一种基于PCA-T2的滚珠丝杠副健康评估方法与流程
本发明涉及滚珠丝杠副健康评估技术。
背景技术:
随着phm系统在工业中的普及和应用,越来越多的设备开始利用phm系统进行健康评估。设备的有效维护能够保障其安全高效地运行,当设备健康水平发生变化时,预示着设备即将发生退化或者故障。滚珠丝杠副作为重要的传动装置,在机械制造业、自动化加工设备等行业应用广泛,因此,其安全运行对于整个工业设备来说至关重要。为了把控整个设备全生命周期的健康状态,实时显示设备所处的健康水平,及时预警设备的退化和失效,为用户提供科学报警,在设备上进行合理的健康评估至关重要。
健康评估的思想是将原始数据通过一系列的操作映射到一个新的域,而新的域被定义为设备的健康值,健康值的大小反映了设备当前状态下的健康水平,或者是与健康状态的偏差程度。在专利“一种滚珠丝杠副健康状态的评估方法”中,其结合拉普拉斯降维与马氏距离分析模型建立了传感器信号样本点在特征空间中与健康值之间的非线性的关系,从而获得滚珠丝杠副性能衰退程度的量化评估。而在其他文献中,有利用逻辑回归进行健康评估,其通过利用健康状态和失效状态的数据,结合逻辑回归拟合出一个模型,将设备的特征值通过模型映射到0-1之间的健康值上,越接近于1表明健康状态越好,越接近于0表明健康状态越差。还有基于量子遗传算法与灰色神经网络的性能评估方法,其主要思想是通过不同运行时间下的数据进行训练,得到丝杠退化的模型,进而评估丝杠的性能情况。
已有的基于拉普拉斯降维与马氏距离的健康评估方法虽然在方法上有较好的优势,操作简单、理论性强,且能构建令信号样本从特征空间到健康值的映射,从而生成反映设备偏离健康状态程度大小的健康值,但是,该方法缺乏自动预警的功能,对于部件的健康状态发生改变时,无法及时提供预警且定位故障位置。
采用基于逻辑回归的健康评估方法,在训练拟合阶段需要健康状态和失效状态的特征数据,因此,该方法过于依赖数据的完整性,且健康和失效的数据都要具备,对数据的要求更加严格。
另外,基于量子遗传算法与灰色神经网络的性能评估方法,其用于模型训练的数据为不同运行时间下的数据,仅仅将运行时间作为性能退化的量化指标,不符合实际情况。不同运行时间下的丝杠也会因为中间环境或者其他因素的影响造成性能退化或者故障,所以该方法缺乏一定的适用性。
技术实现要素:
本发明的目的是为了解决现有技术的上述问题,提供一种基于pca-t2的滚珠丝杠副健康评估方法。
本发明所述的一种基于pca-t2的滚珠丝杠副健康评估方法包括以下步骤:
步骤一:从安装在滚珠丝杠副多个部位的传感器处提取丝杠原始振动信号,并对所述原始振动信号进行预处理;
步骤二:对预处理后的原始振动信号进行特征提取,提取出的特征构成特征值矩阵;
步骤三:对提取的特征值矩阵进行特征选择,得到训练样本的特征值矩阵;
步骤四:结合主成分分析方法对步骤三得到的训练样本特征值矩阵进行降维,删去无关主成分,选取对设备退化贡献率最大的前n个主成分ptx,其中p为代数特征值对应的特征向量,x=(xi)表示第i个特征,且选取出的n个主成分累计贡献率达到x%以上;
