一种表征科研论文研究内容的科技词条抽取方法与流程
本发明涉及信息技术领域,具体涉及一种表征科研论文研究内容的科技词条抽取方法。
背景技术:
科研论文主要功能是记录、总结科研成果,是科技人员交流学术思想和科研成果的工具。目前很多科研论文论文库均提供基于元数据的检索及全文关键词检索,基于内容分析结果的检索尚未见成熟技术和产品。虽然关键词/主题词/受控词一定程度上可以体现研究内容,但没有进一步展示与论文研究主要内容和结论等的相关度;同时,一篇论文的关键词有很多个,造成使用关键词搜索往往可以得到很多搜索结果,但大部分脱离检索预期的结果。检索人员只能在关键词搜索结果中通过阅读文献后做进一步筛选,使科技人员在科研论文检索过程中费时费力,很难检索到自己想要的科研论文。
此外,目前科研论文评价时采用学科或技术作为成果统计边界,无法在具体领域、行业水平层次对科研论文进行科学的评价,不利于更小粒度的研究主题上对研究成果进行纵向比较,也不利于不同研究主题上研究人员的横向比较。
技术实现要素:
本发明的目的是针对现有技术的不足,提供了一种表征科研论文研究内容的科技词条抽取方法,所述方法提出了科技词条这个规范化词语对科技活动的研究范畴进行分类和管理,提供了一种比学科、技术领域等分类更为精确,更能真实反映科技工作中理论和技术研究范畴的分类方法和管理模式,由科技人员主导完成词条的管理;在范畴划分中,若科技词条te1研究范畴是由科技词条te2的研究范畴细化而来,称te2强包含te1,记为te2→te1;若科技词条te1的研究范畴与科技词条te2的研究范畴存在交集,或te1的研究范畴在某种程度上也属于te2的研究范畴,称te2弱包含te1,记为
本发明的目的可以通过如下技术方案实现:
一种表征科研论文研究内容的科技词条抽取方法,所述方法包括以下步骤:
步骤s1、针对科研论文关键词所在领域构建科研论文关联词库,按照科技词条间的关联关系,计算与科研论文存在关联关系的词条集合,作为科研论文关联词库;
步骤s2、根据构建的科研论文关联词库构建科研论文语料库;
步骤s3、对科研论文中的关联科技词条进行评分计算;
步骤s4、根据计算的科技词条的评分,计算科技词条在科研论文中的贡献度;
步骤s5、对科研论文中的科技词条列表进行规约,减少从科研论文中抽取出的科研论文关联词库中的科技词条数,提取出能够表达该篇科研论文研究内容的主要科技词条并计算其贡献系数,生成以该贡献系数为顶点权值的科研论文研究内容科技词条树图。
进一步地,所述步骤s1的具体过程如下:
由于科研论文的关键词一般不是规范的科技词条,需要将关键词替换为规范的科技词条,设替换后的科技词条集合为t;
正向遍历科技词条集合t:t'=t,
反向遍历科技词条集合t:t”=t,
令tlink=t'∪t”,将tlink作为科研论文关联词库。
进一步地,所述步骤s2的具体过程如下:
将科研论文的论文文档文本化:运用文档转换工具将论文转换为后续步骤可处理的txt文本;
对论文结构进行解析,提取出论文的元数据:题目、作者、摘要、关键词、正文、参考文献,并保存到数据库中;
进一步地,所述步骤s3中首先根据科技词条的加权tf-idf值计算出科技词条的自有评分,并经过科技词条评分拓展,计算出科技词条在科研论文中的评分,评分结果为数值,对任意科技词条te,其评分包括自有评分、强包含顶点的评分和弱包含顶点的评分,科技词条te的评分ste计算公式如下:
其中,te表示科技词条库中的科技词条集,tf表示科技词条的词频指数,idf表示科技词条的逆文本频率指数,tf-idfte表示科技词条te的加权tf-idf值,te→tej代表科技词条te强包含科技词条tej,
