一种融合频繁项集的油田业务服务推荐方法与流程
本发明属于推荐方法应用领域,特别是将其应用于油田企业业务服务的领域。
背景技术:
随着油田企业集成服务云平台的不断发展和完善,业务服务数量也不断增多。在油田企业集成服务云平台中每天都会产生大量的数据,使得信息过载问题日益严重。无论是业务服务的使用者在大量业务服务中定位最能满足自己当前需求的业务服务还是开发者在海量的行为数据发掘使用者的需求都面临巨大的挑战和困难。
为了有效解决信息过载问题,关于推荐方法的技术迅速发展起来,为此国内外也进行了大量的研究。近年来,随着大数据时代的到来,推荐技术正向着传统方法和机器学习结合的方向发展。目前,各种新的推荐技术方法仍是各国的前沿研究方向。
传统的推荐方法是基于用户历史评分数据建立推荐模型,计算用户对物品的喜爱程度,而在油田企业集成服务云平台中,用户对业务服务的评分数据不仅是反应用户喜爱度还有用户工作过程中的需求。若仅考虑用户的喜爱度则会使推荐的结果会具有一定的偏差,如果在传统推荐模型的基础上考虑用户工作需求的因素,推荐的准确率和用户满意度将会有很大提高。
由于用户评分数据的稀疏性,即用户不可能对所有的油田业务服务进行评分。在缺少评分数据的情况下,现有常用的随机算法、众数法、平均法等评分补充方法都是根据其他极少的评分数据进行推算,这就导致最终的推荐效果不是十分理想。因此迫切需要一种在评分数据稀疏的情况下能够考虑工作需求对用户进行推荐的方法。
针对传统推荐方法在油田业务服务上面临的问题,本发明提供一种新的融合频繁项集的油田业务服务推荐方法。本发明提供的方法以油田业务服务数据为基础,通过用户行为分析,能有效挖掘用户的行为习惯或工作模式,将用户工作模式与传统推荐技术相结合,使推荐方法具有较高的准确率,从而有助于能提高用户的工作效率,提高用户对云平台的满意度。
技术实现要素:
由于用户工作需求对推荐结果的影响,采用传统常规的推荐模型存在推荐效果不理想的情况,本发明从传统推荐模型与关联规则算法相结合的角度出发,提供一种融合频繁项集的油田业务服务推荐方法,结合时间信息对用户的工作需求进行建模,能有效提高推荐的准确率和用户的满意度。
由于用户评分数据稀疏,采用传统算法在少量的评分数据下计算存在推荐结果不准确的问题,结合时间信息进行用户行为分析能有效挖掘用户的工作模式并为生成虚拟评分数据提供依据,因此本发明结合时间信息进行用户行为轨迹挖掘,从而能较好的解决用户评分数据稀疏的问题。
融合频繁项集的油田业务服务推荐方法主要包括以下几个步骤:
a.数据预处理
利用python的re模块对油田业务服务的数据进行数据预处理;
b.计算频繁二项集
根据apirori算法原理,计算油田业务服务数据的频繁二项集及支持度,通过计算频繁二项集两项之间的时间间隔,结合时间信息定义赋值函数,赋予时间间隔小的两个业务服务赋予较高的权值,时间间隔大的两个业务服务赋予较小的权值,最终将权值进行累加得到频繁二项集的组合支持度,公式如下:
sup_time=sup(item)+f(公式2)
公式1为赋分函数计算公式,其中f为赋值函数,f’为上一轮计算的赋值函数值,val为时间间隔的值,公式2为组合支持度计算公式,其中sup_time为组合支持度,sup(item)为频繁项集的支持度;