步骤五:每加入一个新样本,便构建并计算pca-t2统计量t2=xtp·λ-1·ptx,式中λ=diag{λ1,λ2,...,λn}为代数特征值矩阵,ptx为前n个主成分;
步骤六:设定健康曲线的报警阈值线,所述健康曲线指t2随时间变化的曲线,若t2超出阈值线时,向用户发出报警并定位故障位置,否则,跳转到步骤七;
步骤七:等到新样本加入,重复步骤五和步骤六,直到设备无新样本数据加入。
进一步地,步骤一中对所述原始振动信号进行预处理包括对所述原始振动信号进行小波降噪、剔除异常值、以及缺失值填充。
进一步地,步骤二中,预处理后的原始振动信号提取的特征包括:均方根值、方差、标准差、最大值、最小值、平均幅值、峭度因子、波形系数、峰值、峰值因子、脉冲指标、方根幅值、裕度系数以及偏度。
进一步地,步骤四中,x=90。
进一步地,步骤四的具体方法为:
步骤四一、利用pca训练出主成分,并将该主成分按照所述贡献率由大到小排序;
步骤四二、按照贡献率由大到小选择主成分,并使得选取的主成分累积贡献率>x%。
进一步地,步骤六中,设定健康曲线的报警阈值线的具体方法为:构造健康曲线的置信区间,报警阈值线的纵坐标为该置信区间的下端点值,横坐标为时间。
进一步地,构造健康曲线的置信区间的具体方法为:
步骤六一、每加入一个新样本,便更新一次置信区间,对于第k个样本,所述置信区间的构造公式如下:
式中
步骤六二、判断新加入的样本是否处在置信区间内:
计算
步骤六三:当p=m时,判断n中的连续数个数是否为m,所述连续数为n的子集,连续数个数为连续数中元素的个数,若是,则阈值线为所述m对应的m个样本中第一个样本的健康值;若n中的连续数个数小于m,则更新n、p,重复步骤六一和步骤六二,由此得到的阈值线为设备退化报警阈值线;
n与p的更新方法为:当n中的连续数q的最后一个元素与n的最后一个元素相同时,令n=q;当n中的连续数q的最后一个元素与n的最后一个元素不同时,令n只保留其最后一个元素;p为n此时的元素个数;
步骤六四:扩大置信区间范围,由原来的2d扩展到8d,步骤六一中的区间更新为:
此处所构造的置信区间的实际意义在于对于只含随机误差的健康值,有接近100%的概率分布在m区间中,超出这个范围的可能性接近于0%,因此超出的部分被认为健康值完全退化,开始出现失效。
步骤六五:重复步骤四和步骤六二和步骤六三,得到第二条阈值线。
由此得到的阈值线为设备失效报警阈值线。
本发明通过特征提取以及特征选择的方法获得振动信号的特征值,通过一系列的预处理后,将特征值矩阵代入新构建的映射模型中,此新映射模型是通过构建pca-t2(霍特林统计量)实现的,它描述的是数据集中的每一个样本与数据集的中心的距离,反映的是与健康状态之间的偏差,偏差越小表明健康状态越好,偏差越大表明健康状态越差。最后根据自适应阈值算法给出滚珠丝杠副的报警阈值。