基于大数据和深度学习的跟踪认定方法和机器人系统与流程
本发明涉及信息技术领域,特别是涉及一种基于大数据和深度学习的跟踪认定方法和机器人系统。
背景技术:
在实现本发明过程中,发明人发现现有技术中至少存在如下问题:现有技术下进行认定(例如高新企业认定、人才认定等等)都是一次性的,认定完之后就不再跟踪,有的对象(对象包括企业、候选人等等)可能在认定时通过了,但一旦通过之后,对象就不再有认定的压力,而放松对自己的要求,从而认定通过之后的一段时间内可能不再符合认定的要求,但并不会影响之前认定的结果,这样就会导致认定的结果不具有时效性,也就是说过去认定的结果不一定符合对象现在实际的情况,这样就会使得认定失去可信性和意义;而有的对象在认定不通过之后,努力进取,经过一定的时间努力之后,虽然已经达到了认定的标准,但因为之前的认定失败,对象一直迟迟不敢再次申请认定,甚至可能因为之前认定失败而失去信心而一直不再申请认定,这样就会到导致已经达到认定标准的对象因为没有再次申请认定而一直处于未认定的状态,从而会导致认定的结果不全面;总而言之,现有的认定技术会导致不再满足认定标准的对象仍然保持认定通过的结果;而已经满足认定标准的对象缺仍然保持认定不通过的结果,从而无法与时俱进,已认定的结果失去了时效性、客观性和可信性;现有认定技术中大部分认定通过的结果是永久有效的,那么其缺点就如上所述非常明显,也有少数认定通过的结果是在一定时间段(例如几年)内有效的,过期后需要重新认定,这一方面仍然无法解决上面所述的缺点,因为所说的有效时间段一般都是比较长的,在那段时间内对象会发生很多变化,极有可能从符合认定标准变成不符合认定标准,从而仍然导致认定的结果失去了时效性、客观性和可信性;同时,另一方面,认定通过的结果只在一定的时间段内有效,过期后需要重新认定,这一方面会浪费已认定通过的对象的时间和人力物力来重新申请认定,同时也浪费了认定主管单位的时间和人力物力,因为如果已认定通过的对象的数据变化没有影响到认定的结果,那么就没有必要重新申请认定,从而导致现有认定技术的成本高、效率低;第三方面也是最重要的方面,现有技术都是在认定主管部门规定的认定时间进行认定,导致被认定的对象在平时没压力、不努力,在认定时为时已晚,临时努力也无济于事,导致了有些被认定的对象为了认定通过而铤而走险,做出找关系、作假等违法行为。
因此,现有技术还有待于改进和发展。
技术实现要素:
基于此,有必要针对现有技术中的缺陷或不足,提供基于大数据和深度学习的跟踪认定方法和机器人系统,以解决现有技术中认定的时效性、客观性、可信度、准确性不足和成本高、效率低的缺点。
第一方面,本发明实施例提供一种认定方法,所述方法包括:
认定标准获取步骤,用于获取预设类别的认定标准;
对象数据获取步骤,用于获取待认定的对象的数据;获取的数据包括第三方数据,数据更客观和可行,所以可以提高认定的客观性和可信度;如果数据不客观,认定也就不会准确,因为数据更客观,进而也就提高了准确性;
标准对应的数据获取步骤,用于从所述待认定的对象的数据中获取所述认定标准对应的数据;
数据变化检测步骤,用于将所述待认定的对象的所述认定标准对应的数据与上一次认定时所述待认定的对象的所述认定标准对应的数据进行比较并判断是否发生了变化:是,则转到跟踪认定判断步骤执行;否,则转到复制认定结果步骤执行;
跟踪认定判断步骤,用于判断所述认定标准对应的数据是否符合所述认定标准;根据标准进行自动认定,可以提高认定的效率;
复制认定结果步骤,用于将所述待认定的对象的上一次认定结果作为所述待认定的对象的本次认定结果;
结果反馈步骤,用于判断认定结果的变化,并发送给所述待认定的对象;可以及时把结果反馈给待认定对象,从而可以使得满足标准的对象早日申请认定,从而可以提高认定的时效性;
跟踪控制步骤,用于获取预设时间段或预设时间点,每隔预设时间段或达到预设时间点就重新执行所述认定方法中的所有步骤。不论待认定的对象是否申请认定,都会定期进行跟踪认定,从而可以提高认定的时效性,同时也能使得认定更符合对象的实时情况,从而使得认定的结果更可信和准确。同时,在认定过期后,对于跟踪认定通过的对象无需重新进行人工认定,从而降低了成本。
优选地,
所述对象数据获取步骤包括:
数据源获取步骤,用于获取数据源;
对象数据检索步骤,用于从所述数据源中检索并获取所述待认定的对象的数据;
所述标准对应的数据获取步骤包括:
数据筛选步骤,用于从所述待认定的对象的数据中筛选出所述认定标准对应的数据作为第一数据;
数据清洗步骤,用于从所述第一数据中提取与每一项标准对应的数据作为所述每一项标准对应的第二数据。
优选地,
所述数据清洗步骤包括:
对应数据源获取步骤,用于获取多个所述第二数据中每个所述第二数据对应的数据源;
可信度获取步骤,用于获取每个所述第二数据对应的数据源的可信度;
可信度选取步骤,用于从每个所述第二数据对应的数据源的可信度中选取最高的可信度,保留所述多个所述第二数据中所述最高的可信度对应的所述第二数据,删除所述多个所述第二数据中所述最高的可信度对应的所述第二数据以外的其他所述第二数据。
优选地,
所述跟踪认定判断步骤包括:
子标准获取步骤,用于获取所述认定标准中每一项标准和总体标准;
对应数据提取步骤,用于从所述第一数据中提取所述每一项标准对应的所述第二数据;
对应数据变化检测步骤,用于将所述待认定的对象的所述每一项标准对应的第二数据与上一次认定时所述待认定的对象的所述每一项标准对应的第二数据进行比较并判断是否发生了变化:是,则执行每一项标准对应的预设模型获取步骤或每一项标准判断步骤;否,则跳转到对应数据提取步骤或总体标准对应的预设模型获取步骤执行;
每一项标准对应的预设模型获取步骤,用于获取所述每一项标准对应的预设模型;
每一项标准对应的第三数据生成步骤,用于根据所述每一项标准对应的所述第二数据和所述每一项标准对应的所述预设模型,计算得到所述每一项标准对应的第三数据;
每一项标准判断步骤,用于根据所述每一标准对应的第三数据和预设范围和预设范围,判断所述待认定的对象是否符合所述每一项标准;
总体标准对应的预设模型获取步骤,用于获取所述总体标准对应的预设模型;
