一种求解提升邻近算子机的神经网络优化方法与流程
本发明涉及深度学习神经网络优化
技术领域:
,尤其涉及一种通过求解提升邻近算子机(liftedproximaloperatormachine,lpom)进行神经网络优化的方法。
背景技术:
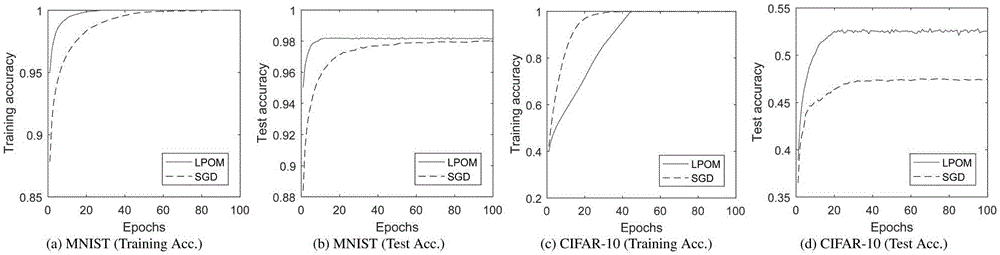
:前向深度神经网络是由层次结构的全连接层构成,并且不存在反馈连接。最近随着硬件和数据集规模的发展,前向深度神经网络在许多任务上成为标准。例如,图像识别[16],语音识别[12],自然语言理解[6]和作为围棋学习系统的重要组成部分[22]。近几十年以来,优化前向神经网络的目标通常是一个高度非凸且关于网络权值嵌套的函数。优化前向神经网络的主要方法是随机梯度下降法(stochasticgradientdescent,sgd)[21].它的有效性通过其在各种实际应用中的成功得到验证。近年来,各种随机梯度下降的变种被先后提出。它们使用自适应的学习效率或动量项,如nesterov动量[23],adagrad[8],rmsprop[7]和adam[15]。sgd及其变种使用较少的训练样本来估计梯度,使得每次迭代的计算量较小。此外,由于估计的梯度含有噪声,这有利于逃出鞍点[9]。然而,这些方法也存在一些缺点。主要的问题是梯度的量级随着网络层数指数级减小或增大造成梯度消失或爆炸。这种现象会造成收敛变慢或不稳定,这在较深的神经网络中尤为严重。该缺点可以通过使用非饱和激活函数如线性整流单元(relu)和修正的网络结构如resnet[11]进行缓和。然而,根本问题依然存在[24]。此外,它们无法直接处理不可微激活函数(如二值神经网络[13]),不同层的权值也不能并行更新。sgd的缺点激发了研究训练前向神经网络的新方法。最近,训练前向神经网络被形式化为一个约束优化问题。它引入了网络激活为辅助变量,网络结构则是通过逐层的约束来保证[3]。这种做法将嵌套函数的依赖关系断裂为等式约束,于是可以使用许多标准的优化算法进行求解。属于这一类型方法的主要区别在于如何处理等式约束。文献[4]通过二次惩罚项来近似等式约束,并交替优化网络权值和激活。文献[25]在每层又多引入一个辅助变量。他们也使用二次惩罚项来近似等式约束。然而,这两种方法都是近似等式约束或包含较多的辅助变量。受交错方向法[16]的启发,文献[24]和文献[27]使用增广拉格朗日法来获得严格的等式约束。然而,这两种方法都涉及到拉格朗日乘子和非线性约束,故而需要更多的内存,优化也更为困难。根据relu激活函数等价于一个简单的约束凸优化问题,文献[26]将非线性约束松弛为惩罚项,它刻画了网络结构和relu激活函数。于是,非线性约束不复存在。然而,该方法局限于relu激活函数,无法用于其他激活函数。文献[2]采用了类似的思路,但是讨论了多种类型的单增激活函数。然而,他们更新权值和激活的算法仍然局限于relu函数。他们的方法只能用于初始化sgd,无法超越sgd的性能。专利[1]提出一个近似前向神经网络的新模型,称为提升邻近算子机(liftedproximaloperatormachine,lpom)。lpom把激活函数重写为与之等价的近邻算子,并将该邻近算子作为惩罚项添加到目标函数中来近似前向神经网络。然而,专利[1]中给出的求解算法没有利用它关于每层权值和激活是块多凸的这一特性。使用交错方向法更新网络激活时引入了多个辅助变量。使用梯度下降法更新权值时选择合适的学习效率非常困难。引用文献:[1]一种提升邻近算子机神经网络优化方法.201711156691.4[2]askari,a.;negiar,g.;sambharya,r.;andghaoui,l.e.2018.liftedneuralnetworks.arxivpreprintarxiv:1805.01532.[3]beck,a.,andteboulle,m.2009.afastiterativeshrinkagethresholdingalgorithmforlinearinverseproblems.siamjournalonimagingsciences183–202.[4]carreira-perpinan,m.,andwang,w.2014.distributedoptimizationofdeeplynestedsystems.ininternationalconferenceonartificialintelligenceandstatistics,10–19.[5]clevert,d.-a.;unterthiner,t.;andhochreiter,s.2015.fastandaccuratedeepnetworklearningbyexponentiallinearunits(elus).arxivpreprintarxiv:1511.07289.[6]collobert,r.;weston,j.;bottou,l.;karlen,m.;kavukcuoglu,k.;andkuksa,p.2011.naturallanguageprocessing(almost)fromscratch.journalofmachinelearningresearch12:2493–2537.