采用本发明所述的基于pca-t2的健康评估方法,可以有效地实时监控滚珠丝杠副的运行状态,结合了主成分分析的相关方法,将样本数据降维,避免了维度过大造成的数据重叠和精度降低的问题;构造了霍特林统计量,将样本从特征空间映射到主成分构建的新坐标中,即健康值,有效地反映了新加入样本与基线样本(数据集的中心)之间的偏离程度,间接反映了设备的健康水平;新加入了自适应阈值的方法,为丝杠的运行提供了预警的功能,有助于用户提前发现设备的退化和故障,及时维护和更换部件,避免了不必要的损失。本发明所述的方法在部件健康状态发生改变时,能够时提供预警并且定位故障位置;在训练阶段不需要失效数据,对数据的要求相对较为宽松;用于模型训练的数据为同一运行时间下提取的数据,符合实际情况,解决了现有技术存在的问题。
附图说明
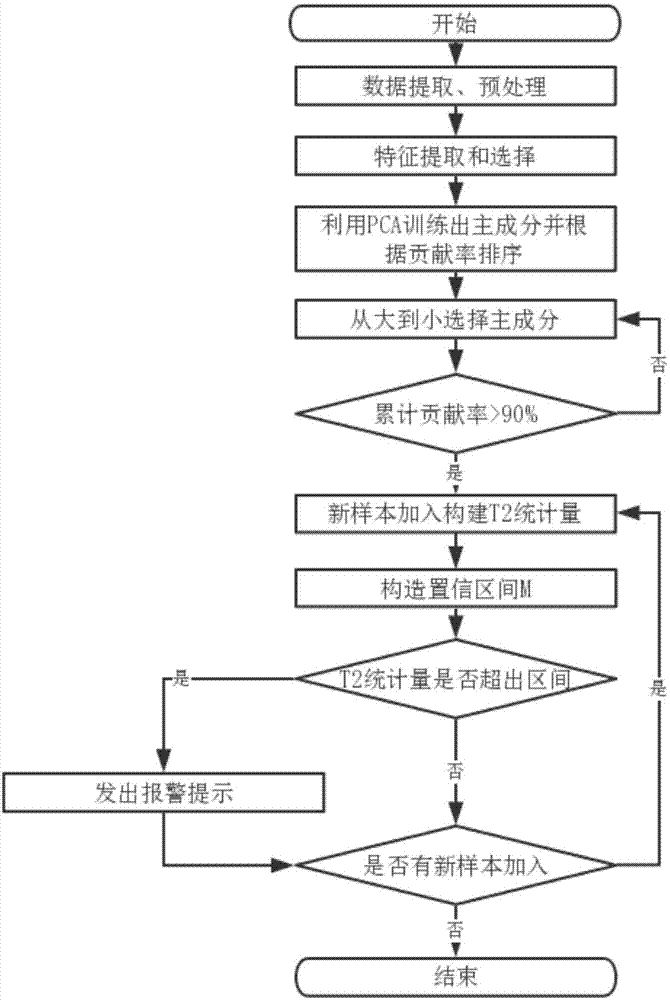
图1为本发明实施方式所述的基于pca-t2的滚珠丝杠副健康评估方法的流程图;
图2为采用本发明实施方式所述的基于pca-t2的滚珠丝杠副健康评估方法的评估效果图。
具体实施方式
具体实施方式一:如图1所示,本实施方式所述的一种基于pca-t2的滚珠丝杠副健康评估方法分为获取健康值、自适应阈值监测、定位故障分布三部分,具体如下:
步骤一:从安装在滚珠丝杠副系统多个部位的传感器处提取丝杠原始振动信号,并对所述原始振动信号进行小波降噪、剔除异常值、缺失值填充等预处理,所述传感器分布在滚珠丝杠副系统的两端轴承与中间丝母上,提取的信号来自传感器的优选通道,所述优选通道是指传感器三个通道中最能反映部件退化趋势的通道(通过前期观察三个通道输出的振动信号来确定振动信号退化趋势明显的通道信号);
步骤二:对预处理后的原始振动信号进行特征提取,提取的特征的好坏将决定健康评估的准确性;
此处提取了丝杠数据的14个特征,包括均方根值、方差、标准差、最大值、最小值、平均幅值、峭度因子、波形系数、峰值、峰值因子、脉冲指标、方根幅值、裕度系数以及偏度。
步骤三:对提取的特征值矩阵(矩阵为u*v维,其中u为全体样本数,v为步骤二中每个原始信号提取出的特征数14)进行特征选择,以选出对于设备退化贡献大的特征,得到训练样本特征值矩阵;
特征选择的意义在于原提取的特征值矩阵维度大,并且各个特征之间存在一定的耦合关系,这样会导致所观测的数据存在一定的重叠。因此要对特征值矩阵进行降维,以选出最优的(即最能反映原始变量的信息)、贡献度大(对于设备的退化趋势贡献程度大)的特征进行健康评估。
步骤四:结合主成分分析方法对步骤三得到的训练样本特征值矩阵进行降维,删去无关主成分,选取贡献率最大的前n个主成分ptx(此处选取的主成分是前面选择的特征值矩阵的线性组合),其中p为代数特征值对应的特征向量(将代数特征值从大到小排序后所对应的特征向量作为线性组合的系数,该系数具有唯一性,可通过编程求解),为线性代数的名词,应区别于上述的特征值矩阵,x=(xi)表示第i个特征,且累计贡献率达到90%以上,具体为:
利用pca训练出主成分,并将该主成分按照所述贡献率由大到小排序,然后按照贡献率由大到小选择主成分,并使得选取的主成分累积贡献率>90%。
步骤五:每加入一个新样本(此处的新样本为对一组原始信号处理后的特征值矩阵),便构建并计算pca-t2(霍特林)统计量
t2=xtp·λ-1·ptx
