一种基于在线社会网络的用户情感分析方法与流程
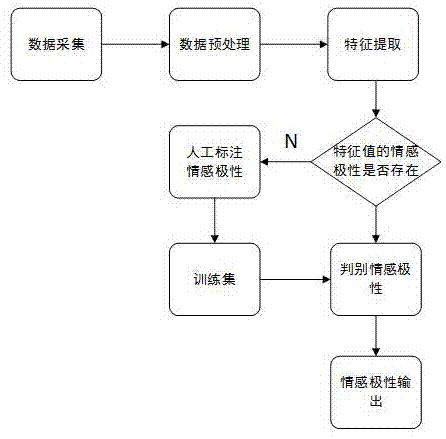
本发明涉及情感认知计算领域,具体涉及一种基于在线社会网络的用户情感分析的方法。
背景技术:
随着现在科学技术的不断发展,人们对于生活品质的要求不断提高。作为人类交互的常用媒介,计算机在人们的日常生活中的作用日益提高,起到了不可或缺的作用。在如今产品的功能性计完全满足人们的日常需求时,如何提升用户的使用体验成为了衡量一个产品成功与否的关键。
用户体验指用户在使用产品时的感受,这是一种主观的情绪。一个优秀的产品被用户使用时,会让用户有着诸如轻松、愉快等正面情绪。增强计算机的智能化程度有利于提高用户的使用体验。这就需要计算机可以像人类一样思考,体会人类的情感,在人类的日常使用中,学习用户的使用习惯。
随着网络的发展,在线社会网络吸引了越来越多的用户投身进来。较之传统的社会网络,在线社会网络有着网络的优势,使得人们之间的联系不在受到距离的限制,扩大了人们的社会活动范围。同时可以将人们的活动可以被记录下来,通过对这些行为的收集和分析,可以判断出用户当时的情绪。这对于提升用户的使用体验是很有帮助的。
技术实现要素:
本发明提出一种基于在线社会网络的用户情感分析方法,从在线社会网络的角度着手,通过对用户的日常行为进行分析,找出用户的兴趣点所在,使用svm分类器对此类数据进行情感识别。
一种基于在线社会网络的用户情感分析方法,包括如下步骤:
步骤一:通过网络爬虫、分析数据包、采集日志文件以及通过调用服务商提供的api接口来开发在线社会网络的应用的方式来收集其中的用户数据来获取用户的信息;
步骤二:对于采集到的用户数据进行处理,通过tf-idf的技术筛选出领域高频词并自动训练出相应的领域分类器,对于数据的处理包括以下几部分:
首先去除在线社会网络中无效转发的操作,从而去除数据中的无效信息;
然后选出部分领域作为标注训练集,从在线社会网络中若干个热门搜索主题作为领域,将收集的用户信息进行划分;
最后利用领域中的种子词对收集到的用户数据进行分类,采用java开源包fundannlp作为文本的分类工具进行划分;
步骤三:提取用户数据中的有效特征,采用通过设置window特征以及word2vec特征的方式来进行特征提取:
(3-1)当用户的文本信息中存在多个评论对象时,通过设置多个window特征,将用于情感倾向性判别的特征限定在一定的范围之内;
(3-2)word2vec将文本中的词转化成向量的形式表示,以此来反映文本的语法规则以及语义特性;通过将文本转化成空间向量,由空间向量的相似度,来表示文本语义上的相似度;通过将不同领域的微博数据作为word2vec的输入进行向量化,然后将得到的向量采用k-means算法进行聚类,最终将其分为若干类,得到词与类别的映射关系;
步骤四:当抽取完特征值后采用支持向量机(svm)作为情感判别方式对用户情绪进行分析;基于svm的情感极性分类任务分为以下三个部分:
(4-1)情感词典的构建:对于情感的分析需要识别情感词的特征值,为此可利用基准情感词,通过大量的语料集对未知情感词采用pmi算法进行情感极性分类扩展情感词典采用人工选取的方式选择情感语义非常明显的基准情感词,并利用如下公式设定阈值进行计算归类;
其中m、n是正向和负向基准情感词的个数,p(w)是待识别情感词出现的概率,p(w,xi)是待识别情感词和正向基准情感词共同出现的概率,p(w,yi)是待识别情感词和负向基准情感词共同出现的概率;
(4-2)情感特征的选择:情感分析特征的选取结合构建的情感词典利用卡方法统计量选择与情感特征相关的词语,计算公式如下:
其中x2(w,s)表示s情感类别中词w的卡方计量,n表示情感训练数据集的规模,p(s,w)表示在情感类别s中包含词w的文档规模,
(4-3)情感极性分类:将基于用户的情感分类分为几种情况;
步骤五:在完成了用户的情感判别之后,对判断结果进行输出。
进一步地,所述步骤四的(4-3)情感极性分类中,具体的基于用户的情感分类分为以下几种情况:
(4-3-1)若出现了包含情感的词语,则从情感极性表中找出对应的极值,为正向情感词时去正极值,为负向情感词时取负极值对于情感极性不明确的,则取其所有情感极值的期望值;
(4-3-2)出现否定词时,则表示用户的情感与之后出现的情感词表的的情感相反对情感极值取反并减少情感词对应的情感数目增量,增加反向的情感数目增量;
(4-3-3)若出现反问副词,模型视它的出现是为了加强负向的情感极值,对于这样的情况,提高负向情感极值;
(4-3-4)若出现程度副词时,表示它的出现是为了加强或者减少情感极值对于程度词修饰情感词的情况,视程度词级别增强或减弱情感极值。
根据如上情况,计算出单据情感极值的公式为:
其中,f(p)是正向情感倾向值,设置f(p)=1,f(n)是正向情感倾向值,设置f(n)=-1,α是正向影响因子,β是负向影响因子,设置取值范围[0,2],两者的值再由试验统计分析得出,np、nn分别为正向和负向情感词的个数,e(wi)、e(wj)分别是正向和负向情感词极值的期望,计算公式为:
其中,m为情感词的极值个数,wk为情感词的极值,pk为其出现的概率。
本发明达到的有益效果为:
(1)本发明基于在线社会网络,以用户的日常使用行为判断出使用者的情感极性,具有较为准确的情感识别效果;
(2)采用支持向量机构建情感极性的分类器,其分类的查全率和准确率几乎超过现有的所有方法,具有很好的泛化能力;
(3)当获得了数据的特征集合后,只需对其进行人工标注情感极性即可,操作简单,易于实现。
附图说明
图1为本发明所述方法的工作流程图。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
一种基于在线社会网络的用户情感分析方法,包括如下步骤:
步骤一:通过网络爬虫、分析数据包、采集日志文件以及通过调用服务商提供的api接口来开发在线社会网络的应用的方式来收集其中的用户数据来获取用户的信息。
步骤二:对于采集到的用户数据进行处理,通过tf-idf的技术筛选出领域高频词并自动训练出相应的领域分类器,对于数据的处理包括以下几部分。
首先去除在线社会网络中无效转发的操作,从而去除数据中的无效信息;然后选出部分领域作为标注训练集,从在线社会网络中若干个热门搜索主题作为领域,将收集的用户信息进行划分;最后利用领域中的种子词对收集到的用户数据进行分类,采用java开源包fundannlp作为文本的分类工具进行划分。
步骤三:提取用户数据中的有效特征,采用通过设置window特征以及word2vec特征的方式来进行特征提取:
(3-1)当用户的文本信息中存在多个评论对象时,通过设置多个window特征,将用于情感倾向性判别的特征限定在一定的范围之内。
(3-2)word2vec将文本中的词转化成向量的形式表示,以此来反映文本的语法规则以及语义特性;通过将文本转化成空间向量,由空间向量的相似度,来表示文本语义上的相似度;通过将不同领域的微博数据作为word2vec的输入进行向量化,然后将得到的向量采用k-means算法进行聚类,最终将其分为若干类,得到词与类别的映射关系。
步骤四:当抽取完特征值后采用支持向量机(svm)作为情感判别方式对用户情绪进行分析;基于svm的情感极性分类任务分为以下三个部分:
(4-1)情感词典的构建:对于情感的分析需要识别情感词的特征值,为此可利用基准情感词,通过大量的语料集对未知情感词采用pmi算法进行情感极性分类扩展情感词典采用人工选取的方式选择情感语义非常明显的基准情感词,并利用如下公式设定阈值进行计算归类;
其中m、n是正向和负向基准情感词的个数,p(w)是待识别情感词出现的概率,p(w,xi)是待识别情感词和正向基准情感词共同出现的概率,p(w,yi)是待识别情感词和负向基准情感词共同出现的概率。
(4-2)情感特征的选择:情感分析特征的选取结合构建的情感词典利用卡方法统计量选择与情感特征相关的词语,计算公式如下:
其中x2(w,s)表示s情感类别中词w的卡方计量,n表示情感训练数据集的规模,p(s,w)表示在情感类别s中包含词w的文档规模,
(4-3)情感极性分类:将基于用户的情感分类分为几种情况:
(4-3-1)若出现了包含情感的词语,则从情感极性表中找出对应的极值,为正向情感词时去正极值,为负向情感词时取负极值对于情感极性不明确的,则取其所有情感极值的期望值。
(4-3-2)出现否定词时,则表示用户的情感与之后出现的情感词表的的情感相反对情感极值取反并减少情感词对应的情感数目增量,增加反向的情感数目增量。
(4-3-3)若出现反问副词,模型视它的出现是为了加强负向的情感极值,对于这样的情况,提高负向情感极值。
(4-3-4)若出现程度副词时,表示它的出现是为了加强或者减少情感极值对于程度词修饰情感词的情况,视程度词级别增强或减弱情感极值。
根据如上情况,计算出单据情感极值的公式为:
其中,f(p)是正向情感倾向值,设置f(p)=1,f(n)是正向情感倾向值,设置f(n)=-1,α是正向影响因子,β是负向影响因子,设置取值范围[0,2],两者的值再由试验统计分析得出,np、nn分别为正向和负向情感词的个数,e(wi)、e(wj)分别是正向和负向情感词极值的期望,计算公式为:
其中,m为情感词的极值个数,wk为情感词的极值,pk为其出现的概率。
步骤五:在完成了用户的情感判别之后,对判断结果进行输出。
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!