一种基于深度神经网络的人体姿态识别方法与流程
本发明涉及人体姿态识别,具体涉及一种基于深度神经网络的人体姿态识别方法,属于智能视频监控和计算机视觉领域。
背景技术:
人体姿态识别是指对图像中的人体进行自动分析处理,对人体姿势信息按照预先设计的分类标注。姿态识别是行为识别中的一个基本问题,可靠而准确地识别人体姿态可以用于人体行为分析、人员工作状态或学习状态的判别,从而为各行各业的智能化管理自动提供信息。由于图像中人的衣着,姿态,背景等的多样性以及存在一些自我遮挡和其他人或物体遮挡的情况,准确地预测出图像中的人体姿态非常具有挑战性。目前基于普通光学图像的人体姿态识别算法主要利用人体的表观特征,如人体轮廓特征或图像中人体与其他物体之间的上下文关系,这些特征都与颜色有关,易受到光照等外界条件的影响,当不能够提取到很好的特征,易出现识别准确率低下等问题。
山东大学提出一种基于关节点信息的人体行为识别新方法(机器人,2014.3),使用kinect采集的关节点数据构造人体结构向量,用人体结构向量间的向量角和向量模比值提取行为来表示特征量,最后使用动态时间规整(dtw)算法计算测试行为模板与参考行为模板之间的相似度。该方法主要目的是识别动态行为,虽然也利用了关节点信息构造人体结构特征,但是利用kinect专用设备获取人体关节点信息,并且构造出的人体结构特征信息处理方法也跟本专利不同。电子科技大学提出一种基于深度卷积神经网络的人体姿势识别方法(cn105069413a),将姿势估计阐述为分类问题,设计了针对姿势估计的神经网络ilpn来进行关节定位,通过查找坐标映射表,将统一尺度下的人体姿势映射回原图像尺度下从而估计出rgb图像中人体姿势。广东省智能制造研究所提出基于卷积神经网络与支持向量机的人体行为识别方法(cn108052896a),将rgb图像输入至vgg神经网络模型进行特征提取,形成一组卷积特征图;将特征图作为双分支深度卷积神经网络模型的输入,获得关节点和关节关联信息,然后采用二分图匹配算法逐步进行局部寻优,最终获得最佳关节匹配;对骨骼序列数据进行归一化处理,并通过组合多个支持向量机分类器来实现多分类器的构造。以上两种方法虽然利用了深度神经网络,但网络模型提取关节点信息的过程和方法都与本专利不同;同时这些方法都没有涉及如何在网络摄像机中实时获取视频帧,并进行实时分类识别的问题。本发明利用深度卷积姿态神经网络从实时视频帧中提取人体关节点信息,实时分类识别人体姿态,还提出了从网络摄像机视频流实时在线地获取图像帧,返回识别结果用于智能视频监测系统的方法,可以应用于智能视频监控系统中,可提高系统综合性能,改善用户的实时体验,更实用、可行性更高,有广泛的应用价值和经济效益。
技术实现要素:
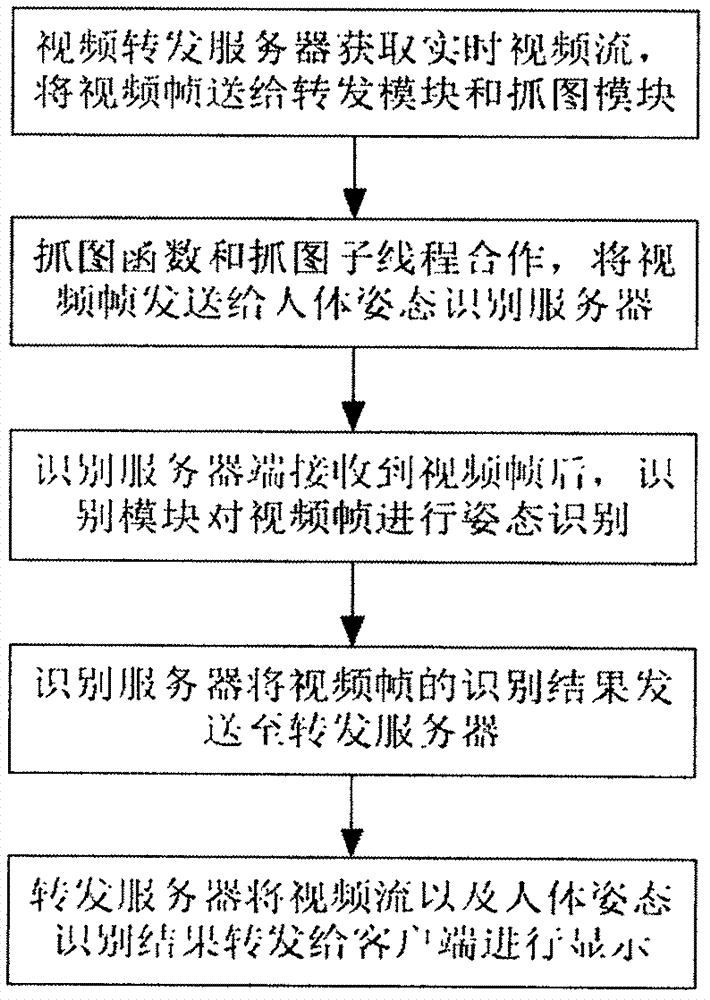
本发明公开了一种面向智能视频监控的基于深度神经网络的人体姿态识别方法,该方法包括:1)转发服务器从网络视频录像机上接收实时视频流,抓图子线程从实时视频流中抓取视频帧,发送给识别服务器;2)识别服务器使用深度卷积姿态神经网络模型提取关节点信息特征,合成人体骨架的结构信息,形成特征向量;3)通过多分类支持向量机进行分类识别,将识别结果返回转发服务器;4)转发服务器将识别结果与视频帧一并发送至客户端显示,实现实时的智能视频监控系统中的人体姿态识别。
