基于用户行为分析的大规模场景实时渲染方法与流程
本发明涉及机器学习技术领域,特别是指一种基于用户行为分析的大规模场景实时渲染方法。
背景技术:
虚拟现实技术(virtualreality,简称vr技术)具有沉浸感、交互性和创意性的特点[1],融合了计算机图形学、数字图像处理、多媒体、传感器、网络等多学科的最新发展成果,被广泛应用在教育、医疗、设计、艺术、规划等众多领域[2-3]。为了营造真实的沉浸感体验,虚拟现实技术对场景的实时渲染要求很高。当场景的模型量较大、模型质量较高时,实时高质量渲染场景中的所有模型是十分耗费资源的,有时甚至是不能实现的。因此需要模型智能动态预加载和撤销,即只加载用户视力所及的模型,并且在这些模型中对于较远处的模型,加载其粗糙版本,同时将很久未被关注的模型从内存中撤销。虚拟现实中丁点的延迟都会给用户带来不真实的体验,因此预测用户下一时刻可能的位置及视力范围尤为重要,实现大规模场景的提前渲染。
本发明基于用户行为分析预测用户下一时刻可能的位置及视力范围。狭义的用户行为分析是指网络上的用户行为,是指在获得网站访问量基本数据的情况下,对有关数据进行统计、分析,从中发现用户访问网站的规律,已经被广泛应用于信息检索[4]、垃圾邮件识别[5]、网页排序[6]等。本发明中的用户行为分析指的是在虚拟现实场景中,根据用户的运动行为预测下一时刻用户的运动,其中用户行为包括用户在场景中的位置、用户位移方向、位移速度、头部上下转动的方向和速度、头部左右转动的方向和速度。
参考文献:
[1]howardrheingold.virtualreality:exploringthebravenewtechnologies[m].simon&schusteradultpublishinggroup,1991.
[2]郑彦平,贺钧.虚拟现实技术的应用现状及发展.信息技术,2005,(12):94-95.
[3]夏平均,姚英学等.基于虚拟现实和仿生算法的装配序列优化.机械工程学报,2007,43(4):44-52.
[4]masahiromorita,yoichishinoda.informationfilteringbasedonuserbehavioranalysisandbestmatchtextretrieval.sigir,pp272-281,1994.
[5]yiqunliu,rongweicen,minzhang,shaopingma,liyunru.identifyingwebspamwithuserbehavioranalysis.proceedingsofthe4thinternationalworkshoponadversarialinformationretrievalontheweb,pp.9-16,2008.
[6]eugeneagichtein,ericbrill,susandumais.improvingwebsearchrankingbyincorporatinguserbehaviorinformation.sigir,pp.19-26,2006.
技术实现要素:
本发明要解决的技术问题是提供一种基于用户行为分析的大规模场景实时渲染方法,根据用户运动行为和场景信息,预测下一时刻用户可能的位置及视力范围,实现大规模场景的智能动态预加载和撤销。首先,收集虚拟现实场景中的用户运动行为数据,构建用户行为数据库;使用该数据库训练得到基于神经网络的用户行为分析基础模型;为了适应个性化的用户行为,在实际应用中根据用户在场景中的行为序列不断更新基础模型,得到个性化的用户行为模型用于预测下一时刻用户位置和视力范围;最后,根据当前的虚拟现实场景数据和预测的用户行为,输出需要渲染的场景,提前加载相应的模型,并且在这些模型中对于较远处的模型,加载其粗糙版本,同时将很久未被关注的模型从内存中撤销。
该方法包括步骤如下:
(1)收集虚拟现实场景中的用户运动行为数据,构建虚拟场景中用户行为数据库;
(2)基于神经网络构建用户行为分析基础模型,使用步骤(1)中获得的用户行为数据库训练模型,得到个性化模型;
(3)根据步骤(2)中训练好的个性化模型计算下一时刻用户位置和视力范围,根据当前的虚拟现实场景数据,输出需要渲染的场景。