进一步地,所述步骤s3的具体过程为:
s3.1、对科研论文进行科技词条抽取及词频统计,利用分词工具提取出科研论文中题目、摘要、关键词、正文这四部分出现的科技词条,并统计科技词条在这四部分中出现的次数,具体步骤为:将科研论文关联词库tlink作为分词工具分词时依据的用户自定义词库,并注明词性“technologyentry”;将全文中出现的关键词统一替换为科技词条;利用分词工具对科研论文的各个部分进行分词、去停用词;挑选出分词后词性为“technologyentry”的词即为科研论文中抽取出的科技词条,运用同义词库将同义不同形的科技词条归纳为同一种形式;统计出同义词检测后的科技词条在科研论文中各部分出现的次数,完成词频统计;
s3.2、计算科技词条的加权tf-idf值,具体步骤为:假设在科研论文题目、摘要、关键词、正文部分抽取出的科技词条所占的权重分别为ktitle,kabstract,kkeywords,ktext,并且满足ktitle+kabstract+kkeywords+ktext=1,计算科技词条te的
其中,
计算科技词条te的
其中,
计算科技词条te的
同理得到科技词条te在该篇论文中的
计算科技词条te的加权tf-idf值,计算公式为:
对科技词条进行评分拓展,计算出科技词条te的自有评分为:
ste=tf-idfte
对任意科技词条te,其评分包括自有评分、强包含顶点的评分和弱包含顶点的评分,科技词条te的评分ste计算公式如下:
出度为零的顶点,评分只包含自有评分。
进一步地,所述步骤s4的具体过程为:
首先计算科技词条树图中每条有向边的组合系数:对每一个科技词条te,设a是其后继顶点,te→a或
αte-a=sa/ste
其中,sa表示科技词条a的评分,ste表示科技词条te的评分;
然后计算科技词条的前驱节点置信度:对每一个科技词条te,设b是其前驱节点,b→te或
其中,te表示科技词条库中的科技词条集,sb表示科技词条b的评分,
最后计算科技词条te的贡献系数χte,公式为:
其中,te表示科技词条库中的科技词条集,αa-te表示科技词条te和科技词条a之间的组合系数,βte-a表示科技词条te的前驱节点是科技词条a的置信度。
进一步地,所述步骤s5的具体过程为:
按贡献系数χte对科技词条降序排序,χ1≥χ2≥…≥χn,指定主成分比重阈值th,当满足
对贡献系数进行调整,令χ'i=χi,i=1,2,…,k,调整公式为:
最后生成以调整后的贡献系数为顶点权值的科研论文研究内容科技词条树图。
本发明与现有技术相比,具有如下优点和有益效果:
本发明提供的一种表征科研论文研究内容的科技词条抽取方法,以科技词条树图反映了科技词条在论文中的贡献度,其计算过程考虑了词条间的上下级关系、同义关系,将论文研究内容数值化,从而客观地反映了论文的主要研究范畴,解决了科研论文检索和评价过程中统计边界过于粗糙的缺点,这将有效推动科研论文检索、科研论文评价、科研论文大数据分析等活动的开展。
附图说明
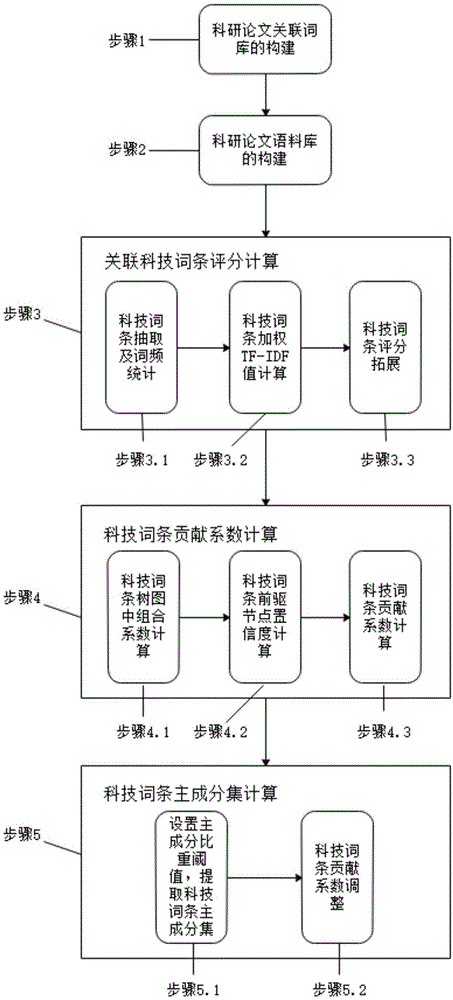
图1为本发明实施例表征科研论文研究内容的科技词条抽取方法流程图。
图2为本发明实施例中某科研论文关联词库的构建示意图。
图3为本发明实施例中某科研论文的科技词条树图。
图4为本发明实施例中某科研论文的带贡献系数标注的科技词条树图。
图5为本发明实施例中某科研论文的经科技词条主成分集计算后的科技词条树图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例:
本实施例提供了一种表征科研论文研究内容的科技词条抽取方法,首先构建科研论文关联词库和科研论文语料库,然后进行科技词条抽取、词频统计、加权tf-idf值计算、科技词条评分拓展,得到每个科技词条的评分,再计算科技词条树图中词条之间的组合系数(后继节点评分占前驱节点评分的比值)、前驱节点置信度(后继节点是由某一前驱节点延伸下来的可能性)、贡献系数(科技词条对论文研究内容的反映程度),最后对贡献系数降序排序,设置主成分比值阈值,提取科技词条主成分集,进而进行贡献系数调整,得到最能反映科研论文研究内容的科技词条及其贡献系数。
所述方法的流程图如图1所示,包括以下步骤:
步骤1:科研论文关联词库的构建;
针对科研论文关键词所在领域构建科研论文关联词库,按照科技词条间的关联关系,计算与科研论文存在关联关系的词条集合,作为科研论文关联词库;具体过程如下:
由于科研论文的关键词一般不是规范的科技词条,需要将关键词替换为规范的科技词条,设替换后的科技词条集合为t;
正向遍历科技词条集合t:t'=t,
反向遍历科技词条集合t:t”=t,
令tlink=t'∪t”,将tlink作为科研论文关联词库。
具体以某一篇科研论文为例,为便于标识,每项科技词条均设置一个可唯一标识的编码id,图2、3、4、5中每个顶点表示一条科技词条及其同义词,对每个词条仅列出其词条编码,词条间的强包含关系用i型有向边表示,弱包含关系用ii型有向边表示;图2展示了的某科研论文关联词库的构建,该篇论文只有一个关键词“机器学习”,“机器学习”在科技词条库中,id4代表了“机器学习”这个科技词条,经过正向遍历和逆向遍历,可遍历到的科技词条有id1、id2、id5、id6、id7,图中用斜线填充的科技词条代表id4可遍历到的,那么该篇论文的科研论文关联词库为{id1,id2,id4,id5,id6,id7};
步骤2:科研论文语料库的构建;具体过程如下:
将科研论文的论文文档文本化:运用文档转换工具将论文转换为后续步骤可处理的txt文本;
对论文结构进行解析,提取出论文的元数据:题目、作者、摘要、关键词、正文、参考文献,并保存到数据库中;
步骤3:关联科技词条评分计算;具体过程为:
步骤3.1、对科研论文进行科技词条抽取及词频统计,利用分词工具提取出科研论文中题目、摘要、关键词、正文这四部分出现的科技词条,并统计科技词条在这四部分中出现的次数,具体步骤为:将科研论文关联词库tlink作为分词工具分词时依据的用户自定义词库,并注明词性“technologyentry”;将全文中出现的关键词统一替换为科技词条;利用分词工具对科研论文的各个部分进行分词、去停用词;挑选出分词后词性为“technologyentry”的词即为科研论文中抽取出的科技词条,运用同义词库将同义不同形的科技词条归纳为同一种形式;统计出同义词检测后的科技词条在科研论文中各部分出现的次数,完成词频统计;
步骤3.2、计算科技词条的加权tf-idf值,具体步骤为:假设在科研论文题目、摘要、关键词、正文部分抽取出的科技词条所占的权重分别为ktitle,kabstract,kkeywords,ktext,并且满足ktitle+kabstract+kkeywords+ktext=1,计算科技词条te的
其中,
计算科技词条te的
其中,
计算科技词条te的
同理得到科技词条te在该篇论文中的
计算科技词条te的加权tf-idf值,计算公式为:
步骤3.3、对科技词条进行评分拓展,计算出科技词条te的自有评分为:
ste=tf-idfte