总体标准判断步骤,用于根据所述每一项标准对应的第三数据、所述总体标准对应的预设模型和预设范围,判断所述待认定的对象是否符合所述总体标准;
综合判断步骤,用于判断所述待认定的对象是否符合所述认定标准中所述每一项标准和所述总体标准。
优选地,
所述每一项标准对应的预设模型获取步骤包括:
每一项标准对应的深度学习模型初始化步骤,用于初始化所述每一项标准对应的深度学习模型作为第一深度学习模型;
每一项标准对应的历史数据获取步骤,用于从历史大数据中获取所述每一项标准对应的已进行过认定的每一对象的所述第二数据和第三数据;
第二深度学习模型生成步骤,用于将所述每一项标准对应的已进行过认定的每一对象的所述第二数据作为所述第一深度学习模型的输入数据,对所述第一深度学习模型进行无监督训练,得到的所述第一深度学习模型作为第二深度学习模型;
第三深度学习模型生成步骤,用于将所述每一项标准对应的已进行过认定的每一对象的所述第二数据和所述第三数据分别作为所述第二深度学习模型的输入数据和输出数据,对所述第二深度学习模型进行有监督训练,得到的所述第二深度学习模型作为第三深度学习模型;
每一项标准对应的预设模型设置步骤,用于将所述第三深度学习模型作为所述每一项标准对应的预设模型;
所述总体标准对应的预设模型获取步骤包括:
总体标准对应的深度学习模型初始化步骤,用于初始化所述总体标准对应的深度学习模型,得到的所述深度学习模型作为第四深度学习模型;
总体标准对应的历史数据获取步骤,用于从历史大数据中获取所述已进行过认定的每一对象的所述认定标准中每一项标准对应的第三数据的集合和所述总体标准对应的第三数据;
第五深度学习模型生成步骤,用于将所述认定标准中每一项标准对应的已进行过认定的每一对象的所述第三数据的集合作为所述深度学习模型的输入数据,对所述第四深度学习模型进行无监督训练,得到的所述第四深度学习模型作为第五深度学习模型;
第六深度学习模型生成步骤,用于将所述已进行过认定的每一对象的所述认定标准中每一项标准对应的所述第三数据的集合和所述总体标准对应的所述第三数据分别作为所述第五深度学习模型的输入数据和输出数据,对所述第五深度学习模型进行有监督训练,得到的所述第五深度学习模型作为第六深度学习模型;
总体标准对应的预设模型设置步骤,用于将所述第六深度学习模型作为所述总体标准对应的预设模型。
优选地,
所述每一项标准判断步骤包括:
每一项标准对应的预设范围获取步骤,用于获取所述每一项标准对应的预设范围;
每一项标准对应的第三数据判断步骤,用于判定所述待认定的对象是否符合所述每一项标准;
每一项标准对应的变化提醒步骤,用于判断所述待认定的对象在是否符合所述每一项标准方面的变化,并将变化信息发送给所述待认定的对象;
所述总体标准判断步骤包括:
总体标准对应的第三数据生成步骤,用于根据所述每一项标准对应的所述第三数据和所述总体标准对应的所述预设模型,计算得到所述总体标准对应的第三数据;
总体标准对应的预设范围获取步骤,用于获取所述总体标准对应的预设范围;
总体标准对应的第三数据判断步骤,用于判断所述待认定的对象是否符合所述总体标准。
第二方面,本发明实施例提供一种认定系统,所述系统包括:
认定标准获取模块,用于获取预设类别的认定标准;
对象数据获取模块,用于获取待认定的对象的数据;
标准对应的数据获取模块,用于从所述待认定的对象的数据中获取所述认定标准对应的数据;
数据变化检测模块,用于将所述待认定的对象的所述认定标准对应的数据与上一次认定时所述待认定的对象的所述认定标准对应的数据进行比较并判断是否发生了变化:是,则转到跟踪认定判断模块执行;否,则转到复制认定结果模块执行;
跟踪认定判断模块,用于判断所述认定标准对应的数据是否符合所述认定标准;
复制认定结果模块,用于将所述待认定的对象的上一次认定结果作为所述待认定的对象的本次认定结果;
结果反馈模块,用于判断认定结果的变化,并发送给所述待认定的对象;
跟踪控制模块,用于获取预设时间段或预设时间点,每隔预设时间段或达到预设时间点就重新执行所述认定系统中的所有模块。
优选地,
所述对象数据获取模块包括:
数据源获取模块,用于获取数据源;
对象数据检索模块,用于从所述数据源中检索并获取所述待认定的对象的数据;
所述标准对应的数据获取模块包括:
数据筛选模块,用于从所述待认定的对象的数据中筛选出所述认定标准对应的数据作为第一数据;
数据清洗模块,用于从所述第一数据中提取与每一项标准对应的数据作为所述每一项标准对应的第二数据。
优选地,
所述跟踪认定判断模块包括:
子标准获取模块,用于获取所述认定标准中每一项标准和总体标准;
对应数据提取模块,用于从所述第一数据中提取所述每一项标准对应的所述第二数据;
对应数据变化检测模块,用于将所述待认定的对象的所述每一项标准对应的第二数据与上一次认定时所述待认定的对象的所述每一项标准对应的第二数据进行比较并判断是否发生了变化:是,则跳转到每一项标准对应的预设模型获取模块或每一项标准判断模块执行;否,则跳转到对应数据提取模块或总体标准对应的预设模型获取模块执行;
每一项标准对应的预设模型获取模块,用于获取所述每一项标准对应的预设模型;
每一项标准对应的第三数据生成模块,用于根据所述每一项标准对应的所述第二数据和所述每一项标准对应的所述预设模型,计算得到所述每一项标准对应的第三数据;
每一项标准判断模块,用于根据所述每一标准对应的第三数据和预设范围和预设范围,判断所述待认定的对象是否符合所述每一项标准;
总体标准对应的预设模型获取模块,用于获取所述总体标准对应的预设模型;
总体标准判断模块,用于根据所述每一项标准对应的第三数据、所述总体标准对应的预设模型和预设范围,判断所述待认定的对象是否符合所述总体标准;
综合判断模块,用于判断所述待认定的对象是否符合所述认定标准中所述每一项标准和所述总体标准。
第三方面,本发明实施例提供一种机器人系统,所述机器人中分别配置有如第二方面任一项所述的认定系统。
本发明实施例具有的优点和有益效果包括:
