一种基于多标签网络的多向量表示学习方法与流程
本发明涉及一种表示学习方法,更特别地说,是指一种基于多标签网络的多向量表示学习方法。
背景技术:
如今,信息网络在社交网络、生物网络、引用网络和电信网络等形式的大量实际应用中变得无处不在。分析这些网络在许多学科的各种新兴应用中起着至关重要的作用。众所周知,网络数据通常非常复杂,因此难以处理。为了有效地处理网络数据,第一个关键挑战就是找到有效的网络数据表示。
目前已经提出了很多网络表示学习算法,如“deepwalk:onlinelearningofsocialrepresentations”译文为:深度行走:社交表示的在线学习,bryanperozzi等,26mar2014;该文献中使用word2vec方法对网络的表示进行学习。它将网络嵌入到潜在的低维空间中,该空间能够保持网络的结构和属性,使得网络的原始节点可以表示为低维向量,以此可以作为任何基于矢量的机器学习算法的特征,例如节点分类,链路预测等。
但是,先前的一些表示学习方法存在着一些明显的缺陷:每个节点仅具有一个向量表示,这对于一些多标签网络的数据集来说,一个向量将会是这些节点标签的综合表示,而无法体现出每个标签所独有的特性,进而无法更好的完成多标签分类任务。这里多标签是指网络中的一个节点拥有多种属性,表现出不同的功能。例如,纽约时报的新闻语料库可能被同时标记为宗教、政治、教育、金融和教育等主题。如果使用一个向量来表示,将会是对这些不同主题的一个平均,无法学习出每个主题自己所独有的向量表示,进而无法完成多标签网络的分类、分析等工作。
技术实现要素:
为了解决网络节点的多标签表示学习的问题,本发明提出了一种基于多标签网络的多向量表示学习方法。在本发明中,网络中的每个节点可以具有多个标签向量和一个全局向量以供进一步研究。首先借助基于node2vec随机游走统计模型对网络结构进行采样,得到网络节点邻居信息;采样完成的节点游走序列由一连串的节点组成,每一次对下一个游走节点的选择都是随机的;在完成所有网络节点的负采样之后,本发明构建了一个基于skip-gram模型的浅层神经网络框架,并通过当前节点信息来预测周围的邻居节点;其次,为每一个游走节点维护多个聚类集群,并通过其游走-邻居节点的嵌入来生成属于当前节点的节点标签(简称为聚类标签),所述聚类标签被预测为最接近所述游走邻居向量的集群,标签向量被预测为所述集群的中心。在预测聚类标签和标签向量之后,本发明对该标签向量进行不断地迭代更新直至收敛。最后,为了充分利用这些标签向量,本发明为它设置权重,为每个节点形成一个新的向量表示。
本发明的一种基于多标签网络的多向量表示学习方法,其特征在于表示学习有如下步骤:
步骤一,基于node2vec随机游走方法采样获取游走序列集合walks;
步骤101:构建属于任意节点nodea的空的节点游走序列,记为
步骤102:将所述nodea节点放入所述
步骤103:获取属于所述nodea节点的全部邻居节点集,记为
步骤104:随机选择所述邻居节点集
步骤105:采用别名采样算法(aliassampling),根据二阶随机游走的跳转概率
步骤106:对v={node1,node2,…,nodea,…,nodeo,…,nodea}中的其他节点采用步骤101至步骤105,获得节点对应的节点游走序列;从而得到游走序列集合walks,且
步骤二,采用负采样方法生成模型所需的训练数据;
步骤201:建立空的正样本队列q正和空的负样本队列q负,然后执行步骤202;所述q正用于存放训练模型所需要的正采样数据,所述q负用于存放训练模型所需要的负采样数据;
步骤202:设立邻居窗口大小,记为wd,然后执行步骤203;
对第一任意节点游走序列
每次对序列-节点
步骤203:采用任意两个网络节点与正负样本标识构成一个三元组,然后执行步骤204;
对于序列-相邻节点
对网络中所有节点v={node1,node2,…,nodea,…,nodeo,…,nodea}进行采样,每次从网络中选取任意两个节点,选取的两个节点可以是相邻的,也可以是不相邻的,即第一任意节点nodea,第二任意节点nodeo;如果两个节点之间不存在连边
对网络中所有节点v={node1,node2,…,nodea,…,nodeo,…,nodea}进行采样,每次从网络中选取任意两个节点,选取的两个节点可以是相邻的,也可以是不相邻的,即第一任意节点nodea,第二任意节点nodeo;如果两个节点之间存在连边((nodea,nodeo)∈e),或者两个随机选取的节点相同,则将任意两个节点nodea、nodeo组成三元组(nodea,nodeo,+1)存入正样本队列q正中,即