对任意科技词条te,其评分包括自有评分、强包含顶点的评分和弱包含顶点的评分,科技词条te的评分ste计算公式如下:
出度为零的顶点,评分只包含自有评分。
图3展示了某科研论文的科技词条树图,图中节点“id/score/ownscore”,其中id代表科技词条的可唯一标识的编码,score代表科技词条的评分,ownscore代表科技词条的自有评分。图中id4的评分计算公式为:
sid4=tf-idfid4+sid6+sid7=0.3+0.5+0.4=1.2
步骤4:科技词条贡献系数计算;具体过程为:
步骤4.1、计算科技词条树图中每条有向边的组合系数:对每一个科技词条te,设a是其后继顶点,te→a或
αte-a=sa/ste
其中,sa表示科技词条a的评分,ste表示科技词条te的评分;
步骤4.2、计算科技词条的前驱节点置信度:对每一个科技词条te,设b是其前驱节点,b→te或
其中,te表示科技词条库中的科技词条集,sb表示科技词条b的评分,
步骤4.3、计算科技词条te的贡献系数χte,公式为:
其中,te表示科技词条库中的科技词条集,αa-te表示科技词条te和科技词条a之间的组合系数,βte-a表示科技词条te的前驱节点是科技词条a的置信度。
步骤5:科技词条主成分集计算;
对科研论文中的科技词条列表进行规约,减少从科研论文中抽取出的科研论文关联词库中的科技词条数,提取出能够表达该篇科研论文研究内容的主要科技词条并计算其贡献系数,生成以该贡献系数为顶点权值的科研论文研究内容科技词条树图。具体过程为:
步骤5.1、按贡献系数χte对科技词条降序排序,χ1≥χ2≥…≥χn,指定主成分比重阈值th,当满足
步骤5.2、对贡献系数进行调整,令χ'i=χi,i=1,2,…,k,调整公式为:
最后生成以调整后的贡献系数为顶点权值的科研论文研究内容科技词条树图。
在图3中,id2和id4之间的组合系数为αid2-id4=sid4/sid2=1.2/1.9=0.632,id4的前驱节点是id1的置信度βid4-id1=sid1/(sid1+sid2)=1.4/(1.9+1.4)=0.424,id4的前驱节点是id2的置信度βid4-id2=sid2/(sid1+sid2)=1.9/(1.9+1.4)=0.576。图4中,词条id4贡献系数χid4计算公式为:
对图4中科技词条的贡献系数降序排序,所得结果为id6/0.209,id7/0.133,id3/0.129,id8/0.100,id4/0.055,id2/0.047,id5/0.031,id1/0.029,取th=0.8,
词条id6、id7、id3、id8、id4是该篇论文的代表性科技词条,贡献系数分别为33.4%、21.2%、20.6%、16.0%、8.9%,最后得到经科技词条主成分集计算后的以调整后的贡献系数为顶点权值的科技词条树图如图5所示。
由上述可见,本发明的一种表征科研论文研究内容的科技词条抽取方法,考虑了科技词条间的上下级关系、同义关系,将论文研究内容数值化,给出了最能代表论文研究内容的科技词条及其贡献系数,从而客观地反映了论文的主要研究范畴,解决了科研论文检索和评价过程中统计边界过于粗糙的缺点,这将有效推动科研论文检索、科研论文评价、科研论文大数据分析等活动的开展。
以上所述,仅为本发明专利较佳的实施例,但本发明专利的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明专利所公开的范围内,根据本发明专利的技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!