1、本发明实施例对已进行过认定的企业进行定期或不定期或实时地自动跟踪认定,能够检测到对象在认定之后的时间内是否还符合认定的要求,从而可以更新认定的结果,使得认定的结果具有时效性,当过去认定的结果不符合对象现在实际的情况时,对认定的结果进行更新。而现有技术下进行认定(例如高新企业认定、人才认定等等)都是一次性的,对象在认定通过之后的一段时间内可能不再符合认定的要求,但并不会影响之前认定的结果,这样就会导致认定的结果不具有时效性,也就是说过去认定的结果不一定符合对象现在实际的情况,这样就会使得认定失去可信性和意义。
2、本发明实施例对认定不通过的对象也进行跟踪认定,一旦发现所述对象满足认定的标准之后会主动邀请所述对象重新申请认定或直接通知所述对象已经通过了认定,从而使得认定的结果更全面。而现有技术中有的对象在认定不通过之后,努力进取,经过一定的时间努力之后,虽然已经达到了认定的标准,但因为之前的认定失败,对象一直迟迟不敢再次申请认定,甚至可能因为之前认定失败而失去信心而一直不再申请认定,这样就会到导致已经达到认定标准的对象因为没有再次申请认定而一直处于未认定的状态,从而会导致认定的结果不全面。
3、本发明实施例只在已通过认定的对象在发展过程中不再符合认定的标准时才通知对象进行整改,这一方面可以提醒企业自动地改进,另一方面也节省了对象的时间和人力物力,因为如果在跟踪认定的过程中,对象一直符合认定的标准,就没有必要再次申请认定,其上次认定通过的结果也就仍然有效,而不需要过一段时间之后又需要重新申请认定,从而也减少和降低了认定主管部门的工作量。而现有技术中认定通过的结果只在一定的时间段内有效,过期后需要重新认定,这一方面会浪费已认定通过的对象的时间和人力物力来重新申请认定,同时也浪费了认定主管单位的时间和人力物力,因为如果已认定通过的对象的数据变化没有影响到认定的结果,那么就没有必要重新申请认定,从而导致现有认定技术的成本高、效率低。
4、本发明实施例在平时不断地进行跟踪认定,来不断提醒某些项标准没有通过或总体没有通过认定的对象进行整改,从而避免了对象最终不能通过认定的悲剧局面,所以跟踪认定是在帮忙被认定对象最终能够通过认定,能够提高被认定对象的获得感和安全感,降低被认定对象为了通过认定而找关系和作假等违法行为发生的可能性。而现有技术都是在认定主管部门规定的认定时间进行认定,导致被认定的对象在平时没压力、不努力,在认定时为时已晚,临时努力也无济于事,导致了有些被认定的对象为了认定通过而铤而走险,做出找关系、作假等违法行为。
5、本发明实施例跟踪认定的结果可以辅助认定专家的评审:
(1)本发明实施例基于大数据结合认定标准进行智能分析来判断对象是否可以认定为预设类别来辅助专家进行评审,能降低专家评审的工作量,提高专家认定的效率。
(2)本发明实施例采用深度学习技术基于历史大数据自动生成用于认定的预设模型,可以进一步提高认定的智能性和准确性。
(3)本发明实施例通过认定方法和系统能够筛选出符合预设类别认定标准的数据和对象,供评审专家参考,这样可以提高评审专家评审的速度,降低评审专家评审的工作量。
(4)本发明实施例通过认定方法和系统能够筛选出不符合预设类别认定标准的数据和对象,供评审专家参考,这样可以使得评审专家对不符合条件的数据和对象更加严格的评审,从而提高评审的准确率。
本发明实施例提供的基于大数据和深度学习的跟踪认定方法和机器人系统,包括:获取预设类别的认定标准,获取待认定的对象的数据,从所述对象的数据中获取所述认定标准对应的数据,将所述待认定的对象的所述认定标准对应的数据与上一次认定时所述待认定的对象的所述认定标准对应的数据进行比较并判断是否发生了变化:是,则转到跟踪认定判断步骤执行;否,则转到复制认定结果步骤执行。本发明实施例能够实时地根据对象实际数据来及时更新认定的结果,并提醒对象进行整改或邀请对象再次申请认定。上述方法和系统通过基于大数据和深度学习的跟踪认定技术,提高了认定的时效性、客观性、可信度和效率,并降低了认定的成本。
附图说明
图1为本发明的实施例1提供的认定方法的流程图;
图2为本发明的实施例4提供的跟踪认定判断步骤的流程图;
图3为本发明的实施例5提供的每一项标准对应的预设模型获取步骤的流程图;
图4为本发明的实施例5提供的总体标准对应的预设模型获取步骤的流程图;
图5为本发明的实施例7提供的认定系统的原理框图;
图6为本发明的实施例10提供的跟踪认定判断模块的原理框图;
图7为本发明的实施例11提供的每一项标准对应的预设模型获取模块的原理框图;
图8为本发明的实施例11提供的总体标准对应的预设模型获取模块的原理框图。
具体实施方式
下面结合本发明实施方式,对本发明实施例中的技术方案进行详细地描述。
(一)本发明的各种实施例中的方法包括以下步骤的各种组合:
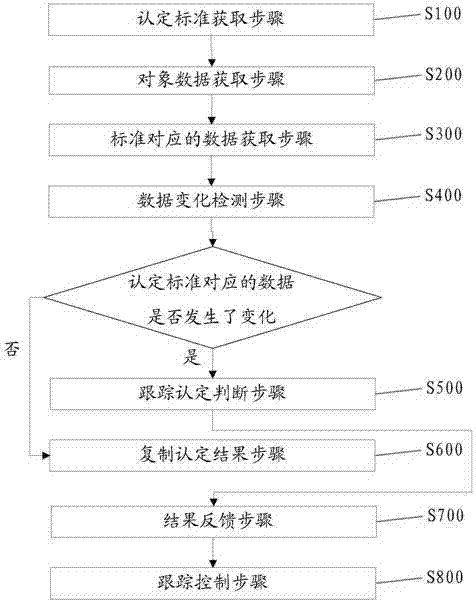
认定标准获取步骤s100:获取预设类别的认定标准。
预设类别的认定标准就是将一个对象认定为预设类别对象的标准,例如将一个企业认定为高新企业的标准。所述预设类别例如高新技术企业,又如三好学生,又如优秀教师等等。
例如,国家对高新企业认定的标准一般如下,各个地方的认定标准与国家高新企业的认定标准会大同小异:1、企业申请认定时须注册成立一年以上;2、企业通过自主研发、受让、受赠、并购等方式,获得对其主要产品(服务)在技术上发挥核心支持作用的知识产权的所有权;3、对企业主要产品(服务)发挥核心支持作用的技术属于《国家重点支持的高新技术领域》规定的范围;4、企业从事研发和相关技术创新活动的科技人员占企业当年职工总数的比例不低于10%;5、企业近三个会计年度(实际经营期不满三年的按实际经营时间计算,下同)的研究开发费用总额占同期销售收入总额的比例符合如下要求:(1)最近一年销售收入小于5,000万元(含)的企业,比例不低于5%;(2)最近一年销售收入在5,000万元至2亿元(含)的企业,比例不低于4%;(3)最近一年销售收入在2亿元以上的企业,比例不低于3%.其中,企业在中国境内发生的研究开发费用总额占全部研究开发费用总额的比例不低于60%;6、近一年高新技术产品(服务)收入占企业同期总收入的比例不低于60%;7、企业创新能力评价应达到相应要求;8、企业申请认定前一年内未发生重大安全、重大质量事故或严重环境违法行为。
