基于河流模拟的季节性河流与地下水间相互作用预测方法与流程
本发明属于水文水资源数据信息自动化处理
技术领域:
,具体涉及一种基于河流模拟的季节性河流与地下水间相互作用预测方法的设计。
背景技术:
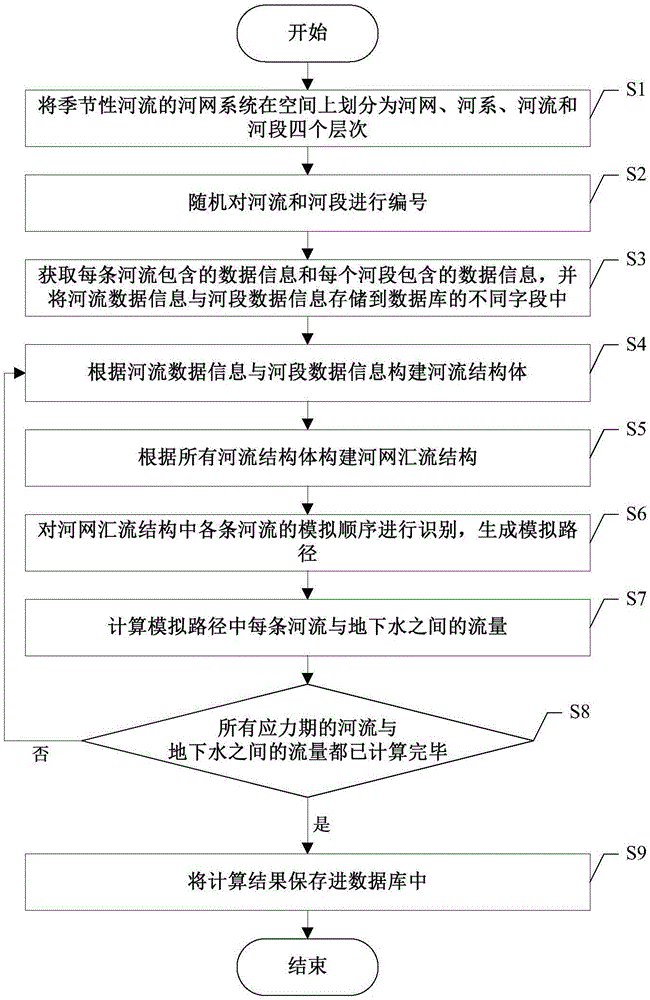
:地表水与地下水的相互转化是自然界普遍存在的一种水文现象,它是水资源的基本属性之一。在进行水资源评价和规划管理中,必须十分注重地表水与地下水的密切水力联系,将两者耦合起来考虑才能为水资源的评价和规划管理提供坚实的基础。在地表水与地下水相互作用系统中,以河流-含水层相互作用研究的意义最重要,即季节性河流与地下水的关系。季节性河流主要指的是在枯水季节河水断流河床裸露而在丰水季节河水奔腾的间歇性河流。为刻画地下水流与季节性河流的关系,需要进行地下河系统模拟分析,最开始,地下水模拟及预测多采用的是简单的水均衡法及水文地质比拟法,对于边界条件的认识常常将河流当作定水头边界或者给定水头边界来处理,而这在很多情况下并不符合实际情形。在实际情形中河流的水位、与含水层交换的流量都是动态变化的,这种复杂机制用传统方法难以刻画。随着计算机技术的发展,数值模拟在地下水计分析算中得到了应用,计算理论和实测地下水分析能力都取得了很大的进步,地下水与地表水的动态关系也得到了较好的刻画。目前地下河系统数值模拟方法主要有有限差分法、有限单元法、边界元法和有限体积法等,基于这些模拟方法几十年来各种地下水数值模拟软件不断涌现,包括visualmodflow、feflow、gms等常用软件。目前以modflow为代表的基于单元中心的有限差分法的数值模拟模型,运用迭代求解的方法求解描述地下水各种状态的偏微分方程定解问题。然而,基于中心单元有限差分方法的数值模拟软件把研究区进行了时间和空间上的离散,在离散的网格上用差商近似代替微商,将微分方程及其定解条件化为代数方程,迭代求解得到水头值。而由于每个离散的网格单元都包含了输入和输出项,上游的出流量等于下游的入流量,因此必须按照河流的汇流顺序将网格单元进行排序。大多模拟软件在这方面要求用户自行指定河流的汇流关系:对所有河流进行编序,将河系中各条河流按汇流的次序排列成序列,并以序号对序列中的河流逐一加以命名,以便于之后进行模拟运算。但在实际纵横交错的复杂河网中这项工作繁琐且易错,若河网关系或汇流顺序排列不当将导致整个程序的模拟结果出现计算错误,在程序无检查情况下,产生的错误隐蔽,难以排查。除此之外,现有的模拟软件在生成河网时对人工分流河流的处理并不灵活,当河流需要按照分流比进行分流时,需要用户自行将分流比换算成固定流量值输入到各分流项,并且无法处理可分水量小于下游所有分水河流的总需水量的情形。技术实现要素:本发明的目的是为了解决采用现有模拟软件对季节性河流与地下水之间相互作用的数值预测存在的上述问题,提出了一种基于河流模拟的季节性河流与地下水间相互作用预测方法。本发明的技术方案为:基于河流模拟的季节性河流与地下水间相互作用预测方法,包括以下步骤:s1、将季节性河流的河网系统在空间上划分为河网、河系、河流和河段四个层次。s2、随机对河流和河段进行编号。s3、获取每条河流包含的数据信息和每个河段包含的数据信息,并将河流数据信息与河段数据信息存储到数据库的不同字段中。s4、根据河流数据信息与河段数据信息构建河流结构体。s5、根据所有河流结构体构建河网汇流结构。s6、对河网汇流结构中各条河流的模拟顺序进行识别,生成模拟路径。s7、计算模拟路径中每条河流与地下水之间的流量。s8、判断是否所有应力期的河流与地下水之间的流量都已计算完毕,若是则进入步骤s9,否则返回步骤s4。s9、将计算结果保存进数据库中,完成对季节性河流与地下水之间相互作用的预测。进一步地,步骤s3中的河流数据信息包括:河流的编号,从1号开始,存储于字段segmid中。下游编号,表示该河流的下游河流编号,该值为-1表示没有下游河流,存储于字段nextunit中。首端入流量,存储于字段inflow中。分流状况,该值不为-1则表示本河流所要分流的河流编号,为-1表示本河流不从别的河流分流,存储于字段divsegm中。分流方式,若本河流从别的河流分流,该值为0表示按指定流量分流,为1表示按分水比分流,存储于字段divopt中。分水比,表示本河流分流所占的比例,值域为0~1,存储于字段divratio中。计算水位,该值为1表示本河流根据曼宁公式计算水位,为0表示水位由用户指定,存储于字段bcalstage中。步骤s3中的河段数据信息包括:应力期编号,存储于字段iperiod中。网格编号,表示本河段所在单元格的层、行、列号,分别存储于字段ilyr、irow和icol中。所属河流编号,存储于字段segmid中。河流内编号,表示本河段在在河流内的编号,存储于字段cellid中。