[7]dauphin,y.;devries,h.;andbengio,y.2015.equilibratedadaptivelearningratesfornon-convexoptimization.innips,1504–1512.[8]duchi,j.;hazan,e.;andsinger,y.2011.adaptivesubgradientmethodsforonlinelearningandstochasticoptimization.journalofmachinelearningresearch12:2121–2159.[9]ge,r.;huang,f.;jin,c.;andyuan,y.2015.escapingfromsaddlepoints-onlinestochasticgradientfortensordecomposition.incolt,797–842.[10]glorot,x.,andbengio,y.2010.understandingthedifficultyoftrainingdeepfeedforwardneuralnetworks.inproceedingsofthethirteenthinternationalconferenceonartificialintelligenceandstatistics,249–256.[11]he,k.;zhang,x.;ren,s.;andsun,j.2016.deepresiduallearningforimagerecognition.incvpr,770–778.[12]hinton,g.;deng,l.;yu,d.;dahl,g.e.;mohamed,a.-r.;jaitly,n.;senior,a.;vanhoucke,v.;nguyen,p.;sainath,t.n.;etal.2012.deepneuralnetworksforacousticmodelinginspeechrecognition:thesharedviewsoffourresearchgroups.ieeesignalprocessingmagazine29(6):82–97.[13]hubara,i.;courbariaux,m.;soudry,d.;el-yaniv,r.;andbengio,y.2016.binarizedneuralnetworks.inadvancesinnips,4107–4115.[14]jia,y.;shelhamer,e.;donahue,j.;karayev,s.;long,j.;girshick,r.;guadarrama,s.;anddarrell,t.2014.caffe:convolutionalarchitectureforfastfeatureembedding.inproceedingsofthe22ndacminternationalconferenceonmultimedia,675–678.acm.[15]kingma,d.p.,andba,j.2014.adam:amethodforstochasticoptimization.arxivpreprintarxiv:1412.6980.[16]krizhevsky,a.;sutskever,i.;andhinton,g.e.2012.imagenetclassificationwithdeepconvolutionalneuralnetworks.innips,1097–1105.[17]lin,z.;liu,r.;andsu,z.2011.linearizedalternatingdirectionmethodwithadaptivepenaltyforlow-rankrepresentation.innips,612–620.[18]nesterov,y.,ed.2004.introductorylecturesonconvexoptimization:abasiccourse.springer.[19]netzer,y.;wang,t.;coates,a.;bissacco,a.;wu,b.;andng,a.y.2011.readingdigitsinnaturalimageswithunsupervisedfeaturelearning.innipsworkshopondeeplearningandunsupervisedfeaturelearning,volume2011,5.[20]parikh,n.;boyd,s.;etal.2014.proximalalgorithms.foundationsandtrendsrinoptimization1(3):127–239.[21]rumelhart,d.e.;hinton,g.e.;andwilliams,r.j.1986.learningrepresentationsbyback-propagatingerrors.nature323(6088):533.