对象数据获取步骤s200:获取待认定的对象的数据。待认定的对象指的就是待跟踪认定的对象。所述对象例如企业、学生、教师等等。例如需要认定企业是否为高新技术企业,又如需要认定一个学生是否为三好学生,又如需要认定一个教师是否为优秀教师等等。待认定的对象包括已进行过认定且认定通过的对象、已进行过认定且认定未通过的对象,还可以包括未进行过认定的对象。待认定的对象可以是申请认定的对象,也可以是未申请认定的对象。对待认定的对象进行跟踪认定时,无需待认定的对象去申请认定;不管待认定的对象是否申请认定,都会对待认定的对象每隔一段时间就进行跟踪认定。
对象数据获取步骤s200包括数据源获取步骤s210、对象数据检索步骤s220。
数据源获取步骤s210:获取数据源。所述数据源包括对象提供的数据、第三方提供的数据。对象提供的数据指所述对象提供的数据。第三方提供的数据包括政府部门、行业协会、知识产权局等部门存储的对象数据。数据源的提供方式包括数据检索与获取接口。通过所述接口通过计算机程序就能自动检索和获取相关数据。数据源一般为在线数据源,通过互联网可以远程获取在线数据源中的数据。所述数据源可以包括分布在不同部门的多个数据源。
对象数据检索步骤s220:从数据源中检索并获取所述对象的数据。因为数据源中包含有很多对象的数据和其他数据,如果整体获取下来再检索会花费过多的网络传输时间,所以需要先检索出所述对象的数据,再将所述对象的数据获取到本地。当有多个数据源时,要分别从多个数据源检索出所述对象的数据,然后分别下载到本地。
标准对应的数据获取步骤s300:从所述待认定的对象的数据中获取所述认定标准对应的数据。
标准对应的数据获取步骤s300包括数据筛选步骤s310、数据清洗步骤s320。
数据筛选步骤s310:根据所述认定标准,从所述对象的数据中筛选出所述对象对应的第一数据。所述对象的数据包括有各种数据,其中数据不一定都与预设类别认定标准有关,所以需要从所述对象的数据中检索出与预设类别认定标准有关的数据,作为所述对象对应的第一数据。预设类别认定标准有多项,各项标准对应的数据可能在不同的数据源中,例如财务数据在工商部门提供的数据源中,知识产权数据在知识产权局提供数据源中,质检数据在质检部门提供的数据源中,安全数据在公安部门提供的数据源中,所以更优的方式是,获取数据源中数据类别与各项标准之间的预设对应关系,从所述对象的数据中获取每一数据源对应的数据,从所述每一数据源对应的数据中检索出与所述每一数据源对应的标准相关的数据。例如知识产权部门提供的数据源对应的标准是知识产权标准,从知识产权部门提供的数据源中包括这个对象的知识产权的缴费数据、申请数据、受理数据、授权数据,其中“申请数据、受理数据、授权数据”这三个类别的数据与预设类别认定的知识产权标准有关,则在知识产权部门提供的数据源中所述三个数据类别与预设类别认定的知识产权标准之间的建立对应关系,作为所述预设的对应关系。
数据清洗步骤s320:从所述第一数据中提取每一项标准对应的第二数据。将第一数据中与每一项标准对应的数据作为第二数据。判断所述每一项标准对应的第二数据是否存在:否,则向用户发送缺少所述每一项标准对应的第二数据的提醒信息;是,则判断所述每一项标准对应的第二数据是否唯一:否,则判断所述每一项标准对应的多个第二数据之间是否一致:否,则保留所述多个第二数据中可信度最高的第二数据,删除所述多个第二数据中其他第二数据。从所述第一数据中提取的所述每一项标准对应的第二数据是所述第一数据中与所述每一项标准对应的数据。
数据清洗步骤s320中所述保留所述多个第二数据中可信度最高的第二数据,删除所述多个第二数据中其他第二数据的步骤包括对应数据源获取步骤s321、可信度获取步骤s322、可信度选取步骤s323。
对应数据源获取步骤s321:获取所述多个第二数据中每个第二数据对应的数据源。因为第一数据是从数据源获取的,而第二数据又是从第一数据中提取的,所以可以获取到每个第二数据对应的数据源。
可信度获取步骤s322:获取所述每个第二数据对应的数据源的可信度。所述可信度可以预先设置。例如公安部门的数据源的可信度为100%,工商部门的数据源的可信度为99%,知识产权部门的数据源的可信度为98%,对象自身提供的数据源的可信度为80%。预先设置所述可信度的方式包括由专家对可信度进行设置,还包括自动生成所述可信度。
可信度获取步骤s322中所述自动生成可信度的步骤包括:将所有数据源的可信度初始化为初始值,例如50%。从历史大数据中获取每个对象的所述第一数据和已清洗得到的第二数据。将所述已清洗得到的第二数据对应的数据源的可信度增加预设值,将所述第一数据中与已清洗得到的第二数据一致的其他第二数据对应的数据源的可信度增加预设值,例如0.1%,将所述第一数据中与已清洗得到的第二数据不一致的其他第二数据对应的数据源的可信度减少预设值,例如0.05%。当所述第二数据对应的数据源的可信度达到100%时,则不再增加预设值;当所述第二数据对应的数据源的可信度减少到0%时,则不再建设预设值。这样就能够使得不同的数据源的可信度根据历史第二数据是否正确而进行增减,从而形成不同数据源的不同可信度。所述已清洗得到的第二数据指的是通过人工方式或其他方式确认的正确的第二数据。可见,在尚不清楚各个数据源的可信度之前的多次预设类别认定时,需要人工的方式来进行数据的清洗,然后就可以根据这些历史数据来分析得到各个数据源的可信度。
可信度选取步骤s323:从所述每个第二数据对应的数据源的可信度中选取最高的可信度。保留所述多个第二数据中所述最高可信度对应的第二数据,删除所述多个第二数据中所述最高可信度对应的第二数据以外的其他第二数据。这样就能够在多个第二数据相互冲突时,保留最可信的数据,而将其他的相互冲突的数据删除。
数据变化检测步骤s400:判断所述待认定的对象在本次认定之前是否被认定过:
是(被认定过的情况),则将所述待认定的对象的所述认定标准对应的数据与上一次认定时所述待认定的对象的所述认定标准对应的数据进行比较并判断是否发生了变化:是,则转到跟踪认定判断步骤s500执行;否,则转到复制认定结果步骤s600执行;
