一种基于加权近邻决策的故障分类诊断方法与流程
本发明涉及一种数据驱动的故障诊断方法,尤其涉及一种基于加权近邻决策的故障分类诊断方法。
背景技术:
为了保证安全生产与维持产品质量稳定,需准确地诊断出生产对象运行中出现的故障。可以说,只要有生产,过程监测就会一直是工业界与学术界广泛关注的研究课题。在现有科研文献与专利资料中,针对故障检测的研究层出不穷。相比之下,针对故障诊断的研究成果却屈指可数。从过程监测任务的要求来看,故障检测与故障诊断二者缺一不可。通常来讲,故障检测的任务在于告诉我们生产过程对象出现异常工况,而故障诊断在于找出问题所在。故障诊断发展至今大体有两种思路:其一是正确地定位异常变化的测量变量;其二是通过匹配历史数据库中的已知故障类型,以识别出当前被检测出故障的类型。前者依赖于测量变量的贡献度,而后者则将故障诊断当成模式分类问题来处理。
然而,与传统模式分类问题不同的是,故障分类所能使用的数据皆采集自工况切换的过渡过程阶段,各故障类型的训练数据变化情况非常复杂。此外,在故障发生后,现场操作人员会在第一时间内将过程修复至正常运行状态,各种故障工况下采集到的数据量通常也是有限的。从这点上讲,故障分类诊断若是直接采用模式分类领域常用的分类算法如:支持向量机、神经网络等建立多分类模型通常得不到满意的效果。这主要是因为这些算法在建立分类模型时需要足够充足的训练数据才能保证模型精度,它们通常不适合用作故障分类诊断。
考虑到故障分类诊断问题的特殊性,故障发生后并非是所有的测量变量都会出现异常波动,而且各个故障类型会引起不同测量变量出现不同程度的异常变化。因此,如何区分出各个参考故障的特征变量及其相应的异常变化程度,是提升故障分类正确度的必要途径。另外,由于各故障类型训练数据的有限性问题,不宜使用判别分析与神经网络等传统分类算法,可采取的分类思路应该立足于单个样本。作为最经典的分类方法,k阶近邻成分分析是通过两两样本数据之间的空间距离实现分类目的的,算法简单明了。此外,近邻成分分析(neighborhoodcomponentanalysis,nca)算法能从近邻分类最优的角度找到各测量变量的重要性程度,不要求充足的训练数据。
技术实现要素:
本发明所要解决的主要技术问题是:如何对各类故障实施变量加权,并在此基础上通过加权近邻距离诊断故障类型。为此,本发明方法首先利用近邻成分分析算法逐个为各参考故障类型优化出相应的加权向量。然后,计算加权后的样本之间的加权近邻距离,从而识别诊断出故障类型。
本发明解决上述技术问题所采用的技术方案为:一种基于加权近邻决策的故障分类诊断方法,包括以下步骤:
(1):采集生产过程处于正常运行工况下的n0个样本数据,组成正常工况训练数据矩阵
(2):从生产过程历史数据库中找到不同故障工况条件下的采样数据,组成各个参考故障的训练数据矩阵x1,x2,…,xc,其中
(3):根据如下所示公式,利用均值向量μ=[μ1,μ2,…,μm]与标准差对角矩阵
其中,diag{δ1,δ2,…,δm}表示将δ1,δ2,…,δm构造成一个对角矩阵,x表示矩阵x0,x1,x2…,xc中的各个行向量,
(4):将矩阵
(5):记矩阵yc中各行向量为x1,x2,…,xn,其中n=n0+nc,再利用近邻成分分析(nca)算法优化求解出权重向量wc,具体的实施过程如下所示。
①初始化梯度步长α=1、初始化目标函数值f0(wc)=-106、以及初始化权重系数向量wc=[1,1,…,1],即各变量的权重系数初始值统一设置为1。
②根据如下所示公式计算在当前权重系数向量wc条件下的目标函数值f(wc):
上式中,当且仅当xi与xj对应的类标号相同时,yij=1,其他情况yij=0。概率pij的计算方式如下所示:
上式(3)中,j=1,2,…,n,dw(xi,xj)=||(xi-xj)diag(wc)||,diag(wc)表示将wc中的元素转变成对角矩阵,符号||||表示计算向量的长度。