水位,存储于字段strstage中。水力传导度,表示本河段和地下含水层之间的水力传导度,存储于字段cond中。河床顶部高程,存储于字段strtop中。河床底部高程,存储于字段strbtm中。河床宽度,存储于字段strwdt中。河床坡降,存储于字段strslp中。曼宁糙率系数,存储于字段strndc中。进一步地,字段divopt的值为1时,河流的分流方式为按照分水比从被分流河流进行分流,分流公式为:其中n为分流河流的数量,i表示第i条分流河流且i=1,2,...,n,qriv表示被分流河流末端出流量,qdivi表示第i条分流河流分得的流量,αi为第i条分流河流的系统设置分水比例,βi为第i条分流河流的实际分水比例,qnriv表示分流之后剩余流入下游河流的流量。若各条分流河流的分水比例之和小于或等于1,则将出流流量按照分水比例进行分流,剩余流量汇入下游河流;若分水比例之和大于1,则河流下游没有流量,各分流河流按照分水比例分流。字段divopt的值为0时,河流的分流方式为按照指定流量从被分流河流进行分流,分流公式为:其中qi表示第i条河流分得的指定流量,位于字段inflow中;若被分流河流的出流量大于或等于各分流河流的指定流量,则按照指定流量进行分流,剩余流量汇入下游河流;若被分流河流的出流量小于各分流河流的指定流量,则河流下游没有流量,各分流河流按照指定流量的比例进行分流。进一步地,步骤s4中构建的河流结构体包括:上游单元指针数组,用于保存所有向本河流单元汇流的上游河流单元的指针。分流单元指针数组,用于保存本河流单元所要分流的河流单元的指针。下游单元指针,用于保存本河流单元的下游河流单元的指针。河流单元数据数组,包括河流单元编号数据、河流单元属性数据以及河流单元分流数据。河段数据数组,用于保存本河流单元中所有河段的数据信息。进一步地,步骤s5包括以下分步骤:s51、根据河流的编号选择第一个河流结构体。s52、判断该河流结构体是否有下游河流结构体,若是则进入步骤s53,否则进入步骤s54。s53、将该河流结构体的下游单元指针指向下游河流结构体的上游单元指针数组,进入步骤s55。s54、标记该河流结构体为顶级河流出口,并将其加入顶级河流出口数组,进入步骤s55。s55、判断是否所有河流结构体都已完成指针关系设置,若是则进入步骤s56,否则选择下一个河流结构体,返回步骤s52。s56、根据河流的编号选择第一个河流结构体。s57、判断该河流结构体是否为分流河流结构体,若是则进入步骤s58,否则进入步骤s59。s58、将该分流河流结构体的上游单元指针数组中的指针指向上游河流结构体的分流单元指针数组,进入步骤s59。s59、判断是否所有河流结构体都已完成分流关系设置,若是则完成河网汇流结构构建,进入步骤s6,否则选择下一个河流结构体,返回步骤s57。进一步地,步骤s6中对各条河流的模拟顺序进行识别的过程包括河系扫描和河系遍历。河系扫描包括以下步骤:a1、初始化设置扫描次数isumscan=0。a2、初始化设置扫描终止标识ifinish=0。a3、设置河网汇流结构中的河系序数i=1。a4、调用递归函数routtest(i)对第i个河系进行遍历,并获取函数routtest(i)的返回值;若函数routtest(i)的返回值为0,表示本河系中每条河流的模拟顺序都得到确定,若函数routtest(i)的返回值为-1,表示本河系中有河流在本次河系扫描中不能确定模拟顺序。a5、将本河系函数routtest(i)的返回值累加到扫描终止标识ifinish中。a6、令河系序数i加1。a7、判断i是否大于河网汇流结构中的河系个数,若是则进入步骤a8,否则返回步骤a4。a8、判断扫描终止标识ifinish是否等于0,若是则表示本河系中所有河流的模拟顺序都已确定,结束河系扫描流程,否则进入步骤a9。a9、令扫描次数isumscan加1。a10、判断扫描次数isumscan是否大于河网汇流结构中河流单元总个数,若是则表示河网的物理结构不合理,模拟出现异常,结束河系扫描流程,否则返回步骤a2。河系遍历包括以下步骤:b1、设置当前遍历的河流结构体序数为j。b2、判断第j个河流结构体在之前的河系扫描过程中是否已经确定模拟顺序,若是则设置递归函数routtest(j)的返回值为0,进入步骤b13,否则进入步骤b3。b3、判断第j个河流结构体的上游单元指针数组是否有值,若是则表示第j个河流结构体上游有支流河流结构体,进入步骤b4,否则表示第j个河流结构体上游没有支流河流结构体,进入步骤b11。b4、初始化设置结果值iresult=0。b5、初始化设置上游支流河流结构体序数k=1。b6、调用递归函数routtest(k)对第k个上游支流河流结构体进行遍历。