具体来说,本发明的方法包括以下内容:
a.视频转发服务器获取实时视频流,将视频帧送给转发模块和抓图模块,具体实施步骤如下:
a1.视频转发服务器(简称转发服务器)建立面向客户端和网络视频录像机(简称nvr)的控制端口和数据端口;
所述控制端口用于控制信息通信,数据端口用于视频流和人体姿态识别信息通信;
a2.客户端通过控制端口向转发服务器发送请求某路nvr视频的请求;
a3.转发服务器主线程(简称主线程)根据客户端请求,向nvr发送请求该路视频流的请求,为该路视频流建立对应的通道;
a4.主线程为每个通道创建所需的线程和缓冲队列,具体步骤如下:
a4.1创建一个定时器,一个抓图函数,一个抓图子线程和一个抓图环形缓冲队列,用于抓图和姿态识别;
抓图环形缓冲队列包含但不限于以下成员:
-队列头指针head,指向要识别处理的视频帧的视频数据缓冲区,初值为-1;
-队列尾指针tail,指向新获取的视频帧的视频数据缓冲区,初值为-1;
-视频帧数据缓冲区指针pbuf,指向当前正在识别的视频帧,初值为-1;
-视频帧数据大小nsize,为当前正在识别的视频帧的大小,初值为-1;
-上一帧ppre,指向已经识别的视频帧数据缓冲区,初值为-1;
a4.2创建一个转发子线程和一个转发环形缓冲队列,用于转发收到的视频流给客户端;所述的转发环形缓冲队列结构类似于抓图环形缓冲队列;
a5.主线程接收从nvr发来的视频流,将视频流中的视频帧分别处理,具体步骤如下:
a5.1将视频帧直接挂接到转发环形缓冲队列;
a5.2将解码后的视频帧存入播放缓冲区;
b.抓图函数和抓图子线程合作,将视频帧发送给人体姿态识别服务器(简称识别服务器),具体步骤如下:
b1.将定时器的时间间隔设置为m秒,m包括但不限于1;定时器每隔m秒触发给定的抓图函数;
b2.抓图函数从播放缓冲区里抓取视频帧,挂载到抓图环形缓冲队列上,将队列尾指针tail指向该视频帧;
b3.抓图子线程从抓图环形缓冲队列上摘取视频帧,发送至识别服务器,具体步骤如下:
b3.1抓图子线程通过绑定相应的端口与识别服务器连接;
b3.2抓图子线程将抓图环形缓冲队列头指针head的值,赋给视频帧数据缓冲区指针pbuf,读取视频帧大小nsize;
b3.3抓图子线程将pbuf所指的视频帧发送给识别服务器端后,并将pbuf的值赋给ppre;
b3.4将head加1,指向下一个要识别的视频数据缓冲区;循环步骤b3.2与b3.3;
c.识别服务器端接收到视频帧后,识别模块对视频帧进行姿态识别,具体步骤如下:
c1.识别模块接收视频帧,选取图片左上角作为坐标原点;
c2.识别模块利用深度神经网络模型对视频帧中的人体检测并进行关节点定位,得到关节点坐标,写入坐标文本文件中,具体步骤如下:
c2.1所述的深度神经网络模型包括人体检测模型和关节点定位模型;
c2.2利用人体检测模型检测视频帧中各个人体所在位置,输出包围人体的矩形框,具体步骤如下:
c2.2.1加载训练好的模型;
c2.2.2输入待检测的视频帧,得到各个人体所在的大致区域,输出包人体矩形框的位置信息;
所述的人体矩形框位置信息包括但不限于坐标信息(x1,y1,x2,y2),其中(x1,y1)是左上角坐标,(x2,y2)是右下角坐标;