否(未被认定过的情况),则转到跟踪认定判断步骤s500执行。如果所述待认定的对象在本次认定之前从未被认定过,那么本次认定就是第一次认定,上次的认定不存在,自然就无法和上次的认定进行比较了,所以如果本次认定是所述待认定的对象第一次被认定,本步骤则转到跟踪认定判断步骤s500执行。
跟踪认定判断步骤s500:判断所述认定标准对应的数据是否符合所述认定标准:是,则判断所述待认定的对象属于预设类别;否,则判断所述待认定的对象不属于预设类别。
认定判断步骤s500包括子标准获取步骤s510、对应数据提取步骤s520、对应数据变化检测步骤s530、每一项标准对应的预设模型获取步骤s540、每一项标准对应的第三数据生成步骤s550、每一项标准判断步骤s560、总体标准对应的预设模型获取步骤s570、总体标准判断步骤s580、综合判断步骤s590。
子标准获取步骤s510:获取所述认定标准中每一项标准和总体标准。
对应数据提取步骤s520:从所述第一数据中提取所述每一项标准对应的第二数据。
对应数据变化检测步骤s530:将所述待认定的对象的所述每一项标准对应的第二数据与上一次认定时所述待认定的对象的所述每一项标准对应的第二数据进行比较并判断是否发生了变化:
是,则判断所述每一项标准对应的第二数据是否存在:是,则跳转到s540继续执行;否,则将所述每一项标准对应的第三数据设置为空,然后跳转到s560继续执行。
否,则获取所述待认定的对象的上一次认定时是否符合所述每一项标准的结果作为所述待认定的对象的本次是否符合所述每一项标准的结果,然后不再继续执行s540、s550、s560。所述待认定的对象的上一次是否符合所述每一项标准的结果包括符合、不符合。
每一项标准对应的预设模型获取步骤s540:获取所述每一项标准对应的预设模型。所述预设模型包括公式或算法或深度学习模型。
当所述预设模型是深度学习模型时,每一项标准对应的预设模型获取步骤s540包括每一项标准对应的深度学习模型初始化步骤s541、每一项标准对应的历史数据获取步骤s542、第二深度学习模型生成步骤s543、第三深度学习模型生成步骤s544、每一项标准对应的预设深度学习模型设置步骤s545。
每一项标准对应的深度学习模型初始化步骤s541:初始化所述每一项标准对应的深度学习模型,将所述深度学习模型的输入格式设置为所述每一项标准对应的第二数据的格式,将所述深度学习模型的输出格式设置为所述每一项标准对应的第三数据的格式,通过初始化得到的所述深度学习模型作为第一深度学习模型。
每一项标准对应的历史数据获取步骤s542:从历史大数据中获取所述每一项标准对应的已进行过认定的每一对象的第二数据和第三数据。历史大数据是指大量的历史数据或积累了较长时间的数据。待认定的对象,包括已进行过认定通过的对象、已进行过认定但认定未通过的对象。其中,第三数据可以是所述每一项标准对应的评分或评价结果或其他能反映出所述第二数据符合所述每一项标准的程度的数值。程度可以是一个百分比,例如0%到100%,0%表示完全不符合,100%表示完全符合。
第二深度学习模型生成步骤s543:将所述每一项标准对应的已进行过认定的每一对象的第二数据作为所述第一深度学习模型的输入数据,对所述第一深度学习模型进行无监督训练,通过无监督训练得到的所述第一深度学习模型作为第二深度学习模型。
第三深度学习模型生成步骤s544:将所述每一项标准对应的已进行过认定的每一对象的第二数据和第三数据分别作为所述第二深度学习模型的输入数据和输出数据,对所述第二深度学习模型进行有监督训练。将所述每一项标准对应的已进行过认定的每一对象的第二数据和第三数据分别作为所述第二深度学习模型的输入数据和输出数据,指的是将所述每一项标准对应的已进行过认定的每一对象的第二数据作为所述第二深度学习模型的输入数据,将所述每一项标准对应的已进行过认定的所述每一对象的第三数据作为所述第二深度学习模型的输出数据,通过有监督训练得到的所述第二深度学习模型作为第三深度学习模型。
每一项标准对应的预设模型设置步骤s545:将所述第三深度学习模型作为所述每一项标准对应的预设模型。
每一项标准对应的第三数据生成步骤s550:根据所述每一项标准对应的第二数据和所述每一项标准对应的预设模型,计算得到所述每一项标准对应的第三数据。在计算机上执行所述每一项标准对应的预设模型,将所述每一项标准对应的第二数据作为所述每一项标准对应的预设模型的输入,计算得到的输出作为所述每一项标准对应的第三数据。优选地,将所述每一项标准对应的第二数据作为所述每一项标准对应的所述第三深度学习模型的输入,计算得到的所述第三深度学习模型的输出作为所述每一项标准对应的第三数据。其中,第三数据可以是所述每一项标准对应的评分或评价结果或其他能反映出所述第二数据符合所述每一项标准的程度的数值。
每一项标准判断步骤s560:根据所述每一标准对应的第三数据和预设范围,判断所述待认定的对象是否符合所述每一项标准。
每一项标准判断步骤s560包括每一项标准对应的预设范围获取步骤s561、每一项标准对应的第三数据判断步骤s562、每一项标准对应的变化提醒步骤s563。
每一项标准对应的预设范围获取步骤s561:获取所述每一项标准对应的预设范围。不同的标准对应的预设范围不同,有的是硬性的标准,则有固定的范围,而有的标准不是硬性的标准,则范围设为从负无穷到正无穷。如果一个标准不是硬性的标准,则这个标准对应的结果都在所述预设范围内。但不论一个标准是否是硬性的标准都会对所述待认定的对象是否能通过认定产生影响,因为会对最终总体评分产生影响,而总体评分对应的总体标准一般都会有一个范围,例如大于80分。
每一项标准对应的第三数据判断步骤s562:判断所述每一项标准对应的第三数据是否为空:
是,则判断所述每一项标准对应的预设范围是否为从负无穷到正无穷:是,则判定所述待认定的对象符合所述每一项标准;否,则判定所述待认定的对象不符合所述每一项标准;
否:则判断所述每一项标准对应的第三数据是否在所述每一项标准对应的预设范围中:是,则判定所述待认定的对象符合所述每一项标准;否,则判定所述待认定的对象不符合所述每一项标准。