b7、获取函数routtest(k)的返回值并将其累加到结果值iresult中;若函数routtest(k)的返回值为0,表示该上游支流河流结构体的模拟顺序都得到确定,若函数routtest(k)的返回值为-1,表示该上游支流河流结构体未能确定模拟顺序。b8、令上游支流河流结构体序数k加1。b9、判断k是否大于上游支流河流结构体个数,若是则进入步骤b10,否则返回步骤b6。b10、判断结果值iresult是否等于0,若是则表示已经确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为0,进入步骤b13,否则表示无法确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为-1,进入步骤b13。b11、判断第j个河流结构体的分流单元指针数组是否有值,若是则表示第j个河流结构体从其他河流结构体分流,进入步骤b12,否则表示第j个河流结构体不从其他河流结构体分流,其为本河系的上游最初级河流,进而确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为0,进入步骤b13。b12、判断第j个河流结构体分流的河流结构体在之前的河系遍历过程中是否已经确定模拟顺序,若是则确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为0,进入步骤b13;否则无法确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为-1,进入步骤b13。b13、输出routtest(j)的返回值,结束第j个河流结构体的遍历。进一步地,步骤s7中河流与地下水之间的流量计算公式为:其中qriv′表示河流与地下水之间的流量,存储于字段stream中,其值为正时表示河流流向地下含水层的渗漏量,其值为负时表示地下含水层流向河流的排泄量;criv表示河流-地下含水层之间的水力传导系数,存储于字段cond中;hi,j,k表示本河段所在的单元计算水头,rbot表示河床基底处的某点的高程,存储于字段strbtm中;hriv表示河段的水位,存储于字段strstage中。进一步地,河段的水位hriv的确定方法为:若字段bcalstage的值为0,则河段的水位hriv由用户指定;若字段bcalstage的值为1,则根据曼宁公式计算河段水位,计算公式为:其中q为河流每个河段的入流量,n为曼宁糙率系数,存储于字段strndc中,c为河段与地下含水层间的水力传导度,存储于字段cond中;w为河段的河床宽度,存储于字段strwdt中;s为河段的河床坡降,存储于字段strslp中。本发明的有益效果是:(1)本发明中在进行河流编号时是随机的,无需考虑河网的汇流关系和分流关系,方便了用户的工作,用户在对研究区的所有河流编号完成后,仅需进一步指出每条河流流入的下游河道编号,后续可通过自动搜索河网中各条河流模拟次序算法把整个河网中的河流按照汇流次序划分完毕并按序逐一命名,以满足定量分析的需要。(2)本发明完善了多河流分流的功能,能够模拟多条河流的定量分流和按比例分流情形,以及可分水量大于或小于总需水量的情形。(3)采用本发明对季节性河流与地下水间相互作用的流量预测具有较高的精确性,与实际情况相比,相对误差仅为0.005%。附图说明图1所示为本发明实施例提供的基于河流模拟的季节性河流与地下水间相互作用预测方法流程图。图2所示为本发明实施例提供的地下水差分单元与河流、河段的关系示意图。图3所示为本发明实施例提供的河流结构体内部示意图。图4所示为本发明实施例提供的河网汇流结构示意图。图5所示为本发明实施例提供的构建河网汇流结构流程图。图6所示为本发明实施例提供的河系扫描流程图。图7所示为本发明实施例提供的河系遍历流程图。图8所示为本发明实施例提供的地下水位下降至河床底积层之下示意图。图9所示为本发明实施例提供的地下水位高于河床底积层的底面示意图。图10所示为本发明实施例提供的河网结构及分流情况示意图。图11所示为本发明实施例提供的河网汇流关系示意图。图12所示为本发明实施例提供的河网单元出流量示意图。图13所示为本发明实施例提供的河网单元渗漏量示意图。具体实施方式现在将参考附图来详细描述本发明的示例性实施方式。应当理解,附图中示出和描述的实施方式仅仅是示例性的,意在阐释本发明的原理和精神,而并非限制本发明的范围。本发明实施例提供了一种基于河流模拟的季节性河流与地下水间相互作用预测方法,如图1所示,包括以下步骤s1~s9:s1、将季节性河流的河网系统在空间上划分为河网、河系、河流和河段四个层次。河网指的是研究区范围内所有交错纵横的河流所构成的地表水通道系统。河网中的河流可能经多个流域出口流出,因此将河网分为多个河系,每个河系对应一个流域出口。