其中,步骤(1)中用户行为数据库包括特定场景下用户行为数据库和通用型数据库。特定场景下用户行为数据库,如射击类游戏场景中的用户行为数据库、数字工厂中的用户行为数据库等;通用型数据库,即不区分虚拟现实的场景类型。
步骤(1)中用户运动行为数据包括用户在场景中的位置、用户位移方向和速度、头部转动的方向和速度。
步骤(2)中用户行为分析基础模型为基于lstm的用户行为分析基础模型。
步骤(3)具体为:得到下一时刻用户位置及视力范围后,加载用户视力所及的模型,并在这些模型中对于远处的模型,加载其粗糙版本,同时将很久未被关注的模型从内存中撤销。
步骤(5)中从内存中撤销的模型为用户3-5min未关注的模型。
本发明的上述技术方案的有益效果如下:
上述方案中,当场景的模型量较大、模型质量较高时,通过场景的智能动态预加载和撤销,提前加载用户下一时刻可能的视力范围所及的模型,并且加载远处模型的粗糙版本,撤销内存中很久未被关注的模型,实现大规模场景的实时渲染,节省渲染资源,避免渲染延迟,进而营造出真实的沉浸感体验。
附图说明
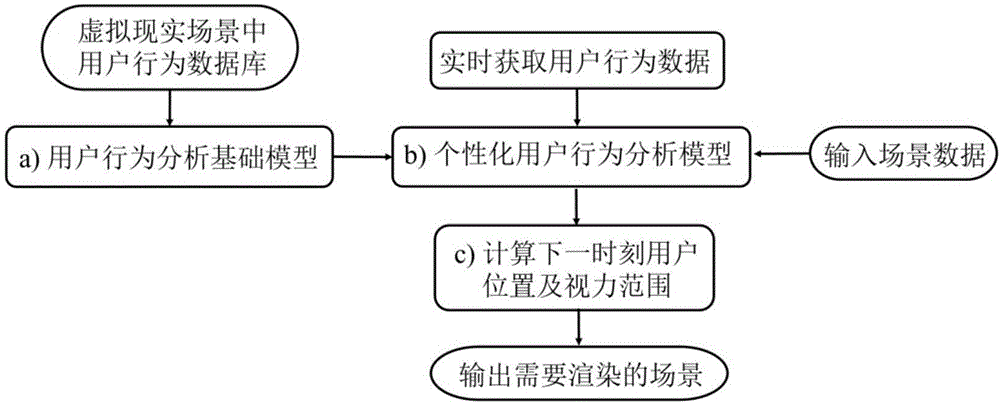
图1为本发明的基于用户行为分析的大规模场景实时渲染方法流程图;
图2为本发明的用户行为分析模型。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明提供一种基于用户行为分析的大规模场景实时渲染方法。
如图1所示,该方法首先收集虚拟现实场景中的用户运动行为数据,构建虚拟场景中用户行为数据库;然后,基于神经网络构建用户行为分析基础模型,使用上述获得的用户行为数据库训练模型,得到个性化模型;最后根据训练好的个性化模型计算下一时刻用户位置和视力范围,根据当前的虚拟现实场景数据,输出需要渲染的场景。
下面结合具体实施例予以说明。
在实际应用时,输入数据为场景信息和用户行为信息,其中用户行为信息包括用户在场景中的位置(x,y,z)、用户位移方向(dx,dy,dz)、位移速度v、头部方向(pitch,yaw,roll)和转动速度v’,场景信息指场景的语义信息,如场景中对象的名称、大小、重要性、交互复杂度等,输出为下一个时刻需要渲染的场景。具体步骤为:
a.用户行为分析基础模型。首先收集虚拟现实场景中的用户运动行为数据,构建虚拟场景中用户行为数据库,包括特定场景下用户行为数据库和通用型数据库。使用上述虚拟场景用户行为数据库训练基于lstm(longshorttermmemory)的用户行为分析基础模型,示意图如图2所示。其中,xi为第i时刻的输入数据,即用户行为属性,包括用户在场景中的位置(xi,yi,zi)、用户位移方向(dxi,dyi,dzi)、位移速度vi、头部方向(pitchi,yawi,rolli)和转动速度v’i;yi为所预测的第i+1时刻的用户行为属性,即下一时刻用户在场景中的位置(xi+1,yi+1,zi+1)、位移方向(dxi+1,dyi+1,dzi+1)和速度vi+1、头部方向(pitchi+1,yawi+1,rolli+1)和转动速度v’i+1;si为第i时刻的模型状态。采用标准的lstm模型,梯度下降方法进行训练。训练得到的用户行为分析基础模型的参数用于个性化用户行为分析模型参数的初始化。
b.个性化用户行为分析模型。该模型的框架、参数设置和训练方法与用户行为分析基础模型一致,如图2所示。使用用户行为分析基础模型的参数作为个性化模型参数的初始值,实时获取的用户行为数据和场景数据训练更新个性化模型,模型输出的用户行为属性用于步骤(c)的下一时刻用户位置及视力范围的计算。其中,场景的语义信息直接影响用户行为,如数字工厂中的重要设备,如果交互复杂,则用户的停留时间越长、操作精度要求越高,那么用户位移的速度较慢,头部转动的速度也相比漫游时缓慢。用户在虚拟现实场景中体验的时间越长,用户的个人数据越多,模型优化越深入,用户体验越好。
c.计算下一时刻用户位置及视力范围。输入场景属性和个性化用户行为分析模型得到的下一时刻的用户行为属性,计算下一时刻用户位置及视力范围,用户位置和头部状态决定了用户视力范围,我们默认用户眼睛是直视状态。完成以下三个操作:(1)加载用户视力所及的模型;(2)在这些模型中对于较远处的模型,加载其粗糙版本;(3)将很久未被关注的模型从内存中撤销。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!