c2.3利用关节点定位模型预测人体关节点的位置,具体步骤如下:
c2.3.1加载训练好的关节点定位模型;
c2.3.2从矩形框所框选范围内,直接生成不同尺度的图像,分别送入关节点定位模型;
c2.3.3基于每个尺度,计算网络预测的各个关节点的响应图,得到不同尺度下各个关节点的响应图;
c2.3.4对于每个关节点,依次累加每个关节点对应的所有尺度的响应图,得到总响应图;
c2.3.5在每个关节点的总响应图上,找出分数最大的点,则该最大值所在位置(x,y)即为预测的关节点位置,选取图片左上角作为坐标原点;
c2.4将视频帧编号及其对应的14个关节点坐标依次写入坐标文本文件中;
所述的关节点具体顺序依次为头部,颈部,右肩,右肘,右腕,左肩,左肘,左腕,右臀,右膝,右脚踝,左臀,左膝,左脚踝;
c3.用矩阵标识关节点之间的连接关系,用人体姿态描述向量来表示四肢角度与方向信息,最终合成人体骨架结构信息,具体步骤如下:
c3.1根据c2.3生成的关节点连接信息,构造一个14*14的关节点连接关系矩阵,标识相邻关节点之间的连接关系,0值表示对应关节点没有连接,非0值表示对应关节点有连接;
c3.2根据关节点连接矩阵,为人体中的三连续关节区域构造人体姿态描述向量
c3.2.1所述的三连续关节区域包括左上肢,右上肢,左下肢,右下肢,头部-右肩,头部-左肩;其中,右上肢指右肩、右肘和右腕;右下肢指右臀,右膝,右脚踝;左上肢指左肩、左肘和左腕;左下肢指左臀,左膝,左脚踝;头部-右肩指头部,颈部和右肩;头部-左肩指头部,颈部和左肩;
c3.2.2以右上肢为例,设点a(x1,y1)、b(x2,y2)、c(x3,y3)分别表示右肩、右肘和右腕的关节点坐标,
-右上肢关节向量间的向量角p1,计算公式如下:
-右上肢关节向量间的模比值r1,计算公式如下:
c3.2.3按照c3.2.2的步骤,分别计算左上肢,左下肢,右下肢,头部-右肩,头部-左肩的向量角和模比值,依次记为p2,p3,p4,p5,p6和r2,r3,r4,r5,r6;
c3.2.4利用上述向量角和模比值构造一个12维的人体姿态描述向量
c4.利用支持向量机分类器对向量
c4.1加载已训练好的多分类支持向量机分类器模型;
c4.2用所有的子分类器进行测试并计算骨架信息预测类别及概率值;具体步骤如下:
c4.2.1根据决策函数的返回值的符号判断其属于的类别;
c4.2.2统计各类别的投票得分情况,选择得分高的类作为测试数据的类;
c4.2.3由投票情况计算属于该类别的概率值;
d.识别服务器将视频帧的识别结果发送至转发服务器;
所述的识别结果包括但不限于人体矩形框坐标、识别出的姿态类别、概率;
e.转发服务器将视频流以及人体姿态识别结果转发给客户端进行显示,具体步骤如下:
e1.转发服务器上的主线程接收识别服务器发来的识别结果信息,下一个要转发的视频帧的附加数据包中;
e2.转发子线程负责从转发环形缓冲队列摘取视频帧及其附加数据包;
e3.转发子线程将视频帧及其附加数据包一起转发给客户端;
e4.客户端实时显示视频帧以及对应的人体矩形包围框和姿态识别的概率。
本发明与现有技术相比,具有以下优点:实现了一套从网络摄像机视频流实时抓取视频帧机制,将抓取的视频帧发送至识别服务器端,利用深度卷积姿态神经网络的方法从视频帧中提取人体关节点信息,并对人体姿态进行分类识别,实现了视频监控中人体姿态的实时识别,使面向智能视频监控的人体姿态实时识别方法更实用、可行性更高,应用和推广价值更大。