河系由多条河流组成,其中的河流是地表水流经的某一条通道,具有上游和下游的概念,水量经由每条河流的上游流动到下游,并汇入其下一级河道,成为下一级河流上游的入流量,水量通过河流的逐级汇流,最终从河系的最下级河流的下游出口(也称为流域出口)流出。本发明实施例中,各条河流是相互独立的地表水通道单元,为了模拟河流地表水与地下水之间的相互耦合作用,需要将河流按其地下水差分网格之间的空间分布关系将河流划分为各个河段。河段是指某河流分布在某地下水网格单元中的一段,是模拟河道地表水和地下水相互作用的基础单元。河流中水量从上游向下游流动,因此将河流从上游到下游按地下水差分网格单元逐段划分并将河段按顺序进行编号,河段编号从小到大的相对顺序代表了水流的流动方向。图2显示了河流、地下水差分网格单元、河段之间的示意关系,图2中有7条河流,其中第1条河流分为2个河段,第2条河流分为4个河段。s2、随机对河流和河段进行编号。研究区的每条河流都具有唯一的编号用来进行区分不同的河流,河流的编号从1开始连续编号,因此最大的河流编号即为研究区河流的数量。本发明实施例中,河流的编号除了标识该河流之外没有任何其他的含义,因此研究区中各条河流的编号可以是随机乱序的,具有很高的编号自由度。现有的其他技术方法通常要求河流的编号同时也表明河流在模拟过程中的前后顺序,如modflow等,这意味着用户必须先识别出河网中河流之间的汇流关系和分流关系后再对河流进行顺序编号,并用编号顺序代表河流在模拟过程中的前后顺序,这对于较复杂的河网而言不仅是很重的工作负担,而且很容易出错。本发明中用户在进行河流编号时无需考虑河网的汇流关系和分流关系,这方便了用户的工作。用户在对研究区的所有河流编号完成后,仅需进一步指出每条河流流入的下游河道编号,后续步骤中可以通过相应算法自动建立河网汇流结构,并识别河网中各条河流的模拟次序。图2中展示了研究区中7条河流的编号。每条河流按其在地下水差分网格中的分布被分为不同的河段,图2展示了河段的划分与编号规则。单元格(1,3)表示位于第1行第3列的单元格。河流1有两个河段,沿着河流流动的方向,从单元(1,3)开始,到单元(2,3)结束。其中一些流量被引入到河流2中,剩余的流量从河流1进入河流3,而河流3具有4个河段。河流2和河流4在单元(5,3)中交汇,以形成包含2个河段的河流5,河流3、河流5和河流6在单元(5,4)中交汇,以形成河流7。河流3和河流6中的两个小部分河流不包括在内在编号方案中,因为它们只穿过单元格(2,4)和(3,5)的角落。此外,不同河流的多个河段可以分配到相同的模型单元格,如第5条河流的第二个河段;第3条河流的第4个河段;第6条河流的第5个河段;第7条河流的第1个河段都位于单元(5,4)中。s3、获取每条河流包含的数据信息和每个河段包含的数据信息,并将河流数据信息与河段数据信息存储到数据库的不同字段中。其中,河流包含的数据信息如表1所示,不同数据信息存储于数据库的不同字段中。表1本发明实施例中,当字段divopt的值为1时,河流的分流方式为按照分水比从被分流河流进行分流,分流公式为:其中n为分流河流的数量(n≥1),i表示第i条分流河流且i=1,2,...,n,qriv表示被分流河流末端出流量,qdivi表示第i条分流河流分得的流量,αi为第i条分流河流的系统设置分水比例,βi为第i条分流河流的实际分水比例,qnriv表示分流之后剩余流入下游河流的流量。本发明实施例中,由于系统设置的各分流河流的分水比例αi之和可能大于1,因此引入实际分水比例βi作为模拟时第i条分流河流的实际的分水比例。若各条分流河流的分水比例之和小于或等于1,则将出流流量按照分水比例进行分流,剩余流量汇入下游河流;若分水比例之和大于1,则河流下游没有流量,各分流河流按照分水比例分流。当字段divopt的值为0时,河流的分流方式为按照指定流量从被分流河流进行分流,分流公式为:其中qi表示第i条河流分得的指定流量,位于字段inflow中;若被分流河流的出流量大于或等于各分流河流的指定流量,则按照指定流量进行分流,剩余流量汇入下游河流;若被分流河流的出流量小于各分流河流的指定流量,则河流下游没有流量,各分流河流按照指定流量的比例进行分流。河段包含的数据信息如表2所示,这些信息数据是模拟河流地表水与地下水水力联系的基础。表2s4、根据河流数据信息与河段数据信息构建河流结构体。在河流、河段数据信息齐备的基础上,可以设计河流单元的数据结构体,从而在模拟过程中方便信息数据的组织和使用,河流结构体的内部结构如图3所示,每个河流结构体中包括:上游单元指针数组,用于保存所有向本河流单元汇流的上游河流单元的指针。分流单元指针数组,用于保存本河流单元所要分流的河流单元的指针。下游单元指针,用于保存本河流单元的下游河流单元的指针。