一种基于协同级联森林的隧道车辆再识别方法与流程
本发明涉及交通领域,特别涉及一种基于协同级联森林的隧道车辆再识别方法,可用于隧道交通安全管理和智能监控等领域。
背景技术:
随着科学技术的发展,视频监控系统已经在交通行业得到了广泛的应用,其在交通安全运营中起到了非常重要的作用。在逐步向智能化发展监控系统中,车辆再识别技术是基于计算机视觉的一个研究领域,旨在非重叠的多摄像机网络下找到同一目标车辆。车辆再识别技术广泛地应用在视频监控系统中,是检测交通异常事件、车辆行为分析等方面的关键技术,因此研究车辆再识别技术具有非常重要的意义与应用价值。车辆再识别技术是建立在目标跟踪的基础上,对同一目标进行再识别,其结果可以进一步辅助多摄像机中的目标跟踪,从而用于交通安全管理,实现视频监控系统的智能化。
隧道是公路上的事故高发路段,车辆再识别是检测隧道内是否发生碰撞事故、异常停车以及连续跟踪重点车辆的重要技术手段。现存车辆再识别技术主要有两种,一种是利用车载电子标签与路侧读写器进行信息互传从而确认车辆身份,但是相关设备的道路沿线安装率很低;另一种是随着计算机视觉的发展而得到广泛应用的车牌识别技术,但在分辨率低、光照弱、遮挡、高车速等情况下,很难获取准确的车牌信息,从而无法实现稳定高效的车辆再识别。因此这两种技术多应用在特定场景下,如停车场和收费站等。此外,由于隧道内光照昏暗不均一、图像分辨率低、视域狭窄遮挡频繁等因素,导致隧道车辆图像的类内间距很大;大多数车辆之间的颜色和外形都非常相似,导致隧道车辆图像的类间间距很小,与车辆再识别类似的行人再识别研究中常采用的基于特征度量学习方法,很难同时满足鲁棒性、稳定性和有区分性,而基于深度学习的方法虽性能良好但需要大量的训练数据且参数众多,从而调参难度大、实用性差。
技术实现要素:
为解决以上问题,本发明利用车辆外形的颜色和纹理信息来提取表达能力强、鲁棒性好的视觉特征,同时提出了基于协同级联森林模型来识别两个无重叠视域的相机拍摄到的两辆车是不是同一辆车,可有效解决视觉特征类内距离大与类间距离小的问题。
为达到上述目的,本发明采用以下技术手段:
本发明提出了一种有效的车辆再识别方法,基于协同级联森林的隧道车辆再识别方法,包括以下步骤:
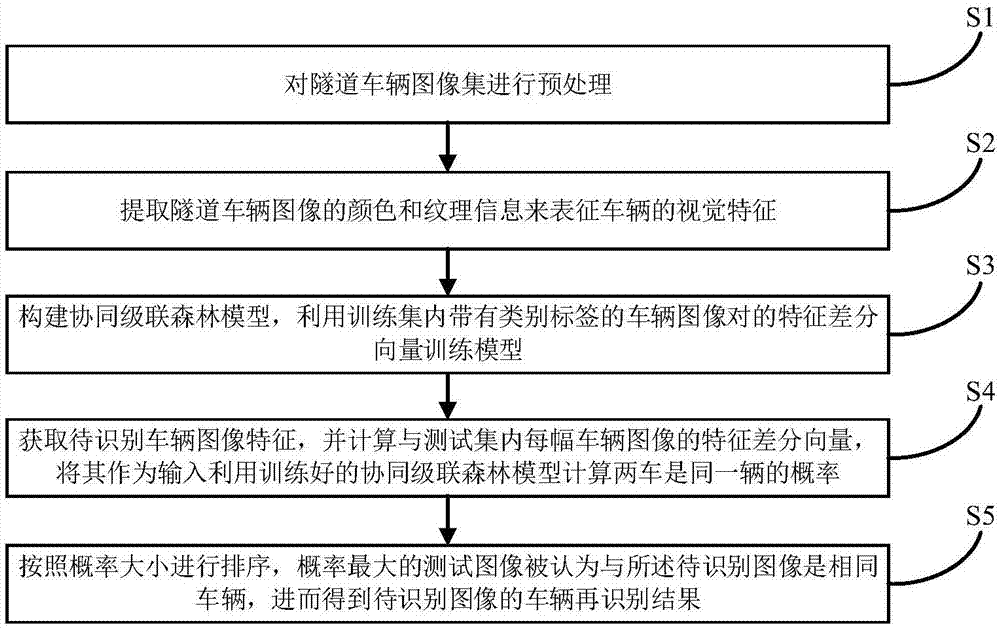
步骤s1,对隧道车辆图像集进行预处理;
步骤s2,提取隧道车辆图像的颜色和纹理信息来表征车辆的视觉特征;
步骤s3,构建协同级联森林模型,利用训练集内带有类别标签的车辆图像对的特征差分向量训练模型;
步骤s4,获取待识别车辆图像特征,并计算与测试集内每幅车辆图像的特征差分向量,将其作为输入利用训练好的协同级联森林模型计算两车是同一辆的概率;
步骤s5,按照概率大小进行排序,概率最大的测试图像被认为与所述待识别图像是相同车辆,进而得到待识别图像的车辆再识别结果。
可选地,所述步骤s1包括以下步骤:
步骤s11,将隧道车辆图像的尺寸统一缩放为m×n,其中m、n为正整数;
步骤s12,利用retinex算法消除图像光照非均性的影响,改善图像的视觉效果。
可选地,所述步骤s2包括以下步骤:
步骤s21,采用多尺度金字塔表示,通过局部池化下采样原始隧道车辆图像。每个尺度下分别提取隧道车辆图像的lomo特征,由siltp纹理特征和hsv颜色直方图组成。
步骤s22,每个滑动子窗口内,根据其中包含的像素点计算siltp特征,统计形成纹理直方图特征;
步骤s23,每个滑动子窗口内,根据其中包含的像素点计算hsv色域下的颜色直方图特征;
步骤s24,将同一水平位置的所有子窗口的纹理和颜色直方图特征根据局部最大出现频次原则进行整合;