③判断是否满足收敛条件|f(wc)-f0(wc)|<10-6?若是,则结束迭代循环过程并输出权重系数向量wc;若否,则继续实施步骤④。
④设置f0(wc)=f(wc)后根据如下所示公式计算梯度值δf,并根据公式wc=wc+αδf更新权重系数向量:
⑤根据更新后的wc计算目标函数值f(wc),并判断是否满足条件f(wc)>f0(wc)?若是,则根据公式α=1.01α更新梯度步长α;若否,则根据公式α=0.4α更新梯度步长α。
⑥返回步骤③继续下一次迭代优化,直至满足步骤③中的收敛条件。
(6):根据公式
(7):判断是否满足条件c<c?若是,则置c=c+1后返回步骤(4);若否,则得到所有c类参考故障的加权向量w1,w2,…,wc,以及加权矩阵f1,f2,…,fc。
上述步骤(1)至步骤(7)完成了对各个类型故障可用训练数据的加权处理,以下所示步骤(8)至步骤(13)为在线故障数据所属故障类型的诊断过程。
(8):当在线被监测数据z∈r1×m被识别为故障样本数据后,根据公式
(9):调用第c类故障的加权向量wc,根据公式
(10):根据如下所示公式计算加权矩阵fc中各行向量
上式中,k=1,2,…,nc,符号||||表示计算向量的长度。
(11):从加权平均距离
(12):判断是否满足条件:c<c?若是,则置c=c+1后返回步骤(9);若否,则得到当前故障样本数据与所有c类参考故障之间的差距d1,d2,…,dc后执行步骤(13)。
(13):根据d1,d2,…,dc中的最小值确定在线故障数据z∈r1×m所归属的故障类型,并返回步骤(8)继续实施下一个故障样本的故障分类诊断。
与传统方法相比,本发明方法的优势在于:
首先,本发明方法无论是寻找各故障的加权向量还是在线诊断故障类型,都是基于近邻关系的,不需要较为充足的可用训练样本数。其次,本发明方法的主体思路是为各个故障类型优选出其对应的各变量的加权系数,从而突显出各故障的特征变量的变化特征。最后,本发明方法利用最小加权近邻均值计算在线故障数据与各故障的差距,不依赖于分类模型,只依靠加权向量与加权近邻距离。可以说,本发明方法是一种行之有效的数据驱动的故障分类诊断方法。
附图说明
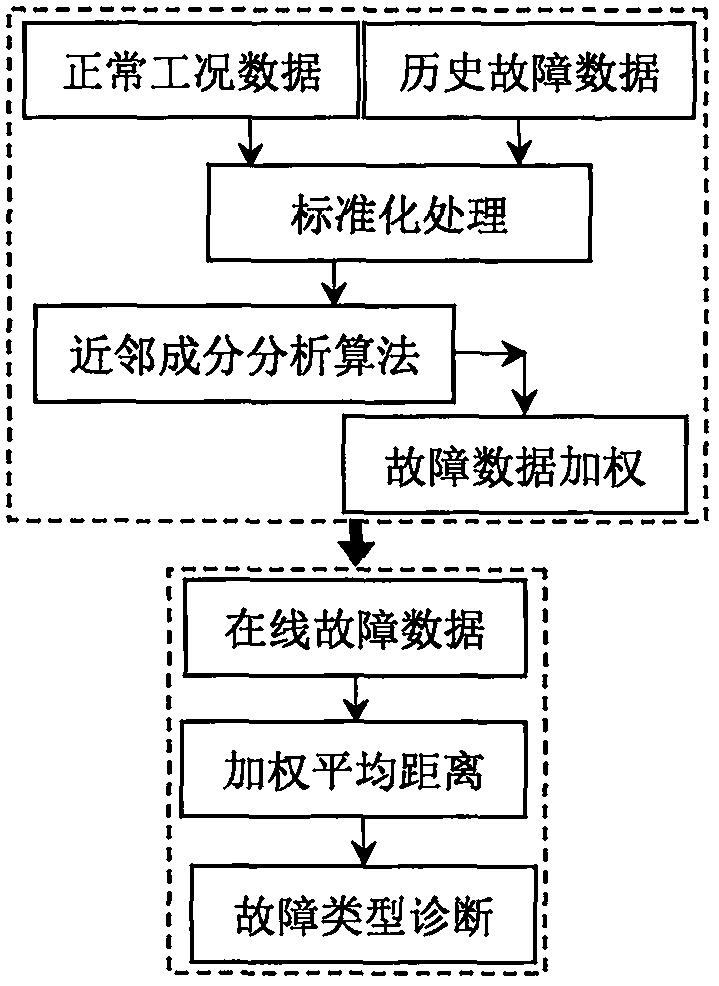
图1为本发明方法的实施流程图。
具体实施方式
下面结合附图对本发明方法的具体实施方式进行详细的说明。
如图1所示,本发明公开一种基于加权近邻决策的故障分类诊断方法,具体的实施方式包括如下所示步骤。
步骤(1):采集生产过程处于正常运行工况下的n0个样本数据,组成正常工况训练数据集
步骤(2):从生产过程历史数据库中找到不同故障工况条件下的采样数据,组成各个参考故障的训练数据集x1,x2,…,xc。
步骤(3):利用均值向量μ=[μ1,μ2,…,μm]与标准差对角矩阵
步骤(4):将矩阵
步骤(5):记矩阵yc中各行向量为x1,x2,…,xn,其中n=n0+nc,再利用近邻成分分析算法优化求解出权重向量wc。
步骤(6):根据公式
步骤(7):判断是否满足条件c<c?若是,则置c=c+1后返回步骤(4);若否,则得到所有c类故障的加权向量w1,w2,…,wc,以及加权矩阵f1,f2,…,fc。
步骤(8):当在线被监测数据z∈r1×m被识别为故障样本数据后,根据公式
步骤(9):调用第c类故障的加权向量wc,根据公式
步骤(10):根据如下所示公式计算加权矩阵fc中各行向量
上式中,k=1,2,…,nc,符号||||表示计算向量的长度。
步骤(11):从加权平均距离
步骤(12):判断是否满足条件:c<c?若是,则置c=c+1后返回步骤(9);若否,则得到当前故障样本数据与所有c类参考故障之间的差距d1,d2,…,dc后执行步骤(13)。
步骤(13):根据d1,d2,…,dc中的最小值确定在线故障数据z∈r1×m所归属的故障类型,并返回步骤(8)继续实施下一个故障样本的故障分类诊断。
- 还没有人留言评论。精彩留言会获得点赞!