河流单元数据数组,包括河流单元编号数据、河流单元属性数据以及河流单元分流数据。s5、根据所有河流结构体构建河网汇流结构。在河流结构体的基础上,利用河流结构体对象指针可以构建研究区整体河网的汇流结构。将针对每一条河流及其河段的数据信息生成河流结构体对象,再利用河流的上、下游关系,河流分流关系和河流结构体对象指针将不同的河流结构体连接起来,形成模拟中的河网汇流结构,如图4所示。在河网汇流结构构建过程中,需要考虑天然和人工两方面的因素,一是河网中不同河流的上、下游关系,即天然河网的拓扑结构;二是不同河流之间的人工分流联系,即人类干预下的调水关系。在无人工干预的自然状况下,河流总是由上游的初级河流向下游流域出口汇流。如图5所示,河网汇流结构的构建过程包括以下步骤s51~s59:s51、根据河流的编号选择第一个河流结构体。在步骤s51之前,首先需要根据解析数据库中关于季节性河流边界数据的所有字段,从中提取河流信息和属性信息,并确定河流编号。检查编号连续性之后采用哈希表结构存储河流的编号信息,方便后续分析计算时进行查询。s52、判断该河流结构体是否有下游河流结构体,若是则进入步骤s53,否则进入步骤s54。s53、将该河流结构体的下游单元指针指向下游河流结构体的上游单元指针数组,进入步骤s55。s54、标记该河流结构体为顶级河流出口,并将其加入顶级河流出口数组,进入步骤s55。s55、判断是否所有河流结构体都已完成指针关系设置,若是则进入步骤s56,否则选择下一个河流结构体,返回步骤s52。s56、根据河流的编号选择第一个河流结构体。s57、判断该河流结构体是否为分流河流结构体,若是则进入步骤s58,否则进入步骤s59。判断某个河流结构体是否为分流河流结构体的具体方法为:当某河流结构体单元数据中的首端入流量值不为0且分流河流编号不为-1时,该河流结构体即为分流河流结构体。其中,首端入流量和分流河流编号分别从数据库中的inflow和divsegm字段解析得到。s58、将该分流河流结构体的上游单元指针数组中的指针指向上游河流结构体的分流单元指针数组,进入步骤s59。s59、判断是否所有河流结构体都已完成分流关系设置,若是则完成河网汇流结构构建,进入步骤s6,否则选择下一个河流结构体,返回步骤s57。s6、对河网汇流结构中各条河流的模拟顺序进行识别,生成模拟路径。河网汇流结构中各条河流模拟顺序的自动识别是本发明的核心。本发明实施例中,首先设置一个模拟顺序数组,每识别出一条河流的模拟顺序,就将该河流结构体的对象指针置于模拟顺序数组的末尾。这样当所有河流的模拟顺序识别出来之后,该模拟顺序数组中各元素的先后顺序就代表了各条河流的模拟顺序。识别河流模拟顺序的算法流程包括两个大的步骤:河系扫描与河系遍历。如果河网中的各条河流之间没有人工分水联系,各条河流的模拟顺序可直接通过对各个河系进行从上游到下游的河流遍历确定;如果河网中的各条河流之间存在人工分水联系,则需要通过河系遍历和河系扫描相结合的方法确定模拟路径。由于河网汇流结构中存在复杂的分水关系,若对于某条河流,其所分流的河流在该河流模拟之前还没有进行模拟,则这条河流在模拟时就不能确定从分流的河流所分得的流量,分流的过程就不能实现。由于分流关系完全独立于自然的逐级汇流关系,没有规律可言,因此需要通过不断的对河网中各个河系进行扫描测试才能确定最终合理的河流模拟顺序。对河网汇流结构中所有的河系逐一调用递归函数routtest,从而完成所有河系自身的遍历,称之为一次扫描。在河网中不存在河流间分流关系时,各个河系的汇流顺序都是独立的,因此仅需要1次扫描,河网系统中各条河流的模拟顺序即可确定。然而当河流间存在分水关系时,某个河系中的某条河流可能需要等待别的河系中的某条河流模拟完之后才能够确定其上游来水量,造成该河系的一次扫描过程还不能完成该河系中所有河流模拟顺序的排序。本发明实施例中,提出了反复扫描河网的算法来确保每个河系中每条河流的模拟顺序都能得到合理的确定,如图6所示,河系扫描包括以下步骤a1~a10:a1、初始化设置扫描次数isumscan=0。a2、初始化设置扫描终止标识ifinish=0。a3、设置河网汇流结构中的河系序数i=1。a4、调用递归函数routtest(i)对第i个河系进行遍历,并获取函数routtest(i)的返回值;若函数routtest(i)的返回值为0,表示本河系中每条河流的模拟顺序都得到确定,若函数routtest(i)的返回值为-1,表示本河系中有河流在本次河系扫描中不能确定模拟顺序。a5、将本河系函数routtest(i)的返回值累加到扫描终止标识ifinish中。a6、令河系序数i加1。a7、判断i是否大于河网汇流结构中的河系个数,若是则进入步骤a8,否则返回步骤a4。