步骤204:设立一个正负样本比例参数β,假设正样本队列q正中三元组个数为np,那么q负中的三元组数量等于β×np;将得到的正样本队列q正与负样本队列q负合并在一起,得到一个新的样本队列q新={q1,...,q(1+β)×np};然后执行步骤205;
步骤205:将新的样本队列q新={q1,...,q(1+β)×np}中的所有元素打乱顺序,得到乱序的样本队列q排序={q1-排序,...,q(1+β)×np-排序},然后执行步骤301;
步骤三,采用基于skip-gram的神经网络方法来构建概率模型;
为了方便说明构建神经网络概率模型将
步骤301:从所述q排序={q1-排序,...,q(1+β)×np-排序}中每次选择一个三元组作为一对节点放入神经网络概率模型中进行学习,然后执行步骤302;将任意选择出的一个三元组记为(nodea,nodeo,δ);
步骤302:对于给定的nodea记它在节点游走序列
步骤303:为nodea维护若干个聚类集群,记第r个聚类中心为μ(nodea,r),其值为第r个聚类中的所有邻居向量的平均,并记此聚类集群中的邻居向量个数为num(nodea,r),计算所述nodea的每个聚类中心μ(nodea,r)与其邻居向量vneighbor(nodea)之间的相似程度sim(μ(nodea,r),vneighbor(nodea)),然后执行步骤304;
为nodea所设定的聚类集群个数r(nodea)由超参数λ来确定,初始化每个节点为1个聚类集群;
步骤304:根据所述的nodea的每个聚类中心μ(nodea,r)与其邻居向量vneighbor(nodea)之间的相似程度来为所述nodea预测聚类标签;如果
聚类中心μ(nodea,r)与其邻居向量vneighbor(nodea)之间的相似程度sim(μ(nodea,r),vneighbor(nodea))由它们之间的余弦值来衡量,其值越接近1说明越相似。
步骤305:将nodea的第
步骤306:在给定节点nodea的第
步骤307:采用随机梯度下降算法更新节点nodea的第
步骤308:设定任意节点nodea的第
本发明一种基于多标签网络的多向量表示学习方法的优点在于:(a)网络节点表示是用一个向量将网络中的各个节点进行描述;为了处理多标签网络中的庞杂的信息和邻居节点关系,本发明的多向量表示学习方法能够使得网络中的每个节点学习出一个或多个标签向量;对于一个节点的多向量表示,本发明会先使用基于node2vec随机游走获取其周边节点,再依据skip-gram浅层神经网络构建节点与其邻居节点之间的关系,然后通过聚类方法为每个节点维护多个聚类集群,进而学习出多个向量表示。(b)为了验证本发明方法的效果,本发明选用blogcatalog、ppi、wikipedia等不同领域的多标签网络数据集,对网络的节点进行多标签分类的工作。在该仿真实验中,本发明方法根据每个节点的每个标签向量的权重,对这些向量做加权平均,最终为每个节点形成一个新的向量表示,在使用相同分类器的情况下,分类结果要显著比其他方法好,可以验证本发明方法在对多标签网络进行网络节点表示方面是有效的。
附图说明
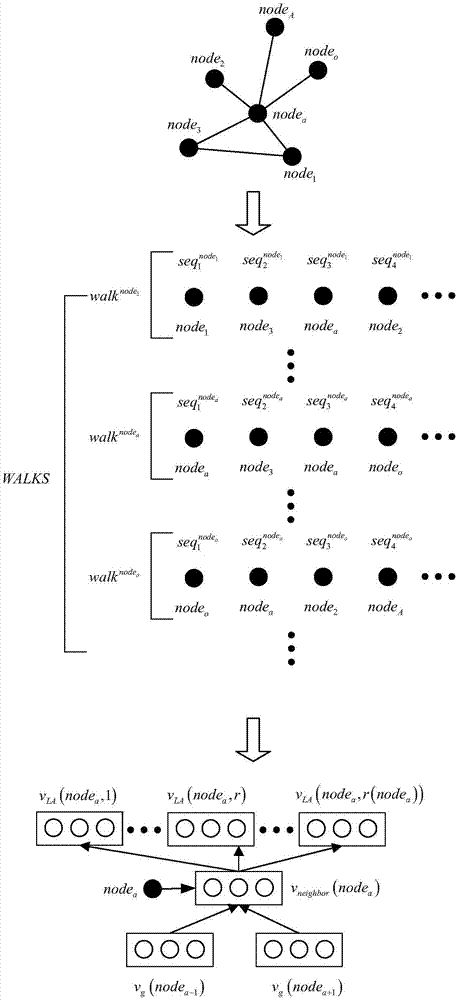
图1是本发明多标签网络节点的多向量表示的学习流程图。
图2a是在blogcatalog数据集中macro-f1指标的评价结果。
图2b是在blogcatalog数据集中micro-f1指标的评价结果。
图3a是在ppi数据集中macro-f1指标的评价结果。
图3b是在ppi数据集中micro-f1指标的评价结果。
图4a是在wikipedia数据集中macro-f1指标的评价结果。
图4b是在wikipedia数据集中micro-f1指标的评价结果。
具体实施方式
下面将结合附图和实施例对本发明做进一步的详细说明。