附图说明
附图说明用于提供对本发明技术方案的进一步理解,并构成说明书的一部分,与本方法的实施一起用于解释本发明的技术方案,并不构成本发明技术方案的限制。
附图说明如下:
图1是本发明方法的流程图;
图2是本发明方法所识别的关节点坐标图;
具体实施方式
下面结合附图,对本发明的具体实施方式作进一步描述。
如图1所示,一种基于深度神经网络的人体姿态识别方法,包括如下步骤:
a.转发服务器获取实时视频流,将视频帧送给转发模块和抓图模块,具体实施步骤如下:
a1.转发服务器建立面向客户端和nvr的控制端口和数据端口;
a2.客户端通过控制端口向转发服务器端发送请求编号为10的nvr视频;
a3.主线程根据客户端请求,向nvr发送请求,并为该路视频建立对应的通道,通道号为10;
a4.主线程为该通道设定一个定时器,一个抓图函数,并创建一个抓图子线程t1和一个抓图环形缓冲队列,用于抓图和姿态识别;缓冲队列包含:抓图缓冲区头指针m_nhead,初值为-1;抓图缓冲区尾指针m_ntail,初值为-1;视频帧数据缓冲区指针m_npbuf,初值为-1;抓图的视频帧数据大小nsize,初值为0;连接的上一帧m_nppre,初值为-1;一个转发子线程t2和一个转发环形缓冲队列,用于转发收到的视频流给客户端,所述的转发环形缓冲队列结构类似于抓图环形缓冲队列;
a5.主线程接根据客户端的请求,接收从nvr发来的通道号为10的视频流,将视频流中的视频帧直接挂接到转发环形缓冲队列,并将解码后的视频帧存入播放缓冲区;
b.抓图函数和抓图子线程合作,将视频帧发送给识别服务器,具体实施步骤如下:
b1.将定时器的时间间隔m_ncaptime设置为1秒,定时器每隔1秒均会触发给定的抓图函数;
b2.抓图函数将从播放缓冲队列中定时抓取转化为jpg格式的视频帧,编号记为201807081136,并挂载到抓图缓冲队列上,将队列尾指针m_ntail指向该视频帧;
b3.抓图子线程从抓图环形缓冲队列上摘取视频帧,发送给识别服务器,具体步骤如下:
b3.1抓图子线程t1绑定需要监听的端口,端口号为41936,与识别服务器端进行连接;
b3.2t1将抓图缓冲队列头指针m_nhead的值赋给视频帧数据缓冲区m_npbuf,读取视频帧大小nsize;
当m_nhead=-1时,t1将m_nhead的值-1赋给pbuf,此时环形缓冲区上没有可以发送的视频数据缓冲区,则抓图子线程睡眠100秒之后,重新开始循环;
当m_nhead=20时,t1将m_nhead的值20赋给m_npbuf,此时环形缓冲区上有可以发送的视频数据缓冲区,t1将m_npbuf所指的视频数据缓冲区发送给至识别服务器端;
b3.3t1将m_npbuf所指的视频帧发送给识别服务器端后,并将m_npbuf的值20赋给m_npre;
b3.4将m_nhead的值加1变为21,指向下一个要识别的视频数据缓冲区,循环步骤b3.2与b3.3;
c.识别服务器端接收到视频帧201807081136后,识别模块对视频帧进行姿态识别,具体实施步骤如下:
c1.识别模块接收视频帧,选取图片左上角作为坐标原点;