a8、判断扫描终止标识ifinish是否等于0,若是则表示本河系中所有河流的模拟顺序都已确定,结束河系扫描流程,否则进入步骤a9。a9、令扫描次数isumscan加1。a10、判断扫描次数isumscan是否大于河网汇流结构中河流单元总个数,若是则表示河网的物理结构不合理,模拟出现异常,结束河系扫描流程,否则返回步骤a2。每次在更新扫描次数isumscan时,需要对其进行检查。由于河网中的河流单元总数是固定的,而每次扫描至少能多确定一条河流的模拟顺序,因此扫描次数isumscan存在一个阈值。若扫描次数isumscan的值大于河网中河流单元的总个数,则表明模拟出现异常,河网的物理结构不合理,退出模拟并结束河系扫描流程。河网中每个河系都有一个顶级河流出口(最下游的河流单元),河系遍历的过程采用递归调用的方法,从每个河系的流域出口开始向上游河流结构体遍历,直至找到上游最初级河流(不从别的河流结构体分流的河流),然后从初级河流开始向下游排序。如图7所示,河系遍历包括以下步骤b1~b13:b1、设置当前遍历的河流结构体序数为j。b2、判断第j个河流结构体在之前的河系扫描过程中是否已经确定模拟顺序,若是则设置递归函数routtest(j)的返回值为0,进入步骤b13,否则进入步骤b3。b3、判断第j个河流结构体的上游单元指针数组是否有值,若是则表示第j个河流结构体上游有支流河流结构体,进入步骤b4,否则表示第j个河流结构体上游没有支流河流结构体,进入步骤b11。b4、初始化设置结果值iresult=0。b5、初始化设置上游支流河流结构体序数k=1。b6、调用递归函数routtest(k)对第k个上游支流河流结构体进行遍历。b7、获取函数routtest(k)的返回值并将其累加到结果值iresult中;若函数routtest(k)的返回值为0,表示该上游支流河流结构体的模拟顺序都得到确定,若函数routtest(k)的返回值为-1,表示该上游支流河流结构体未能确定模拟顺序。b8、令上游支流河流结构体序数k加1。b9、判断k是否大于上游支流河流结构体个数,若是则进入步骤b10,否则返回步骤b6。b10、判断结果值iresult是否等于0,若是则表示已经确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为0,进入步骤b13,否则表示无法确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为-1,进入步骤b13。b11、判断第j个河流结构体的分流单元指针数组是否有值,若是则表示第j个河流结构体从其他河流结构体分流,进入步骤b12,否则表示第j个河流结构体不从其他河流结构体分流,其为本河系的上游最初级河流,进而确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为0,进入步骤b13。b12、判断第j个河流结构体分流的河流结构体在之前的河系遍历过程中是否已经确定模拟顺序,若是则确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为0,进入步骤b13;否则无法确定第j个河流结构体的模拟顺序,设置routtest(j)的返回值为-1,进入步骤b13。b13、输出routtest(j)的返回值,结束第j个河流结构体的遍历。s7、计算模拟路径中每条河流与地下水之间的流量。河流与地下水之间的流量计算公式为:其中qriv′表示河流与地下水之间的流量,存储于字段stream中,其值为正时表示河流流向地下含水层的渗漏量,其值为负时表示地下含水层流向河流的排泄量;criv表示河流-地下含水层之间的水力传导系数,存储于字段cond中;hi,j,k表示本河段所在的单元计算水头,rbot表示河床基底处的某点的高程,存储于字段strbtm中;hriv表示河段的水位,存储于字段strstage中。计算流量qriv′需要用到三个参数:河段的水位hriv、河流-地下含水层之间的水力传导系数criv以及河床基底处的高程位置rbot,并且需要将qriv′表达式(3)中的参数拆分代入基于水量均衡的差分方程。当hi,j,k≤rbot时,如图8所示,hi,j,k已经下降至河床底积层底面之下,在其下形成了一个非饱和带。如果假定河床底积层本身保持饱和,河床基底处的某点的水头可简单地视为该点的高程,即rbot,则河流与地下水之间的流量为一个常数值。在计算时需要将-criv(hriv-rbot)添加到差分项rhs中;当hi,j,k>rbot时,如图9所示,hi,j,k高于河床底积层的底面,河流与地下水之间的流量与河流和地下含水层的水头差成正比,以水头hi,j,k作为变量。在计算时需要将-criv添加到差分项hcof中,并将-criv*hriv添加到差分项rhs中,从而将qriv′拆分代入基于水量均衡的差分方程。