式中λ=diag{λ1,λ2,...,λn}为代数特征值矩阵(此处特征值为代数特征值,为线性代数的名词概念),ptx为前n个主成分;此处构造的统计量(统计量反映的是样本数据与基线数据即数据集中心之间的距离)意义在于在保留贡献率高的主成分后计算样本数据与基线数据(数据集的中心)之间的距离。
步骤六:确定健康曲线的报警阈值线,所述健康曲线指t2随时间变化的曲线,若健康值即t2超出阈值线时,向用户发出报警并定位故障位置(此处由于在两端轴承与中间丝母上面分别安装了振动传感器,因此当系统出现报警时可以自动定位到具体的部件上面),否则,跳转到步骤七;这里的报警阈值线的纵坐标可以是健康曲线的置信区间的下端点值。
步骤七:等到新样本加入,重复步骤五和步骤六,直到设备无新样本数据加入。
其中,步骤六构造健康曲线的置信区间的具体方法为:
步骤六一、每加入一个新样本,便更新一次置信区间,对于第k个样本,所述置信区间的构造公式如下:
式中
此处所构造的置信区间的实际意义在于对于只含随机误差的健康值,有95%的概率分布在m区间中,超出这个范围的可能性只有5%,因此超出的部分被认为健康值出现异常,开始发生退化。
步骤六二、判断新加入的样本是否处在置信区间内:
计算
步骤六三:当p=m时(m可取1-10中的任意整数),判断n中的连续数个数是否为m(即连续m个样本处在置信区间外),连续数是n的子集,连续数个数是连续数中元素的个数,若是,则阈值线为所述连续m个样本中第一个样本对应的健康值;若n中的连续数个数小于m,则更新n、p,重复步骤六一和步骤六二。
n与p的更新方法为:当n中的连续数q的最后一个元素与n的最后一个元素相同时,令n=q;当n中的连续数q的最后一个元素与n的最后一个元素不同时,令n只保留其最后一个元素。p为n此时的元素个数。例如,n={13457},此时连续数q={345},那么更新n={7},p=1;如果n={35789},此时q={789},那么更新n={789},p=3。
由此得到的阈值线为设备退化报警阈值线,目的是为了提醒用户设备的健康状态开始发生变化,已经出现退化的趋势。
步骤六四:扩大置信区间范围,由原来的2d扩展到8d,将步骤六一中的区间更新为:
此处所构造的置信区间的实际意义在于对于只含随机误差的健康值,有接近100%的概率分布在m区间中,超出这个范围的可能性接近于0%,因此超出的部分被认为健康值完全退化,开始出现失效。
步骤六五:重复步骤四和步骤六二和步骤六三,得到第二条阈值线,,由此得到的阈值线为设备失效报警阈值线,目的是为了提醒用户设备健康状态濒临失效边缘,请及时维护或更换,以免失效停机造成的成本增加。
采用上述滚珠丝杠副健康评估方法对滚珠丝杠副的健康情况进行评估,如图2所示,前500个小时,t2值处在较低的水平且相对平稳,说明设备健康状态良好;在500-700小时之间,t2值相对提高,但也处于较平稳状态,说明设备健康状态发生了轻微退化;在700小时之后,t2陡然增加,触发报警,健康曲线呈现出紊乱抖动的变化,说明设备健康状态较差,出现故障或者失效。
- 还没有人留言评论。精彩留言会获得点赞!