每一项标准对应的变化提醒步骤s563:判断所述待认定的对象在本次认定之前是否被认定过:是,则判断所述待认定的对象在是否符合所述每一项标准方面的变化,并将变化信息发送给所述待认定的对象。如果所述待认定的对象在本次认定之前从未被认定过,那么本次认定就是第一次认定,上次的认定不存在,自然就无法和上次的认定进行比较了,所以如果本次认定是所述待认定的对象第一次被认定,本步骤就无需继续执行。
如果所述待认定的对象以前被认定过,那么比较并判断所述待认定的对象在本次认定时是否符合所述每一项标准的结果与所述待认定的对象在上次认定时是否符合所述每一项标准的结果是否有变化:是,则将是否符合所述每一项标准的结果的变化通知所述待认定的对象,判断所述本次认定时是否符合所述每一项标准的结果是否为认定通过:否,则通知所述待认定的对象参照所述每一项标准进行整改。是否符合所述每一项标准的结果包括符合所述每一项标准的结果、不符合所述每一项标准的结果。例如所述待认定的对象在本次认定时是否符合所述每一项标准的结果是所述待认定的对象符合所述每一项标准,而所述待认定的对象在上次认定时是否符合所述每一项标准的结果是所述待认定的对象不符合所述每一项标准,则表明发生了变化;或者所述待认定的对象在本次认定时是否符合所述每一项标准的结果是所述待认定的对象不符合所述每一项标准,而所述待认定的对象在上次认定时是否符合所述每一项标准的结果是所述待认定的对象符合所述每一项标准,则表明发生了变化。
总体标准对应的预设模型获取步骤s570:获取所述总体标准对应的预设模型。所述预设模型包括公式或算法或深度学习模型。因为数据变化检测步骤s400中已经检测到了变化才执行s500,从而才会执行s570,因为数据发生了变化,那么必然存在某一项或某几项标准对应的第二数据发生了变化,从而必然会导致第三数据发生变化,从而会影响总体标准判断的结果,所以无论所述待认定的对象是否符合所述每一项标准的判断结果是否发生变化,对所述待认定的对象是否符合所述总体标准的判断结果都是有可能发生变化的,所以一旦数据变化检测步骤s400中已经检测到了变化,则对所述待认定的对象是否符合所述总体标准的判断步骤必不可少的。
当所述预设模型是深度学习模型时,总体标准对应的预设模型获取步骤s570包括总体标准对应的深度学习模型初始化步骤s571、总体标准对应的历史数据获取步骤s572、第五深度学习模型生成步骤s573、第六深度学习模型生成步骤s574、总体标准对应的预设模型设置步骤s575:
总体标准对应的深度学习模型初始化步骤s571:初始化所述总体标准对应的深度学习模型,将所述深度学习模型的输入格式设置为所述认定标准中每一项标准对应的第三数据的集合的格式,将所述深度学习模型的输出格式设置为所述总体标准对应的第三数据的格式,通过初始化得到的所述深度学习模型作为第四深度学习模型。
总体标准对应的历史数据获取步骤s572:从历史大数据中获取所述已进行过认定的每一对象的所述认定标准中每一项标准对应的第三数据的集合和所述总体标准对应的第三数据。其中,每一项标准对应的第三数据可以是所述每一项标准对应的评分或评价结果或其他能反映出所述第二数据符合所述每一项标准的程度的数值。总体标准对应的第三数据可以是所述总体标准对应的评分或评价结果或其他能反映出所述每一项标准对应的第三数据符合所述总体标准的程度的数值。
第五深度学习模型生成步骤s573:将所述认定标准中每一项标准对应的已进行过认定的每一对象的第三数据的集合作为所述深度学习模型的输入数据,对所述第四深度学习模型进行无监督训练,通过无监督训练得到的所述第四深度学习模型作为第五深度学习模型。
第六深度学习模型生成步骤s574:将所述已进行过认定的每一对象的所述认定标准中每一项标准对应的第三数据的集合和所述总体标准对应的第三数据分别作为所述第五深度学习模型的输入数据和输出数据,对所述第五深度学习模型进行有监督训练。将所述认定标准中每一项标准对应的已进行过认定的每一对象的第三数据的集合和所述总体标准对应的第三数据分别作为所述第五深度学习模型的输入数据和输出数据,指的是将每一项标准对应的已进行过认定的每一对象的第三数据作为所述第五深度学习模型的输入数据,将所述总体标准对应的已进行过认定的所述每一对象的第三数据作为所述第五深度学习模型的输出数据,通过有监督训练得到的所述第五深度学习模型作为第六深度学习模型。
总体标准对应的预设模型设置步骤s575:将所述第六深度学习模型作为所述总体标准对应的预设模型。
总体标准判断步骤s580:根据所述每一项标准对应的第三数据、所述总体标准对应的预设模型和预设范围,判断所述待认定的对象是否符合所述总体标准。
总体标准判断步骤s580包括总体标准对应的第三数据生成步骤s581、总体标准对应的预设范围获取步骤s582、总体标准对应的第三数据判断步骤s583。
总体标准对应的第三数据生成步骤s581:根据所述每一项标准对应的第三数据和所述总体标准对应的预设模型,计算得到所述总体标准对应的第三数据。在计算机上执行所述每一项标准对应的预设模型,将所述每一项标准对应的第三数据作为所述总体标准对应的预设模型的输入,计算得到的输出作为所述总体标准对应的第三数据。优选地,将所述每一项标准对应的第三数据作为所述总体标准对应的所述第六深度学习模型的输入,计算得到的所述第六深度学习模型的输出作为所述总体标准对应的第三数据。其中,每一项标准对应的第三数据可以是所述每一项标准对应的评分或评价结果或其他能反映出所述第二数据符合所述每一项标准的程度的数值。总体标准对应的第三数据可以是所述总体标准对应的评分或评价结果或其他能反映出所述每一项标准对应的第三数据符合所述总体标准的程度的数值。
总体标准对应的预设范围获取步骤s582:获取所述总体标准对应的预设范围。总体标准对应的总体评分一般都会有一个范围,例如大于80分。
总体标准对应的第三数据判断步骤s583:判断所述总体标准对应的第三数据是否在所述总体标准对应的预设范围中:是,则判断所述待认定的对象符合所述总体标准;否,则判断所述待认定的对象不符合所述总体标准。
