理模型。具体地在实际应用中,系统中集成的预设治理模型包括:精准匹配治理模型,其是通过维表与事实表关联,将事实表中的字段替换为维表中的内容,例如在电力数据的维表如图3所示,其中维表中的id表示预设的编码,name标识上述预设编码所对应的编码含义;事实表如图4所示,其中,obj_id表示事实表中的排列序号,azwz表示与上述维表中相对应的预设编码,sbmc表示该排列序号对应的电力数据的实际含义,在实际使用中,由于编码不易理解需要使用维表中的对应的编码意义,故需要精准匹配治理模型进行替换,获得新表,例如:将事实表中azwz列中的1替换为维表中的“地上室内”,将azwz列中2替换为维表中的“地上室外”等;模糊匹配治理模型,其是允许对正则式或普通字符进行替换,将该列的内容替换为指定形式;表达式治理模型,这类模型用户可以指定hive支持的表达式,可以选择新增一列或覆盖现有列的值;需要说明的是,在实际应用中,上述的预设治理模型还可以包括其他可以实现数据治理功能的各类模型,本发明并不以此为限。
治理模型构建子模块32根据数据治理要求构建新治理模型。在实际应用中,可能存在系统中现有的预设数据治理模型无法实现用户的数据治理要求的情况,此时,用户可以在上述的治理模型构建子模块32中根据数据治理要求构建新的治理模型,并将该治理模型添加进原有的预设治理模型中,既可以实现数据治理要求,又可以不断地丰富系统的数据治理功能。
治理模型选择子模块31根据数据治理要求从新治理模型及多个预设治理模型中选择执行治理任务的各治理模型。在实际应用中,当用户的数据治理要求中包含多个治理条件时,则需要根据不同的治理条件选择不同的治理模型。
治理任务构建子模块33根据数据治理要求对执行治理任务的各治理模型生成数据治理任务。具体地,用户在实际使用时,需要根据数据的实际治理要求,可能进行多种数据治理的融合治理,需要生成对应的数据治理任务。该数据治理任务包括:执行治理任务的各治理模型的执行顺序列表及执行时间信息。例如,待治理数据需要进行数据匹配和冗余数据删除的治理要求,则需要选择执行数据匹配的治理模型和执行冗余数据删除的治理模型依次顺序对待治理数据进行治理,并且设立这两个治理模型的治理执行时间是立即执行还是定时执行。
在一较佳实施例中,如图2所示,上述的数据治理模块4包括:
预处理子模块41,用于接收待治理数据,并将待治理数据进行格式转换,生成标准数据。在实际应用中,上述数据源管理模块2发送的待治理数据的模型可能包括系统不支持的数据类型,此时,预处理子模块41则将待治理数据进行格式转换,生成系统支持的标准数据,增强了系统的兼容性。
数据治理执行子模块42,用于根据执行顺序列表及执行时间信息对标准数据进行数据治理,生成治理结果。在实际应用中,上述的治理结果包括治理完成后的数据,及执行的治理任务结果等,在数据治理完成后,上述的数据治理执行子模块42还用于将治理结果发送至用户端。
在一较佳实施例中,如图5所示,上述的数据治理系统还包括:治理日志生成模块5,根据数据治理模块4对待治理数据的数据治理过程进行记录,生成数据治理日志。具体地,上述的数据治理日志包括:治理任务信息、治理时长信息、治理结果信息(例如总记录数、被治理的记录数)等。在实际应用中,用户可以通过查看治理日志来了解待治理数据的治理情况,例如:待治理数据都进行了那些治理模型的治理,每个治理模型的治理时间以及治理是否成功等信息。
在一较佳实施例中,如图5所示,上述的数据治理系统还包括:治理评价模块6,根据数据治理要求对治理结果进行评价,生成评价结果;当评价结果为合格时,数据治理模块4将治理结果发送至用户端;当评价结果为不合格时,任务构建模块3重新根据数据治理要求及用户操作权限为待治理数据构建新数据治理任务;数据治理模块4根据新数据治理任务对待治理数据进行数据治理,生成新治理结果。在实际应用中,用户采用上述数据治理系统对待治理数据进行数据治理时,可能存在某些治理任务中的程序执行失败或治理过程没有完成的情况,为了给用户提供更完善的服务,上述的治理评价模块6可以对最终的治理结果进行评价,当出现上述情况时,为用户构建新的数据治理任务,重新对待治理数据进行数据治理,以满足用户的数据治理要求,提高系统的数据治理的准确性。