将所有计算单元得到的差分方程联立,并采用迭代的方法进行求解。在迭代的过程中,每次迭代的结果都将经过处理后用于下一次的计算。不同的算法有不同的处理方法,在正常情况下,每次迭代后的水头变化逐渐减小,最终达到收敛。这样就完成了一个时间段的水头计算。是否收敛,通常由一个预先定义的收敛指标来确定,当两次迭代计算的最大水头差值小于该收敛指标时,称之为收敛。从初始水头开始,每一步求出每个时间段结束时的水头值,并用该值作为下一个时间段的初始值,并重复这样的过程,直至所要求的时间结束,这样就能得到模拟路径中每条河流与地下水之间的流量。河段的水位hriv的确定方法为:若字段bcalstage的值为0,则河段的水位hriv由用户指定;若字段bcalstage的值为1,则根据曼宁公式计算河段水位,计算公式为:其中q为河流每个河段的入流量,n为曼宁糙率系数,存储于字段strndc中,c为河段与地下含水层间的水力传导度,存储于字段cond中;w为河段的河床宽度,存储于字段strwdt中;s为河段的河床坡降,存储于字段strslp中。本发明实施例中,无论是指定水位计算还是根据曼宁公式进行自动水位计算,一个河段的上游入流量减去本河段的渗漏量(或加上地下水向本河段的渗出量)后,将作为本河段的下游出流量流向下一个河段,成为下一个河段的上游入流量。这样逐次可将河流流量从河流的最上游的河段计算到河流的最下游河段,该流量接着又将成为下一条河流的上游入流量,该过程将一直持续到河流水量离开河网系统。s8、判断是否所有应力期的河流与地下水之间的流量都已计算完毕,若是则进入步骤s9,否则返回步骤s4。s9、将计算结果保存进数据库中,完成对季节性河流与地下水之间相互作用的预测。下面以一个具体实施例对本发明的效果作进一步说明:如图10所示,河网中有9条河流,河流的编号不按照河网汇流的顺序进行,各河流曼宁糙率系数均为0.013。其中,河流1有6个河段,长度分别为2333.21m、5203.9m、3093.2m、5303.9m、5589.5m、2748.8m;河床顶部高程均为-0.5m;河床底部高程均为-1.1m;河床的宽度均为12m;河床的坡降均为0.0012。河流2有7个河段,长度分别为4302.4m、5003.7m、5003.7m、5003.7m、5003.7m、5003.7m、3279.8m;河床顶部高程均为-2m;河床底部高程均为-3m;河床的宽度均为20m;河床的坡降均为0.001。河流3有10个河段,长度分别为44615.4m、6349.3m、6350.4m、6350.4m、6350.4m、6350.4m、6350.4m、6350.4m、6350.4m、3657.2m;河床顶部高程均为-2.5m;河床底部高程均为-3.3m;河床的宽度均为20m;河床的坡降均为0.001。河流4有4个河段,长度分别为5584.0m、2750.6m、4756.1m、6507.3m;河床顶部高程均为-2.6m;河床底部高程均为-3.4m;河床的宽度均为20m;河床的坡降均为0.001。河流5有9个河段,长度分别为2872.5m、4636.0m、3969.2m、5190.0m、5190.0m、3572.2m、4983.6m、5190.0m、5190.0m;河床顶部高程均为-3m;河床底部高程均为-4m;河床的宽度均为20m;河床的坡降均为0.001。河流6有4个河段,长度分别为2647.4m、6812.4m、8235.4m、4735.2m;河床顶部高程均为-2.3m;河床底部高程均为-3.1m;河床的宽度均为20m;河床的坡降均为0.001。河流7有8个河段,长度分别为5463.0m、8445.2m、8445.2m、8445.2m、8445.2m、3686.0m、8445.2m、4759.2m;河床顶部高程均为-3.2m;河床底部高程均为-3.8m;河床的宽度均为20m;河床的坡降均为0.001。河流8有4个河段,长度分别为7161.3m、13369.2m、16279.3m、6149.1m;河床顶部高程均为-5m;河床底部高程均为-9m;河床的宽度均为20m;河床的坡降均为0.001。河流9有10个河段,长度分别为2781.2m、3001.0m、2321.0m、2543.0m、2442.0m、2797.0m、2611.0m、2351.0m、2124.0m、2100.0m;河床顶部高程均为-1m;河床底部高程均为-2m;河床的宽度均为12m;河床的坡降均为0.0012。单元网格沿行方向的渗透系数为8m/s;垂向水力传导率为0.00002;网格单元的初始水头为-1m。河流1的初始流量为12000m3/min,河流8的初始流量为10000m3/min,河流3从河流7分水量为4000m3/min。