[22]silver,d.;huang,a.;maddison,c.j.;guez,a.;sifre,l.;vandendriessche,g.;schrittwieser,j.;antonoglou,i.;panneershelvam,v.;lanctot,m.;etal.2016.masteringthegameofgowithdeepneuralnetworksandtreesearch.nature529(7587):484.[23]sutskever,i.;martens,j.;dahl,g.;andhinton,g.2013.ontheimportanceofinitializationandmomentumindeeplearning.inicml,1139–1147.[24]taylor,g.;burmeister,r.;xu,z.;singh,b.;patel,a.;andgoldstein,t.2016.trainingneuralnetworkswithoutgradients:ascalableadmmapproach.inicml,2722–2731.[25]zeng,j.;ouyang,s.;lau,t.t.-k.;lin,s.;andyao,y.2018.globalconvergenceindeeplearningwithvariablesplittingviathekurdyka-lojasiewiczproperty.arxivpreprintarxiv:1803.00225.[26]zhang,z.,andbrand,m.2017.convergentblockcoordinatedescentfortrainingtikhonovregularizeddeepneuralnetworks.innips,1721–1730.[27]zhang,z.;chen,y.;andsaligrama,v.2016.efficienttrainingofverydeepneuralnetworksforsupervisedhashing.incvpr,1487–1495.技术实现要素:为了克服上述现有技术的不足,本发明提供一种提升邻近算子机(lpom)的新解法,用于前向神经网络的训练。与现有的神经网络优化方法不同,该解法对每个子问题均有收敛性保证,可以并行更新变量,并且在求解过程中与采用随机梯度下降法(sgd)占用相当的内存。为叙述方便,本发明首先介绍lpom模型,具体如式1所示:其中,wi-1是第i-1层网络权值,xi是第i层网络激活,i=2,…,n,l(xn,l)是损失函数,n是神经网络的层数,x1是训练样本(当i=2时,xi-1即为x1),l是x1对应的类标,对于矩阵输入,f(x)和g(x)是逐元素的,φ(x)是激活函数,φ-1是φ的逆函数,μi>0是第i个惩罚项的参数,1是全1列向量,||·||f是frobenius范数。若l(xn,l)关于xn是凸的,并且,φ(x)是单增的,则lpom关于wi和xi是块多凸的,即若其余变量保持不变,式1的目标函数关于wi和xi是凸的。本发明提供的技术方案是:一种求解提升邻近算子机的神经网络优化方法,在前向神经网络的训练中,采用一种块坐标下降新方法求解lpom模型(如式1所示),对lpom模型中的每个子问题均保证收敛性,可并行更新变量,且不占用额外内存空间;包括如下步骤:1)从神经网络训练样本中随机选取m1个训练样本x1和l,其中,m1是批处理的大小,l是训练样本x1对应的类标;2)逐层更新网络激活xi,i=1,…,n;执行操作21)~22),这些步骤中各符号的含义与式1中的相同:21)按i=1,…,n-1顺序依次更新xi。循环式2直到收敛。式2中,μi、μi+1分别为第i个和第i+1个惩罚项的参数。22)更新xn。循环式3直到收敛。式3中,μn为式1中第n个惩罚项的参数。3)更新网络权值wi,i=1,…,n-1。这里假设是β平滑的,即如下不等式成立:通过以下过程更新wi:初始化:wi,0,wi,1,θ0=0,t=1。其中,wi,0和wi,1是迭代更新wi的初始值,θ0是参数θ的初始值,t是迭代次数。31)计算θt:其中,θt>0表示第t次迭代时参数θ的值;32)计算yi,t:其中,yi,t表示第t次迭代更新yi;33)计算wi,t+1:其中,wi,t+1表示第t+1次迭代更新wi,表示xi的伪逆;34)t←t+1;其中,步骤21),22)和3)均具有收敛性保证,实现逐层更新网络激活和网络权值。即通过上述求解提升邻近算子机的块坐标下降方法实现神经网络优化。与现有技术相比,本发明的有益效果是:本发明通过求解提升邻近算子机来优化前向神经网络,可以用于图像识别,语音识别和自然语言理解等具体任务。本发明提出的求解提升邻近算子机的块坐标下降法在使用相对较少存储的情况下,能够提高神经网络训练的并行性、适用性和训练效果。具体地,本发明提出的方法可以并行的更新每层的权值和激活。而且,该算法仅使用激活函数本身,没有使用它的微分,从而避免了基于梯度的训练方法中的梯度消失或爆炸问题,能够提升神经网络的训练效果。本发明提出的优化前向神经网络方法可适用于各种单增利普希茨连续的激活函数,激活函数可以是饱和的和不可微的。除了每层的激活,不需要额外的辅助变量,故而与sgd使用大致相当的内存。