基于不相似度与拉普拉斯正则化下的稀疏子集选择方法与流程
本申请涉及机器学习与数据分析领域,其尤其指一种基于不相似度与拉普拉斯正则化下的稀疏子集选择方法。
背景技术:
稀疏子集的选择:发现大量模型或数据点的子集,其保留了整个集合的特征,是计算机视觉应用中的机器学习和数据分析中的一个重要问题,其在图像和自然语言处理,生物/健康信息学,推荐系统等方面有大量应用。这些信息要素被称为代表元或示范。数据代表有助于总结和可视化文本/web文档,图像和视频的数据集,因此增加数据分析师和领域专家的大规模数据集的可解释性。模型代表帮助有效地描述使用少量模型的复杂现象或事件,或者可以用于集合模型中的模型压缩。更重要的是,学习和推理算法(如最近邻(nn))分类器的计算时间和内存要求通过处理包含原始集合的大部分信息的代表来改进。选择一小部分产品推荐给客户不仅可以提高零售商的收入,还可以节省客户时间。此外,代表元有助于数据集的聚类,并且作为最原始的元素,可用于有效地合成/生成新的数据点。最后同样重要的,可以使用代表来获取高性能分类器,使用非常少的样本从大量未标记的样本中选择和注释。不相似度:不相似度是一种数据之间成对的对应关系,它有许多优点:第一,对于高维数据集,其中环境空间维度远高于数据集的基数,处理成对关系比在高维度测量向量上工作更有效。第二,虽然一些实际数据集不存在于向量空间中,例如社交网络数据或蛋白质组学数据中,但成对关系已经可以对其进行有效地计算。
拉普拉斯正则化:低秩方法捕获潜在的低维-rank表示(lrr),作为有前途的数据结构,已经引起了模式分析和信号处理社区的极大兴趣。具体来说,近年来涉及低阶矩阵估计的问题引起了相当大的关注。lrr已广泛应用于子空间分割,图像去除,图像聚类和视频背景/前景分离。lrr中的低等级规范者与最近对鲁棒主成分分析(rpca)的理论进展有着深刻的联系,这为许多应用程序带来了新的强大的建模选项。
技术实现要素:
本发明的目的通过下述技术方案实现:
假设我们有一个源集x={x1,...,xm}和一个目标集y={y1,...,yn},他们分别含有m和n个元素,假设我们得到了x与y之间的不相似度关系
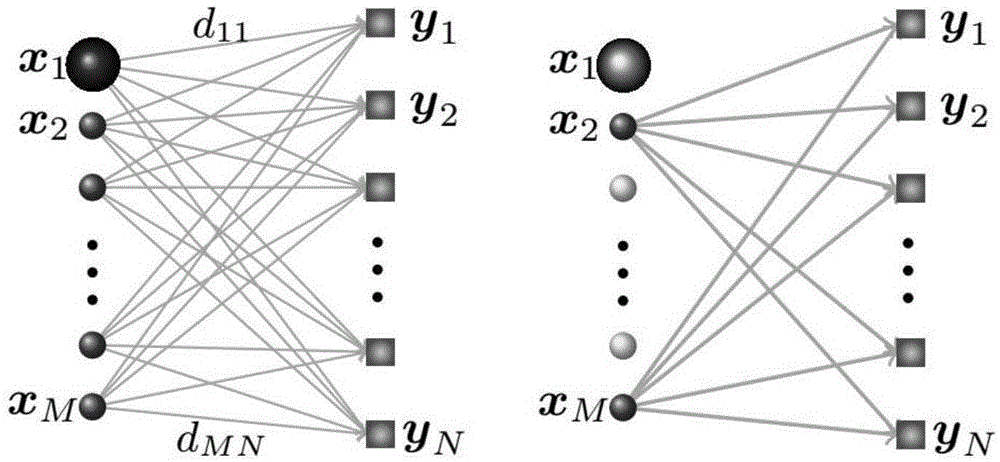
我们的目的是找到x的一个较小的子集使得它能够很好的代表目标集y,如图1所示,其中图1左侧:源集x与目标集y之间的不相似度关系;右侧:找出了源集x的一个子集,这个子集能够很好的代表目标集y所拥有的特征
给予一个不相似度矩阵d,我们需要找到源集x的一个代表子集,即代表元,使得它能够有效的代表目标集y。为此,我们考虑关于与不相似度dij相关联的未知变量zij的优化关系。我们用如下矩阵代表这些未知变量
我们用变量zij表示xi是否代表yj,当zij取0时表示xi代表yj,反之则不代表。为了保证每一个yj都有相应的代表元,我们规定
基于不相似度选择一个很好地编码y的x元素需要达到以下三个目标,第一,我们需要代表元能够足够好的代表yj,如果xi被选为代表元,则编码yj的花费为dijzij∈{0,dij},则通过x的子集代表y的花费为
将这三个目标集合起来,我们得到以下优化函数