综合判断步骤s590:判断所述待认定的对象是否符合所述认定标准中每一项标准和总体标准:是,则判断所述待认定的对象属于预设类别,即所述待认定的对象本次认定的结果为认定通过;否,则判断所述待认定的对象不属于预设类别,即所述待认定的对象本次认定的结果为认定不通过。符合所述认定标准中每一项标准和总体标准指的是同时符合所述认定标准中每一项标准和总体标准。如果有某一项标准或总体标准不符合,则判断所述待认定的对象不属于预设类别。
复制认定结果步骤s600:将所述待认定的对象的上一次认定结果作为所述待认定的对象的本次认定结果。认定结果包括认定通过、认定不通过。上一次指的是本次之前的上一次认定,上一次认定可能是第一次认定,也可能是传统方式的认定,也可能是跟踪认定。
结果反馈步骤s700:判断所述待认定的对象在本次认定之前是否被认定过:是,则判断认定结果的变化,并发送给所述待认定的对象;否,则将本次认定的结果发送给所述待认定的对象。
如果所述待认定的对象在本次认定之前从未被认定过,那么本次认定就是第一次认定,上次的认定不存在,自然就无法和上次的认定结果进行比较了,所以如果本次认定是所述待认定的对象第一次被认定,本步骤只需要将本次认定的结果发送给所述待认定的对象。
如果所述待认定的对象以前被认定过,那么比较并判断所述待认定的对象在本次认定的结果与所述待认定的对象在上次认定的结果是否有变化:是,则将变化的结果通知所述待认定的对象,判断所述本次认定的结果是否为认定通过:
是(上次认定未通过,本次认定通过的情况),则通知待认定的对象已经通过认定或通知邀请所述待认定的对象走申请认定的流程。因为这是系统的自动判断,而实际认定过程中需要一些行政手续,例如待认定的对象的单位盖章的一些申请材料,所以有些类别的认定需要通知所述待认定的对象走申请认定的流程。
否(上次认定通过,本次认定未通过的情况),则通知所述待认定的对象进行整改并等待下次跟踪认定。例如本次认定的结果是所述待认定的对象属于预设类别,而上次认定的结果是所述待认定的对象不属于预设类别,则表明发生了变化,是从上次的认定通过变成了本次的认定不通过;或者本次认定的结果是所述待认定的对象不属于预设类别,而上次认定的结果是所述待认定的对象属于预设类别,则表明发生了变化,是从上次的认定通过变成了本次的认定不通过。
跟踪控制步骤s800,用于获取预设时间段或预设时间点,每隔预设时间段或达到预设时间点就重新执行跟踪认定方法中的所有步骤。
上述步骤可以在spark等大数据平台上执行,以加快大数据处理的速度。
(二)本发明的各种实施例中的系统包括以下模块的各种组合:
认定标准获取模块100执行认定标准获取步骤s100。
执行对象数据获取模块200执行对象数据获取步骤s200。
对象数据获取模块200包括数据源获取模块210、对象数据检索模块220。
数据源获取模块210执行数据源获取步骤s210。
对象数据检索模块220执行对象数据检索步骤s220。
标准对应的数据获取模块300执行标准对应的数据获取步骤s300。
标准对应的数据获取模块300包括数据筛选模块310、数据清洗模块320。
数据筛选模块310执行数据筛选步骤s310。
数据清洗模块320执行数据清洗步骤s320。
数据清洗模块320包括对应数据源获取模块321、可信度获取模块322、可信度选取模块323。
对应数据源获取模块321执行对应数据源获取步骤s321。
可信度获取模块322执行可信度获取步骤s322。
可信度选取模块323执行可信度选取步骤s323。
数据变化检测模块400执行数据变化检测步骤s400。
跟踪认定判断模块500执行跟踪认定判断步骤s500。
跟踪认定判断模块500包括子标准获取模块510、对应数据提取模块520、对应数据变化检测模块530、每一项标准对应的预设模型获取模块540、每一项标准对应的第三数据生成模块550、每一项标准判断模块560、总体标准对应的预设模型获取模块570、总体标准判断模块580、综合判断模块590。
子标准获取模块510执行子标准获取步骤s510。
对应数据提取模块520执行对应数据提取步骤s520。
对应数据变化检测模块530执行对应数据变化检测步骤s530。
每一项标准对应的预设模型获取模块540执行每一项标准对应的预设模型获取步骤s540。
每一项标准对应的预设模型获取模块540包括每一项标准对应的深度学习模型初始化模块541、每一项标准对应的历史数据获取模块542、第二深度学习模型生成模块543、第三深度学习模型生成模块544、每一项标准对应的预设深度学习模型设置模块545。
每一项标准对应的深度学习模型初始化模块541执行每一项标准对应的深度学习模型初始化步骤s541。
每一项标准对应的历史数据获取模块542执行每一项标准对应的历史数据获取步骤s542。
第二深度学习模型生成模块543执行第二深度学习模型生成步骤s543。
第三深度学习模型生成模块544执行第三深度学习模型生成步骤s544。
每一项标准对应的预设深度学习模型设置模块545执行每一项标准对应的预设模型设置步骤s545。
每一项标准对应的第三数据生成模块550执行每一项标准对应的第三数据生成步骤s550。
每一项标准判断模块560执行每一项标准判断步骤s560。
每一项标准判断模块560包括每一项标准对应的预设范围获取模块561、每一项标准对应的第三数据判断模块562、每一项标准对应的变化提醒模块563。
每一项标准对应的预设范围获取模块561执行每一项标准对应的预设范围获取步骤s561。
每一项标准对应的第三数据判断模块562执行每一项标准对应的第三数据判断步骤s562。
每一项标准对应的变化提醒模块563执行每一项标准对应的变化提醒步骤s563。
总体标准对应的预设模型获取模块570执行总体标准对应的预设模型获取步骤s570。
总体标准对应的预设模型获取模块570包括总体标准对应的深度学习模型初始化模块571、总体标准对应的历史数据获取模块572、第五深度学习模型生成模块573、第六深度学习模型生成模块574、总体标准对应的预设模型设置模块575:
总体标准对应的深度学习模型初始化模块571执行总体标准对应的深度学习模型初始化步骤s571。