在本发明中,网络中的节点记为node,多个节点node构成一个节点集合,记为v,且v={node1,node2,…,nodea,…,nodeo,…,nodea};网络中的边记为edge,多条边edge构成一个边集合,记为e,且e={edge1,…,edgeb};节点的标签记为label,多个标签label构成一个节点—标签集合,记为l,且l={label1,…,labelc}。由节点集合、边集合和节点—标签集合构成一个网络,记为g,且g={v,e,l}。edge1表示第一条边;edgeb表示最后一条边,b表示边的总条数,为了方便说明b也表示任意边的标识号。label1表示第一个节点—标签;labelc表示最后一个节点—标签,c表示节点—标签的总标签数,为了方便说明c也表示任意一个节点—标签的标识号。node1表示第1个节点;node2表示第2个节点;nodea表示第a个节点,a表示节点的标识号,a∈a;nodea表示最后一个节点,a表示节点总数。
为了方便说明,nodea也称为任意一个节点,nodeo是除nodea之外的另一个任意节点,下文中将nodea称为第一任意节点,nodeo称为第二任意节点。
在本发明中,以第1个节点node1为起始节点的随机游走序列记为
在本发明中,以第2个节点node2为起始节点的随机游走序列记为
在本发明中,以第一任意节点nodea为起始节点的随机游走序列记为
在本发明中,以第二任意节点nodeo为起始节点的随机游走序列记为
在本发明中,以最后一个节点nodea为起始节点的随机游走序列记为
在本发明中,将节点集合v={node1,node2,…,nodea,…,nodeo,…,nodea}中的所有节点游走序列的集合记为
本发明提出的一种基于多标签网络的多向量表示学习方法,具体表示学习有如下步骤:
步骤一,基于node2vec随机游走方法采样获取游走序列集合walks;
在本发明中,由节点集合v={node1,node2,…,nodea,…,nodeo,…,nodea}构成的网络结构中,对每个节点的邻居节点采样是基于node2vec随机游走方法完成的,也就是以加入二阶随机游走的跳转概率进行的。下面以第一任意节点nodea为起始节点的随机游走序列进行说明,其余节点与所述nodea节点是一样的处理。
步骤101:构建属于任意节点nodea的空的节点游走序列,记为
步骤102:将所述nodea节点放入所述
步骤103:获取属于所述nodea节点的全部邻居节点集,记为
步骤104:随机选择所述邻居节点集
参考图1所示,nodea节点的邻居节点有node1,node2,node3,nodeo,nodea,在
步骤105:采用别名采样算法(aliassampling),根据二阶随机游走的跳转概率
pos表示当前游走节点,src表示位于所述pos的上一个游走节点,dst表示位于所述pos的下一个游走节点;p表示跳入参数,q表示跳出参数,distsrc,dst表示位于所述pos的上、下游走节点之间的最短跳数距离。在本发明中,如果上一个游走节点src到下一个游走节点dst最少需要2跳,则distsrc,dst=2;
如果上一个游走节点src到下一个游走节点dst最少需要1跳,则distsrc,dst=1;
如果上一个游走节点src就是下一个游走节点dst,则distsrc,dst=0。这里,最短跳数distsrc,dst的取值只能为集合{0,1,2}中的一个。如果希望随机游走更多的在局部跳转,那么p需要设置大一些;反之,q需要设置大一些。
步骤106:对v={node1,node2,…,nodea,…,nodeo,…,nodea}中的其他节点采用步骤101至步骤105,获得节点对应的节点游走序列;从而得到游走序列集合walks,且
在本发明中,node2vec方法来自于2016年8月13-17日的会议,《node2vec:scalablefeaturelearningfornetworks》,文译文为“node2vec:网络的可扩展特征学习”,第3.2章节内容,会议名称为“kdd'16proceedingsofthe22ndacmsigkddinternationalconferenceonknowledgediscoveryanddataminingpages855-864”。
步骤二,采用负采样方法生成模型所需的训练数据;
在本发明中,生成模型可使用的训练数据为步骤一得到的游走序列集合
步骤201:建立空的正样本队列q正和空的负样本队列q负,然后执行步骤202;所述q正用于存放训练模型所需要的正采样数据,所述q负用于存放训练模型所需要的负采样数据;
步骤202:设立邻居窗口大小,记为wd,然后执行步骤203;
在本发明中,对第一任意节点游走序列
每次对序列-节点