步骤s25,将整合后的各水平位置的特征进行串联,得到车辆图像的lomo特征向量。
步骤s26,将多尺度的金字塔表示下的图像的lomo特征向量串联在一起,形成一幅隧道车辆图像最终的lomo特征描述向量。
可选地,所述步骤s3包括以下步骤:
步骤s31,对来自不同相机拍摄的两辆车的特征向量进行差分运算,特征差分向量作为协同级联森林模型的源特征向量输入;
步骤s32,为每个输入分配类别标签,来自同一辆车的两图像的特征差分向量类别标签为1,来自不同车辆的两图像的特征差分向量类别标签为0;
步骤s33,构建协同级联森林模型;
步骤s34,利用带有类别标签的车辆图像对的特征差分向量训练协同级联森林模型。
可选地,所述步骤s33包括以下步骤:
步骤s331,利用多层级联的森林构成协同级联森林模型,其中每一层都由极端森林和随机森林两种森林交替组成;
步骤s332,将样本实例输入森林,森林内不同的决策树会得出不同的类别预测,对所有决策树预测进行统计得出两个类别的百分比,所以森林输出的二维向量即分别是两辆车正确匹配和错误匹配的概率;
步骤s333,模型内,每个森林输出的二维向量与前一个森林输出的结果求平均,然后作为下一个森林的增广输入向量,以此类推;
步骤s334,选择模型最后一个森林输出的概率较大的类别作为最终预测结果。
可选地,所述步骤s34包括以下步骤:
步骤s341,设置协同级联森林模型训练参数;
步骤s342,模型每一层的分类精度由该层中极端森林和随机森林的分类精度的平均值计算得出;
步骤s343,训练过程中,如果新增加层与分类精度最高的层相差三层,则协同级联森林模型停止层数叠加生长,且最终模型只保留至分类精度最高的层,舍弃其后精度较低的三层。
与现有技术相比,本发明具有以下优点:
本发明通过多层的协同级联森林模型,充分利用隧道车辆的颜色和纹理特征信息,使得待识别图像与来自同一辆车图像的匹配概率随着模型层数的增加逐渐增大,而与不同车图像的匹配概率逐渐下降,从而能有效地识别类内间距很大的同一辆车的图像,以及区别类间间距很小的不同车的图像,与传统方法相比,提高了隧道车辆再识别的正确率和稳定性。此外,本发明所述方法的超参数少,模型构建简单而且可迁移性强,同样的参数在不同隧道内的识别效果依然良好。
附图说明
图1是根据本发明一实施例的一种基于协同级联森林的隧道车辆再识别方法的流程图;
图2是根据本发明一实施例的基于协同级联森林的模型结构。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
图1是根据本发明一实施例基于协同级联森林的隧道车辆再识别方法的流程图,下面以图1为例来说明本发明的一些具体实现流程。
本发明一种基于协同级联森林的隧道车辆再识别方法,其具体步骤包括:
步骤s1,对隧道车辆图像集进行预处理;预处理包括以下步骤:
步骤s11,将隧道车辆图像的尺寸统一缩放为m×n,其中m、n为正整数;
在本发明一实施例中,隧道车辆图像尺寸统一缩放为250×380,即m=250、n=380,使得提取图像特征向量时维度相同。
步骤s12,利用retinex算法消除图像光照非均性的影响,改善图像的视觉效果。
步骤s2,提取隧道车辆的颜色和纹理信息来表征车辆的视觉特征;具体包括以下步骤:
步骤s21,采用多尺度金字塔表示,通过局部池化下采样原始隧道车辆图像。每个尺度下分别提取隧道车辆图像的lomo特征,由siltp纹理特征和hsv颜色直方图组成。
在本发明一实施例中,采用3个尺度的金字塔表示,2×2的局部池化。滑动子窗口大小为20×20,移动步长为15个像素。