在一较佳实施例中,如图5所示,上述的数据治理系统还包括:治理数据库7,用于对治理结果及数据治理日志进行存储。在实际应用中,上述的治理数据库7对治理结果及数据治理日志进行存储,方便了用户进行数据治理过程的查询,并为该数据治理系统进行升级和维护提供了数据基础。
在一较佳实施例中,如图5所示,上述的数据治理系统还包括:信息查询模块8,用于获取用户的查询请求,根据查询请求、用户操作权限,对治理结果和/或治理日志进行查询。在实际应用中,为了方便用户了解整个数据治理的过程以及该数据治理系统的工作人员对系统的日常管理维护和升级,上述的信息查询模块8根据用户的操作权限赋予各类用户对治理结果和/或治理日志的查询,例如:系统的使用者仅能查询自己的数据治理结果和治理日志,而后台管理人员则可以查询所有用户的数据治理结果和治理日志等。
在实际工程应用中,上述的三种预设数据治理模型:精准匹配治理模型可以通过维表关联得到,模糊匹配治理模型可以通过函数regexp_replace实现,也可以在一个数据治理任务中嵌套多个模糊匹配治理模型,此时会自动嵌套多个regexp_replace函数,表达式治理模型则可以通过hive灵活执行表达式获取结果。实际操作时首先选择数据治理模型,选择数据治理模型需要处理的字段(待治理数据)并输入目标字段,然后批量添加相应数据治理模型,此时系统会将所选的数据治理模型批量应用到待处理字段上,最终生成新的一列,新的一列的列名即为输入的目标字段值,如果列名与已有列名重复,新列将最终覆盖旧列,存入结果表,具体生成过程如下:
生成一个中间过程表(rules结果表),在该表中所有列都将加上表名加下划线作为新列名,例如表a的data字段在中间过程表中列名为a_data,以避免与目标字段列名重复,中间结果表包含所有经过转换的列名和目标字段列,生成中间过程表后,再生成最终结果表,最终结果表列名将去掉表名加下划线,还原原来的列名,例如在上述中,如果没有目标列为data,则a_data的值将作为列data的值,如果有一个目标列为data,则最终结果表将不保留a_data的值,直接将目标列data的值作为结果表的data列的值。
此外预设数据治理模型除了上述举例的三种数据治理模型还包括一些算法类的数据治理模型,这些算法类数据治理模型则需要使用编写好的算法来处理数据源数据库中的待治理文件中的数据,所以在处理时先将表数据从hdfs(hive的表数据是存在hdfs中的)中导出到本地文件系统中,然后按照设定好的算法参数对表数据进行处理,对于一些参数可以直接进行选择或输入设置,对于一些复杂参数可以进行定制开发,处理完后将结果文件按分隔符建表,再放入hdfs,导入到hive中,最后如果需要再将hive中的数据导出到用户端的目标数据库中。例如常用的算法类数据治理模型有地址规范化模型和数据矩阵填充模型(例如针对电力系统的日采集数据,每天生成96个电表示值,本发明实施例中内置有python编写的最优匹配搜索(cbms),改进交替式最小二乘优化(ials),时间序列arima模型及卡尔曼滤波(karm)等可供选择)。另外,在删除重复数据实现时,可以直接对表选择的列进行查询,对选择的列有重复的取其中一个,删除冗余数据。具体实现为直接对选择的列进行groupby,并加一列count(1),记录合并的记录个数,不产生中间结果表,直接生成目标表,并将目标表从hive导出到用户端的目标数据库。
通过上述各个组成部分的协同合作,本发明实施例的数据治理系统实现了对海量数据的多样化数据治理的功能,用户仅需要简单操作就可以自动进行数据治理任务,具有适用范围广,兼容性好,数据治理方式更为灵活,数据治理时间短的特点,从而降低了工作人员的工作量,提高了数据治理效率,并且实现了对数据治理的评价功能及查询功能,当数据治理不合格时,可以重新对数据进行治理,从而提高了数据治理的准确性,为系统的优化升级提供了良好的数据基础。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!