河流5,河流9,河流2三条河流从河流1分水的比例分别为3:6:1。模拟的空间单位为m;时间单位为天。首先采用步骤s2~s5构建河网汇流结构,检索数据库中的命令关键字,包括segmid、nextunit、divsegm等字段。如表3所示,河流1的下游河流编号为河流2;河流2的下游河流编号为河流4;河流4的下游河流编号为-1,即河流4没有下游河流,为顶级河流出口。如此对每一个河流结构体进行分析,建立河网汇流结构。表3在自然河网的基础上设置调水关系:河流3从河流7分流;河流5与河流9从河流1分流;divsegm字段为-1对应的河流不分流。找到所有有联系的河流单元并设置指针关系,形成的河网汇流关系如图11所示。然后通过步骤s6中的河系遍历和河系扫描自动搜索模拟路径。河网汇流结构中共有两个河系,为左河系(包括河流1、2、3、4)与右河系(河流5、6、7、8、9)。由河系顶级流域出口向上游河流遍历。进行第一次河系扫描,先对左河系进行遍历。从河系出口开始,遍历河流4,发现有上游支流河流2、3,先对河流2进行递归调用。遍历河流2,发现有上游河流1,对河流1进行递归调用。遍历河流1,河流1为左河系上游最初级河流,没有上游河流,将其加入模拟序列数组并返回值0,结束河流1的递归调用,返回到河流2的递归调用函数。河流2获得返回值0,其上游已确定模拟顺序,将河流2加入模拟序列数组并返回值0。结束河流2的递归调用,返回到河流4的递归调用函数。河流4获取第一个上游支流返回值0,接着遍历第二条上游河流3。河流3从河流7分流且河流7没有确定模拟顺序,停止左河系遍历并返回-1。河流4第二个上游返回值为-1,求得两个返回值之和为-1并返回给左河系。接着对右河系进行遍历。从河系出口开始,遍历河流6,发现有上游支流河流9、7,先对河流9进行递归调用。遍历河流9,河流9从河流1分流且河流1已确定模拟顺序,将河流9加入模拟序列数组并返回值0。结束河流9的递归调用,返回到河流6的递归调用函数。河流6获得第一个上游返回值0,接着遍历第二条上游河流7。遍历河流7,发现有上游支流河流5、8,先对河流5进行递归调用。遍历河流5,河流5从河流1分流且河流1已确定模拟顺序,将河流5加入模拟序列数组并返回值0。结束河流5的递归调用,返回到河流7的递归调用函数。河流7获得第一个上游返回值0,接着遍历上游河流8。遍历河流8,河流8为上游顶级河流,将其加入模拟序列数组并返回值0。河流7获得第二个上游返回值0,其所有上游返回值之和为0即所有上游河流都已确定模拟顺序,将河流7加入模拟序列数组并返回值0。结束河流7的递归调用,返回到河流6的递归调用函数。河流6获得第二个上游返回值0,其所有上游河流都已确定模拟顺序,将河流6加入模拟序列数组并将0返回给右河系,此时右河系所有河流已确定模拟顺序,完成第一次河系扫描。两个河系返回值之和为-1,进行第二次河系扫描。对左河系进行遍历,遍历河流4,其上游河流2已确定模拟顺序返回值0,结束河流2的递归调用,返回到河流4的递归调用函数。接着遍历第二条上游河流3,河流3从河流7分流且河流7已确定模拟顺序,将河流3加入模拟序列数组并返回值0。河流4获得第二个上游返回值0,其所有上游返回值之和为0,将将河流4加入模拟序列数组并将0返回给左河系。右河系返回值为0,则不对右河系进行遍历,完成第二次河系扫描。两个河系返回值之和为0,已确定河网中所有河流的模拟顺序,停止扫描。通过步骤s7~s9对河流与地下水之间的流量进行预测,并对预测结果进行分析,可以得到本发明的技术效果为:(1)体现了自动搜索模拟路径的能力。经过对河网的分析,整个河网中的河流按照汇流顺序被逐一编号,结果如表4所示,其中iorder字段为模拟序列,unitid字段为河流原始编号。因此在进行河流原始编号时是随机的,无需考虑河网的汇流关系和分流关系,方便了用户的工作。表4iperiodiorderunitid011022039045058067073086094(2)实现了多条河流按定量分流和按比例分流的功能。河流5,河流9,河流2三条河流从河流1分水的流量分别为:1979.95m3/min、3959.89m3/min、659.99m3/min。比例分别为3:6:1;河流7出流量为12916.03m3/min,经河流3分走4000m3/min的流量后8915.73m3/min的水汇入下游河流6。(3)充分展示了模拟预测结果的精确度。河网各单元网格的出流量和渗漏量如图12、13所示,全区的绝对水量平衡误差为-0.822m3;相对水量平衡误差为0.005%。其中,季节性河流向地下水系统的渗漏量为14303.2m3;地下水系统向季节性河流的排泄量为27.9m3。本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1