进一步地,具体实施实验验证了本发明算法更新每层权值和激活的收敛性。在mnist、cifar-10和svhn数据集[19]上的图像识别任务实验也验证了采用该算法进行神经网络优化具有正确率高的优越性。附图说明图1为本发明提出的求解lpom的新算法和sgd方法在mnist和cifar-10数据集上的结果比较图。具体实施方式下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。本发明提供一种求解提升邻近算子机的神经网络优化方法,在前向神经网络的训练中,采用一种块坐标下降新方法求解lpom模型,对lpom模型中的每个子问题均保证收敛性,可并行更新变量,提高神经网络训练的准确性,且不占用额外内存空间。本发明提出的神经网络优化方法可应用于图像识别、语音识别和自然语言处理等具体任务。以下以图像识别为例,描述具体实施方式,并与当前最好结果进行比较。本发明方法使用最小二乘损失函数即和relu激活函数即relu(x)=max(x,0),未使用任何正则化处理权值。本发明提出的求解lpom的方法与sgd方法使用相同的输入,并且均使用文献[10]记载的随机初始化方法。采用本发明的求解lpom方法和sgd方法,对mnist、cifar-10和svhn[19]三个数据集上的图像识别任务进行比较。对于sgd和lpom,每个数据集中的全部训练图像在每趟(epoch)训练过程中仅使用一次。本实施例采用本发明方法对图像识别神经网络训练优化包括如下步骤:1)从图像识别神经网络的训练样本中随机选取m1幅训练图像x1和l,其中,m1是批处理的大小,可取100或256等值,l是x1对应的类标,常用的mnist和cifar-10数据集均包含10个类别;2)逐层更新前向神经网络的激活xi,i=1,…,n;执行操作21)~22),这些步骤中各符号的含义与式1中的相同:21)按i=1,…,n-1顺序依次更新xi。循环式4共100次。22)更新前向神经网络的激活xn。循环式5共100次。3)更新前向神经网络的权值wi,i=1,…,n-1。对于relu激活函数,是β=1平滑的,即如下不等式成立:所以,可以通过以下过程更新wi,共迭代5次:初始化:wi,0=wi,wi,1=wi,θ0=0,t=1。其中,wi,0和wi,1均初始化为wi。31)计算θt:其中,θt-1是参数θ在t-1次迭代的值;32)计算yi,t:33)计算wi,t+1:其中,表示xi的伪逆;34)t←t+1;其中,步骤21),22)和3)均具有收敛性保证。即通过上述求解提升邻近算子机的块坐标下降方法实现图像识别神经网络的优化。具体地,在mnist数据集上,使用784个原始像素作为本发明中求解lpom的方法及sgd方法的输入。该数据集共含有60,000个训练图像和10,000个测试图像。具体实施中未使用任何预处理或数据增强。与文献[25]一样,本发明使用784-2048-2048-2048-10的前向全连接神经网络。本发明方法对于lpom,简单的设置μi=20。实验运行求解lpom的方法和sgd方法共100趟,批处理大小均为100.在cifar-10数据集上,与文献[25]一样,本发明使用3072-4000-1000-4000-10前向全连接神经网络。通过减去红、绿和蓝三个通道的均值来归一化彩色图像。除此之外,没有使用其他预处理或数据增强。对于求解lpom的方法,设置μi=100.实验共运行求解lpom的方法和sgd方法100趟,批处理大小均为100.在mnist数据集上与文献[2]进行比较时,本发明使用与文献[2]相同的网络结构。实际计算中,文献[2]仅使用relu激活函数。与文献[2]相同,运行求解lpom的方法共17趟,批处理大小为100.对于lpom,在所有网络结构上均设置μi=20.具体实施中未使用预处理或数据增强。与文献[24]在svhn数据集[19]上进行比较时,按照文献[24]关于网络结构和数据集的设置。对于所提出的求解lpom的方法,设置μi=20.本发明中求解lpom的方法与sgd方法在mnist数据集上的训练和测试正确率见图1(a)和(b)。可以看到,两种方法的训练正确率都接近于100%.然而,采用发明方法求解lpom所得的测试正确率(98.2%)略微优于sgd(98.0%)。本发明中的lpom和sgd在cifar-10数据集上的训练和测试正确率如图1(c)和(d)所示。可以看到,两种方法的训练正确率均接近100%.然而,本发明中的lpom的测试正确率(52.5%)高于sgd的测试正确率(47.5%)。采用本发明方法的lpom与文献[2]在mnist上的测试正确率如表1所示。可以看到,本发明中的lpom的结果显著优于文献[2].本发明中的lpom与sgd和文献[24]在svhn数据集上的测试正确率见表2.可以看到,采用本发明方法求解lpom的结果优于sgd和文献[24].表1:采用本发明方法求解的lpom与文献[2]在mnist数据集上的比较表2采用本发明方法求解的lpom与sgd和文献[24]在svhd数据集上的比较sgd95.0%文献[24]96.5%lpom98.3%需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1