步骤203:采用任意两个网络节点与正负样本标识构成一个三元组,然后执行步骤204;
在本发明中,对于序列-相邻节点
对网络中所有节点v={node1,node2,…,nodea,…,nodeo,…,nodea}进行采样,每次从网络中选取任意两个节点(选取的两个节点可以是相邻的,也可以是不相邻的),即第一任意节点nodea,第二任意节点nodeo;如果两个节点之间不存在连边
对网络中所有节点v={node1,node2,…,nodea,…,nodeo,…,nodea}进行采样,每次从网络中选取任意两个节点(选取的两个节点可以是相邻的,也可以是不相邻的),即第一任意节点nodea,第二任意节点nodeo;如果两个节点之间存在连边((nodea,nodeo)∈e),或者两个随机选取的节点相同,则将任意两个节点nodea、nodeo组成三元组(nodea,nodeo,+1)存入正样本队列q正中,即
步骤204:设立一个正负样本比例参数β,假设正样本队列q正中三元组个数为np,那么q负中的三元组数量等于β×np;将得到的正样本队列q正与负样本队列q负合并在一起,得到一个新的样本队列q新={q1,...,q(1+β)×np};然后执行步骤205;
q1表示新的样本队列q新中的最小标识号的三元组。
q(1+β)×np表示新的样本队列q新中的最大标识号的三元组。下标(1+β)×np代表样本队列q新中包含有(1+β)×np个三元组。
步骤205:将新的样本队列q新={q1,...,q(1+β)×np}中的所有元素打乱顺序,得到乱序的样本队列q排序={q1-排序,...,q(1+β)×np-排序},然后执行步骤301;
步骤三,采用基于skip-gram的神经网络方法来构建概率模型;
在本发明中,为了方便说明构建神经网络概率模型将
步骤301:从所述q排序={q1-排序,...,q(1+β)×np-排序}中每次选择一个三元组作为一对节点放入神经网络概率模型中进行学习,然后执行步骤302;在本发明中,举例将任意选择出的一个三元组记为(nodea,nodeo,δ);
步骤302:对于给定的nodea记它在节点游走序列
在本发明中,游走节点的全局向量vg(η)被随机初始化;所述vneighbor(nodea)体现了第一任意节点nodea在第一任意节点游走序列
步骤303:为nodea维护若干个聚类集群,记第r个聚类中心为μ(nodea,r),其值为第r个聚类中的所有邻居向量的平均,并记此聚类集群中的邻居向量个数为num(nodea,r),计算所述nodea的每个聚类中心μ(nodea,r)与其邻居向量vneighbor(nodea)之间的相似程度sim(μ(nodea,r),vneighbor(nodea)),然后执行步骤304;r表示聚类集群的标识号;
在本发明中,为nodea所设定的聚类集群个数r(nodea)由超参数λ来确定,初始化每个节点为1个聚类集群。
步骤304:根据所述的nodea的每个聚类中心μ(nodea,r)与其邻居向量vneighbor(nodea)之间的相似程度来为所述nodea预测聚类标签;如果
在本发明中,聚类中心μ(nodea,r)与其邻居向量vneighbor(nodea)之间的相似程度sim(μ(nodea,r),vneighbor(nodea))由它们之间的余弦值来衡量,其值越接近1说明越相似。
步骤305:将nodea的第
步骤306:在给定节点nodea的第
步骤307:采用随机梯度下降算法更新节点nodea的第
步骤308:设定任意节点nodea的第
在本发明中,训练神经网络的目的在于能够将损失函数的值降低到最少,为了对神经网络进行训练,本发明采用随机梯度下降算法进行网络参数的学习。
在使用随机梯度下降的时候,由于训练迭代次数过多,会出现过拟合的现象,因此,本发明采用了early-stop(译文为提前终止)方法,在训练到损失函数j(θ)不继续变小时即停止训练,来防止训练时发生的过拟合现象。“提前终止”为《深度学习》第7.8节151页的内容,作者为伊恩·古德费洛,约书亚·本吉奥等,译者为赵申剑,黎彧君;2017年8月1日第一版。
本发明与之前的网络表示学习方法相比,最大的不同是对于多标签网络中的每个节点都学习出了多个向量,使得每个标签拥有自己独立的向量表示,这是单向量网络表示学习方法所不能解决的。通过加权的方式对这些标签向量进行处理,最终得到一个新的节点表示向量,然后在不同领域的多标签数据集上做多标签分类的任务,相对于之前的一些方法都有不同程度的提升,从而验证了本发明的有效性。