步骤s22,每个滑动子窗口内,根据其中包含的像素点计算siltp特征,统计形成纹理直方图特征;
步骤s23,每个滑动子窗口内,根据其中包含的像素点计算hsv色域下的颜色直方图特征;
步骤s24,将同一水平位置的所有子窗口的纹理和颜色直方图特征根据局部最大出现频次原则进行整合;
步骤s25,将整合后的各水平位置的特征进行串联,得到车辆图像的lomo特征向量。
步骤s26,将多个尺度的金字塔表示下的图像的lomo特征向量串联在一起,形成一幅隧道车辆图像最终的lomo特征描述向量。
步骤s3,构建协同级联森林模型,利用训练集内带有类别标签的车辆图像对的特征差分向量训练模型;步骤s3具体包括以下步骤:
步骤s31,对来自不同相机拍摄的两辆车的特征向量进行差分运算,特征差分向量作为协同级联森林模型的源特征向量输入;
步骤s32,为每个输入分配类别标签,来自同一辆车的两图像的特征差分向量类别标签为1,来自不同车辆的两图像的特征差分向量类别标签为0;
步骤s33,如图2所示构建协同级联森林模型;所述步骤s33包括以下步骤:
步骤s331,利用多层级联的森林构成协同级联森林模型,其中每一层都由极端森林和随机森林两种森林交替组成;
步骤s332,将样本实例输入森林,森林内不同的决策树会得出不同的类别预测,对所有决策树预测进行统计得出两个类别的百分比,所以森林输出的二维向量即分别是两辆车正确匹配和错误匹配的概率;
步骤s333,模型内,每个森林输出的二维向量与前一个森林输出的结果求平均,然后作为下一个森林的增广输入向量,以此类推;
在本发明一实施例中,所述模型第一层没有前层,所以第一层内作为开端的极端森林输出结果直接作为增广向量输入到随机森林,增广向量与源特征向量串联作为下一森林的输入。从模型第一层的随机森林开始,当前森林输出的二维向量与前一个森林输出的结果求平均,然后作为下一个森林的增广输入向量,同理于其它层的森林;
步骤s334,选择模型最后一个森林输出的概率较大的类别作为最终预测结果。
步骤s34,利用带有类别标签的车辆图像对的特征差分向量训练协同级联森林模型。所述步骤s34包括以下步骤:
步骤s341,设置协同级联森林模型训练参数;
在本发明一实施例中,所述模型训练参数主要包括每个森林中决策树的个数,取值为50,以及为了避免过拟合采用的交叉验证,次数取值为20。
步骤s342,模型每一层的分类精度由该层中极端森林和随机森林的分类精度的平均值计算得出;
步骤s343,训练过程中,如果新增加层与分类精度最高的层相差三层,则协同级联森林模型停止层数叠加生长,且最终模型只保留至分类精度最高的层,舍弃其后精度较低的三层。
步骤s4,获取待识别车辆图像特征,并计算与测试集内每幅车辆图像的特征差分向量,将其作为输入利用训练好的协同级联森林模型计算两车是同一辆的概率;
步骤s5,按照概率大小进行排序,概率最大的测试图像被认为与所述待识别图像是相同车辆,进而得到待识别图像的车辆再识别结果。
以网上公开的行人再识别数据库作为测试对象,在隧道车辆再识别tunnel-vreid数据库上,该数据库包含1000辆来自多个隧道的车,取一半作为测试集,一个摄像机拍摄的车辆图像作为待识别图像,另一个摄像机拍摄的图像作为测试图像,本发明的平均正确率达到rank-1=55.1%;在vehicleid数据库上,该数据库包含26328辆普通路段的车,采用同样的模型参数和测试规则,本发明的平均正确率达到rank-1=49.2%。由此可见本发明方法的有效性。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!