总体标准对应的历史数据获取模块572执行总体标准对应的历史数据获取步骤s572。
第五深度学习模型生成模块573执行第五深度学习模型生成步骤s573。
第六深度学习模型生成模块574执行第六深度学习模型生成步骤s574。
总体标准对应的预设模型设置模块575执行总体标准对应的预设模型设置步骤s575。
总体标准判断模块580执行总体标准判断步骤s580。
总体标准判断模块580包括总体标准对应的第三数据生成模块581、总体标准对应的预设范围获取模块582、总体标准对应的第三数据判断模块583。
总体标准对应的第三数据生成模块581执行总体标准对应的第三数据生成步骤s581。
总体标准对应的预设范围获取模块582执行总体标准对应的预设范围获取步骤s582。
总体标准对应的第三数据判断模块583执行总体标准对应的第三数据判断步骤s583。
综合判断模块590执行综合判断步骤s590。
复制认定结果模块600执行复制认定结果步骤s600。
结果反馈模块700执行结果反馈步骤s700。
跟踪控制模块800执行跟踪控制步骤s800。
上述模块可以在spark等大数据平台上部署,以加快大数据处理的速度。
(三)本发明的几种实施例
实施例1提供一种认定方法,所述认定方法包括认定标准获取步骤s100、对象数据获取步骤s200、标准对应的数据获取步骤s300、数据变化检测步骤s400、跟踪认定判断步骤s500、复制认定结果步骤s600,如图1所示。
实施例2提供一种认定方法,包括实施例1中所述方法的各步骤;其中,对象数据获取步骤s200包括数据源获取步骤s210、对象数据检索s220,标准对应的数据获取步骤s300包括数据筛选步骤s310、数据清洗步骤s320。
实施例3提供一种认定方法,包括实施例2中所述方法的各步骤;其中,数据清洗步骤s320包括对应数据源获取步骤s321、可信度获取步骤s322、可信度选取步骤s323。
实施例4提供一种认定方法,包括实施例2中所述方法的各步骤;其中,跟踪认定判断步骤s500包括子标准获取步骤s510、对应数据提取步骤s520、对应数据变化检测步骤s530、每一项标准对应的预设模型获取步骤s540、每一项标准对应的第三数据生成步骤s550、每一项标准判断步骤s560、总体标准对应的预设模型获取步骤s570、总体标准判断步骤s580、综合判断步骤s590,如图2所示。
实施例5提供一种认定方法,包括实施例4中所述方法的各步骤;其中,每一项标准对应的预设模型获取步骤s540包括每一项标准对应的深度学习模型初始化步骤s541、每一项标准对应的历史数据获取步骤s542、第二深度学习模型生成步骤s543、第三深度学习模型生成步骤s544、每一项标准对应的预设深度学习模型设置步骤s545,如图3所示;总体标准对应的预设模型获取步骤s570包括总体标准对应的深度学习模型初始化步骤s571、总体标准对应的历史数据获取步骤s572、第五深度学习模型生成步骤s573、第六深度学习模型生成步骤s574、总体标准对应的预设模型设置步骤s575,如图4所示。
实施例6提供一种认定方法,包括实施例4中所述方法的各步骤;其中,每一项标准判断步骤s560包括每一项标准对应的预设范围获取步骤s561、每一项标准对应的第三数据判断步骤s562、每一项标准对应的变化提醒步骤s563;总体标准判断步骤s580包括总体标准对应的第三数据生成步骤s581、总体标准对应的预设范围获取步骤s582、总体标准对应的第三数据判断步骤s583。
实施例7提供一种认定系统,所述认定系统包括认定标准获取模块100、对象数据获取模块200、标准对应的数据获取模块300、数据变化检测模块400、跟踪认定判断模块500、复制认定结果模块600,如图5所示。
实施例8提供一种认定系统,包括实施例7中所述系统的各步骤;其中,对象数据获取模块200包括数据源获取模块210、对象数据检索s220,标准对应的数据获取模块300包括数据筛选模块310、数据清洗模块320。
实施例9提供一种认定系统,包括实施例8中所述系统的各步骤;其中,数据清洗模块320包括对应数据源获取模块321、可信度获取模块322、可信度选取模块323。
实施例10提供一种认定系统,包括实施例8中所述系统的各步骤;其中,跟踪认定判断模块500包括子标准获取模块510、对应数据提取模块520、对应数据变化检测模块530、每一项标准对应的预设模型获取模块540、每一项标准对应的第三数据生成模块550、每一项标准判断模块560、总体标准对应的预设模型获取模块570、总体标准判断模块580、综合判断模块590,如图6所示。
实施例11提供一种认定系统,包括实施例10中所述系统的各步骤;其中,每一项标准对应的预设模型获取模块540包括每一项标准对应的深度学习模型初始化模块541、每一项标准对应的历史数据获取模块542、第二深度学习模型生成模块543、第三深度学习模型生成模块544、每一项标准对应的预设深度学习模型设置模块545,如图7所示;总体标准对应的预设模型获取模块570包括总体标准对应的深度学习模型初始化模块571、总体标准对应的历史数据获取模块572、第五深度学习模型生成模块573、第六深度学习模型生成模块574、总体标准对应的预设模型设置模块575,如图8所示。
实施例12提供一种认定系统,包括实施例10中所述系统的各步骤;其中,每一项标准判断模块560包括每一项标准对应的预设范围获取模块561、每一项标准对应的第三数据判断模块562、每一项标准对应的变化提醒模块563;总体标准判断模块580包括总体标准对应的第三数据生成模块581、总体标准对应的预设范围获取模块582、总体标准对应的第三数据判断模块583。
实施例13提供一种机器人系统,所述机器人中分别配置有如实施例7至实施例12所述的认定系统。
上述各实施例中的方法和系统可以在计算机、服务器、云服务器、超级计算机、机器人、嵌入式设备、电子设备等上执行和部署。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!