实施例1
本实施例采用了blogcatalog社交关系网络数据集、ppi蛋白质网络数据集与wikipedia单词共存网络数据集进行学习和实验工作。
blogcatalog是一个博客网站上列出的博主的社交关系网络数据集,总共含有10312个节点,333983条边和39个不同的标签。标签代表博主的兴趣爱好,每一个节点都包含一个或多个标签,表示该博主所拥有的不同的兴趣爱好。
ppi是一个蛋白质与蛋白质之间相互作用的网络数据集,总共含有3890个节点,76584条边和50个不同的标签。标签从标记基因集中获取,代表生物的状态。
wikipedia是一个出现在wikipedia存储的前100万个字节中的单词的共存网络数据集,总共含有4777个节点,184812条边和40个不同的标签。标签代表单词的词性,从stanfordpos-tagger推断出来。
为了验证有效性,本发明方法主要对比了不同方法在多标签网络节点分类任务中的表现:
deepwalk:采用了普通随机游走算法对网络进行采样,随后用word2vec算法得到网络中每一个节点的表示。(2014deepwalk:onlinelearningofsocialrepresentations[j].perozzib,alrfour,skienas.kdd:701-710.)
node2vec:是deepwalk的升级版,采用了二阶随机游走算法对网络进行采样,随后用word2vec算法得到网络中每一个节点的表示。(2016,node2vec:scalablefeaturelearningfornetworks[c].grovera,leskovecj.kdd:855.)
line:主要用于大规模网络嵌入,并且可以保持节点的一阶和二阶邻近度。它分为两个独立的阶段为一个节点学习出一个d维的向量。在第一阶段,通过广度优先搜索技术(bfs)在节点的直接邻居上学习前d/2维度;在第二阶段,通过从源节点的2跳距离中采样出节点学习后d/2维度。最后拼接到一起形成一个向量。(2015,line:large-scaleinformationnetworkembedding[j].tangj,qum,wangm,etal,2(2):1067-1077.)
graph2gauss:这种方法主要用于大规模的带属性网络上,他将每个节点嵌入为高斯分布,并捕获关于节点表示的不确定性。(2017,deepgaussianembeddingofgraphs:unsupervisedinductivelearningviaranking[j].bojchevskia,günnemanns.)
对本发明方法选用多标签节点分类预测方法进行向量表示效果的对比。本实验均采用混合验证技术(cross-validation),在不同的分类预测方法选用one-vs-rest分类器进行分类。
本发明方法采用了两个评价指标进行衡量分别是micro-f1和macro-f1。
其中macro-f1的计算方法为:
其中pmacro表示宏差准率,rmacro表示宏查全率。
micro-f1的计算方法为:
其中pmicro表示微差准率,rmicro表示微查全率。
在blogcatalog数据集的效果如图2a、图2b所示,在ppi数据集的效果如图3a、图3b所示,在wikipedia数据集的效果如图4a、图4b所示,其中图2a、图3a和图4a代表的是各方法在macro-f1评价指标下的表现,图2b、图3b和图4b代表的是各方法在micro-f1评价指标下的表现。图的横轴代表了分类器的训练数据占全部数据的百分比(这里用0到1之间的小数表示)。从图中可以看出,本发明方法在不同领域的多标签数据集上的macro-f1和micro-f1评价指标下都比其他几种网络表示学习方法的效果要好,特别可以看出,相比node2vec算法,本发明方法在macro-f1和micro-f1评价指标下,对于各个训练数据所占比例均有2%左右的提升,可以展现出本发明方法在对多标签网络进行多向量表示之后再进行加权,得到的网络节点表示向量要显著比单向量的网络节点表示方法要好。
通过图2~图4的多标签分类的实验结果分析,这些实验体现了本发明方法能够更好地表达多标签网络的网络信息,从而得到更好的网络节点表示向量,因此可以验证本发明方法的有效性。
- 还没有人留言评论。精彩留言会获得点赞!