c.推荐模型的建立
采用传统的基于物品的协同过滤算法与频繁项集的组合支持度相结合的方式建立油田业务服务推荐模型。用户对油田业务服务的评分不仅是反应用户喜爱度还有工作过程中的需求,若直接采用传统的推荐算法基于用户的评分来计算用户的喜爱度则忽略了用户的工作需求部分。根据余弦相似度计算油田业务服务之间的余弦相似性,定义评分函数结合时间信息计算油田业务服务之间的相似性,由需求度计算公式计算用户对油田业务服务的需求度,输出需求度最高的三个服务,运算公式如下:
公式3是余弦相似度的计算公式,其中|n(i)|表示使用过油田业务服务i的用户数,|n(j)|表示使用过油田业务服务j的用户数,|n(i)|∩|n(j)|表示同时使用过油田业务服务i和j的用户数量,公式4是评分函数,其中wji表示油田业务服务之间的相似度,k表示权重参数,sup_time表示组合支持度,freq表示频繁项集;
d.实际检测
获得油田业务服务数据,输入融合频繁项集的油田业务服务推荐方法中,推荐算法的输出即为用户的推荐结果。
附图说明
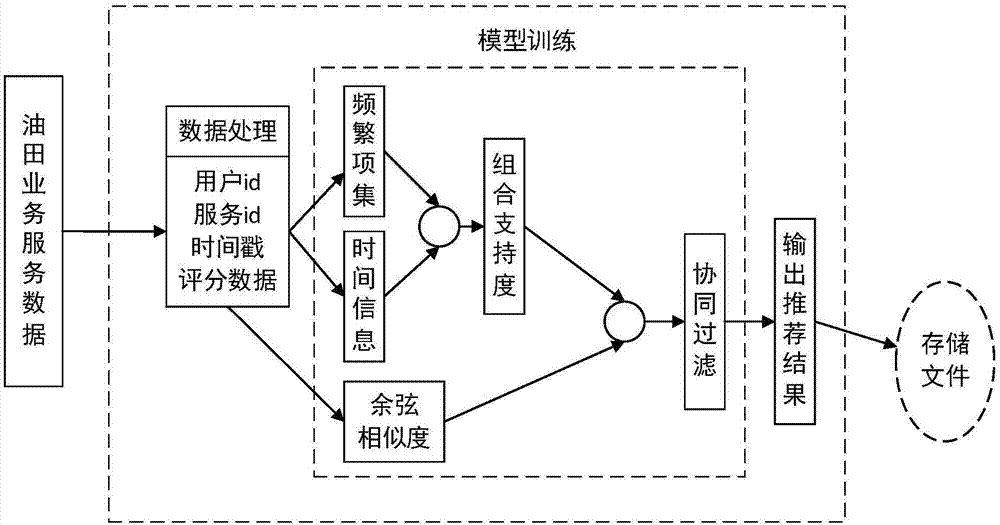
图1是本发明的模型结构图
具体实施方式
下面结合附图说明本发明的实施方式。
图1是本发明的融合频繁项集的油田业务服务推荐方法的模型结构图,本发明的推荐方法分为三个阶段,具体包括:
a.数据预处理
利用python的re模块对油田业务服务数据进行处理,提取油田业务服务数据中的用户id、业务服务id、时间戳、评分数据等属性数据,并照用户id进行组织,存储在二维列表中;
b.模型训练
第一步:根据apriori原理对油田业务服务数据进行频繁项集挖掘,计算频繁项集中每一项的时间间隔,定义赋值函数将时间间隔参数化,赋予时间间隔小的业务服务较大的权值,时间间隔大的业务服务较小的权值,再将出现的频繁项集的权值与支持度进行累加得到组合支持度。赋值函数和组合支持度计算公式如下:
sup_time=sup(item)+w3(val)
其中w3为赋值函数,w3’为上一轮计算的赋值函数值,val为时间间隔的值,sup_time为组合支持度,sup(item)为频繁项集的支持度。
第二步:根据余弦相似度计算公式计算油田业务服务之间的相似度,定义评分函数,将余弦相似度与组合支持度输入评分函数,评分函数的输出作为基于物品的协同过滤算法的相似度输入,逐个计算用户对油田业务服务的需求度。
余弦相似度计算公式和评分函数公式如下:
其中k表示权重参数,当k依次取0.01-0.2时,计算出k的取值为0.05时效果最佳,wji表示油田业务服务之间的相似度,sup_time表示组合支持度,freq表示频繁项集,|n(i)|表示使用过油田业务服务i的用户数,|n(j)|表示使用过油田业务服务j的用户数,|n(i)|∩|n(j)|表示同时使用过油田业务服务i和j的用户数量;
c.存储及实际检测
根据用户对油田业务服务的需求度,记录每个用户需求度最高的三个业务服务,并写入文件中,对待推荐的用户进行推荐,将用户名输入模型中,模型的输出即为推荐结果。
- 还没有人留言评论。精彩留言会获得点赞!