其中||-||p代表lp范数,i(-)代表指示函数。此目标函数中的第一项代表编码的质量,第二项表示代表元的个数,第三项表示代表元的结构。
由于其中包含二元结构zij∈{0,1},所以此问题是一个非凸问题,即np-hard,所以我们考虑以下凸松弛问题:
在这个优化函数中我们去掉了非凸部分——指示函数i(-)。我们可以继续将以上问题写为如下的矩阵形式
s.t.1tz=1t,z≥0
其中,
本方法克服了原有方法的以下缺点与不足:
寻找大数据的一个代表元(即代表子集),使得这个代表元能够代表源集绝大部分的特征,这种方法在机器学习的相关问题中有很重要的研究与应用价值。寻找代表元的相关工作已经进行了一段时间,根据代表应保留的信息类型,相关研究算法可以分为两类。
第一类算法是查找位于一个或多个低维子空间中的数据的代表元,在这种情况下数据一般是嵌入一个向量空间之中,这种方法不能应用于数据不在子空间中的一般情况之中。
第二类算法使用数据点对之间的相似性/不相似性,而不是度量向量。使用成对相似性/不相似性关系可以将模型考虑在线性子空间之外,然而现有算法受制于对初始化的依赖。
本发明相对于现有技术的优点及效果:
本文提出的方法基于数据点之间的不相似度关系,找出源集的代表子集,我们将原问题归纳为一个基于不相似度的低秩稀疏子集选择问题,并且在代表元的数量与代表质量之间得到一个比较好的权衡,在此基础上,我们还将引入一个低秩条件,使得所选出的子集能够保留其结构。
附图说明
图1为本发明的目标集寻找示意图。
具体实施例
假设我们有一个源集x={x1,...,xm}和一个目标集y={y1,...,yn},他们分别含有m和n个元素,假设我们得到了x与y之间的不相似度关系
我们的目的是找到x的一个较小的子集使得它能够很好的代表目标集y,如图1所示,其中图1左侧:源集x与目标集y之间的不相似度关系;右侧:找出了源集x的一个子集,这个子集能够很好的代表目标集y所拥有的特征。
给予一个不相似度矩阵d,我们需要找到源集x的一个代表子集,即代表元,使得它能够有效的代表目标集y。为此,我们考虑关于与不相似度dij相关联的未知变量zij的优化关系。我们用如下矩阵代表这些未知变量
我们用变量zij表示xi是否代表yj,当zij取0时表示xi代表yj,反之则不代表。为了保证每一个yj都有相应的代表元,我们规定
基于不相似度选择一个很好地编码y的x元素需要达到以下三个目标,第一,我们需要代表元能够足够好的代表yj,如果xi被选为代表元,则编码yj的花费为dijzij∈{0,dij},则通过x的子集代表y的花费为
将这三个目标集合起来,我们得到以下优化函数
其中||-||p代表lp范数,i(-)代表指示函数。此目标函数中的第一项代表编码的质量,第二项表示代表元的个数,第三项表示代表元的结构。
由于其中包含二元结构zij∈{0,1},所以此问题是一个非凸问题,即np-hard,所以我们考虑以下凸松弛问题:
在这个优化函数中我们去掉了非凸部分——指示函数i(-)。我们可以继续将以上问题写为如下的矩阵形式
s.t.1tz=1t,z≥0
其中,
- 还没有人留言评论。精彩留言会获得点赞!