一种基于半监督广域迁移度量学习的小样本目标识别方法与流程
本发明属于深度学习及目标识别技术领域,涉及一种基于半监督广域迁移度量学习的小样本目标识别方法。
背景技术:
在机器学习领域,小样本学习相关的研究工作是近年的发展重点,其中包括:1)半监督学习:是监督学习与无监督学习相结合的一种学习方法。半监督学习同时使用标记数据与大量的未标记数据,来进行模式识别工作。通过挖掘未标记数据中所蕴藏的对标记数据有补充作用的信息,提高分类器的泛化能力。2)迁移学习:是指利用数据、任务、或模型之间的相似性,将在旧领域(源域)学习过的模型,应用于新领域(目标域)的一种学习过程。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。迁移学习的核心问题是,找到新问题和原问题之间的相似性,实现知识的顺利迁移。3)度量学习:亦即相似度学习,是对样本间距离分布进行建模,使得属于同类样本靠近,异类样本远离。目前比较好的方法可学习一个端到端的最近邻分类器,它同时受益于带参数和无参数的优点,对已知样本有很好的泛化性,且对新样本有良好的拓展能力。
针对遥感影像小样本目标检测识别问题,上述的机器学习方法提供了可借鉴之处,但若直接套用,则还存在诸多局限:1)半监督学习对未标记样本的真实类别也有限制等等;2)迁移学习对源域有较严格的限制,为了保证“正迁移”,要求源域与目标域有强关联。
技术实现要素:
本发明的目的在于针对传统小样本目标识别方法的不足,为深度学习及视频分析研究提供一种半监督广域迁移度量学习的小样本目标识别方法。
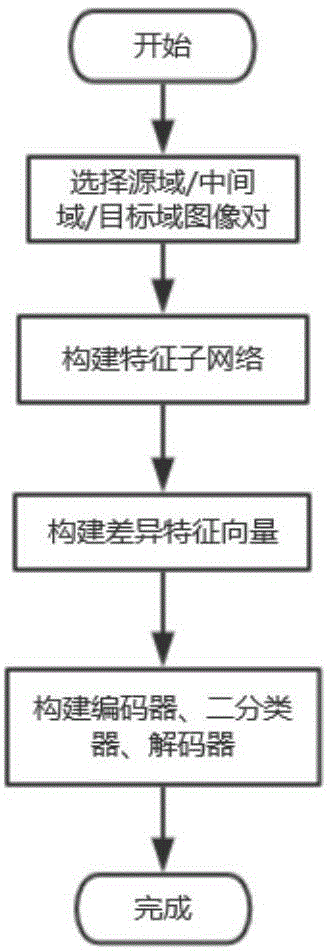
本发明方法包括以下步骤:
步骤(1)、选择源域图像对、中间域图像对和目标域图像对;
目标域图像对是两个某类具体型号的目标图像,源域图像对是和目标域图像对类似的图像对,中间域图像对是利用大量的无标签样本构建的;
步骤(2)、构建特征子网络;
直接提取典型深度网络的前几个卷积层,构建特征子网络;直接提取典型深度网络为alexnet、vgg-16或vgg-19。
步骤(3)、构建差异特征向量;
用差异特征向量表示图像对在特征空间上的相对距离,拟将图像对相应的特征子网络输出相减并转换为一维向量,从而获得差异特征向量;
步骤(4)、构建编码器、二分类器和解码器;
源域、中间域样本选择依据之一是:入选的源域、中间域样本与目标域样本一起,经编码与解码后的重构误差对应的代价函数是:
其中fe,fd分别为编码器与解码器,xs,xi,xt分别为源域、中间域、目标域的差异特征向量,
源域、中间域样本选择的另外一个依据是:入选的源域、中间域样本与目标域样本一起,编码后得到的特征所具备的鉴别性对应的代价函数是:
其中fc是二分类器,ys,yt是源域、目标域样本的标签;δ(·,·)表征两个输入参数值是否一致,一致为0,不一致为1;g(z)用于衡量输入参数的预测的可信度:g(z)=-zlnz-(1-z)ln(1-z);
总的优化目标函数为:
其中θ是fc,fe,fd的参数集合;
当θ固定不变时,源域、中间域样本可根据下式进行选择:
当νs,νi固定不变时,θ通过误差后向传播算法进行寻优求解;由此,可通过迭代的方式,学习得到θ与νs,νi。
本发明的有益效果是:广域迁移的目的是拓展源域范围,让更多的源域样本能够参与到学习中来。广域迁移需要解决的问题是如何将与目标域相距较远的源域做合理迁移。在源域与目标域中间,引入了中间域作为一个桥梁来连接二者。为了保证“正迁移”,降低“负迁移”风险,建立了源域/中间域样本的选择机制,从中挑选出对目标域样本分类有用的部分样本。本项目给出了一种非目标域样本对目标域样本的有用性描述方式,进而设计了样本选择算法。