c2.识别模块利用深度卷积神经网络模型对视频帧中的人体检测并进行关节点定位,得到关节点坐标,写入坐标文本文件中,具体实施步骤如下:
c2.1所述的深度神经网络模型包括人体检测模型和关节点定位模型;
c2.2利用人体检测模型检测视频帧中各个人体所在位置,输出若干包围人体的矩形框,具体步骤如下:
c2.2.1加载训练好的人体检测模型;
c2.2.2输入待检测的视频帧,得到一个人体所在的大致区域,输出人体矩形框的位置信息l1=(22,124,251,629);
c2.3利用关节点定位模型预测人体关节点的位置,具体步骤如下:
c2.3.1加载训练好的关节点定位模型;
c2.3.2从矩形框所框选范围内l1=(22,124,251,629),直接生成不同尺度的图像,分别送入关节点定位模型,
c2.3.3基于每个尺度,计算网络预测的各个关节点的响应图,得到不同尺度下各个关节点的响应图;
c2.3.4对于每个关节点,依次累加每个关节点对应的所有尺度的响应图,得到总响应图;
c2.3.5在每个关节点的总响应图上,找出分数最大的点,则该最大值所在位置(x,y)即为预测的关节点位置;
c2.4将视频帧编号201807081136及其对应的14个关节点坐标依次写入坐标文本文件中,(179,126):头部,(179,217):颈部,(103,249):右肩,(103,339):右肘,(105,412):右腕,(231,251):左肩,(247,347):左肘,(216,410):左腕,(176,414):右臀,(130,464):右膝,(77,610):右脚踝,(197,426):左臀,(188,426):左膝,(112,625):左脚踝;
c3.用矩阵标识相邻关节点之间的连接关系,四肢角度与方向信息由特征向量人体姿态描述向量来表示,最终合成人体骨架结构信息;具体实施步骤如下:
c3.1根据c2.3生成的关节点连接信息,初始化一个14*14,元素值均为0的矩阵,其中把之间有连线的关节点在矩阵里标识出来,是否为非零值标识关节点间是否存在联系;
c3.2根据关节点连接矩阵,为人体中的三连续关节区域构造人体姿态描述向量
c4.利用多分类支持向量机分类器进行分类识别,加载已训练好的多分类支持向量机分类器模型(多个二分类器,采用一对一的方式构造);进行预测时,用所有的子分类器进行测试,根据决策函数的返回值的符号判断其属于的类别,并统计各类别的投票得分情况,选择得分高的类作为测试数据的类,计算骨架信息预测类别及概率值,输入测试骨架信息得到预测类别为sit及概率值83.67%;
d.识别服务器端将视频帧编号信息与识别结果人体矩形框坐标、姿态所属类别sit,及其概率为83.67%发送至转发服务器;
e.转发服务器将视频流以及人体姿态识别结果转发给客户端进行显示,具体实施步骤如下:
e1.转发服务器上的主线程接收识别服务器发来的识别结果信息,写入转发环形缓冲队列中,下一个要转发的视频帧的附加数据包中;
e3.转发子线程t2负责从转发环形缓冲队列摘取视频帧及其附加数据包;
e4.转发子线程t2将视频帧及其附加数据包一起转发给客户端;
e5.客户端实时显示视频帧以及对应的人体矩形包围框和姿态识别的类别和概率。
最后需要注意的是,公布实施的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!