本发明的关键在于充分利用目标的先验信息。本发明由于有机结合了多种机器学习方法,突破现有小样本学习方法的局限,方法简单易于实现,对使用传统方法的工程无需重新构造,详细兼容,能够节省大量人力。并且可以与其它小样本目标识别的方法相结合,对提高目标检测识别(特别是目标具体型号识别)精度有重要意义。
附图说明
图1为本发明的流程图。
图2为本发明各网络构建设计图。
具体实施方式
本发明所提出的基于半监督广域迁移度量学习的小样本目标识别方法就是为了拓宽源域的范围,引入中间域概念,利用更多已标注/未标注的数据。
具体内容包括:
1)半监督广域迁移度量学习的网络结构设计
包含前端的特征子网络以及后端的以自编码器为基本框架的网络结构设计。
2)源域/中间域样本选择算法
在源域中选择部分已标注样本,在中间域中选择部分未标注样本,确保入选的样本对目标域的度量学习有“正迁移”效果。
广域迁移的目的是拓宽源域的范围,通过迁移能够利用更多已标注的数据,从而为目标域的任务带来更多有效信息。广域迁移存在的问题是当范围拓宽时,源域与目标域的“距离”增大,直接利用源域样本,“负迁移”的风险增大。解决的思路是:在源域与目标域之间,利用大量的无标签样本,构建中间域样本;以中间域为桥梁,将单步长距离迁移分解为多步短距离迁移,控制“负迁移”风险;此外,建立选择机制,在源域与中间域样本集合中,选择部分高“正迁移”概率样本,进一步降低“负迁移”风险。
下面结合具体实施例对本发明做进一步的分析。
本实施例采用舰船图像作为样本数据集。在基于半监督广域迁移度量学习的小样本目标识别过程中具体包括以下步骤,如图1、图2所示:
步骤(1)、选择源域/中间域/目标域图像对。
目标域图像是某类具体型号目标图像,源域图像对是类似的图像对,如具体型号的相近类的目标图像。在同一型号或不同型号图像集中选择图像对,如果2张图像来自同一型号,则该图像对视为正例,反之则为反例。在源域与目标域之间,利用大量的无标签样本,构建中间域样本。
步骤(2)、构建特征子网络。
直接提取典型深度网络(alexnet,vgg-16/vgg-19)的前几个卷积层,构建特征子网络。
步骤(3)、构建差异特征向量。
用差异特征向量表示图像对在特征空间上的相对距离,拟将图像对相应的特征子网络输出相减并转换为一维向量,从而获得差异特征向量。
步骤(4)、构建编码器、二分类器、解码器。
源域/中间域样本选择依据之一是:入选的源域/中间域样本与目标域样本一起,经编码与解码后的重构误差要小。对应的代价函数是:
其中fe,fd分别为编码器与解码器,xs,xi,xt分别为源域/中间域/目标域的差异特征向量,
源域/中间域样本选择的另外一个依据是:入选的源域/中间域样本与目标域样本一起,编码后得到的特征具备较高的鉴别性,有助于正确分类。对应的代价函数是:
其中fc是二分类器,ys,yt是源域,目标域样本的标签;δ(·,·)表征2个输入参数值是否一致,一致为0,不一致为1;g(z)用于衡量输入参数(属于某类的概率)的预测的可信度:
g(z)=-zlnz-(1-z)ln(1-z)。
总的优化目标函数为:
其中θ是fc,fe,fd的参数集合。
当θ固定不变时,源域/中间域样本可根据下式进行选择:
当νs,νi固定不变时,θ可通过误差后向传播算法进行寻优求解。由此,可通过迭代的方式,学习得到θ与νs,νi。
上述实施例并非是对于本发明的限制,本发明并非仅限于上述实施例,只要符合本发明要求,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!